tc模拟延时丢包等网络故障依赖的内核驱动
/lib/modules/5.15.0-52-generic/kernel/net/sched/sch_netem.ko
有些系统并不是默认就安装上该驱动的,如果没有安装该驱动,构造网络故障时会报错。
root@:curtis# tc qdisc change dev enp4s0 root netem delay 10ms reorder 25% 50%
Error: Qdisc not found. To create specify NLM_F_CREATE flag.
安装驱动
insmod /lib/modules/5.15.0-52-generic/kernel/net/sched/sch_netem.ko
可是为什么安装好内核驱动之后还是会报错??
curtis@:linux$ sudo tc qdisc change dev enp4s0 root netem delay 10ms reorder 25% 50%
Error: Qdisc not found. To create specify NLM_F_CREATE flag.
内核驱动源码路径
./net/sched/sch_netem.c
尝试自己编译下这个内核驱动? - - 自己编译了之后,发现是同样的情况??
root@:sch_netem# tc qdisc show
qdisc noqueue 0: dev lo root refcnt 2
qdisc fq_codel 0: dev enp4s0 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn
qdisc noqueue 0: dev wlp5s0 root refcnt 2
qdisc noqueue 0: dev docker0 root refcnt 2
qdisc noqueue 0: dev vethf5e645e root refcnt 2
尝试用其他命令尝试注入网络时延故障 - - 发现做网络延时是没有问题的,这就有理由怀疑是命令格式问题?
root@:sch_netem# tc qdisc add dev enp4s0 root netem delay 15ms
root@:sch_netem# tc qdisc show
qdisc noqueue 0: dev lo root refcnt 2
qdisc netem 8002: dev enp4s0 root refcnt 2 limit 1000 delay 15.0ms
qdisc noqueue 0: dev wlp5s0 root refcnt 2
qdisc noqueue 0: dev docker0 root refcnt 2
qdisc noqueue 0: dev vethf5e645e root refcnt 2
最后还是自己去翻了以下man手册,最终找到了答案,change是用来修改某个网卡网络规则的(无脑拷贝他人命令的结果),add是给某个网口添加规则,没有添加相关规则,肯定就不能修改。
tc-netem man 手册
root@:sch_netem# tc qdisc add dev enp4s0 root netem delay 10ms reorder 25% 50%
root@:sch_netem# tc qdisc
qdisc noqueue 0: dev lo root refcnt 2
qdisc netem 8004: dev enp4s0 root refcnt 2 limit 1000 delay 10.0ms reorder 25% 50% gap 1
qdisc noqueue 0: dev wlp5s0 root refcnt 2
qdisc noqueue 0: dev docker0 root refcnt 2
qdisc noqueue 0: dev vethf5e645e root refcnt 2
root@:sch_netem#
root@:sch_netem# tc qdisc change dev enp4s0 root netem delay 10ms reorder 50% 50%
root@:sch_netem# tc qdisc
qdisc noqueue 0: dev lo root refcnt 2
qdisc netem 8004: dev enp4s0 root refcnt 2 limit 1000 delay 10.0ms reorder 50% 50% gap 1
qdisc noqueue 0: dev wlp5s0 root refcnt 2
qdisc noqueue 0: dev docker0 root refcnt 2
qdisc noqueue 0: dev vethf5e645e root refcnt 2
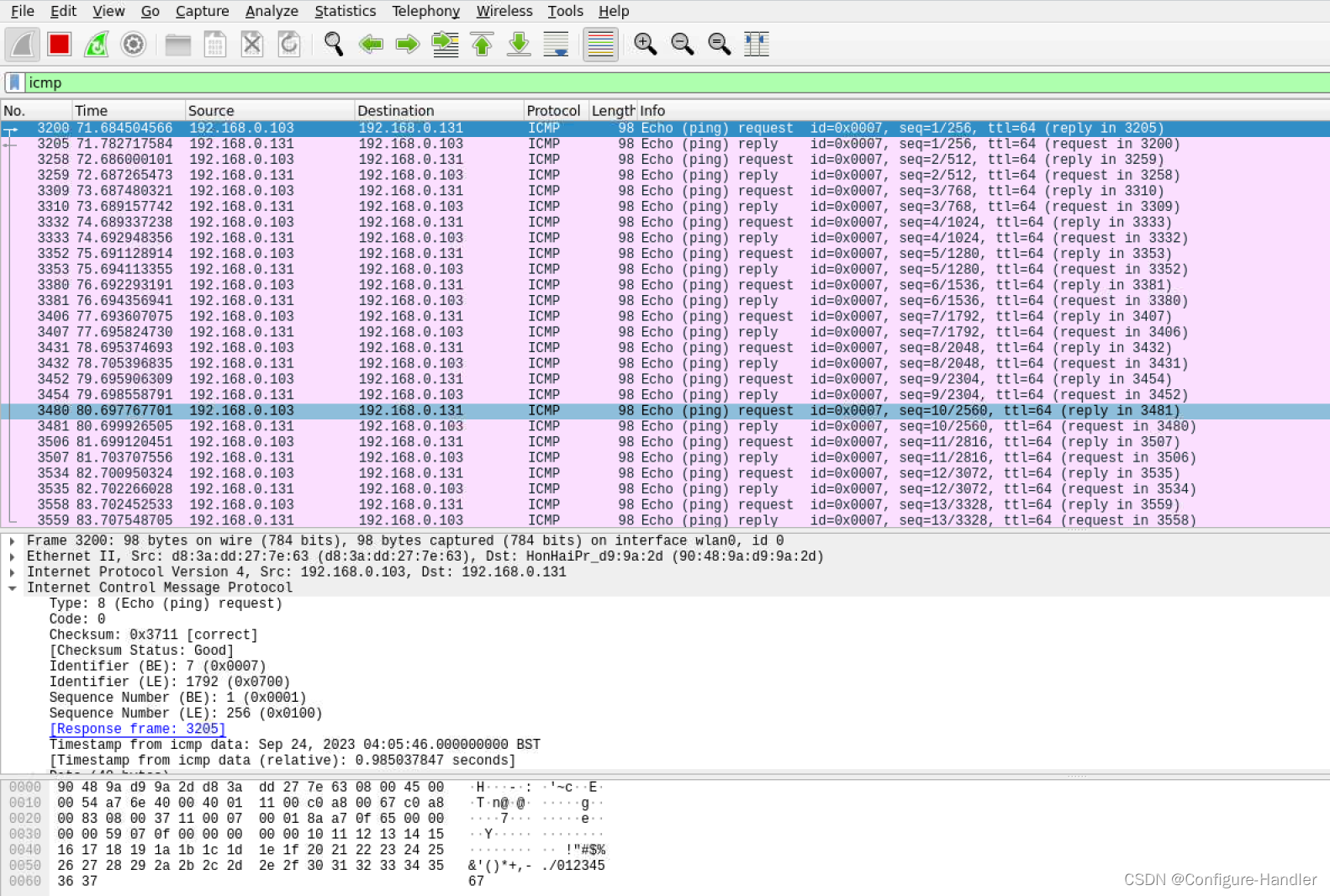
使用wireshark抓包,ping是icmp类型的报文。
tc 使用示例
查看所有已经设定的规则
root@rlk:/home# tc qdisc show
qdisc noqueue 0: dev lo root refcnt 2
qdisc netem 8001: dev ens33 root refcnt 2 limit 1000 delay 100.0ms
qdisc noqueue 0: dev docker0 root refcnt 2
延时
# tc qdisc add dev eth0 root netem delay 100ms
Add fixed amount of delay to all packets going out on device
eth0(为设备eth0上传出的所有数据包添加固定的延迟量).
Each packet will have added delay of 100ms ± 10ms. - - tc延时也非准确?
# tc qdisc change dev eth0 root netem delay 100ms 10ms
100ms±10ms延时时间随机变化。
# tc qdisc change dev eth0 root netem delay 100ms 10ms 25%
This causes the added delay of 100ms ± 10ms and the next
packet delay value will be biased by 25% on the most recent
delay. This isn't a true statistical correlation, but an
approximation.
uniform variation with correlation value -- 具有相关值的均匀变化。
使振幅根据uniform variation with correlation value发生变化。
这会导致增加 100ms ± 10ms 的延迟,并且下一个数据包延迟值将比最近的延迟偏差25%。
这不是真正的统计相关性,而是近似值。
从测试的情况来看,10ms为offset,ping实际延迟时间为90~110之间。
如果将比例设置为100%,则ping实际延迟时间为108,这个百分比比较晦涩?
# tc qdisc change dev eth0 root netem delay 100ms 20ms distribution normal
This delays packets according to a normal distribution (Bell
curve) over a range of 100ms ± 20ms.
验证方法,ping目标主机。
PS C:\Users\94805> ping -t 192.168.0.130
正在 Ping 192.168.0.130 具有 32 字节的数据:
来自 192.168.0.130 的回复: 字节=32 时间=100ms TTL=64
来自 192.168.0.130 的回复: 字节=32 时间=101ms TTL=64
来自 192.168.0.130 的回复: 字节=32 时间=100ms TTL=64
来自 192.168.0.130 的回复: 字节=32 时间=101ms TTL=64
192.168.0.130 的 Ping 统计信息:
数据包: 已发送 = 9,已接收 = 9,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 100ms,最长 = 202ms,平均 = 112ms
丢包
# tc qdisc change dev eth0 root netem loss 0.1%
This causes 1/10th of a percent (i.e 1 out of 1000) packets
to be randomly dropped.
An optional correlation may also be added. This causes the
random number generator to be less random and can be used to
emulate packet burst losses.
重复包
# tc qdisc change dev eth0 root netem duplicate 1%
This causes one percent of the packets sent on eth0 to be
duplicated.
# tc qdisc change dev eth0 root netem loss 0.3% 25%
This will cause 0.3% of packets to be lost, and each
successive probability depends is biased by 25% of the
previous one.
There are two different ways to specify reordering. The gap
method uses a fixed sequence and reorders every Nth packet.
# tc qdisc change dev eth0 root netem gap 5 delay 10ms
This causes every 5th (10th, 15th, …) packet to go to be sent
immediately and every other packet to be delayed by 10ms.
This is predictable and useful for base protocol testing like
reassembly.
The reorder form uses a percentage of the packets to get
misordered.
# tc qdisc change dev eth0 root netem delay 10ms reorder 25% 50%
In this example, 25% of packets (with a correlation of 50%) will
get sent immediately, others will be delayed by 10ms.
Packets will also get reordered if jitter is large enough.
# tc qdisc change dev eth0 root netem delay 100ms 75ms
If the first packet gets a random delay of 100ms (100ms base
- 0ms jitter) and the second packet is sent 1ms later and
gets a delay of 50ms (100ms base - 50ms jitter); the second
packet will be sent first. This is because the queue
discipline tfifo inside netem, keeps packets in order by time
to send.
If you don't want this behavior then replace the internal queue
discipline tfifo with a simple FIFO queue discipline.
# tc qdisc add dev eth0 root handle 1: netem delay 10ms 100ms
# tc qdisc add dev eth0 parent 1:1 pfifo limit 1000
Example of using rate control and cells size.
# tc qdisc add dev eth0 root netem rate 5kbit 20 100 5
Delay all outgoing packets on device eth0 with a rate of
5kbit, a per packet overhead of 20 byte, a cellsize of 100
byte and a per celloverhead of 5 bytes.
高级用法
It is possible to selectively(有选择的) apply impairment(损伤) using traffic
classification.
# tc qdisc add dev eth0 root handle 1: prio
# tc qdisc add dev eth0 parent 1:3 handle 30: tbf rate 20kbit buffer 1600 limit 3000
# tc qdisc add dev eth0 parent 30:1 handle 31: netem delay 200ms 10ms distribution normal
# tc filter add dev eth0 protocol ip parent 1:0 prio 3 u32 match ip dst 65.172.181.4/32 flowid 1:3
This eample uses a priority(优先级) queueing discipline(规则); a TBF is
added to do rate control; and a simple netem delay. A filter
classifies all packets going to 65.172.181.4 as being
priority 3.
从上述命令来看,可以根据实际使用需求设定包过滤器。
tc qdisc add dev $(net) root handle 1:0 prio bands 4
tc qdisc add dev $(net) parent 1:4 handle 40: netem delay "$dvalue"
tc filter add dev $(net) protocol ip parent 1:0 prio 4 u32 match ip dst $(ip) match ip dport $(port) 0xffff flowid 1:4
根root qdisc的handle为默认为1:0,因为root qdisc为 classless pfifo_fast qdisc。
pfifo_fast 有三个所谓的 “band”(可理解为三个队列),编号分别为 0、1、2:(默认是三个,在指定bands个数最少为3)
否则报错如下所示:
root@:~# tc qdisc add dev ens19 root handle 1: prio bands 1
RTNETLINK answers: Invalid argument
root@:~# tc qdisc add dev ens19 root handle 1: prio bands 2
RTNETLINK answers: Invalid argument
疑问:可以根据需求自定义添加pfifo_fast qdisc的band? - - 从实现结果来看确实可以按需配置。
每个 band 上分别执行 FIFO 规则。
如果 band 0 有数据,就不会处理 band 1;同理,band 1 有数据时,不会去处理 band 2。
内核会检查数据包的 TOS 字段,将“最小延迟”的包放到 band 0。
tc qdisc add dev $(net) root handle 1:0 prio bands 4
- handle 队列规则句柄,可以理解为网络流量流经的路径上的一个标识,默认
1:0为根节点,也可以自定义 ,比如说为10:0。 - root handle 1:0 表示创建一个根队列,并将其标识为1:0。
- prio 表示使用优先级调度算法,如果不指定具体的值,如
tc qdisc del dev ens19 root handle 1:0 prio,则默认prio的值为1,如果不指定该参数,如tc qdisc del dev ens19 root handle 1:0不指定prio将会报错,Error: Specified qdisc kind is unknown.。 - bands 4 表示创建4个子队列,如果不指定该值
root handle默认为3个bands。
树形结构
1: root qdisc
/ | \
/ | \
/ | \
1:1 1:2 1:3 classes
| | |
10: 20: 30: qdiscs qdiscs
sfq tbf sfq
band 0 1 2
tc qdisc add dev $(net) parent 1:4 handle 40: netem delay "$dvalue"
- handle 40 指定
qdisc子class句柄为40:0,这个值也是可以根据需求去指定的。 - netem 参数可以理解为指定包的排队规则,还有其他排队规则,如
pfifo_fast TBF SFQ FQ,Netem是Linux 2.6及以上内核版本提供的一个网络模拟功能模块,这就是为什么需要单独加载sch_netem内核模块的原因,该功能模块可以用来在性能良好的局域网中,模拟出复杂的互联网传输性能,注入低带宽,传输延迟,丢包等故障。
tc filter add dev $(net) protocol ip parent 1:0 prio 4 u32 match ip dst $(ip) match ip dport $(port) 0xffff flowid 1:4
- protocol ip 匹配 ip protocol,也可以使用
/etc/protocols里面的协议号。 - u32 一种匹配规则,特点是能匹配包的任何部分。
- match ip dst $(ip) match ip dport $(port) 0xffff 目的
dst_ip/port的所有ip协议的所有包。u32 match ip sport 80 0xffff``IP头中的源端口号是一个16位的字段,范围从0到65535。使用0xffff作为掩码意味着我们希望匹配所有的源端口号,因为0xffff的二进制表示为16个1,它与任何16位的源端口号进行逻辑与操作时都会匹配,所以上述命令已经制定了dst_ip/dport是不是不需要指定0xffff?,实际使用如果要匹配端口,不接0xffff会报错Illegal "match",也就是必须输入的参数。 - flowid 1:4 将特定的流量流向标识为1:4的子队列,以便对该流量应用特定的规则和限制。
查看某个interface的filter 规则。
tc filter show dev ens18
查看某个interface的class。
tc class show dev ens18
仅仅匹配sport是生效的,ssh到目标主机有明显的延迟。
tc filter add dev ens18 protocol ip parent 1:0 prio 4 u32 match ip sport 22 0xffff flowid 1:4
为什么match规则为source ip存在问题???,将src替换为dst是生效的???
tc filter add dev ens18 protocol ip parent 1:0 prio 4 u32 match ip src 192.168.0.207 flowid 1:4
- 指定本地网卡,只匹配
srcip地址是不生效 - 指定本地网卡,只匹配
src port是生效 - 匹配
src ip + src port不生效 - 只匹配
dst ip地址生效 - 只匹配
dst port生效 - 匹配
dst ip + dst port生效
原因分析:
子网掩码255.255.255.0 - - 24
子网掩码255.255.240.0 - - 20
在指定本地网卡为src ip时,需要指定子网掩码,指定子网掩码之后,延迟效果是存在的,默认的子网掩码为255.255.255.0,可以通过ifconfig或者ip addr show来查看网卡配置的子网掩码。
特别注意:
设定规则之后,如果对应网卡被移除,对应的规则也将会丢失。