FastJson是一款性能优异的java序列化和反序列框架,广泛应用于日常开发工作中,也许正是因为作者在设计这款框架时,比较注重性能方面的考量,在框架安全性,空间占用等方面做了一些牺牲。
很不幸小编前两天就遇到了一个使用FastJson导致内容泄漏的问题。下面是小编从发现内存泄漏问题,到问题排查,再到问题修复的整个过程的记录,当各位读者遇到类似问题后,能有所启发。
某天线上告警,系统jvm堆内存使用率过高,后台登录机器发现jvm 比较gc频繁,而且gc后,对内存占用并没有明显减少,初步怀疑出现了"内存泄漏"。
于是,使用jmap命令查看了一下当前堆内存的信息:
jamp -histo <pid> | head -n 20
结果如下图
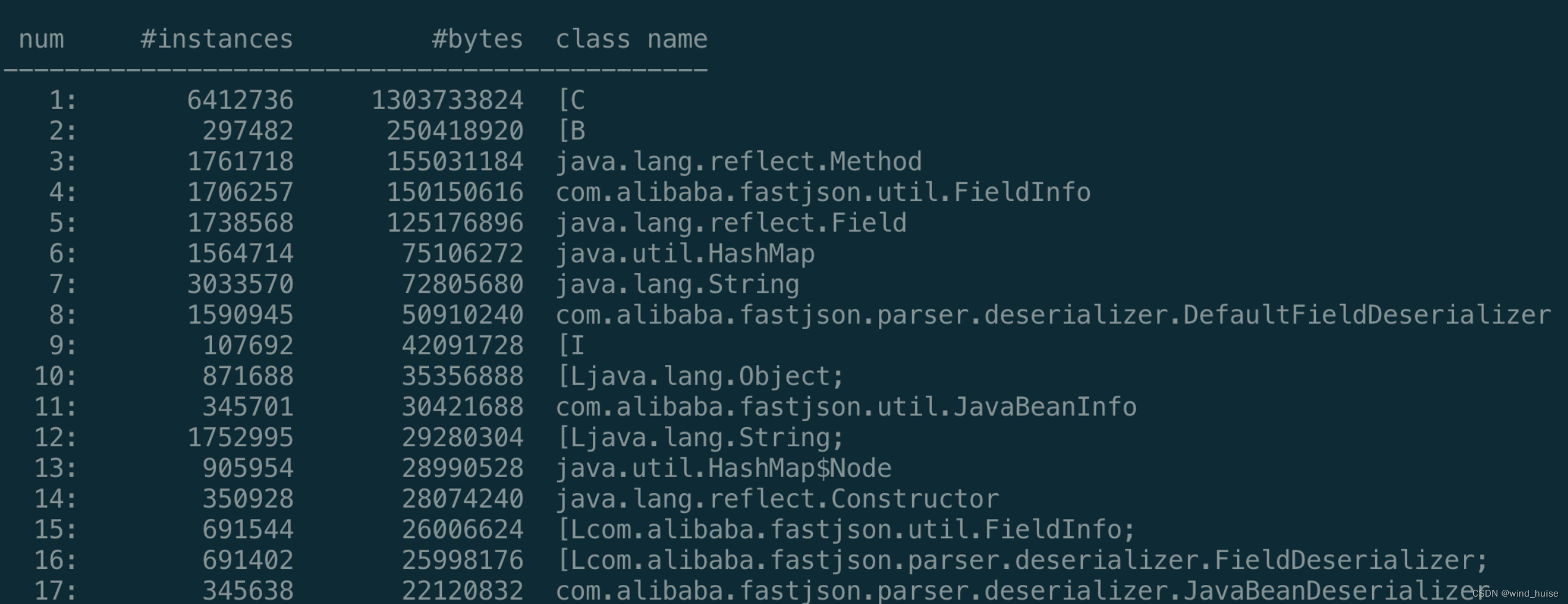
经过多次GC后,上图中的主要对象的数量不降反增,说明系统的确存在内存泄漏问题,而且是FastJson内部的对象。
到这里,第一个问题出现了:上面的FieldInfo,DefaultFieldDeserializer,JavaBeanDeserializer 这些类是干啥的呢?
fastJson反序列化的流程
要了解 FieldInfo,DefaultFieldDeserializer,JavaBeanDeserializer 类的作用,我们需要先了解一下FastJson进行反序列化的流程。
FastJson在将json字符串反序列化成java对象的过程中,会为这个java类生成一个反序列化器,也就是 JavaBeanDeserializer,
同时FastJson还会给这个java类的每个字段都会被封装成一个FeildInfo对象,并且为每个字段也会生成一个 针对字段的反序列化器 DefaultFieldDeserializer。
当对一个java类 进行反序列化时,先用字段反序列化器,反序列化出每个字段,然后再用 JavaBeanDeserializer 反序列化出对象。
上面涉及到的FastJson内部类的关系可以参考下图:
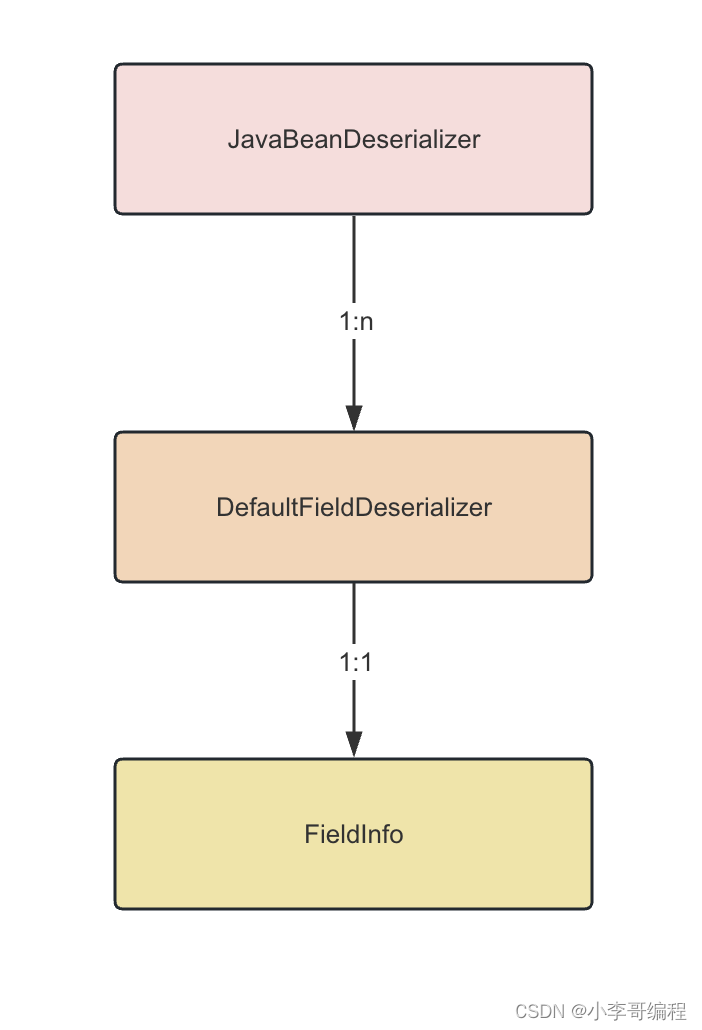
简单来说,就是在反序列化时,一个java类型会对应一个 JavaBeanDeserializer 和 多个 DefaultFieldDeserializer,而且fastJson内部会使用一个类似Map的KV结构 IdentityHashMap 将 类型和 JavaBeanDeserializer进行缓存,防止每次使用时都需要创建,来提升性能。
为什么会产生内存泄露
这一切都看似很合理,但是为什么会出现上图中产生的内存泄漏呢?
在上图中 堆中存在大量的 JavaBeanDeserializer 对象,按照上文讲到的 JavaBeanDeserializer 和类型的对应关系,那么业务系统中 也就会有对应数量的 java类,但是业务系统中其实并没有这么多java类型。
到这里,第二个问题出现了:IdentityHashMap的缓存没有生效吗?
这个时候,我使用了 jmap dump命令将此时内存空间进行了 dump。
jmap -dump:live,format=b,file=dump.bin <pid>
然后使用mat工具分析了一个这么多 JavaBeanDeserializer 对应的java类型都是什么?
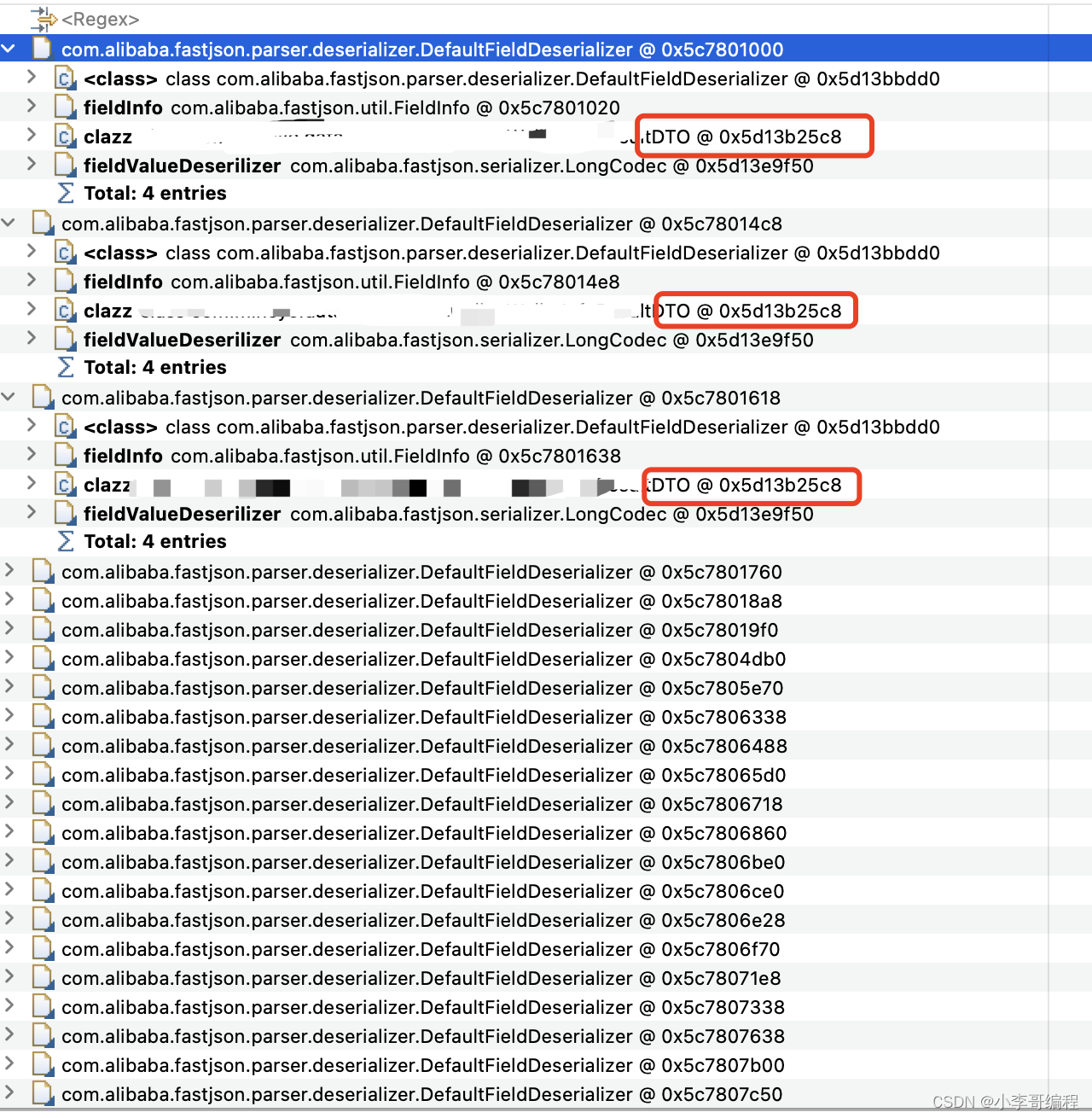
经过分析发现了问题,大量的 JavaBeanDeserializer 对应的 java class 都是一样的。
到这里我们基本上可以得出结论:由于中存在某种问题,产生了java类型一样,但是保存到 IdentityHashMap 时 key不同,导致 IdentityHashMap 认为他们是不同的数据型,导致大量 相同的 JavaBeanDeserializer 保存到了 IdentityHashMap 中,进而也会存在更多的 DefaultFieldDeserializer ,因为这些 JavaBeanDeserializer 一直被 IdentityHashMap 引用,所以无法被gc回收,也就产生了 内存泄漏。
什么情况下产生内存泄露
知道了问题产生的原因,那接下来就要看下业务系统到底存在什么bug,才会产生很多类型相同但对 IdentityHashMap 而言 Key 却不同的问题呢?
在排查业务系统的bug之前,还要确认下 IdentityHashMap 判断两个Key相同的标准是什么?具体可以看一下代码
public boolean put(K key, V value) {
final int hash = System.identityHashCode(key);
final int bucket = hash & indexMask;
for (Entry<K, V> entry = buckets[bucket]; entry != null; entry = entry.next) {
if (key == entry.key) { // 使用 == 进行相同判断
entry.value = value;
return true;
}
}
Entry<K, V> entry = new Entry<K, V>(key, value, hash, buckets[bucket]);
buckets[bucket] = entry;
return false;
}
看以上代码可以发现 IdentityHashMap 判断两个key是否相同的依据是”==“,条件十分苛刻。
接下来就要看一下,业务系统中在进行反序列化时,使用的具体类型是什么,是不是么有满足 上面判断相同的条件呢?
下面是业务系统的伪代码:
private static void des2(String json) {
ParameterizedTypeImpl type = new ParameterizedTypeImpl(new Type[]{SomeInfo.class}, null, CommonVO.class);
CommonVO<SomeInfo> tmpResult = JSON.parseObject(json, type);
System.out.println(tmpResult);
}
果然有问题,每次进行序列化时,都创建了一个新的数据类型,这也就导致了IdentityHashMap缓存失效,罪魁祸首在这里。
如何解决
知道了问题,修改起来就很简单了:将数据类型作为一个对象属性,或者一个类属性,防止每次调用desc2时,都创建一个新的类型,修改后内存泄漏问题,也就迎刃而解了。
不过除了以上解决方案,FastJson也提供了一个解决方案,使用 TypeRefrence,及时每次序列化化都创建一个 对应的对象也不会产生内存泄漏的问题,为什么 TypeRefrence 不会出现问题呢?
源码之下无秘密,以下TypeRefreen的代码
protected TypeReference(){
Type superClass = getClass().getGenericSuperclass();
Type type = ((ParameterizedType) superClass).getActualTypeArguments()[0];
Type cachedType = classTypeCache.get(type);
if (cachedType == null) {
classTypeCache.putIfAbsent(type, type);
cachedType = classTypeCache.get(type);
}
this.type = cachedType;
}
这里使用了一个 ConcurrentMap 对类型进行缓存,我们知道 ConcurrentMap 判断key相同的依据是 key的hashcode是否一样, 而这里的 ParameterizedType对hashcode和equal方法进行进行了重写:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
ParameterizedTypeImpl that = (ParameterizedTypeImpl) o;
// Probably incorrect - comparing Object[] arrays with Arrays.equals
if (!Arrays.equals(actualTypeArguments, that.actualTypeArguments)) return false;
if (ownerType != null ? !ownerType.equals(that.ownerType) : that.ownerType != null) return false;
return rawType != null ? rawType.equals(that.rawType) : that.rawType == null;
}
@Override
public int hashCode() {
int result = actualTypeArguments != null ? Arrays.hashCode(actualTypeArguments) : 0;
result = 31 * result + (ownerType != null ? ownerType.hashCode() : 0);
result = 31 * result + (rawType != null ? rawType.hashCode() : 0);
return result;
}
使用TypeRefrence改写后的代码如下:
private static void des3(String json) {
Type type = new TypeReference<ResultDTO<OEVideoCreateResultDTO>>() {}.getType();
CommonVO<SomeInfo> tmpResult = JSON.parseObject(json, type);
System.out.println(tmpResult);
}
只要数据类型相同,那么key就是相同的,这也就保证了,只要数据类型相同,即使每次都是用新的 TypeRefrence 也不会产生上面的内存泄漏问题。
最后小编还尝试了GSON和 Jackson这两种工具,使用上面问题代码进行了反序列化压测,结果并没有出现内存泄露的问题,你知道为什么吗?




![【算法每日一练]-分块(保姆级教程 篇1)POJ3648](https://img-blog.csdnimg.cn/566be9b69e154f4790a42a7a31f1e92e.png)