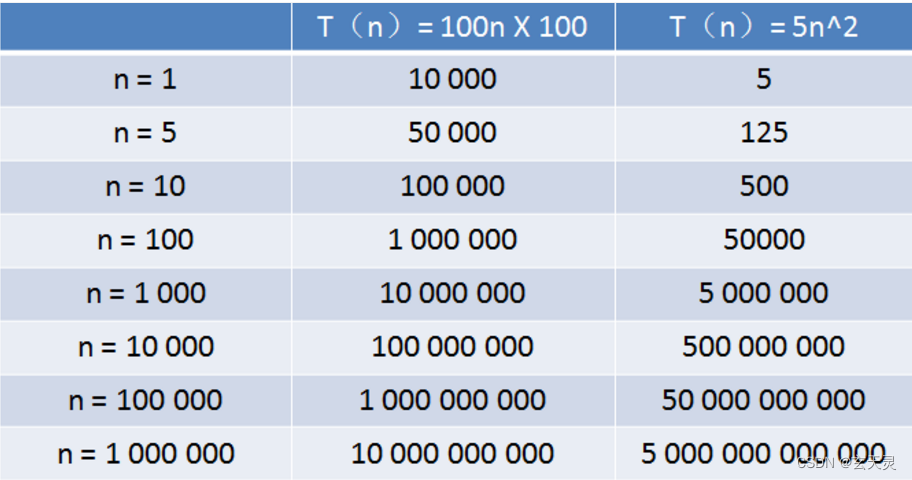
总览
步骤 1 - 生成候选
对于每个测试用户,我们生成可能的选择,即候选人。、我们从 5 个来源生成候选人:
- 点击、购物车、订单的用户历史记录
- 测试周期间最受欢迎的 20 次点击、购物车、订单
- 具有类型权重的点击/购物车/订单到购物车/订单的共同访问矩阵
- 购物车/订单到购物车/订单的共同访问矩阵称为buy2buy
- 点击/购物车/订单与点击的共同访问矩阵,具有时间加权
第 2 步 - 重新排名并选择 20
给定候选名单,我们必须选择 20 个作为我们的预测。在这本笔记本中,我们使用一组手工制定的规则来做到这一点。我们可以通过训练一个XGBoost模型来为我们选择,从而改进我们的预测。我们手工制定的规则优先考虑:
- 最近以前访问过的项目
- 以前多次访问过的项目
- 以前在购物车或订单中的商品
- 购物车/订单到购物车/订单的共同访问矩阵
- 当前热门商品
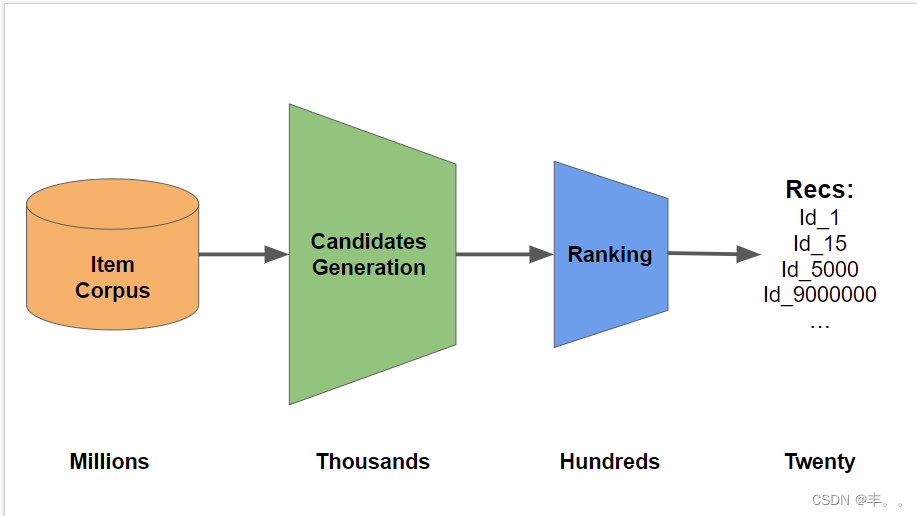
第 1 步 - 使用 RAPIDS 生成候选者
对于候选生成,我们构建了三个共同访问矩阵。一个计算购物车/订单的受欢迎程度,给定用户之前的点击/购物车/订单。我们将类型权重应用于此矩阵。一个计算给定用户以前的购物车/订单的购物车/订单的受欢迎程度。我们称之为“buy2buy”矩阵。一个计算用户之前点击/购物车/订单的点击受欢迎程度。我们将时间权重应用于此矩阵。我们将使用 RAPIDS cuDF GPU 来快速计算这些矩阵
VER即version
VER = 6
import pandas as pd, numpy as np
from tqdm.notebook import tqdm
import os, sys, pickle, glob, gc
from collections import Counter
import cudf, itertools
print('We will use RAPIDS version',cudf.__version__)
使用 RAPIDS 计算三个共同访问矩阵
我们将在 GPU 上使用 RAPIDS cuDF 计算 3 个共同访问矩阵。要获得最大速度,请根据使用的 GPU 将变量DISK_PIECES设置为可能的最小数字,而不会引起内存错误。如果使用 32GB GPU 内存离线运行此代码,则可以使用 DISK_PIECES = 1 并在近 1 分钟内计算出每个共同访问矩阵!Kaggle 的 GPU 只有 16GB 内存,所以我们使用 DISK_PIECES = 4,每个都需要惊人的 3 分钟!以下是一些加快计算速度的技巧
- 使用 RAPIDS cuDF GPU 代替 Pandas CPU
- 读取磁盘一次并保存在 CPU RAM 中以供以后 GPU 多次使用
- 一次在 GPU 上处理尽可能多的数据
- 分两个阶段合并数据。多个小到单个介质。多个中型到单个大型。
- 将结果写入parquet而不是字典
%%time
# CACHE FUNCTIONS
def read_file(f):
return cudf.DataFrame( data_cache[f] )
def read_file_to_cache(f):
df = pd.read_parquet(f)
df.ts = (df.ts/1000).astype('int32')
df['type'] = df['type'].map(type_labels).astype('int8')
return df
# CACHE THE DATA ON CPU BEFORE PROCESSING ON GPU
data_cache = {}
type_labels = {'clicks':0, 'carts':1, 'orders':2}
files = glob.glob('../input/otto-validation/*_parquet/*')
for f in files: data_cache[f] = read_file_to_cache(f)
# CHUNK PARAMETERS
READ_CT = 5
CHUNK = int( np.ceil( len(files)/6 ))
print(f'We will process {len(files)} files, in groups of {READ_CT} and chunks of {CHUNK}.')
1) “推车订单”共同访问矩阵 - 类型加权
%%time
type_weight = {0:1, 1:6, 2:3}
# USE SMALLEST DISK_PIECES POSSIBLE WITHOUT MEMORY ERROR
DISK_PIECES = 4
SIZE = 1.86e6/DISK_PIECES
# COMPUTE IN PARTS FOR MEMORY MANGEMENT
for PART in range(DISK_PIECES):
print()
print('### DISK PART',PART+1)
# MERGE IS FASTEST PROCESSING CHUNKS WITHIN CHUNKS
# => OUTER CHUNKS
for j in range(6):
a = j*CHUNK
b = min( (j+1)*CHUNK, len(files) )
print(f'Processing files {a} thru {b-1} in groups of {READ_CT}...')
# => INNER CHUNKS
for k in range(a,b,READ_CT):
# READ FILE
df = [read_file(files[k])]
for i in range(1,READ_CT):
if k+i<b: df.append( read_file(files[k+i]) )
df = cudf.concat(df,ignore_index=True,axis=0)
df = df.sort_values(['session','ts'],ascending=[True,False])
# USE TAIL OF SESSION
df = df.reset_index(drop=True)
df['n'] = df.groupby('session').cumcount()
df = df.loc[df.n<30].drop('n',axis=1)
# CREATE PAIRS
df = df.merge(df,on='session')
df = df.loc[ ((df.ts_x - df.ts_y).abs()< 24 * 60 * 60) & (df.aid_x != df.aid_y) ]
# MEMORY MANAGEMENT COMPUTE IN PARTS
df = df.loc[(df.aid_x >= PART*SIZE)&(df.aid_x < (PART+1)*SIZE)]
# ASSIGN WEIGHTS
df = df[['session', 'aid_x', 'aid_y','type_y']].drop_duplicates(['session', 'aid_x', 'aid_y'])
df['wgt'] = df.type_y.map(type_weight)
df = df[['aid_x','aid_y','wgt']]
df.wgt = df.wgt.astype('float32')
df = df.groupby(['aid_x','aid_y']).wgt.sum()
# COMBINE INNER CHUNKS
if k==a: tmp2 = df
else: tmp2 = tmp2.add(df, fill_value=0)
print(k,', ',end='')
print()
# COMBINE OUTER CHUNKS
if a==0: tmp = tmp2
else: tmp = tmp.add(tmp2, fill_value=0)
del tmp2, df
gc.collect()
# CONVERT MATRIX TO DICTIONARY
tmp = tmp.reset_index()
tmp = tmp.sort_values(['aid_x','wgt'],ascending=[True,False])
# SAVE TOP 40
tmp = tmp.reset_index(drop=True)
tmp['n'] = tmp.groupby('aid_x').aid_y.cumcount()
tmp = tmp.loc[tmp.n<15].drop('n',axis=1)
# SAVE PART TO DISK (convert to pandas first uses less memory)
tmp.to_pandas().to_parquet(f'top_15_carts_orders_v{VER}_{PART}.pqt')
运行结果
2)“Buy2Buy”共访矩阵
%%time
# USE SMALLEST DISK_PIECES POSSIBLE WITHOUT MEMORY ERROR
DISK_PIECES = 1
SIZE = 1.86e6/DISK_PIECES
# COMPUTE IN PARTS FOR MEMORY MANGEMENT
for PART in range(DISK_PIECES):
print()
print('### DISK PART',PART+1)
# MERGE IS FASTEST PROCESSING CHUNKS WITHIN CHUNKS
# => OUTER CHUNKS
for j in range(6):
a = j*CHUNK
b = min( (j+1)*CHUNK, len(files) )
print(f'Processing files {a} thru {b-1} in groups of {READ_CT}...')
# => INNER CHUNKS
for k in range(a,b,READ_CT):
# READ FILE
df = [read_file(files[k])]
for i in range(1,READ_CT):
if k+i<b: df.append( read_file(files[k+i]) )
df = cudf.concat(df,ignore_index=True,axis=0)
df = df.loc[df['type'].isin([1,2])] # ONLY WANT CARTS AND ORDERS
df = df.sort_values(['session','ts'],ascending=[True,False])
# USE TAIL OF SESSION
df = df.reset_index(drop=True)
df['n'] = df.groupby('session').cumcount()
df = df.loc[df.n<30].drop('n',axis=1)
# CREATE PAIRS
df = df.merge(df,on='session')
df = df.loc[ ((df.ts_x - df.ts_y).abs()< 14 * 24 * 60 * 60) & (df.aid_x != df.aid_y) ] # 14 DAYS
# MEMORY MANAGEMENT COMPUTE IN PARTS
df = df.loc[(df.aid_x >= PART*SIZE)&(df.aid_x < (PART+1)*SIZE)]
# ASSIGN WEIGHTS
df = df[['session', 'aid_x', 'aid_y','type_y']].drop_duplicates(['session', 'aid_x', 'aid_y'])
df['wgt'] = 1
df = df[['aid_x','aid_y','wgt']]
df.wgt = df.wgt.astype('float32')
df = df.groupby(['aid_x','aid_y']).wgt.sum()
# COMBINE INNER CHUNKS
if k==a: tmp2 = df
else: tmp2 = tmp2.add(df, fill_value=0)
print(k,', ',end='')
print()
# COMBINE OUTER CHUNKS
if a==0: tmp = tmp2
else: tmp = tmp.add(tmp2, fill_value=0)
del tmp2, df
gc.collect()
# CONVERT MATRIX TO DICTIONARY
tmp = tmp.reset_index()
tmp = tmp.sort_values(['aid_x','wgt'],ascending=[True,False])
# SAVE TOP 40
tmp = tmp.reset_index(drop=True)
tmp['n'] = tmp.groupby('aid_x').aid_y.cumcount()
tmp = tmp.loc[tmp.n<15].drop('n',axis=1)
# SAVE PART TO DISK (convert to pandas first uses less memory)
tmp.to_pandas().to_parquet(f'top_15_buy2buy_v{VER}_{PART}.pqt')
运行结果
We will process 146 files, in groups of 5 and chunks of 25.
### DISK PART 1
Processing files 0 thru 24 in groups of 5...
0 , 5 , 10 , 15 , 20 ,
Processing files 25 thru 49 in groups of 5...
25 , 30 , 35 , 40 , 45 ,
Processing files 50 thru 74 in groups of 5...
50 , 55 , 60 , 65 , 70 ,
Processing files 75 thru 99 in groups of 5...
75 , 80 , 85 , 90 , 95 ,
Processing files 100 thru 124 in groups of 5...
100 , 105 , 110 , 115 , 120 ,
Processing files 125 thru 145 in groups of 5...
125 , 130 , 135 , 140 , 145 ,
### DISK PART 2
Processing files 0 thru 24 in groups of 5...
0 , 5 , 10 , 15 , 20 ,
Processing files 25 thru 49 in groups of 5...
25 , 30 , 35 , 40 , 45 ,
Processing files 50 thru 74 in groups of 5...
50 , 55 , 60 , 65 , 70 ,
Processing files 75 thru 99 in groups of 5...
75 , 80 , 85 , 90 , 95 ,
Processing files 100 thru 124 in groups of 5...
100 , 105 , 110 , 115 , 120 ,
Processing files 125 thru 145 in groups of 5...
125 , 130 , 135 , 140 , 145 ,
### DISK PART 3
Processing files 0 thru 24 in groups of 5...
0 , 5 , 10 , 15 , 20 ,
Processing files 25 thru 49 in groups of 5...
25 , 30 , 35 , 40 , 45 ,
Processing files 50 thru 74 in groups of 5...
50 , 55 , 60 , 65 , 70 ,
Processing files 75 thru 99 in groups of 5...
75 , 80 , 85 , 90 , 95 ,
Processing files 100 thru 124 in groups of 5...
100 , 105 , 110 , 115 , 120 ,
Processing files 125 thru 145 in groups of 5...
125 , 130 , 135 , 140 , 145 ,
### DISK PART 4
Processing files 0 thru 24 in groups of 5...
0 , 5 , 10 , 15 , 20 ,
Processing files 25 thru 49 in groups of 5...
25 , 30 , 35 , 40 , 45 ,
Processing files 50 thru 74 in groups of 5...
50 , 55 , 60 , 65 , 70 ,
Processing files 75 thru 99 in groups of 5...
75 , 80 , 85 , 90 , 95 ,
Processing files 100 thru 124 in groups of 5...
100 , 105 , 110 , 115 , 120 ,
Processing files 125 thru 145 in groups of 5...
125 , 130 , 135 , 140 , 145 ,
### DISK PART 1
Processing files 0 thru 24 in groups of 5...
0 , 5 , 10 , 15 , 20 ,
Processing files 25 thru 49 in groups of 5...
25 , 30 , 35 , 40 , 45 ,
Processing files 50 thru 74 in groups of 5...
50 , 55 , 60 , 65 , 70 ,
Processing files 75 thru 99 in groups of 5...
75 , 80 , 85 , 90 , 95 ,
Processing files 100 thru 124 in groups of 5...
100 , 105 , 110 , 115 , 120 ,
Processing files 125 thru 145 in groups of 5...
125 , 130 , 135 , 140 , 145 ,
3) “点击”共同访问矩阵 - 时间加权
%%time
# USE SMALLEST DISK_PIECES POSSIBLE WITHOUT MEMORY ERROR
DISK_PIECES = 4
SIZE = 1.86e6/DISK_PIECES
# COMPUTE IN PARTS FOR MEMORY MANGEMENT
for PART in range(DISK_PIECES):
print()
print('### DISK PART',PART+1)
# MERGE IS FASTEST PROCESSING CHUNKS WITHIN CHUNKS
# => OUTER CHUNKS
for j in range(6):
a = j*CHUNK
b = min( (j+1)*CHUNK, len(files) )
print(f'Processing files {a} thru {b-1} in groups of {READ_CT}...')
# => INNER CHUNKS
for k in range(a,b,READ_CT):
# READ FILE
df = [read_file(files[k])]
for i in range(1,READ_CT):
if k+i<b: df.append( read_file(files[k+i]) )
df = cudf.concat(df,ignore_index=True,axis=0)
df = df.sort_values(['session','ts'],ascending=[True,False])
# USE TAIL OF SESSION
df = df.reset_index(drop=True)
df['n'] = df.groupby('session').cumcount()
df = df.loc[df.n<30].drop('n',axis=1)
# CREATE PAIRS
df = df.merge(df,on='session')
df = df.loc[ ((df.ts_x - df.ts_y).abs()< 24 * 60 * 60) & (df.aid_x != df.aid_y) ]
# MEMORY MANAGEMENT COMPUTE IN PARTS
df = df.loc[(df.aid_x >= PART*SIZE)&(df.aid_x < (PART+1)*SIZE)]
# ASSIGN WEIGHTS
df = df[['session', 'aid_x', 'aid_y','ts_x']].drop_duplicates(['session', 'aid_x', 'aid_y'])
df['wgt'] = 1 + 3*(df.ts_x - 1659304800)/(1662328791-1659304800)
df = df[['aid_x','aid_y','wgt']]
df.wgt = df.wgt.astype('float32')
df = df.groupby(['aid_x','aid_y']).wgt.sum()
# COMBINE INNER CHUNKS
if k==a: tmp2 = df
else: tmp2 = tmp2.add(df, fill_value=0)
print(k,', ',end='')
print()
# COMBINE OUTER CHUNKS
if a==0: tmp = tmp2
else: tmp = tmp.add(tmp2, fill_value=0)
del tmp2, df
gc.collect()
# CONVERT MATRIX TO DICTIONARY
tmp = tmp.reset_index()
tmp = tmp.sort_values(['aid_x','wgt'],ascending=[True,False])
# SAVE TOP 40
tmp = tmp.reset_index(drop=True)
tmp['n'] = tmp.groupby('aid_x').aid_y.cumcount()
tmp = tmp.loc[tmp.n<20].drop('n',axis=1)
# SAVE PART TO DISK (convert to pandas first uses less memory)
tmp.to_pandas().to_parquet(f'top_20_clicks_v{VER}_{PART}.pqt')
# FREE MEMORY
del data_cache, tmp
_ = gc.collect()
第 2 步 - 使用手工制定的规则重新排名(选择 20)
def load_test():
dfs = []
for e, chunk_file in enumerate(glob.glob('../input/otto-validation/test_parquet/*')):
chunk = pd.read_parquet(chunk_file)
chunk.ts = (chunk.ts/1000).astype('int32')
chunk['type'] = chunk['type'].map(type_labels).astype('int8')
dfs.append(chunk)
return pd.concat(dfs).reset_index(drop=True) #.astype({"ts": "datetime64[ms]"})
test_df = load_test()
print('Test data has shape',test_df.shape)
test_df.head()
%%time
# LOAD THREE CO-VISITATION MATRICES
def pqt_to_dict(df):
return df.groupby('aid_x').aid_y.apply(list).to_dict()
top_20_clicks = pqt_to_dict( pd.read_parquet(f'top_20_clicks_v{VER}_0.pqt') )
for k in range(1,DISK_PIECES):
top_20_clicks.update( pqt_to_dict( pd.read_parquet(f'top_20_clicks_v{VER}_{k}.pqt') ) )
top_20_buys = pqt_to_dict( pd.read_parquet(f'top_15_carts_orders_v{VER}_0.pqt') )
for k in range(1,DISK_PIECES):
top_20_buys.update( pqt_to_dict( pd.read_parquet(f'top_15_carts_orders_v{VER}_{k}.pqt') ) )
top_20_buy2buy = pqt_to_dict( pd.read_parquet(f'top_15_buy2buy_v{VER}_0.pqt') )
# TOP CLICKS AND ORDERS IN TEST
top_clicks = test_df.loc[test_df['type']=='clicks','aid'].value_counts().index.values[:20]
top_orders = test_df.loc[test_df['type']=='orders','aid'].value_counts().index.values[:20]
print('Here are size of our 3 co-visitation matrices:')
print( len( top_20_clicks ), len( top_20_buy2buy ), len( top_20_buys ) )
#type_weight_multipliers = {'clicks': 1, 'carts': 6, 'orders': 3}
type_weight_multipliers = {0: 1, 1: 6, 2: 3}
def suggest_clicks(df):
# USE USER HISTORY AIDS AND TYPES
aids=df.aid.tolist()
types = df.type.tolist()
unique_aids = list(dict.fromkeys(aids[::-1] ))
# RERANK CANDIDATES USING WEIGHTS
if len(unique_aids)>=20:
weights=np.logspace(0.1,1,len(aids),base=2, endpoint=True)-1
aids_temp = Counter()
# RERANK BASED ON REPEAT ITEMS AND TYPE OF ITEMS
for aid,w,t in zip(aids,weights,types):
aids_temp[aid] += w * type_weight_multipliers[t]
sorted_aids = [k for k,v in aids_temp.most_common(20)]
return sorted_aids
# USE "CLICKS" CO-VISITATION MATRIX
aids2 = list(itertools.chain(*[top_20_clicks[aid] for aid in unique_aids if aid in top_20_clicks]))
# RERANK CANDIDATES
top_aids2 = [aid2 for aid2, cnt in Counter(aids2).most_common(20) if aid2 not in unique_aids]
result = unique_aids + top_aids2[:20 - len(unique_aids)]
# USE TOP20 TEST CLICKS
return result + list(top_clicks)[:20-len(result)]
def suggest_buys(df):
# USE USER HISTORY AIDS AND TYPES
aids=df.aid.tolist()
types = df.type.tolist()
# UNIQUE AIDS AND UNIQUE BUYS
unique_aids = list(dict.fromkeys(aids[::-1] ))
df = df.loc[(df['type']==1)|(df['type']==2)]
unique_buys = list(dict.fromkeys( df.aid.tolist()[::-1] ))
# RERANK CANDIDATES USING WEIGHTS
if len(unique_aids)>=20:
weights=np.logspace(0.5,1,len(aids),base=2, endpoint=True)-1
aids_temp = Counter()
# RERANK BASED ON REPEAT ITEMS AND TYPE OF ITEMS
for aid,w,t in zip(aids,weights,types):
aids_temp[aid] += w * type_weight_multipliers[t]
# RERANK CANDIDATES USING "BUY2BUY" CO-VISITATION MATRIX
aids3 = list(itertools.chain(*[top_20_buy2buy[aid] for aid in unique_buys if aid in top_20_buy2buy]))
for aid in aids3: aids_temp[aid] += 0.1
sorted_aids = [k for k,v in aids_temp.most_common(20)]
return sorted_aids
# USE "CART ORDER" CO-VISITATION MATRIX
aids2 = list(itertools.chain(*[top_20_buys[aid] for aid in unique_aids if aid in top_20_buys]))
# USE "BUY2BUY" CO-VISITATION MATRIX
aids3 = list(itertools.chain(*[top_20_buy2buy[aid] for aid in unique_buys if aid in top_20_buy2buy]))
# RERANK CANDIDATES
top_aids2 = [aid2 for aid2, cnt in Counter(aids2+aids3).most_common(20) if aid2 not in unique_aids]
result = unique_aids + top_aids2[:20 - len(unique_aids)]
# USE TOP20 TEST ORDERS
return result + list(top_orders)[:20-len(result)]
创建提交 CSV
%%time
pred_df_clicks = test_df.sort_values(["session", "ts"]).groupby(["session"]).apply(
lambda x: suggest_clicks(x)
)
pred_df_buys = test_df.sort_values(["session", "ts"]).groupby(["session"]).apply(
lambda x: suggest_buys(x)
)
clicks_pred_df = pd.DataFrame(pred_df_clicks.add_suffix("_clicks"), columns=["labels"]).reset_index()
orders_pred_df = pd.DataFrame(pred_df_buys.add_suffix("_orders"), columns=["labels"]).reset_index()
carts_pred_df = pd.DataFrame(pred_df_buys.add_suffix("_carts"), columns=["labels"]).reset_index()
pred_df = pd.concat([clicks_pred_df, orders_pred_df, carts_pred_df])
pred_df.columns = ["session_type", "labels"]
pred_df["labels"] = pred_df.labels.apply(lambda x: " ".join(map(str,x)))
pred_df.to_csv("validation_preds.csv", index=False)
pred_df.head()
计算验证分数
# FREE MEMORY
del pred_df_clicks, pred_df_buys, clicks_pred_df, orders_pred_df, carts_pred_df
del top_20_clicks, top_20_buy2buy, top_20_buys, top_clicks, top_orders, test_df
_ = gc.collect()
%%time
# COMPUTE METRIC
score = 0
weights = {'clicks': 0.10, 'carts': 0.30, 'orders': 0.60}
for t in ['clicks','carts','orders']:
sub = pred_df.loc[pred_df.session_type.str.contains(t)].copy()
sub['session'] = sub.session_type.apply(lambda x: int(x.split('_')[0]))
sub.labels = sub.labels.apply(lambda x: [int(i) for i in x.split(' ')[:20]])
test_labels = pd.read_parquet('../input/otto-validation/test_labels.parquet')
test_labels = test_labels.loc[test_labels['type']==t]
test_labels = test_labels.merge(sub, how='left', on=['session'])
test_labels['hits'] = test_labels.apply(lambda df: len(set(df.ground_truth).intersection(set(df.labels))), axis=1)
test_labels['gt_count'] = test_labels.ground_truth.str.len().clip(0,20)
recall = test_labels['hits'].sum() / test_labels['gt_count'].sum()
score += weights[t]*recall
print(f'{t} recall =',recall)
print('=============')
print('Overall Recall =',score)
print('=============')
运行结果
clicks recall = 0.5255597442145808
carts recall = 0.4093328152483512
orders recall = 0.6487936598117477
=============
Overall Recall = 0.5646320148830121
=============








![DonkeyCar [02] - 软件配置 - 上位机(windows)](https://img-blog.csdnimg.cn/d4f2b13881f242dfb47d6b616075c574.png)