NLP作为一个领域为基础模型开辟了道路。虽然这些模型在标准基准测试中占据主导地位,但这些模型目前获得的能力与那些将语言描述为人类交流和思维的复杂系统的能力之间存在明显的差距。针对这一点,我们强调语言变异的全部范围(例如,不同的风格、方言、语言),这带来了机遇和挑战,因为有些变体的数据有限。此外,儿童语言习得比基础模型的训练更有样本效率;我们研究了文本和接地之外的信号如何有助于弥合这一差距。语言的这两个特点为今后的基础模型研究提供了明确的方向。
1、人类语言的本质
语言是大多数人类交流和互动的基础。然而,它不仅仅是人类实现共同目标的一种手段:语言是人类思想的核心,是社会和情感关系如何形成的核心,是我们如何在社会和个人中识别自己的核心,也是人类如何记录知识和发展社会智能的核心。口语或手语出现在每个人类社会中,世界上的语言在表达和构建它们所传达的信息的方式上都是难以置信的多样性,同时在语言的丰富性方面也表现出令人惊讶的一致性[Comrie 1989]。语言是非常复杂而有效的系统,儿童在很短的时间内不断获得,并且不断发展并包含语言社区不断变化的需求和条件。由于语言在人类活动中的中心地位,语言理解和生成是人工智能研究的关键要素。自然语言处理(NLP)是人工智能中与语言相关的子领域,与自动语音识别(ASR)和文本到语音(TTS)的相关领域一起,其目标是让计算机能够以与人类相同的方式理解和生成人类语言。
到2021年为止,NLP一直是受基础模型影响最深远的领域。第一代基础模型展示了令人印象深刻的各种语言能力,以及对各种语言情况的惊人适应性。自2018年引入早期的基础模型埃尔莫[Peters et al. 2018]和BERT [Devlin et al. 2019]以来,NLP领域主要围绕使用和理解基础模型展开。该领域已经转向使用基础模型作为主要工具,转向更广泛的语言学习作为中心方法和目标。
在本文中,我们将回顾NLP中基础模型最近的成功,详细介绍基础模型如何改变训练语言机器学习模型的整体过程和心态,并讨论基础模型在应用于更广泛的语言和更现实、更复杂的语言情况时所面临的一些理论和实践挑战。
2、基础模型对NLP的影响。
基础模型对NLP领域产生了巨大的影响,现在是大多数NLP系统和研究的核心。在第一个层面上,许多基础模型都是熟练的语言生成器:例如,Clark等人[2021]证明,非专家很难区分由GPT-3编写的简短英语文本和由人类编写的文本。然而,基础模型在NLP中最具影响力的特征不是它们的原始生成能力,而是它们令人惊讶的通用性和适应性:单个基础模型可以以不同的方式进行调整,以实现许多语言任务。
NLP领域历来专注于为具有挑战性的语言任务定义和设计系统,其愿景是擅长这些任务的模型将为下游应用程序带来胜任的语言系统。NLP任务包括针对整个句子或文档的分类任务(例如,情感分类,如预测电影评论是正面的还是负面的),序列标记任务,其中我们对句子或文档中的每个单词或短语进行分类(例如,预测每个词是动词还是名词,或者哪个词的跨度指的是人还是组织),跨度关系分类,(例如,关系提取或解析,如人和位置是否通过“当前居住地”关系链接,或动词和名词是否通过“主语-动词”关系链接)和生成任务,产生条件化的新文本强烈地依赖于输入(例如,生成文本的翻译或摘要,识别或生成语音,或在对话中做出响应)[Jurafsky和Martin 2009]。在过去,NLP任务有不同的研究社区,开发特定于任务的架构,通常基于不同模型的管道,每个模型执行语言子任务,如标记分割,句法分析或共指消解。
相比之下,执行每个任务的主要现代方法是使用单个基础模型,并使用相对少量的特定于每个任务的注释数据(情感分类,命名实体标记,翻译,摘要)对其进行稍微调整,以创建适应模型。事实证明,这是一种非常成功的方法:对于上面描述的绝大多数任务,稍微适应任务的基础模型大大优于以前的模型或专门为执行该任务而构建的模型管道。仅举一个例子,在2018年回答开放式科学问题的最佳系统,在基础模型之前,可以在纽约摄政8年级科学考试中获得73.1%。一年后的2019年,经过调整的基础模型得分为91.6% [Clark et al. 2019]。
大量训练生成语言的基础模型的出现构成了NLP中语言生成角色的重要转变。直到2018年左右,生成通用语言的问题被认为是非常困难的,除非通过其他语言子任务,否则基本上无法实现[巴黎et al. 2013]。相反,NLP研究主要集中在语言分析和理解文本上。
现在,可以用简单的语言生成目标来训练高度一致的基础模型,比如“预测这个句子中的下一个单词”。这些生成模型现在构成了完成语言机器学习的主要工具-包括曾经被认为是生成先决条件的分析和理解任务。模型也导致了对语言生成任务(如摘要和对话生成)的研究的繁荣。
基础模型范式的兴起已经开始在口语和书面语中发挥类似的作用。现代自动语音识别(ASR)模型,如wav2vec 2.0,仅在语音音频的大型数据集上进行训练,然后在音频上进行调整,并与ASR任务相关联[Baevski et al. 2020]。
由于基础模型范式带来的变化,NLP研究和实践的重点已经从为不同任务定制架构转移到探索如何最好地利用基础模型。对适应方法的研究已经蓬勃发展,基础模型的惊人成功也导致研究兴趣转向分析和理解基础模型。基础模型所展示的成功生成也导致了对语言生成任务(如摘要和对话生成)的研究的蓬勃发展。
3、语言变异和多语言性
尽管基础模型在预训练中获得的语言知识方面具有惊人的通用性,但这种适应性存在局限性:目前尚不清楚当前的基础模型在处理语言变化方面有多成功。语言差异很大。除了世界上有成千上万种不同的语言之外,即使在一种语言或一个说话者内部,语言也是不同的。举几个例子,非正式对话的表现与书面语言不同,人们与朋友交谈时使用的语法结构与权威人士交谈时使用的语法结构非常不同,同一语言中的使用者社区使用不同的方言。社会和政治因素嵌入在如何看待和评价语言变化,以及NLP研究中有多少不同的品种(例如,参见Blodgett和奥康纳[2017]关于非裔美国人英语NLP的失败)。由于基础模型具有学习语言信息和灵活适应这些知识的巨大能力,因此它有望扩展NLP以涵盖更多的语言多样性。这仍然是一个开放的研究问题,以了解是否有可能建立基础模型,这些模型可以稳健而公平地表示语言及其主要和微妙的变化,对使每个语言变体不同的因素给予同等的权重和敏锐度[提出和解决这个问题的研究包括Ponti et al. 2019; Bender 2011; Joshi et al. 2020]。
随着英语基础模型的成功,多语言基础模型已经发布,以将成功扩展到非英语语言。对于世界上6,000多种语言中的大多数语言,可用的文本数据不足以训练大规模的基础模型。举给予一个例子,有超过6500万人说西非语言Fula,但Fula中的NLP资源很少[Nguer et al. 2020]。多语言基础模型通过同时对多种语言进行联合训练来解决这个问题。迄今为止的多语言基础模型(mBERT,mT5,XLM-R)都是在大约100种语言上训练的[Devlin et al. 2019; Goyal et al. 2021; Xue et al. 2020]。联合多语言训练依赖于合理的假设,即语言之间共享的结构和模式可以导致从高资源语言到低资源语言的共享和转移,使我们无法训练独立模型的语言的基础模型成为可能。使用和分析多语言基础模型的实验表明,在多语言基础模型中,不同语言之间的传输和并行编码确实数量惊人[Wu和Dredze 2019; Choenni和Shutova 2020; Pires等人2019; Libovick`y等人2019; Chi等人2020; Papadimitriou等人2021; Cao等人,2019年]。

图 目前,世界上只有一小部分语言在基础模型中得到了体现。世界上有超过6,000种语言,由于构成一种独立语言的固有不确定性,估计数各不相同[Nordhoff and Hammarström 2011]。这张地图显示了世界上的语言,每个点代表一种语言,其颜色表示顶级语言家族。数据来自Glottolog [Hammarström et al. 2021]。我们在地图上标注了一些语言作为例子。
然而,这些模型在多大程度上是强大的多语言仍然是一个悬而未决的问题。目前尚不清楚在这些数据上训练的模型有多少可以代表与英语截然不同的语言方面,或者几乎没有语言资源可用,以及它们明显的多语言性能是否更多地依赖于同化[Lauscher et al. 2020; Virtanen et al. 2019; Artetxe et al. 2020]。多语言模型在训练数据中与最高资源语言相似的语言中表现出更好的性能,并且已经表明多语言模型中的语言竞争模型参数,因此不清楚单个模型中可以容纳多少变化[Wang et al. 2020 d]。一个突出的问题源于我们用来训练多语言基础模型的数据:在许多多语种语料库中,英语数据不仅比低资源语言的数据丰富,而且通常更干净、更广泛,并包含展示更多语言深度和复杂性的示例[Caswell et al. 2021](见Nekoto et al. [2020]关于构建参与性和强大的多语言数据集)。然而,答案并不仅仅在于创建更平衡的语料库:语言变异的轴太多了,创建一个在所有方面都平衡和具有代表性的语料库是不可行的。基础模型的未来、多功能性和公平性都取决于稳健地处理语言变异,尽管数据不平衡[例如,Oren等人,2019年]。
当前的原始形式的多语言基础模型,以及天真的无监督多语言训练方法,可能无法完全模拟语言和语言变体的微妙之处。尽管如此,它们仍然对某些多语言应用程序有用,例如通过为原始训练集中没有的低资源语言调整多语言模型[Wang et al. 2020 b]。此外,(非公开)GShard神经机器翻译模型的结果显示,对于最低资源语言,单语基线的收益最大,收益随着模型大小的增加而增加[Lepikhin et al. 2021]。研究界应该批判性地研究基础模型如何处理语言变异,了解基础模型在为NLP带来公平和代表性方面的局限性,而不是停留在推广消除语言变异的基础模型上,并在其训练数据中主要符合语言多数。
4、人类语言习得的启示
尽管基础模型在创建更像人类的自然语言处理系统方面取得了巨大的进步,但它们获得的语言系统以及学习过程仍然与人类语言有很大的不同。了解机器和人类语言学习之间的这种差距的影响是发展一个了解基础模型的语言限制和可能性的研究社区的必要组成部分。
人类语言习得非常有效:像GPT-3这样的基础模型训练的语言数据比大多数人听到或阅读的语言数据要多三到四个数量级,当然也比儿童在语言能力成熟时接触的语言数据要多得多。基础模型和人类语言习得之间的一个显著差异是人类语言基于真实的世界[Saxton 2017]。例如,婴儿和看护者在语言发展过程中会指向物体[Colonnesi et al. 2010],婴儿在学习语言系统的许多其他方面之前,会学习指代常见物体的单词的基础含义[Bergelson and Swingley 2012]。另一方面,NLP中使用的大多数基础模型都从原始的、无基础的文本的分布信息中学习,并且(与人类学习者相反)Zhang et al. [2021]表明,RoBERTa模型在可用的意义之前表达抽象的句法特征。强大的无基础统计学习确实也存在于婴儿中[Saffran et al. 1996],因此它无疑是习得的一个重要因素。尽管如此,推进基础模型的基础语言学习仍然是接近人类习得效率的重要方向[Dupoux 2018; Tan和Bansal 2020; Zellers等人。另一个重要的方向是研究基础模型中的归纳偏见,以及它们如何与人类思维中的归纳偏见相关联,无论是语言学习的特定偏见还是人类认知的一般偏见[Linzen and Baroni 2021]。虽然人类大脑可能在结构上更加专业化,以实现有效的语言习得,但基础模型不是白板学习者[Baroni 2021],理解和调整这些语言归纳偏见是基础模型研究的重要未来方向。
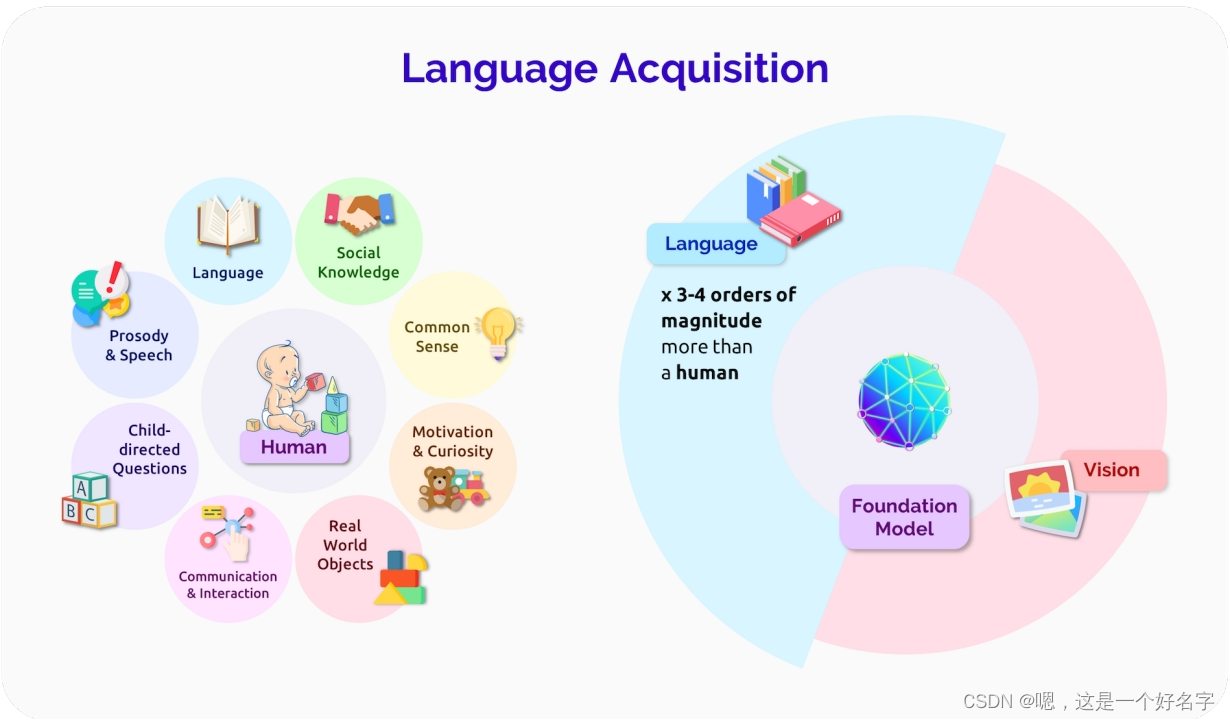
图 人类语言习得和基础模型。虽然人类大脑和基础模型之间肯定存在不同的归纳偏差,但它们学习语言的方式也非常不同。最显著的是,人类与他们有各种需求和愿望的物理和社会世界交互,而基础模型主要观察和建模其他人产生的数据
语言习得效率的一个重要因素是人类获得了一个系统的和可概括的语言系统。虽然关于人类语言系统进行什么类型的理论抽象有许多不同的理论[例如,Comrie 1989; Chomsky 2014; Croft 2001; Jackendoff 2011],人们普遍认为,人类学习语言的方式,使他们能够轻松地插槽新知识到现有的抽象和富有成效地创建新的语法句子。例如,一个10岁的孩子已经获得了很多关于他们的语言是如何工作的抽象概念,尽管他们产生的实际单词和结构在接下来的10年里会发生巨大的变化。另一方面,基础模型通常没有获得我们期望从人类那里获得的系统抽象。例如,当一个基础模型一次准确地产生一个语言结构时,不能保证该结构的未来使用将是基本一致的,特别是在主题发生重大领域转移之后[研究基础模型在系统性方面的局限性的工作示例包括Lake和Baroni 2018; Kim和Linzen 2020; Bahdanau等人2018; Chaabouni等人,2021年]。NLP面临的挑战是,在获取基础模型时开发某种系统性,而不是回归到过于依赖严格语言规则的系统。
语言学习持续了说话者的一生:人类语言的语法不断演变,人类灵活地适应新的语言环境[Sankoff 2018]。例如,当新的术语和概念出现在成年人的生活中时,他们可以相对容易地在语法句子中使用它们,并且人类经常调整他们的语法模式以适应不同的社会群体[Rickford et al. 1994]。另一方面,基础模型的语言系统主要由训练数据设置,并且相对静态[Lazaridou et al. 2021; Khandelwal et al. 2020]。虽然适应方法可以为不同的任务准备基础模型,但仍然不清楚如何在没有大量训练的情况下改变基础模型的更基本的语言基础。建立自然反映人类语言适应和语言进化的自适应模型是基础模型未来的一个重要研究领域。
5、总结
基础模型已经彻底改变了NLP的研究和实践。基础模型为社区带来了许多新的研究方向:将生成理解为语言的一个基本方面,研究如何最好地使用和理解基础模型,了解基础模型可能增加NLP不平等的方式,研究基础模型是否可以令人满意地包含语言变异和多样性,并找到利用人类语言学习动态的方法。在基础模型之前,研究社区关注的大多数复杂的NLP任务现在都可以使用少数几个公开发布的基础模型之一来最好地处理,几乎达到人类的水平。然而,在这种性能与在复杂的下游环境中有效和安全地部署基础模型的需求之间仍然存在很大的差距。