参考 & 鸣谢
- CppHeaderParser - 官方文档
- Python解析C++头文件
- win10直接获得文件绝对路径的方法总结
目的
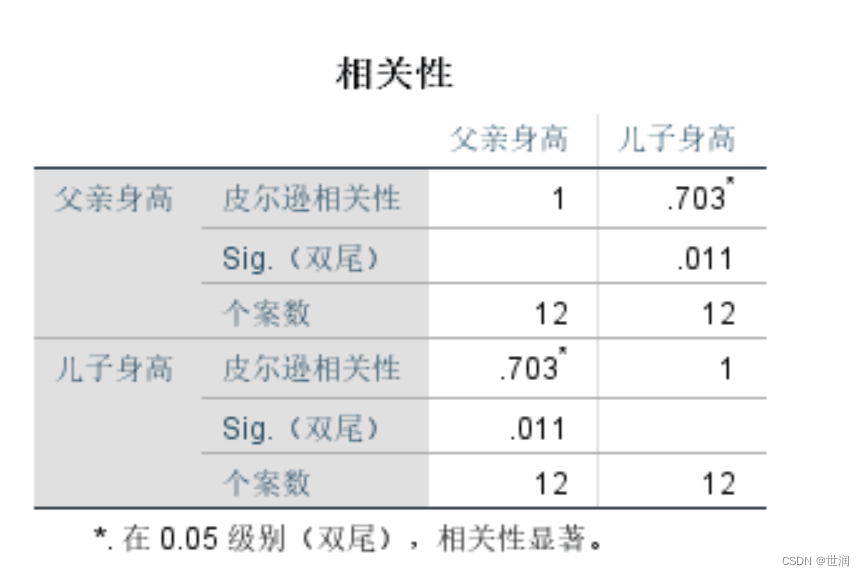
- 解析CPP头文件中的类定义,获取UML中的属性。用于画UML类图。如下所示格式,图片来源-链接

- 即获取,类名,成员函数,成员方法。
- 后置函数返回值、参数类型。
- +、-、# 区分不同的访问权限,public,private,protected。
- 使用Python的CppHeaderPaser库完成CPP文件中类定义解析。
代码实现
import sys
import CppHeaderParser
import os
import shutil
import os
import re
type_hash = {'private' : '- ','protected' : '# ','public' : '+ '}
def get_mem_var(parse_conent,cur_class,target_type):
for class_private_mem_var in parse_conent.classes[cur_class]['properties'][target_type]:
# 组装private属性
tmp_str = type_hash[target_type] + class_private_mem_var['name'] + ' : ' + class_private_mem_var['type']
print(tmp_str)
def get_mem_func(parse_conent,cur_class,target_type):
# 遍历方法 - public
for class_mem_func in parse_conent.classes[class_name]['methods'][target_type]:
tmp_str = ''
tmp_str = type_hash[target_type] + class_mem_func['name'] + '('
# 遍历函数参数
if len(class_mem_func['parameters']): # 有参数
p_cnt = len(class_mem_func['parameters'])
tmp_cnt = 0
for one_param in class_mem_func['parameters']: # 一个函数的多个参数,分多行
tmp_cnt = tmp_cnt + 1
tmp_str = tmp_str + one_param['name'] + " : " + one_param['type']
if tmp_cnt != p_cnt:
tmp_str = tmp_str + ' , '
tmp_str = tmp_str + ')' + " : "
# 组装返回值
tmp_str = tmp_str + class_mem_func['rtnType']
print(tmp_str)
if __name__ == '__main__':
while True:
# file = input("文件路径: ")
file = input("请输入头文件路径: ")
dest_dir_path = './'
# 源文件是否存在
if os.path.exists(file):
print()
# 复制文件
shutil.copy2(file,dest_dir_path)
# 新的目标路径
(file_path,file_name) = os.path.split(file)
file = dest_dir_path + file_name
# 拷贝的临时文件是否存在
if os.path.exists(file):
# 去除新文件中的中文
tmp_new_content = ''
with open(file,"r+",encoding='utf-8') as f:
old_file_content = f.read()
# print(old_file_content)
tmp_new_content = re.sub('[\u4e00-\u9fa5]','',old_file_content)
# 重新打开,清空写入
with open(file,"w+",encoding='utf-8') as f:
f.write(tmp_new_content)
# 解析
parse_conent = CppHeaderParser.CppHeader(file)
# 遍历每个解析到的类
for class_name in parse_conent.classes.keys():
# 当前类
print("###################################################")
print(class_name + '\n')
# 获取属性 - private - protected - public
get_mem_var(parse_conent, class_name, 'private')
get_mem_var(parse_conent, class_name, 'protected')
get_mem_var(parse_conent, class_name, 'public')
print()
# 获取方法 - private - protected - public
get_mem_func(parse_conent, class_name, 'private')
get_mem_func(parse_conent, class_name, 'protected')
get_mem_func(parse_conent, class_name, 'public')
# 分割线,划分不同类
print()
print("###################################################")
else:
print("拷贝文件不存在")
else:
print("源文件文件不存在")
# 结束后删除临时文件
os.remove(file)
使用
获取文件路径
- shift + 右键选择文件,点击复制文件路径,即可获取该文件的绝对路径。
- 或者使用VSCode,Clion,右键选择文件,复制文件路径。
启动程序,输入路径即可。
- 这个类内容太多了,这里就截取了一部分。
- 类名,成员变量,成员方法之间用空行隔开。多个类直接用#隔开。
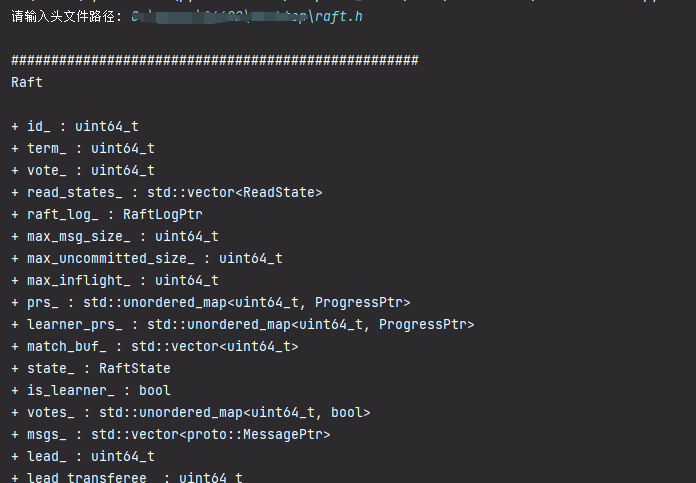
存在问题
- 部分新特性解析错误,例如:
// 定时触发的回调函数
std::function<void()> tick_;
// 处理消息的回调函数
std::function<Status(proto::MessagePtr)> step_;
会识别为成员函数。

- 不完善的地方
- 构造函数析构函数的,返回值类型,为void,应该为空
- 析构函数检测不到波浪号~

- CppHeaderParser打开文件编码问题(已经解决),会提示如下报错
headerFileStr = "".join(fd.readlines())
UnicodeDecodeError: 'gbk' codec can't decode byte 0x8c in position 830: illegal multibyte sequence
原因: 给定文件中有GBK无法表示的字符。例如中文。
解决方法(已在上述代码中使用): 拷贝文件,去掉其中的中文字符,保存文件,用GBK编码集保存。