在当今快节奏的技术环境中,大型AI模型正在推动不同领域的突破。 然而,根据特定任务或数据集定制这些模型可能是一项计算和资源密集型工作。 LoRA是一种突破性且高效的微调技术,它利用这些高级模型的强大功能来执行自定义任务和数据集,而不会造成资源紧张或产生过高的成本。
近几个月来,LoRA 席卷了 AI 社区(图 1)。 在这篇博文中,我们将深入探讨其迅速崛起背后的原因。 我们将探讨 LoRA 的基础原则、其在各个领域的有效性以及它对开源社区的影响。
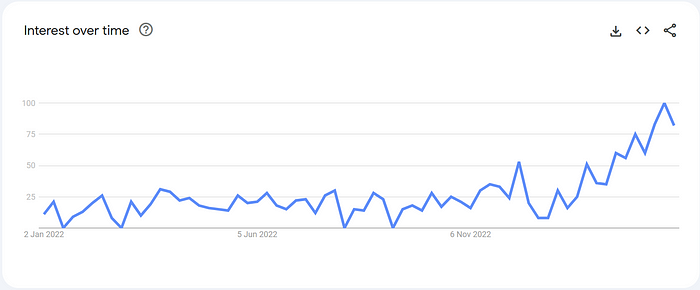
图 1:过去 12 个月 LoRA 一词在计算机科学类别中的流行程度
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
无论你是AI爱好者,还是寻求利用大模型来应对特定业务挑战的工程师,都可以加入我们这个迷人的旅程,了解 LoRA 如何改变大型模型 FMOps(基础模型运维)管道中的微调步骤。
1、背景知识
在深入了解 LoRA 之前,我们先回顾一下一些基本的线性代数概念。 如果你熟悉线性代数的基础知识(特别是矩阵秩),请随意绕过下面的数学。
1.1 矩阵的秩
矩阵的秩(rank)是由其列生成的向量空间的维数,由给定矩阵中线性独立的列(或行)的数量给出。 可以证明,独立列的数量(称为列秩)始终等于独立行的数量(称为行秩)。 因此,对于 m 行 n 列的矩阵 A(表示为 Aₘₙ),

根据秩的不同情况,矩阵主要可以分为两种类型。
- 满秩矩阵:如果
rank(A) = min(m, n),则矩阵 Aₘₙ 称为满秩(full rank)矩阵。 下面显示的矩阵是满秩矩阵的示例。

- 不满秩矩阵:满秩矩阵的反面是不满秩(rank deficient),即
rank(A) < min(m, n)。 下面所示的不满秩矩阵的秩为 1,因为该矩阵的列(或行)不是彼此线性独立的:
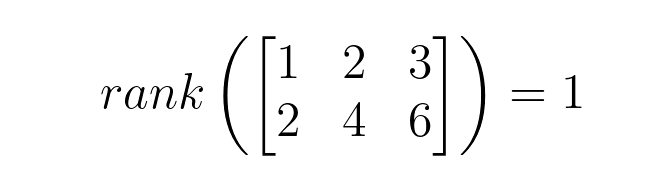
如果秩明显低于(无固定阈值)最小行数和列数,则不满秩矩阵 Aₘₙ 称为低秩(low rank)矩阵。 数学上, rank(A) << min(m, n)。
1.2 秩相关属性
就本博客而言,矩阵的秩可以被理解为它所表示的特征空间的维度。 在这种情况下,特定大小的低秩矩阵比相同维度的满秩矩阵封装更少的特征(或更低维的特征空间)。
下面介绍两个与秩相关的矩阵属性:
- 矩阵的秩受其行数和列数中最小值的约束。
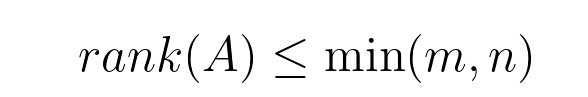
- 两个矩阵的乘积的秩受其各自秩的最小值的约束。给定矩阵 A 和 B,其中rank(A) = m且rank(A) = n,则,

1.3 秩分解
矩阵 Aₘₙ 的秩分解或因式分解是对 A = CₘᵣFᵣₙ 形式的 A 进行因式分解,其中rank(A) = r。 可以证明每个(有限)矩阵都有一个秩分解(证明)。 SVD(奇异值分解)等技术可用于构建此类分解。
至此,我们已经介绍了必要的背景概念。 让我们深入了解 LoRA,并探讨它如何在微调大型AI模型的背景下利用这些原则。
2、LoRA:低秩适配
LoRA (Low rand adaption)是微软研究人员提出的一种高效的微调技术,用于使大型模型适应特定任务和数据集。 虽然本文使用 GPT-3 作为测试用例,并重点关注语言模型和 NLP 任务,但该技术具有相当的通用性,我们将在下面看到。 它可以应用于多种上下文中的各种模型。
之前的许多工作已经表明,过度参数化的大型模型存在较低的内在维度。 LoRA 背后的主要思想是模型微调期间权重的变化也具有较低的内在等级/维度。 具体来说,如果Wₙₖ代表单层的权重,ΔWₙₖ代表模型自适应过程中权重的变化,作者提出ΔWₙₖ是一个低秩矩阵,即:
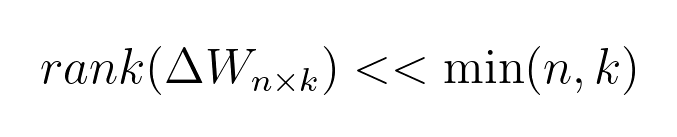
为什么这是有道理的?
大型模型经过训练以捕获其领域的一般表示,例如LLM的语言、Whisper 等模型的音频+语言或图像生成模型的视觉。 这些模型捕获了各种特征,使它们能够以合理的零样本精度用于各种任务。 然而,当使这样的模型适应特定任务或数据集时,只需要强调或重新学习少数特征。 这意味着更新矩阵(ΔW)可以是低秩矩阵。
2.1 LoRA实现方法
LoRA技术使用秩分解来约束更新矩阵 ΔW 的秩。 它将 ΔWₙₖ 表示为 2 个低秩矩阵 Bₙᵣ 和 Aᵣₖ 的乘积,其中 r << min(n, k)。 这意味着该层的前向传递,原来的Wx,被修改为Wx + BAx(如下图所示)。 A 使用随机高斯初始化,B 初始为 0,因此训练开始时 BA=0。 更新 BA 还使用因子 α/r 进行缩放。
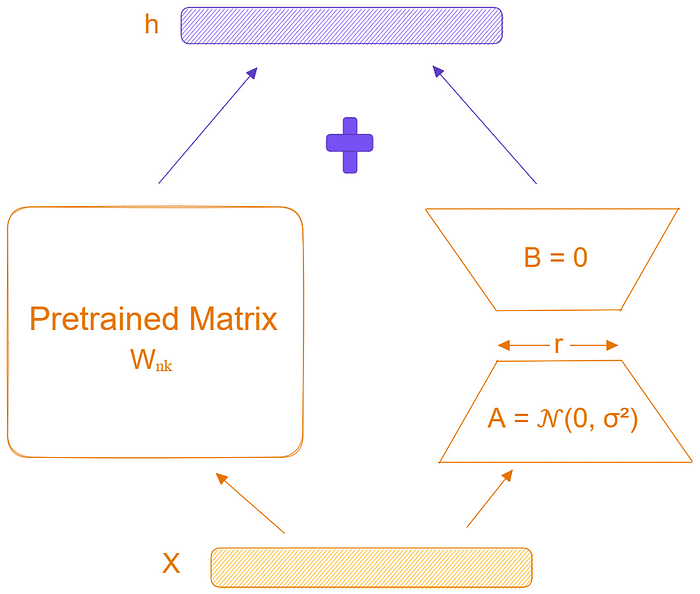
图 2:使用低秩分解改进的前向传播。
2.2 LoRA的实际价值
包括:
- 减少训练时间和空间:使用上面所示的技术,需要在模型微调期间调整
r(n + k)参数。 由于r << min(n, k),这比必须调整的参数数量(nk)要少得多。 这大大减少了微调模型所需的时间和空间。 本文和我们的实验中的一些数据将在下面的部分中讨论。 - 无需额外的推理时间:如果在生产中使用,我们可以显式计算
W’ = W + BA并存储结果,照常执行推理。 这保证了我们在推理过程中不会引入任何额外的延迟。 - 更轻松的任务切换:仅交换 LoRA 权重而不是所有参数,可以更便宜、更快地在任务之间切换。 可以创建多个定制模型并轻松换入和换出。
然而,这里的缺点是,一旦合并权重以消除额外的推理时间,任务切换的便捷性就会消失。 此外,在一次前向传递中将不同 A 和 B 的输入批量输入到不同的任务并不简单。 有得有失,对吧?
3、评估 LoRA 的有效性
讨论了LoRA技术的工作原理及其可能带来的好处后,现在让我们探讨一下它的功效。 在论文中,作者根据完全微调和其他参数/计算高效技术评估了 LoRA(使用 RobBert、GPT2 和 GPT3)的性能。 他们发现 LoRA 通常大幅优于其他高效的微调技术,同时还提供与完全微调相当或更好的性能。 有关其分析的完整详细信息,有兴趣的读者可以参考该论文。
为了进一步探索其有效性,我们在各个领域和任务中进行了额外的实验。 在以下小节中,我们讨论这些实验的结果,展示 LoRA 方法的多功能性和鲁棒性。
3.1 在 Common Voice (NL) 上微调 Whisper-Large-v2
Whisper 是一个 ASR(自动语音识别) 系统,经过大量数据集的训练。 它是一个模型系列,每个模型都有不同的尺寸。 最小的模型 (Whisper-Tiny) 包含 3900 万个参数,而最大的模型 (Whisper-Large-v2 ) 包含 15 亿个参数。 最大的模型可以执行多语言自动语音识别任务。 然而,通过使用特定语言的数据对其进行微调,可以提高其性能。
在本实验中,我们使用通用语音数据集的荷兰语子集对模型进行微调。 我们通常在低数据状态下对大型模型(有或没有 LoRA)进行微调。 使用 r=32(其中 r 是更新矩阵的秩)的 LoRA 对模型进行微调,可将可调节参数的数量减少到 1570 万个,占整个模型参数的 1%。
首先我们用一个小的数据集进行测试。我们对带有或不带有 LoRA 的 Whisper-Large-v2 对来自 Common Voice 荷兰语子集的一小时音频进行了微调。 评价结果如下表所示:
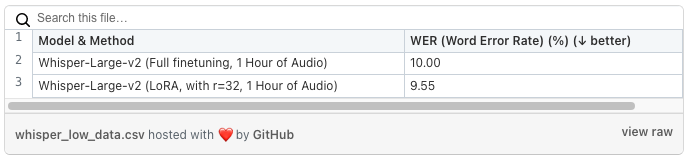
表 1:低数据情况下 LoRA 和全微调的比较
我们看到使用 LoRA 微调的模型的性能与完全微调的模型的性能相似。 然而,如前所述,LoRA 允许我们通过调整极少量的参数(就大小而言,LoRA 检查点仅为 60MB)在更短的时间内完成此任务。 使用 LoRA(和 8 位优化),在 Google Cloud 上的 Nvidia T4 上进行训练大约需要 4 小时,成本不到 5 美元。
接下来我们使用大数据集测试。在本例中,我们使用 Common Voice 的整个荷兰语子集(约 40 小时)对同一模型进行了微调。 评价结果如下表所示:
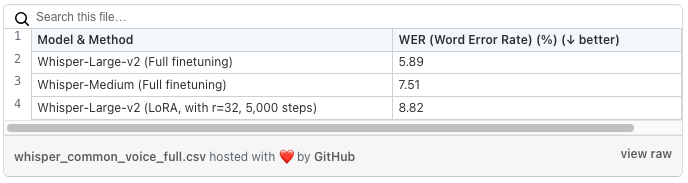
表 2:LoRA 与完全微调的比较
我们看到,使用 LoRA 微调的大型模型(5000 步)的性能与完全微调的大型和中型模型的性能相当。 然而,使用 LoRA(和 8 位优化),在 Google Cloud 上的 Nvidia T4 上进行微调大约需要 10 个小时,成本不到 10 美元。
3.2 调整 LLaMA 来执行对话摘要任务
LLaMA 是 Meta 研究人员发布的大型语言模型。 与 Whisper 一样,它是一个具有不同尺寸的模型系列(最小的是 7B,最大的是 65B)。
我们使用 Samsum 数据集对对话摘要任务的 7B 参数模型进行了微调,并使用 ROUGE 来评估微调后的模型。 为了测试 LoRA 在低秩下的有效性,更新矩阵的秩被限制为 4,即 r=4。 这意味着可调参数的数量为200万个,仅占模型参数总数的0.03%。
从下表中我们可以看到,它的性能优于完全微调的 Flan-T5-Base 模型(2.5 亿个参数)。 此外,使用低秩和 8 位优化使我们能够在单个 Nvidia-T4 上微调如此大的模型!

表 3:LLaMA 在 SamSum 数据集上的低秩微调
注意:这不是模型之间公平的独立比较。 与 Flan-T5-Base 相比,LLaMA-7B 是一个更大的基础模型,因此可能在许多任务上具有更好的零样本性能。 然而,这种比较旨在证明,对于大型基础模型,使用非常低的秩(因此需要较少的计算和微调时间)就足够了。
论文和我们的实验结果证明了 LoRA 的有效性。 LoRA 提供了一种计算和参数有效的方法来微调基础模型,而不会显着降低性能,从而节省时间和金钱!
4、野蛮生长的LoRA
现在让我们看看 LoRA 在开源社区中的应用情况。 随着最近大型基础模型和生成式AI模型的爆炸式增长,开源社区张开双臂欢迎 LoRA,因为它能够让资源匮乏的从业者适应大型模型。 在这里,LoRA 主要用于两个主要目的:指令调整 LLM 和微调扩散模型。
4.1 指令调整大型语言模型
随着 ChatGPT 和 Self-Instruct 等技术的推出,OSS 社区一直在稳步致力于调整大型语言模型以遵循指令。
这里的核心思想很简单。 创建指令和响应的数据集(手工创建或 试用ChatGPT),并通过 LoRA 使用该数据集微调预训练的大型语言模型。 这种方法产生的模型相当擅长像人类一样遵循指令并回答问题。 有兴趣的读者可以查看 Alpaca-LoRA 和 Vicuna 等模型。
Vicuna 回答用户有关夏威夷度假的问题
4.2 微调稳定扩散
在 ChatGPT 和 LLaMA 等其他 LLM 推出之前,LoRA 主要用于调整稳定扩散以适应生成图像的风格。 然后,可以即插即用的方式使用和共享 LoRA 权重,并在需要不同的图像生成样式时将其切换。
如前所述,该技术的主要吸引力在于其参数和计算效率。 Lora库的存在证明了这种方法在生成式AI 社区中的流行,人们可以在其中共享他们的 Lora 文件!
5、结束语
总而言之:LoRA 有两个主要应用。 第一个是用低计算量微调大型模型,第二个是在低数据环境下调整大型模型。 论文的结果、我们的实验以及开源人工智能社区的广泛采用证明了它在当前基础模型驱动的AI环境中的价值。
它使AI民主化,使个人和组织能够在不花太多钱的情况下使用和调整大型基础模型,确保适应这些模型的能力不仅仅掌握在少数人手中!
原文链接:LoRA微调技术详解 - BimAnt