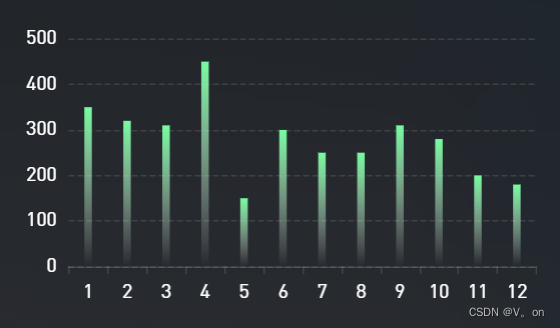
目录
大数据题目的技巧总括
实例精析
实例一
实例二
实例三
大数据题目的技巧总括
(1)哈希函数可以把数据按照种类均匀分流;
(2)布隆过滤器用于集合的建立与查询,并可以节省大量空间;
(3)一致性哈希解决数据服务器的负载管理问题;
前面这三个内容在《与哈希函数有关的结构》这篇文章中已经进行详细介绍。
与哈希函数有关的结构-CSDN博客
(4)利用并查集结构做岛问题的并行计算;
这个内容在《并查集的详解》这篇文章中已经进行详细介绍。
并查集的详解-CSDN博客
(5)位图解决某一范围上数字的出现情况,并可以节省大量空间
关于位图的内容在《与哈希函数有关的结构》这篇文章中有所介绍,这篇文章也有相关介绍
与哈希函数有关的结构-CSDN博客
(6)利用分段统计思想、并进一步节省大量空间
(7)利用堆、外排序来做多个处理单元的结果合并
这篇文章主要介绍后面三个。
实例精析
实例一
32位无符号整数的范围是0~4,294,967,295,现在有一个正好包含40亿个无符号整数的文件,所以在整个范围中必然存在没出现过的数。可以使用最多1GB的内存,怎么找到所有未出现过的数?
这个题目的求解可以采用位图的思想,把32位无符号整数的范围做位图对应,(位图用一个比特表示一个数出现过还是没有出现过),准备一个的比特类型的数组,那么需要
的字节空间,也就是512MB,然后出现过的记录一次,很容易统计出来没有出现过的。
[进阶]只给你3KB的内存,怎么找到一个没有出现过的数字?
题目给了3KB的内存,先计算得出如果把3KB的内存全部变成无符号整型数组的话,可以生成长度为768的整型数组,在这里我们找到比768小的2的次方的大小,选择512长度,此时生成一个长度为512的整型数组。然后将0~这个范围内的数平均分成512份,接着将题目所给的40亿个数字除以512得到的值为多少就放到哪一份所在的数组中,进入一个数组中对应位置的词频加1,统计所有的数字,最终在统计完毕以后,分析哪一份中存在空缺,继续在这一份中按照同样的方式进行统计,最终一定可以找到亿个没有出现过的数字。
进而我们就找到了思路,如果题目只给了1KB内存,同样的用1KB*1024/4,然后找到不超过它的2的次方的某个数值,定义出来整型数组,然后将氛围划分进行求解。
[进阶]只给了有限几个变量,怎么找到一个没有出现过的数字?
将0~这个范围进行二分,然后在每一块分析那一块存在空缺,继续二分,按照这种方式,最多二分32次,一定可以找到一个没有出现过的数字。
对于后面进阶部分的分析采用的是分段统计的思想,在每一段进行题目的求解,进而节省空间
实例二
有一个包含100亿个URL的大文件,假设每个URL占用64B,请找出其中所有重复的URL.
这个题目的解决可以根据哈希函数可以把数据按照种类均匀分流的性质,可以准备多台机器,然后将100亿个大文件分到各台机器上,或者放到多个文件中处理,然后对于每一个文件,使用哈希函数求对应的哈希值,取模得到对应的值,然后根据对应的值依次放到各个用来统计的文件中,统计完毕以后,对每一个统计文件进行处理,在统计文件中就可以中就可以找到重复的URL。
也可以使用布隆过滤器进行操作,根据能够容许的错误率和100亿个样本量进行布隆过滤器的构建,使用布隆过滤器的位图依次开始统计每一个文件,进来过的位置描黑,后面进来的文件如果通过哈希函数求出哈希值取模以后得到的对应的位置已经描黑,那么代表是重复值,采用这种方法统计所有的重复值。
[补充]某搜索公司一天的用户搜索词汇是海量的(百亿数据量),请设计一种求出每天热门Top100词汇的可行办法。
这个问题的解决采用的是堆的思想,先将全部的搜索词汇按照哈希分流的思想,求出哈希值取模放到对应的文件中,每一个文件的搜索词汇放到一个大根堆中,然后将每一个大根堆的堆顶弹出,放到一个总大根堆中,将大根堆的堆顶元素弹出,为TOP1,然后将堆顶元素原来所在的堆的堆顶元素弹出压入总大根堆,然后弹出总大根堆的堆顶元素,按照这种方式,依次打印出TOP100词汇。
实例三
32位无符号整数的范围是0~4294967295,现在有40亿个无符号整数,可以使用最多1GB的 内存,找出所有出现了两次的数。
这个题目依然可以采用哈希函数分流的思想解决,假设我们使用1GB的内存,哈希表一条记录8字节,经过计算1GB内存可以装条记录,那么我们就把内存分成
个小文件,然后对于每一个整数,计算出它的哈希值和m取模,m的值为
,这样就可以把每个整数放到对应的小文件中。接着再对每一个小文件进行同样的操作,哈希函数文件的划分,不断重复上述操作,就可以最终找出所有出现两次的数。
这个题目同样可以使用位图的方法去解决,题目要求找出所有出现两次的数字,那么我们可以用两位信息表示一个数,也就是两个比特,用00表示没有出现过的数字,01表示出现过一次的数字,10表示出现过两次的数字,11表示出现两次以上的数字。这时对于整个范围的数字,需要比特,相当于1GB的内存,实际只有40亿个整数,内存是完全够用的,然后对所有的数字使用位图进行统计,最后找出所有为10的数组即可找到所有出现两次的数。
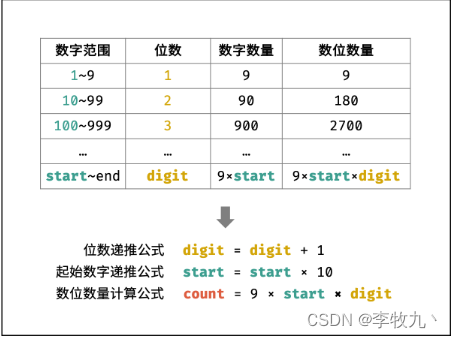
[补充]可以使用最多10MB的内存,怎么找到这40亿个整数的中位数?
这个题目采用分段统计的思想,也就是将总的范围根据内存的大小分成几份,在每一份上进行分析。题目给了10MB内存,计算出10MB内存下最多可以产生的无符号整型数组的长度,数组长度最长为,选择比它小的2的次方的某个数值,选择
长度的无符号整型数组,然后将0~
的范围分成
份,每一份的整型数组用来统计该数组中出现数字的词频,将题目中的40亿个数字每一个除以
,根据得到的商,选择对应的整型数组进入,数组的词频加1,按照这种操作对所有的数字进行统计。需要找到中位数,一共是40个数字,中位数也就是第20亿个数字,从整型数组的0位置开始统计,找到第20个数字所在的位置,在它出现的数组位置中,根据前面位置出现的词频数,找到20亿的数字所在的位置,进而找到40亿个整数的中位数。
当然对于这个题目所用的空间仍然可以更小,使用分段统计的思想,根据题目所给的内存大小决定划分范围的份数,是题目的核心。
实例四
有10GB内存的文件,每一个文件中存放着一个有符号的整数,怎么样利用5GB内存所有的文件中的数字排好序输出。
这个题目可以按照堆的知识进行求解,根据题目所给的内存确定堆中可以存放的记录的数量,使用小根堆进行记录的统计,一个记录占用内存8字节,4字节统计key,4字节统计value。小根堆建立过程中可能还会有一些内存的消耗,假设给每一条记录16字节,那么5GB内存可以存放条记录,我们取记录为
,也就是将整个范围分成
份,然后将无符号整数的范围
~
,一共
个数字除以
得到
,每一份就是
个数字。此时我们从最小的范围开始统计,先将最小的范围的数字从10GB文件中进行弹出,放入小根堆进行统计,得到每一个数字和它出现的词频。然后将得到的小根堆的数字从头开始弹出,此时得到的数字是排好序的,接着对后面的范围进行同样的操作,此时只使用了5GB内存将所有的数字进行了排序。
对于这个题目还可以采用更小的内存进行操作,使用更小的内存求出可以存放的最多的记录数量,根据给定的记录的数量,使用大根堆进行操作,对给定的文件从头开始进行扫描,根据大根堆可以存放的记录的大小放入数字,当达到给定的记录以后,继续扫描的过程中,出现的数字和大根堆里面的数字进行比较,如果发现更小的数字那么弹出大根堆的堆顶元素,然后将更小的数字放进来,按照这种操作依次进行下去,依次操作完毕以后就可以将一些数字(这些数字是较小的一些数字,按照大根堆维持了次序)排好序,接着对剩余的数字按照同样的操作进行。