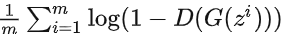目 录
一、基础架构
二、输入部分
三、预训练:MLM+NSP
3.1 MLM:掩码语言模型
3.1.1 mask模型缺点
3.1.2 mask的概率问题
3.1.3 mask代码实践
3.2 NSP
四、如何微调Bert
五、如何提升BERT下游任务表现
5.1 一般做法
5.2 如何在相同领域数据中进行further pre-training
5.3 参数设置Trick
六、如何在脱敏数据中使用Bert等预训练模型
一、基础架构
基础架构为Transformer的Encoder:
具体解释可参考简单易懂的Transformer学习笔记_十七季的博客-CSDN博客
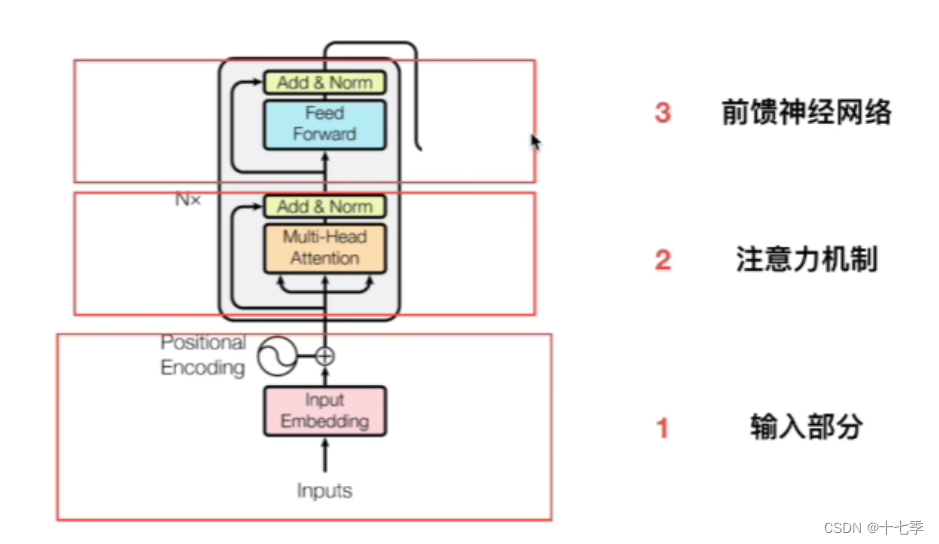
Base bert -12层Encoder堆叠。

其中位置编码部分与Trm的positional encoding不同,具体在下面进行解释。
二、输入部分

CLS向量不能代表整个句子的语义信息
区分句子:上图中第一个句子E_A=0, 第二个句子E_B=1
位置信息:TRM正余弦;Bert随机初始化,模型自学习
三、预训练:MLM+NSP
3.1 MLM:掩码语言模型
没有标签,无监督。
AR:自回归模型,只能考虑单侧信息;GPT
AE:自编码模型,从损坏的输入数据中预测重建原始数据,可以使用上下文信息;Bert
Eg:

3.1.1 mask模型缺点

认为两个mask之间是独立的(但实际未必独立)
3.1.2 mask的概率问题

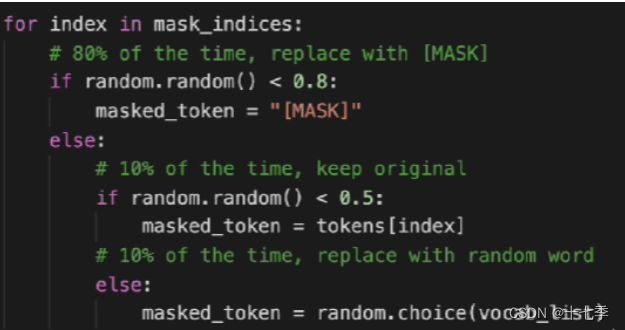
3.1.3 mask代码实践
3.2 NSP
NSP样本如下:
-
从训练语料库中取出两个连续的段落作为正样本
-
从不同的文档中随机创建一对段落作为负样本
缺点:
主题预测(是否属于同一个文档)和连贯性预测合并为一个单项任务
四、如何微调Bert
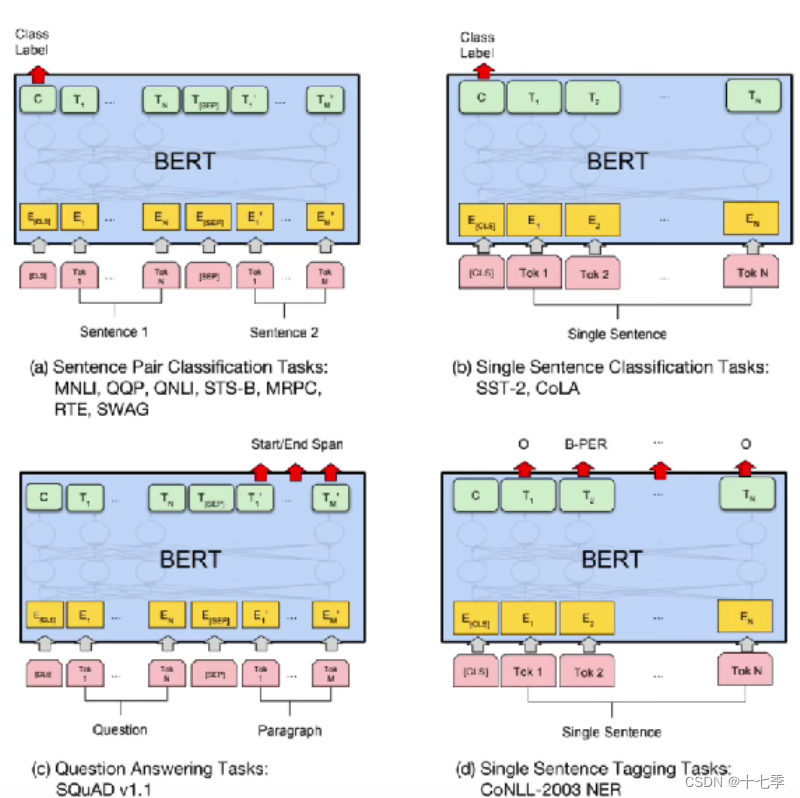
对输出Softmax
五、如何提升BERT下游任务表现
5.1 一般做法
1.获取谷歌中文Bert
2.基于任务数据进行微调
以微博文本情感分析为例:
-
在大量通用语料上训练一个LM(Pretrain);——中文谷歌BERT
-
在相同领域上继续训练LM(Domain transfer);——在大量微博文本上继续训练这个BERT
-
在任务相关的小数据上继续训训练LM(Task transfer); ——在微博情感文本上(有的文本不属于情感分析的范畴)
-
在任务相关数据上做具体任务(Fine-tune)。-
先Domain transfer再进行Task transfer最后Fine-tune性能是最好的
5.2 如何在相同领域数据中进行further pre-training
-
动态mask: 每次epoch去训练的时候mask,而不是一直使用同一个。
-
n-gram mask: 比如ERNIE和SpanBerti都是类似于做了实体词的mask
5.3 参数设置Trick
Batch size:16,32——影响不太大
earning rate(Adam):——尽可能小一点避免灾难性遗忘
Number of epochs:3,4
Weighted decay修改后的adam,使用warmup, 搭配线性衰减
数据增强/自蒸馏/外部知识的融入
六、如何在脱敏数据中使用Bert等预训练模型
对于脱敏语料使用BERT,一般可以分为两种:
-
直接从零开始基于语料训练一个新的BERT出来使用;
-
按照词频,把脱敏数字对照到中文或者其他语言【假如我们使用中文】,使用 中文BERT做初始化,然后基于新的中文语料训练BERT。
参考资料
BERT从零详细解读,看不懂来打我_哔哩哔哩_bilibili