论文地址:官方Inner-IoU论文地址点击即可跳转
官方代码地址:官方代码地址-官方只放出了两种结合方式CIoU、SIoU
本位改进地址: 文末提供完整代码块-包括InnerEIoU、InnerCIoU、InnerDIoU等七种结合方式和其Focus变种
一、本文介绍
本文给大家带来的是YOLOv8最新改进,为大家带来最近新提出的InnerIoU的内容同时用Inner的思想结合SIoU、WIoU、GIoU、DIoU、EIOU、CIoU等损失函数,形成 InnerIoU、InnerSIoU、InnerWIoU、等新版本损失函数,同时还结合了Focus和AIpha思想,形成的新的损失函数,其中Inner的主要思想是:引入了不同尺度的辅助边界框来计算损失,(该方法在处理非常小目标的检测任务时表现出良好的性能(但是在其它的尺度检测时也要比普通的损失要好)。文章会详细探讨这些损失函数如何提高YOLOv8在各种检测任务中的性能,包括提升精度、加快收敛速度和增强模型对复杂场景的适应性。
专栏回顾: YOLOv8改进有效涨点专栏->持续复现各种最新机制
目录
一、本文介绍
二、各种损失函数的基本原理
2.1 交集面积和并集面积
2.2 IoU
2.3 SIoU
2.4 WioU
2.5 GIoU
2.6 DIoU
2.7 EIoU
2.8 CIoU
2.9 FocusLoss
三、InnerIoU等损失函数代码块
3.1 代码一
3.2 代码二
四、添加InnerIoU等损失函数到模型中
五、总结
二、各种损失函数的基本原理
2.1 交集面积和并集面积
在理解各种损失函数之前我们需要先来理解一下交集面积和并集面积,在数学中我们都学习过集合的概念,这里的交集和并集的概念和数学集合中的含义是一样的。

2.2 IoU
论文地址:IoU Loss for 2D/3D Object Detectio
适用场景:普通的IoU并没有特定的适用场景
概念: 测量预测边界框和真实边界框之间的重叠度(最基本的边界框损失函数,后面的都是居于其进行计算)。
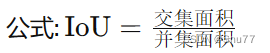
2.3 SIoU
论文地址:SIoU: More Powerful Learning for Bounding Box Regression
适用场景:适用于需要高精度边界框对齐的场景,如精细的物体检测和小目标检测。
概念:SIoU损失通过融入角度考虑和规模敏感性,引入了一种更为复杂的边界框回归方法,解决了以往损失函数的局限性,SIoU损失函数包含四个组成部分:角度损失、距离损失、形状损失和第四个未指定的组成部分。通过整合这些方面,从而实现更好的训练速度和预测准确性。

2.4 WioU
论文地址:WIoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism
适用场景:适用于需要动态调整损失焦点的情况,如不均匀分布的目标或不同尺度的目标检测。
概念:引入动态聚焦机制的IoU变体,旨在改善边界框回归损失。
![]()
2.5 GIoU
论文地址:GIoU: A Metric and A Loss for Bounding Box Regression
适用场景:适合处理有重叠和非重叠区域的复杂场景,如拥挤场景的目标检测。
概念:在IoU的基础上考虑非重叠区域,以更全面评估边界框

2.6 DIoU
论文地址:DIoU: Faster and Better Learning for Bounding Box Regression
适用场景:适用于需要快速收敛和精确定位的任务,特别是在边界框定位精度至关重要的场景。
概念:结合边界框中心点之间的距离和重叠区域。

2.7 EIoU
论文地址:EIoU:Loss for Accurate Bounding Box Regression
适用场景:可用于需要进一步优化边界框对齐和形状相似性的高级场景。
概念:EIoU损失函数的核心思想在于提高边界框回归的准确性和效率。它通过以下几个方面来优化目标检测:
1. 增加中心点距离损失:通过最小化预测框和真实框中心点之间的距离,提高边界框的定位准确性。
2. 考虑尺寸差异:通过惩罚宽度和高度的差异,EIoU确保预测框在形状上更接近真实框。
3. 结合最小封闭框尺寸:将损失函数与包含预测框和真实框的最小封闭框的尺寸相结合,从而使得损失更加敏感于对象的尺寸和位置。
EIoU损失函数在传统IoU基础上增加了这些考量,以期在各种尺度上都能获得更精确的目标定位,尤其是在物体大小和形状变化较大的场景中。
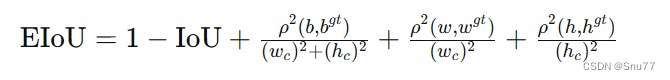
2.8 CIoU
论文地址:CIoU:Enhancing Geometric Factors in Model Learning
适用场景:适合需要综合考虑重叠区域、形状和中心点位置的场景,如复杂背景或多目标跟踪。
概念:综合考虑重叠区域、中心点距离和长宽比。

2.9 FocusLoss
论文地址:Focal Loss for Dense Object Detection
适用场景:适用于需要高精度边界框对齐的场景,如精细的物体检测和小目标检测。
Focal Loss由Kaiming He等人在论文《Focal Loss for Dense Object Detection》中提出,旨在解决在训练过程中正负样本数量极度不平衡的问题,尤其是在一些目标检测任务中,背景类别的样本可能远远多于前景类别的样本。
Focal Loss通过修改交叉熵损失,增加一个调整因子,这个因子降低了那些已经被正确分类的样本的损失值,使得模型的训练焦点更多地放在难以分类的样本上。这种方式特别有利于提升小目标或者在复杂背景中容易被忽视的目标的检测性能。简而言之,Focal Loss让模型“关注”(或“专注”)于学习那些对提高整体性能更为关键的样本。
三、InnerIoU等损失函数代码块
3.1 代码一
此代码块块的基础版本来源于Github的开源版本,我在其基础上将Inner的思想加入其中形成了各种Inner的思想同时融合各种改良版本的损失函数形成对应版本的InnerIoU、InnerCIoU等损失函数。
class Inner_WIoU_Scale:
''' monotonous: {
None: origin v1
True: monotonic FM v2
False: non-monotonic FM v3
}
momentum: The momentum of running mean'''
iou_mean = 1.
monotonous = False
_momentum = 1 - 0.5 ** (1 / 7000)
_is_train = True
def __init__(self, iou):
self.iou = iou
self._update(self)
@classmethod
def _update(cls, self):
if cls._is_train: cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + \
cls._momentum * self.iou.detach().mean().item()
@classmethod
def _scaled_loss(cls, self, gamma=1.9, delta=3):
if isinstance(self.monotonous, bool):
if self.monotonous:
return (self.iou.detach() / self.iou_mean).sqrt()
else:
beta = self.iou.detach() / self.iou_mean
alpha = delta * torch.pow(gamma, beta - delta)
return beta / alpha
return 1
def bbox_iou(box1, box2, x1y1x2y2=True, ratio=1, inner_GIoU=False, inner_DIoU=False, inner_CIoU=False, inner_SIoU=False,
inner_EIoU=False, inner_WIoU=False, Focal=False, alpha=1, gamma=0.5, scale=False, eps=1e-7):
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
# IoU #IoU #IoU #IoU #IoU #IoU #IoU #IoU #IoU #IoU #IoU
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
union = w1 * h1 + w2 * h2 - inter + eps
# Inner-IoU #Inner-IoU #Inner-IoU #Inner-IoU #Inner-IoU #Inner-IoU #Inner-IoU
inner_b1_x1, inner_b1_x2, inner_b1_y1, inner_b1_y2 = x1 - w1_ * ratio, x1 + w1_ * ratio, \
y1 - h1_ * ratio, y1 + h1_ * ratio
inner_b2_x1, inner_b2_x2, inner_b2_y1, inner_b2_y2 = x2 - w2_ * ratio, x2 + w2_ * ratio, \
y2 - h2_ * ratio, y2 + h2_ * ratio
inner_inter = (torch.min(inner_b1_x2, inner_b2_x2) - torch.max(inner_b1_x1, inner_b2_x1)).clamp(0) * \
(torch.min(inner_b1_y2, inner_b2_y2) - torch.max(inner_b1_y1, inner_b2_y1)).clamp(0)
inner_union = w1 * ratio * h1 * ratio + w2 * ratio * h2 * ratio - inner_inter + eps
inner_iou = inner_inter / inner_union # inner_iou
if scale:
self = Inner_WIoU_Scale(1 - (inner_inter / inner_union))
if inner_CIoU or inner_DIoU or inner_GIoU or inner_EIoU or inner_SIoU or inner_WIoU:
cw = inner_b1_x2.maximum(inner_b2_x2) - inner_b1_x1.minimum(
inner_b2_x1) # convex (smallest enclosing box) width
ch = inner_b1_y2.maximum(inner_b2_y2) - inner_b1_y1.minimum(inner_b2_y1) # convex height
if inner_CIoU or inner_DIoU or inner_EIoU or inner_SIoU or inner_WIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = (cw ** 2 + ch ** 2) ** alpha + eps # convex diagonal squared
rho2 = (((inner_b2_x1 + inner_b2_x2 - inner_b1_x1 - inner_b1_x2) ** 2 + (
inner_b2_y1 + inner_b2_y2 - inner_b1_y1 - inner_b1_y2) ** 2) / 4) ** alpha # center dist ** 2
if inner_CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha_ciou = v / (v - inner_iou + (1 + eps))
if Focal:
return inner_iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)), torch.pow(
inner_inter / (inner_union + eps),
gamma) # Focal_CIoU
else:
return inner_iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)) # CIoU
elif inner_EIoU:
rho_w2 = ((inner_b2_x2 - inner_b2_x1) - (inner_b1_x2 - inner_b1_x1)) ** 2
rho_h2 = ((inner_b2_y2 - inner_b2_y1) - (inner_b1_y2 - inner_b1_y1)) ** 2
cw2 = torch.pow(cw ** 2 + eps, alpha)
ch2 = torch.pow(ch ** 2 + eps, alpha)
if Focal:
return inner_iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2), torch.pow(
inner_inter / (inner_union + eps),
gamma) # Focal_EIou
else:
return inner_iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2) # EIou
elif inner_SIoU:
# SIoU Loss https://arxiv.org/pdf/2205.12740.pdf
s_cw = (inner_b2_x1 + inner_b2_x2 - inner_b1_x1 - inner_b1_x2) * 0.5 + eps
s_ch = (inner_b2_y1 + inner_b2_y2 - inner_b1_y1 - inner_b1_y2) * 0.5 + eps
sigma = torch.pow(s_cw ** 2 + s_ch ** 2, 0.5)
sin_alpha_1 = torch.abs(s_cw) / sigma
sin_alpha_2 = torch.abs(s_ch) / sigma
threshold = pow(2, 0.5) / 2
sin_alpha = torch.where(sin_alpha_1 > threshold, sin_alpha_2, sin_alpha_1)
angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - math.pi / 2)
rho_x = (s_cw / cw) ** 2
rho_y = (s_ch / ch) ** 2
gamma = angle_cost - 2
distance_cost = 2 - torch.exp(gamma * rho_x) - torch.exp(gamma * rho_y)
omiga_w = torch.abs(w1 - w2) / torch.max(w1, w2)
omiga_h = torch.abs(h1 - h2) / torch.max(h1, h2)
shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)
if Focal:
return inner_iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha), torch.pow(
inner_inter / (inner_union + eps), gamma) # Focal_SIou
else:
return inner_iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha) # SIou
elif inner_WIoU:
if Focal:
raise RuntimeError("WIoU do not support Focal.")
elif scale:
return getattr(Inner_WIoU_Scale, '_scaled_loss')(self), (1 - inner_iou) * torch.exp(
(rho2 / c2)), inner_iou # WIoU https://arxiv.org/abs/2301.10051
else:
return inner_iou, torch.exp((rho2 / c2)) # WIoU v1
if Focal:
return inner_iou - rho2 / c2, torch.pow(inner_inter / (inner_union + eps), gamma) # Focal_DIoU
else:
return inner_iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
if Focal:
return inner_iou - torch.pow((c_area - inner_union) / c_area + eps, alpha), torch.pow(
inner_inter / (inner_union + eps),
gamma) # Focal_GIoU https://arxiv.org/pdf/1902.09630.pdf
else:
return inner_iou - torch.pow((c_area - inner_union) / c_area + eps,
alpha) # GIoU https://arxiv.org/pdf/1902.09630.pdf
if Focal:
return inner_iou, torch.pow(inner_inter / (inner_union + eps), gamma) # Focal_IoU
else:
return inner_iou # IoU3.2 代码二
代码块二此处是使用Focus时候需要修改的代码,如果不适用则不需要修改下面的代码,因为利用Focus机制时候返回的类型是元组所以需要额外的处理。
if type(iou) is tuple:
if len(iou) == 2:
# Focus Loss 时返回的是元组类型,进行额外处理
loss_iou = ((1.0 - iou[0]) * iou[1].detach() * weight).sum() / target_scores_sum
else:
loss_iou = (iou[0] * iou[1] * weight).sum() / target_scores_sum
else:
# 正常的损失函数
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum四、添加InnerIoU等损失函数到模型中
添加的方法和基础版本的各种损失函数的方法是一样的,网上的教程已经满天飞了,考虑到大家有的人已经会了有的人还不会,所以这里提供我的另一篇博客里面包括YOLOv8改进C2f、Conv、Neck、损失函数、Bottleneck、检测头等各种YOLOv8能够改进的地方的详细过程讲解。所以如果你已经会了可以直接跳过此处,如果你还不会我建议你可以看下面的文章我相信能够帮助到你。
修改教程: YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
五、总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
本专栏其它内容(持续更新)
YOLOv8改进 | DAttention (DAT)注意力机制实现极限涨点
YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
YOLOv8改进 | ODConv附修改后的C2f、Bottleneck模块代码
YOLOv8改进有效涨点系列->手把手教你添加动态蛇形卷积(Dynamic Snake Convolution)
YOLOv8性能评估指标->mAP、Precision、Recall、FPS、IoU
YOLOv8改进有效涨点系列->适合多种检测场景的BiFormer注意力机制(Bi-level Routing Attention)
YOLOv8改进有效涨点系列->多位置替换可变形卷积(DCNv1、DCNv2、DCNv3)
详解YOLOv8网络结构/环境搭建/数据集获取/训练/推理/验证/导出/部署