文章目录
- 一、索引
- 1、说明
- 2、原理
- 3、相关操作
- 3.1、创建索引
- 3.2、查看集合索引
- 3.3、查看集合索引大小
- 3.4、删除集合所有索引(不包含_id索引)
- 3.5、删除集合指定索引
- 4、复合索引
- 二、聚合
- 1、说明
- 2、使用
- 总结
一、索引
1、说明
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
2、原理
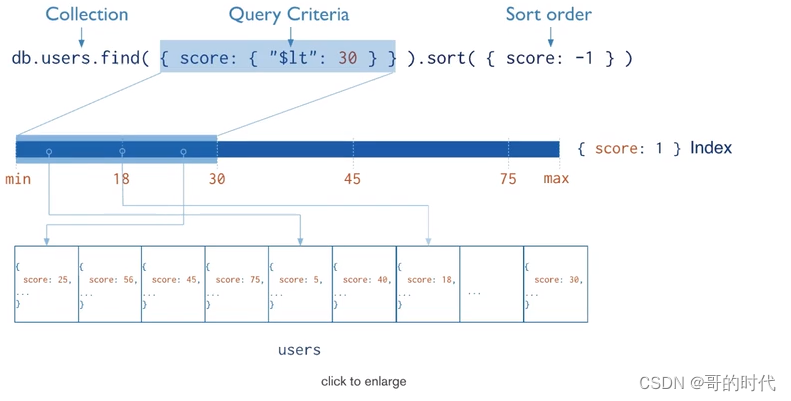
从根本上说,MongoDB中的索引与其他数据库系统中的索引类似。MongoDB在集合层面上定义了索引,并支持对MongoDB集合中的任何字段或文档的子字段进行索引。
默认_id已经创建了索引。
3、相关操作
3.1、创建索引
db.集合名称.createIndex(keys, options)
db.集合名称.createIndex({"title":1,"description":-1})
说明: 语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
3.2、查看集合索引
db.集合名称.getIndexes()
3.3、查看集合索引大小
db.集合名称.totalIndexSize()
3.4、删除集合所有索引(不包含_id索引)
db.集合名称.dropIndexes()
3.5、删除集合指定索引
db.集合名称.dropIndex("索引名称")
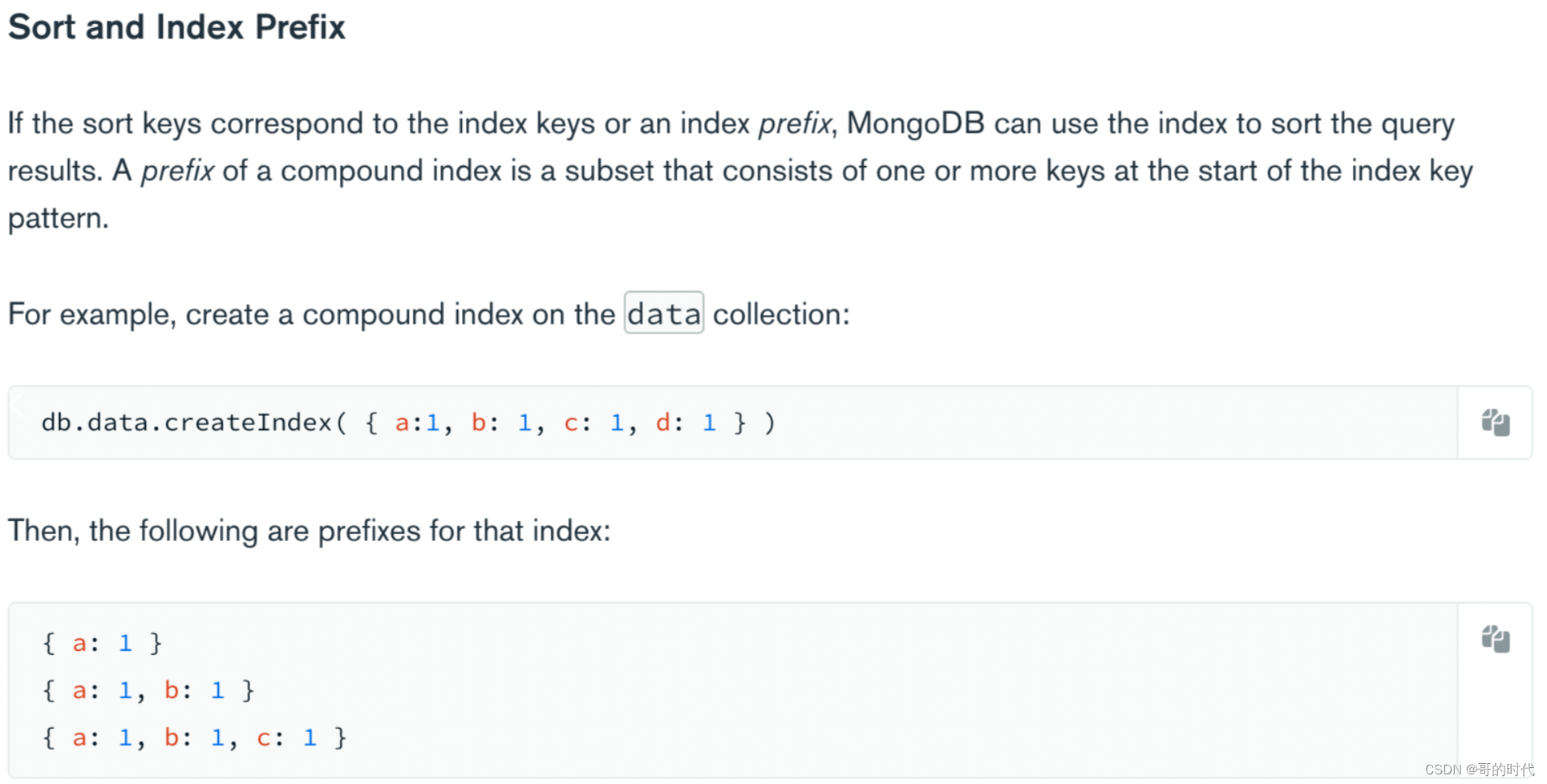
4、复合索引
说明: 一个索引的值是由多个 key 进行维护的索引的称之为复合索引
db.集合名称.createIndex({"title":1,"description":-1})
注意: mongoDB 中复合索引和传统关系型数据库一致都是左前缀匹配原则

二、聚合
1、说明
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似 SQL 语句中的 count(*)。
2、使用
db.test.insertMany([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'runoob.com',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'runoob.com',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
}
]);
现在我们通过以上集合计算每个作者所写的文章数,使用aggregate()计算结果如下:
db.test.aggregate([{$group : {
_id : "$by_user",
num_tutorial : {$sum : 1}
}}])
注意:此处的_id是分组表示,不是文档的 _id.
常见聚合表达式
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", num_tutorial : { s u m : " sum : " sum:"likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", num_tutorial : { a v g : " avg : " avg:"likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", num_tutorial : { m i n : " min : " min:"likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", num_tutorial : { m a x : " max : " max:"likes"}}}]) |
| $push | 将值加入一个数组中,不会判断是否有重复的值。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", url : { p u s h : " push: " push:"url"}}}]) |
| $addToSet | 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", url : { a d d T o S e t : " addToSet : " addToSet:"url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", first_url : { f i r s t : " first : " first:"url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", last_url : { l a s t : " last : " last:"url"}}}]) |
总结
以上就是MongoDB之索引和聚合的相关知识点,希望对你有所帮助。