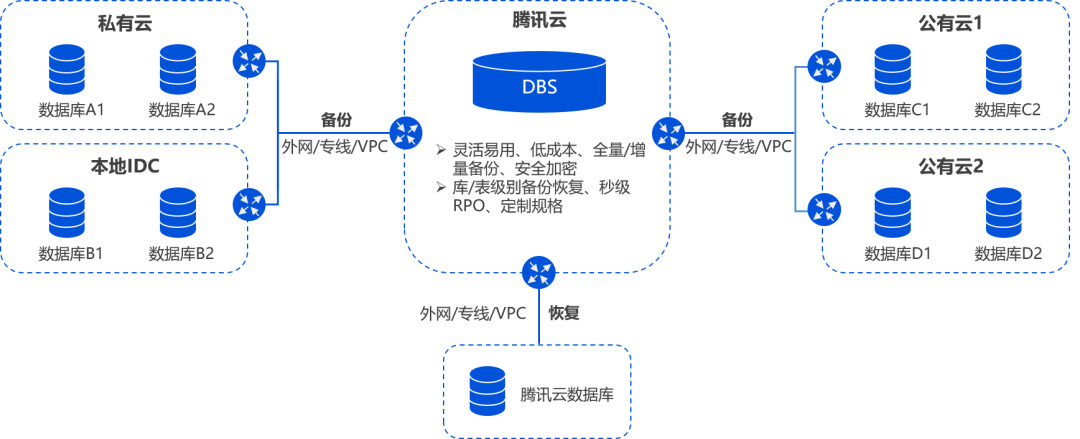
概述
Clickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(MergeTree)中的其他引擎。MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中,数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多,主要特点:
- 存储的数据按主键排序,这使得您能够创建一个小型的稀疏索引来加快数据检索;
- 如果指定了分区键的话,可以使用分区,在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能;
- 支持数据副本,
ReplicatedMergeTree系列的表提供了数据副本功能; - 支持数据采样,需要的话,您可以给表设置一个采样方法。
MergeTree表创建
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
PARTITON BY:选填,表示分区键,用于指定表数据以何种标准进行分区。分区键既可以是单个字段,也可以通过元组的形式指定多个字段,同时也支持使用列表达式。如果不支持分区键,那么 ClickHouse 会生成一个名称为 all 的分区,合理地使用分区可以有效的减少查询时数据量;ORDER BY:必填,表示排序键,用于指定在一个分区内,数据以何种标准进行排序。排序键既可以是单个字段,例如 ORDER BY CounterID,也可以是通过元组声明的多个字段,例如 ORDER BY (CounterID, EventDate)。如果是多个字段,那么会先按照第一个字段排序,如果第一个字段中有相同的值,那么再按照第二个字段排序,依次类推。总之在每个分区内,数据是按照分区键排好序的,但多个分区之间就没有这种关系了;PRIMARY KEY:选填,表示主键,声明之后会依次按照主键字段生成一级索引,用于加速表查询,如果不指定,那么主键默认和排序键相同,所以通常直接使用 ORDER BY 代为指定主键,无须使用 PRIMARY KEY 声明。一般情况下,在每个分区内,数据与一级索引以相同的规则升序排列。和其它关系型数据库不同,MergeTree 允许主键有重复数据,也可以通过 ReplacingMergeTree 实现去重;SAMPLE KEY:选填,抽样表达式。用于声明数据以何种标准进行采样,注意:如果声明了此配置项,那么主键的配置中也要声明同样的表达式;
......
) ENGINE = MergeTree()
ORDER BY (CountID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
-- 抽样表达式需要配合 SAMPLE 子查询使用,该功能对选取抽样数据十分有用
- SETTINGS:选填,用于指定一些额外的参数,以 name=value 的形式出现,主要有以下几种:
index_granularity:对于 MergeTree 而言是一个非常重要的参数,它表示索引的粒度,默认值为 8192。所以 ClickHouse 根据主键生成的索引实际上稀疏索引,默认情况下是每隔 8192 行数据才生成一条索引;index_granularity_bytes:在 19.11 版本之前 ClickHouse 只支持固定大小的索引间隔,由 index_granularity 控制,但是在新版本中增加了自适应间隔大小的特性,即根据每批次写入的数据的体量大小,动态划分间隔大小。而数据的体量大小,则由 index_granularity_bytes 参数控制的,默认为 10M,设置为 0 表示不启用自适应功能;min_index_granularity_bytes- 允许的最小数据粒度,默认值:1024b。该选项用于防止误操作,添加了一个非常低索引粒度的表;min_compress_block_size:表示的就是最小压缩的块大小,默认值为 65536;enbale_mixed_granularity_parts:表示是否开启自适应索引的功能,默认是开启的。
MergeTree存储结构
在这里插入图片描述
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mvsOY7zY-1672198653155)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221216153116757.png)]](https://img-blog.csdnimg.cn/1c619be18f7b440ab5873647b04cb877.png)
分别解释一下它们的作用:
partition:分区目录,里面的各类数据文件(primary.idx、data.mrk、data.bin 等等)都是以分区目录的形式被组织存放的,属于相同分区的数据,最终会被合并到同一个分区目录,而不同分区的数据永远不会被合并在一起;checksums.txt:校验文件,使用二进制的格式进行存储,它保存了余下各类文件(primary.txt、count.txt 等等)的 size 大小以及哈希值,用于快速校验文件的完整性和正确性;columns.txt:列信息文件,使用明文格式存储,用于保存此分区下的列字段信息;count.txt:计数文件,使用明文格式存储,用于记录当前分区下的数据总数。所以后续在查询数据总量的时候可以瞬间返回,因为已经提前记录好了;primary.idx:一级索引文件,使用二进制格式存储,用于存储稀疏索引,一张 MergeTree 表只能声明一次一级索引(通过 ORDER BY 或 PRIMARY KEY)。借助稀疏索引,在查询数据时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度;data.bin:数据文件,使用压缩格式存储,默认为 LZ4 格式,用于存储表的数据。在老版本中每一个列字段都有自己独立的 .bin 数据文件,并以列字段命名,但是在新版本中只有一个 data.bin,也就是合并在一起了;data.mrk:标记文件,使用二进制格式存储,标记文件中保存了 data.bin 文件中数据的偏移量信息,并且标记文件与稀疏索引对齐,因此 MergeTree 通过标记文件建立了稀疏索引(primary.idx)与数据文件(data.bin)之间的映射关系。而在读取数据的时候,首先会通过稀疏索引(primary.idx)找到对应数据的偏移量信息(data.mrk),因为两者是对齐的,然后再根据偏移量信息直接从 data.bin 文件中读取数据;data.mrk3:如果使用了自适应大小的索引间隔,则标记文件会以 data.mrk3 结尾,但它的工作原理和 data.mrk 文件是相同的;partition.dat和minmax_[Column].idx:如果使用了分区键,例如上面的 PARTITION BY toYYYYMM(JoinTime),则会额外生成 partition.dat 与 minmax_JoinTime.idx 索引文件,它们均使用二进制格式存储。partition.dat 用于保存当前分区下分区表达式最终生成的值,而 minmax_[Column].idx 则负责记录当前分区下分区字段对应原始数据的最小值和最大值。举个栗子,假设我们往上面的 user_activity_event 表中插入了 5 条数据,JoinTime 分别 2020-05-05、2020-05-15、2020-05-31、2020-05-03、2020-05-24,显然这 5 条都会进入到同一个分区,因为 toYYYMM 之后它们的结果是相同的,都是 2020-05,而 partition.dat 中存储的就是 2020-05,也就是分区表达式最终生成的值;同时还会有一个 minmax_JoinTime.idx 文件,里面存储的就是 2020-05-03 2020-05-31,也就是分区字段对应的原始数据的最小值和最大值;skp_idx_[IndexName].idx和skp_idx_[IndexName].mrk3:如果在建表语句中指定了二级索引,则会额外生成相应的二级索引文件与标记文件,它们同样使用二进制存储。二级索引在 ClickHouse 中又被称为跳数索引,目前拥有 minmax、set、ngrambf_v1 和 token_v1 四种类型,这些种类的跳数索引的目的和一级索引都相同,都是为了进一步减少数据的扫描范围,从而加速整个查询过程。
常见MergeTree
在ClickHouse的整个体系里面,MergeTree表引擎绝对是一等公民,使用ClickHouse就是在使用MergeTree,这种说法一点也不为过。MergeTree表引擎是一个家族系列,目前整个系列一共包含了14种不同类型的MergeTree。最基础的MergeTree表引擎,向下派生出6个变种表引擎,ReplicatedMergeTree在MergeTree的基础之上增加了分布式协同的能力,当我们为7种MergeTree加上Replicated前缀后,又能组合出7种新的表引擎,这些ReplicatedMergeTree拥有副本协同的能力,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VaRV0Gt9-1672198653156)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221215120031720.png)]](https://img-blog.csdnimg.cn/0c433e802114446e8ce24f666395ce88.png)
- 默认情况: 原生MergeTree表引擎主要用于海量数据分析,支持数据分区、存储有序、主键索引、稀疏索引、数据 TTL 等。MergeTree 支持所有ClickHouse SQL 语法,但是有些功能与 MySQL 并不一致,比如在 MergeTree 中主键并不用于去重;
- 数据去重:为了解决MergeTree 相同主键无法去重的问题,ClickHouse 提供了 ReplacingMergeTree 引擎,用来做去重。ReplacingMergeTree 确保数据最终被去重,但是无法保证查询过程中主键不重复,因为相同主键的数据可能被 shard 到不同的节点,但是 compaction 只能在一个节点中进行,而且 optimize 的时机也不确定;
- 数据更新: 解决删除场景,CollapsingMergeTree 引擎要求在建表语句中指定一个标记列 Sign(插入的时候指定为 1,删除的时候指定为 -1),后台 Compaction 时会将主键相同、Sign 相反的行进行折叠,也即删除,来消除 ReplacingMergeTree 的限制;为了解决 CollapsingMergeTree 乱序写入情况下无法正常折叠问题,VersionedCollapsingMergeTree 表引擎在建表语句中新增了一 列 Version,用于在乱序情况下记录状态行与取消行的对应关系,主键相同,且 Version 相同、Sign 相反的行,在 Compaction 时会被删除;
- 预聚合: 解决聚合场景,ClickHouse 通过 SummingMergeTree 来支持对主键列进行预先聚合。在后台 Compaction 时,会将主键相同的多行进行 sum 求 和,然后使用一行数据取而代之,从而大幅度降低存储空间占用,提升聚合计算性能。同理还有 AggregatingMergeTree用来预聚合平均值;
- 高可用: ReplicatedMergeTree使得以上 MergeTree 家族拥有副本机制,保证高可用,用于生产环境,对于大数据量的表来说不推荐使用,因为副本是基于zk做数据同步的,大数据量会对zk造成巨大压力,成为整个ck整个集群瓶颈。业务可以根据数据重要程度在性能和数据副本之间做选择。
预聚合
在报表场景下大部分查询聚合查询的维度字段是固定,并且没有明细数据的查询需求,这类场合就可以使用SummingMergeTree或是AggregatingMergeTree来加速查询。值得一提的是,通常只有在使用SummingMergeTree或AggregatingMergeTree的时候,才需要同时设置ORDER BY与PRIMARY KEY。
显式的设置PRIMARY KEY,是为了将主键和排序键设置成不同的值,是进一步优化的体现,主键用来过滤,排序键用来数据维度的指标合并,但是如果ORDER BY与PRIMARY KEY不同,PRIMARY KEY必须是ORDER BY的前缀(为了保证分区内数据和主键的有序性)。
SummingMergeTree
求和引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
columns - 包含了将要被汇总的列的列名的元组。可选参数,所选的列必须是数值类型,并且不可位于主键中。
AggregatingMergeTree
该引擎继承自 MergeTree,并改变了数据片段的合并逻辑。 ClickHouse 会将一个数据片段内所有具有相同主键(准确的说是排序键)的行替换成一行,这一行会存储一系列聚合函数的状态,可以使用 AggregatingMergeTree 表来做增量数据统计聚合。可以使用 AggregatingMergeTree 表来做增量数据的聚合统计,包括物化视图的数据聚合。AggregatingMergeTree是SummingMergeTree的加强版,SummingMergeTree能做的是对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = AggregatingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[TTL expr]
[SETTINGS name=value, ...]
数据更新
数据的更新在ClickHouse中有多种实现手段,例如按照分区Partition重新写入、使用Mutation的DELETE和UPDATE查询。使用CollapsingMergeTree或VersionedCollapsingMergeTree也能实现数据更新,这是一种使用标记位,以增代删的数据更新方法,通过增加一个标志字段(例如图中的sigh字段),作为数据有效性的判断依据,在新分区合并后,在同一分区内,ORDER BY条件相同的数据,其标志值为1和-1的数据行会进行抵消。
CollapsingMergeTree对数据写入的顺序是敏感的,它要求标志位需要按照正确的顺序排序。例如按照1,-1的写入顺序是正确的; 而如果按照-1,1的错误顺序写入,CollapsingMergeTree就无法正确抵消。如果在一个多线程并行的写入场景,我们是无法保证这种顺序写入的,此时就需要使用VersionedCollapsingMergeTree了。VersionedCollapsingMergeTree在CollapsingMergeTree基础之上,额外要求指定一个version字段,在分区Merge合并时,它会自动将version字段追加到ORERY BY的末尾,从而保证了标志位的有序性。
参考
- https://www.cnblogs.com/MrYang-11-GetKnow/p/15901514.html
- https://mp.weixin.qq.com/s/0bXEfAN3xRXOWgGKr2GQZg
- https://mp.weixin.qq.com/s/yHUs3ah58SCmoWriZTd3kg
- https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/
![DonkeyCar [02] - 软件配置 - 上位机(windows)](https://img-blog.csdnimg.cn/d4f2b13881f242dfb47d6b616075c574.png)