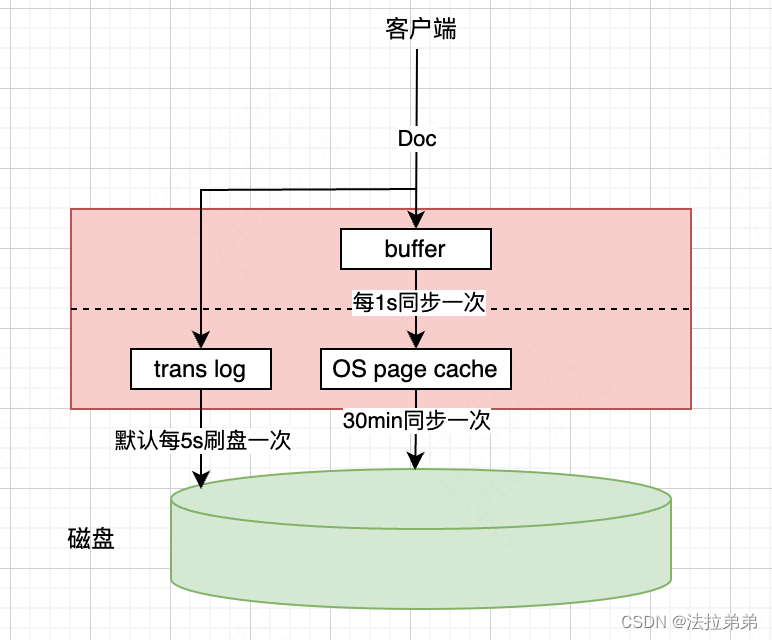
其实除了VAE自监督外,引入语义属性来约束生成特征的质量。感觉解纠缠这个说法有点扯淡。
语义相关模块的作用
其实就是把语义属性也作为标签。除了VAE外,加了语义属性作为标签,这样生成的特征就可以即跟原始视觉特征对齐,又跟语义属性对齐,来保证生成的特征足够逼真。
用可见类样本和标签训练好VAE和解纠缠模块后,输入不可见类的语义属性特征,通过VAE生成不可见类视觉特征,将生成的视觉特征输入到解纠缠模块会得到与属性对齐的视觉特征,质量更好。
将解纠缠后的可见类视觉特征和生成的不可见类视觉特征输入到GZSL分类器,进行训练。
用解纠缠后的视觉特征训练分类器的好处:
如果不使用解纠缠方法,那么生成的方法有可能会强调那些与语义属性标注无关的特征(语义属性标注的都是容易区分不同物种的特征)。所以生成的图像要强调生成这些标注的特征,解纠缠就是要去掉与语义属性标注无关的特征。如果不用解纠缠,假如猫是不可见类,猫很容易被识别为虎,因为生成特征可能会强调那些语义无关的特征,比如耳朵,可是猫和老虎的耳朵形状很相似,这样就很容易将猫识别为老虎。
如果去掉这些语义无关的视觉特征,由于标注的语义特征都是能区分物种的,所以只需要强调生成语义相关的视觉特征即可。然后用于训练和泛化,就会去掉相似耳朵的影响。
相关性模块R,以矩阵0作为标签,输出是0-1,
one_hot_labels = torch.zeros(opt.batchsize, sample_C_n).scatter_(1, re_batch_labels.view(-1, 1), 1).to(opt.gpu)
class RelationNet(nn.Module):
'''
该网络主要目的是计算输入数据s和c之间的关系
'''
def __init__(self, args):
super(RelationNet, self).__init__()
self.fc1 = nn.Linear(args.C_dim + args.S_dim, 2048)
self.fc2 = nn.Linear(2048, 1)
def forward(self, s, c):
# 将c扩展为与s相同的大小
c_ext = c.unsqueeze(0).repeat(s.shape[0], 1, 1)
# c_ext.shape[0]是行,代表样本数。c_ext.shape[1]是列,是类别数
cls_num = c_ext.shape[1]
# 对输入的s进行处理,将其扩展为一个与c类别数量相同的大小
s_ext = torch.transpose(s.unsqueeze(0).repeat(cls_num, 1, 1), 0, 1)
relation_pairs = torch.cat((s_ext, c_ext), 2).view(-1, c.shape[1] + s.shape[1])
relation = nn.ReLU()(self.fc1(relation_pairs))
relation = nn.Sigmoid()(self.fc2(relation))
return relation
x1, h1, hs1, hn1 = ae(x_mean)
relations = relationNet(hs1, sample_C)
relations = relations.view(-1, labels.unique().cpu().shape[0]) #相关性分数在0-1之间
# one_hot里面都是0,要让相关性分数最大,就要让relation结果接近1,就要让relation与Onehot矩阵的loss最大。
p_loss = opt.ga * mse(relations, one_hot_labels)
x2, h2, hs2, hn2 = ae(X)
relations = relationNet(hs2, sample_C)
relations = relations.view(-1, labels.unique().cpu().shape[0])
p_loss = p_loss + opt.ga * mse(relations, one_hot_labels)
rec = mse(x1, X) + mse(x2, X)
RelationNet最后得到语义相关特征和对应的语义属性特征的相关分数。训练它让相关性分数最大化。也就是说让提取的特征与语义相关性强。
训练GZSL分类器
用解纠缠后的可见类视觉特征和解纠缠后的生成的不可见类视觉特征,来训练分类器GZSL。
gen_feat, gen_label = synthesize_feature_test(model, ae, dataset, opt)
with torch.no_grad():
# 将可见类输入到解纠缠编码器,得到语义相关的视觉特征和语义无关的视觉特征。
train_feature = ae.encoder(dataset.train_feature.to(opt.gpu))[:,:opt.S_dim].cpu()
test_unseen_feature = ae.encoder(dataset.test_unseen_feature.to(opt.gpu))[:,:opt.S_dim].cpu()
test_seen_feature = ae.encoder(dataset.test_seen_feature.to(opt.gpu))[:,:opt.S_dim].cpu()
# 拼接解纠缠后的 可见类特征 和 生成的不可见类特征
train_X = torch.cat((train_feature, gen_feat), 0)
train_Y = torch.cat((dataset.train_label, gen_label + dataset.ntrain_class), 0)
训练阶段
1.先获取到可见类的视觉特征和语义属性特征。
2.可见类的视觉特征 和 语义属性输入到Encoder,得到特征z。
3.根据特征z和属性a输入到解码器,得到生成的可见类视觉特征。
x_mean, z_mu, z_var, z = model(X, C)
4.将生成的不可见类特征输入到解纠缠器AE中,得到hs1和hn1是语义相关的特征和语义无关的特征
'''
ae是解纠缠自编码器。x1是重构的x_mean
h1是编码器提取的特征
hs1和hn1是语义相关的特征和语义无关的特征
'''
x1, h1, hs1, hn1 = ae(x_mean)
# 计算语义相关的特征hs1和语义属性C的相关性
relations = relationNet(hs1, sample_C)
x2, h2, hs2, hn2 = ae(X)
relations = relationNet(hs2, sample_C)
relations = relations.view(-1, labels.unique().cpu().shape[0])
生成阶段
输入:可见类的视觉特征 和 语义属性
输出:生成的可见类视觉特征
过程:
1.可见类的视觉特征 和 语义属性输入到Encoder,得到特征z。
2.
3.用生成的可见类视觉特征 与 真实的视觉特征用MSE Loss + KL散度loss计算损失然后反向传播。最终根据可见类的视觉样本和语义属性样本训练出一个生成器。
4.输入0-1分布和不可见类的属性生成不可见类的视觉特征。与可见类视觉特征一起加入解纠缠和分类器的训练。
解纠缠阶段
- 解纠缠器
输入:可见类视觉特征 和 生成的不可见类视觉特征
输出
测试阶段
输入:
一张图片(没有语义描述)。
输出:
该图片的类别。
过程:
1.输入一张图片,提取到这个图片的特征。
2.把特征分为语义相关和语义无关的特征。
3.使用语义相关的特征与所有属性做匹配。找到该语义相关特征对应的语义属性。(用语义相关的特征 与 属性做匹配 比原始的特征与属性匹配要准确)。
4.将该语义相关特征 与 语义属性拼接,输入到分类器中,输出类别。

怎么计算的呢(猜测)?
训练阶段,得到st之后,通过索引访问它的标签。
访问ac的标签的标签。
如果两者标签相同,则是一个匹配对。
论文上说的计算方法
论文上说用sigmoid对(s,a)进行计算,得出0或1.

# model是一个vae,此处的x_mean是生成的图片特征
x_mean, z_mu, z_var, z = model(X, C)
loss, ce, kl = multinomial_loss_function(x_mean, X, z_mu, z_var, z, beta=beta)
sample_labels = np.array(sample_label)
re_batch_labels = []
for label in labels_numpy:
index = np.argwhere(sample_labels == label)
re_batch_labels.append(index[0][0])
re_batch_labels = torch.LongTensor(re_batch_labels)
one_hot_labels = torch.zeros(opt.batchsize, sample_C_n).scatter_(1, re_batch_labels.view(-1, 1), 1).to(opt.gpu)
# one_hot_labels = torch.tensor(
# torch.zeros(opt.batchsize, sample_C_n).scatter_(1, re_batch_labels.view(-1, 1), 1)).to(opt.gpu)
# 输入生成的图片样本x_mean 得出语义相关的特征hs1和语义无关的特征hn1
x1, h1, hs1, hn1 = ae(x_mean)
relations = relationNet(hs1, sample_C)
relations = relations.view(-1, labels.unique().cpu().shape[0])
p_loss = opt.ga * mse(relations, one_hot_labels)
x2, h2, hs2, hn2 = ae(X)
relations = relationNet(hs2, sample_C)
relations = relations.view(-1, labels.unique().cpu().shape[0])
p_loss = p_loss + opt.ga * mse(relations, one_hot_labels)
rec = mse(x1, X) + mse(x2, X)
根据语义相关的特征和对应的语义属性特征训练一个网络
class RelationNet(nn.Module):
def __init__(self, args):
super(RelationNet, self).__init__()
self.fc1 = nn.Linear(args.C_dim + args.S_dim, 2048)
self.fc2 = nn.Linear(2048, 1)
def forward(self, s, c):
c_ext = c.unsqueeze(0).repeat(s.shape[0], 1, 1)
cls_num = c_ext.shape[1]
s_ext = torch.transpose(s.unsqueeze(0).repeat(cls_num, 1, 1), 0, 1)
relation_pairs = torch.cat((s_ext, c_ext), 2).view(-1, c.shape[1] + s.shape[1])
relation = nn.ReLU()(self.fc1(relation_pairs))
relation = nn.Sigmoid()(self.fc2(relation))
return relation
最终的分类函数
model
class LINEAR_LOGSOFTMAX(nn.Module):
def __init__(self, input_dim, nclass):
super(LINEAR_LOGSOFTMAX, self).__init__()
self.fc = nn.Linear(input_dim, nclass)
self.logic = nn.LogSoftmax(dim=1)
def forward(self, x):
o = self.logic(self.fc(x))
return o
def fit_zsl(self):
best_acc = 0
mean_loss = 0
last_loss_epoch = 1e8
for epoch in range(self.nepoch):
for i in range(0, self.ntrain, self.batch_size):
self.model.zero_grad()
batch_input, batch_label = self.next_batch(self.batch_size)
self.input.copy_(batch_input)
self.label.copy_(batch_label)
inputv = Variable(self.input)
labelv = Variable(self.label)
output = self.model(inputv)
loss = self.criterion(output, labelv)
mean_loss += loss.item()
loss.backward()
self.optimizer.step()
acc = self.val(self.test_unseen_feature, self.test_unseen_label, self.unseenclasses)
if acc > best_acc:
best_acc = acc
return best_acc * 100
import torch.optim as optim
import glob
import json
import argparse
import os
import random
import math
from time import gmtime, strftime
from models import *
from dataset_GBU import FeatDataLayer, DATA_LOADER
from utils import *
from sklearn.metrics.pairwise import cosine_similarity
import torch.backends.cudnn as cudnn
import classifier
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', default='SUN',help='dataset: CUB, AWA2, APY, FLO, SUN')
parser.add_argument('--dataroot', default='./data', help='path to dataset')
parser.add_argument('--workers', type=int, help='number of data loading workers', default=4)
parser.add_argument('--image_embedding', default='res101', type=str)
parser.add_argument('--class_embedding', default='att', type=str)
parser.add_argument('--gen_nepoch', type=int, default=400, help='number of epochs to train for')
parser.add_argument('--lr', type=float, default=0.0001, help='learning rate to train generater')
parser.add_argument('--zsl', type=bool, default=False, help='Evaluate ZSL or GZSL')
parser.add_argument('--finetune', type=bool, default=False, help='Use fine-tuned feature')
parser.add_argument('--ga', type=float, default=15, help='relationNet weight')
parser.add_argument('--beta', type=float, default=1, help='tc weight')
parser.add_argument('--weight_decay', type=float, default=1e-6, help='weight_decay')
parser.add_argument('--dis', type=float, default=3, help='Discriminator weight')
parser.add_argument('--dis_step', type=float, default=2, help='Discriminator update interval')
parser.add_argument('--kl_warmup', type=float, default=0.01, help='kl warm-up for VAE')
parser.add_argument('--tc_warmup', type=float, default=0.001, help='tc warm-up')
parser.add_argument('--vae_dec_drop', type=float, default=0.5, help='dropout rate in the VAE decoder')
parser.add_argument('--vae_enc_drop', type=float, default=0.4, help='dropout rate in the VAE encoder')
parser.add_argument('--ae_drop', type=float, default=0.2, help='dropout rate in the auto-encoder')
parser.add_argument('--classifier_lr', type=float, default=0.001, help='learning rate to train softmax classifier')
parser.add_argument('--classifier_steps', type=int, default=50, help='training steps of the classifier')
parser.add_argument('--batchsize', type=int, default=64, help='input batch size')
parser.add_argument('--nSample', type=int, default=1200, help='number features to generate per class')
parser.add_argument('--disp_interval', type=int, default=200)
parser.add_argument('--save_interval', type=int, default=10000)
parser.add_argument('--evl_interval', type=int, default=400)
parser.add_argument('--evl_start', type=int, default=0)
parser.add_argument('--manualSeed', type=int, default=5606, help='manual seed')
parser.add_argument('--latent_dim', type=int, default=20, help='dimention of latent z')
parser.add_argument('--q_z_nn_output_dim', type=int, default=128, help='dimention of hidden layer in encoder')
parser.add_argument('--S_dim', type=int, default=1024)
parser.add_argument('--NS_dim', type=int, default=1024)
parser.add_argument('--gpu', default='0', type=str, help='index of GPU to use')
opt = parser.parse_args()
if opt.manualSeed is None:
opt.manualSeed = random.randint(1, 10000)
print("Random Seed: ", opt.manualSeed)
np.random.seed(opt.manualSeed)
random.seed(opt.manualSeed)
torch.manual_seed(opt.manualSeed)
torch.cuda.manual_seed_all(opt.manualSeed)
cudnn.benchmark = True
print('Running parameters:')
print(json.dumps(vars(opt), indent=4, separators=(',', ': ')))
opt.gpu = torch.device("cuda:"+opt.gpu if torch.cuda.is_available() else "cpu")
def train():
dataset = DATA_LOADER(opt)
opt.C_dim = dataset.att_dim
opt.X_dim = dataset.feature_dim
opt.Z_dim = opt.latent_dim
opt.y_dim = dataset.ntrain_class
out_dir = 'out/{}/wd-{}_b-{}_g-{}_lr-{}_sd-{}_dis-{}_nS-{}_nZ-{}_bs-{}'.format(opt.dataset, opt.weight_decay,
opt.beta, opt.ga, opt.lr,
opt.S_dim, opt.dis, opt.nSample, opt.Z_dim, opt.batchsize)
os.makedirs(out_dir, exist_ok=True)
print("The output dictionary is {}".format(out_dir))
log_dir = out_dir + '/log_{}.txt'.format(opt.dataset)
with open(log_dir, 'w') as f:
f.write('Training Start:')
f.write(strftime("%a, %d %b %Y %H:%M:%S +0000", gmtime()) + '\n')
dataset.feature_dim = dataset.train_feature.shape[1]
opt.X_dim = dataset.feature_dim
opt.Z_dim = opt.latent_dim
opt.y_dim = dataset.ntrain_class
data_layer = FeatDataLayer(dataset.train_label.numpy(), dataset.train_feature.cpu().numpy(), opt)
opt.niter = int(dataset.ntrain/opt.batchsize) * opt.gen_nepoch
result_gzsl_soft = Result()
result_zsl_soft = Result()
# 注意 model是vae
model = VAE(opt).to(opt.gpu)
relationNet = RelationNet(opt).to(opt.gpu)
discriminator = Discriminator(opt).to(opt.gpu)
ae = AE(opt).to(opt.gpu)
print(model)
with open(log_dir, 'a') as f:
f.write('\n')
f.write('Generative Model Training Start:')
f.write(strftime("%a, %d %b %Y %H:%M:%S +0000", gmtime()) + '\n')
start_step = 0
optimizer = optim.Adam(model.parameters(), lr=opt.lr, weight_decay=opt.weight_decay)
relation_optimizer = optim.Adam(relationNet.parameters(), lr=opt.lr, weight_decay=opt.weight_decay)
dis_optimizer = optim.Adam(discriminator.parameters(), lr=opt.lr, weight_decay=opt.weight_decay)
ae_optimizer = optim.Adam(ae.parameters(), lr=opt.lr, weight_decay=opt.weight_decay)
ones = torch.ones(opt.batchsize, dtype=torch.long, device=opt.gpu)
zeros = torch.zeros(opt.batchsize, dtype=torch.long, device=opt.gpu)
mse = nn.MSELoss().to(opt.gpu)
iters = math.ceil(dataset.ntrain/opt.batchsize)
beta = 0.01
coin = 0
gamma = 0
for it in range(start_step, opt.niter+1):
if it % iters == 0:
beta = min(opt.kl_warmup*(it/iters), 1)
gamma = min(opt.tc_warmup * (it / iters), 1)
blobs = data_layer.forward()
feat_data = blobs['data']
labels_numpy = blobs['labels'].astype(int)
labels = torch.from_numpy(labels_numpy.astype('int')).to(opt.gpu)
C = np.array([dataset.train_att[i,:] for i in labels])
C = torch.from_numpy(C.astype('float32')).to(opt.gpu)
X = torch.from_numpy(feat_data).to(opt.gpu)
sample_C = torch.from_numpy(np.array([dataset.train_att[i, :] for i in labels.unique()])).to(opt.gpu)
sample_C_n = labels.unique().shape[0]
sample_label = labels.unique().cpu()
# model是VAE
x_mean, z_mu, z_var, z = model(X, C)
loss, ce, kl = multinomial_loss_function(x_mean, X, z_mu, z_var, z, beta=beta)
sample_labels = np.array(sample_label)
re_batch_labels = []
for label in labels_numpy:
index = np.argwhere(sample_labels == label)
re_batch_labels.append(index[0][0])
re_batch_labels = torch.LongTensor(re_batch_labels)
one_hot_labels = torch.zeros(opt.batchsize, sample_C_n).scatter_(1, re_batch_labels.view(-1, 1), 1).to(opt.gpu)
# one_hot_labels = torch.tensor(
# torch.zeros(opt.batchsize, sample_C_n).scatter_(1, re_batch_labels.view(-1, 1), 1)).to(opt.gpu)
'''
ae是解纠缠自编码器。x1是重构的x_mean
h1是编码器提取的特征
hs1和hn1是语义相关的特征和语义无关的特征
'''
x1, h1, hs1, hn1 = ae(x_mean)
relations = relationNet(hs1, sample_C)
relations = relations.view(-1, labels.unique().cpu().shape[0])
p_loss = opt.ga * mse(relations, one_hot_labels)
x2, h2, hs2, hn2 = ae(X)
relations = relationNet(hs2, sample_C)
relations = relations.view(-1, labels.unique().cpu().shape[0])
p_loss = p_loss + opt.ga * mse(relations, one_hot_labels)
rec = mse(x1, X) + mse(x2, X)
if coin > 0:
s_score = discriminator(h1)
tc_loss = opt.beta * gamma *((s_score[:, :1] - s_score[:, 1:]).mean())
s_score = discriminator(h2)
tc_loss = tc_loss + opt.beta * gamma* ((s_score[:, :1] - s_score[:, 1:]).mean())
loss = loss + p_loss + rec + tc_loss
coin -= 1
else:
s, n = permute_dims(hs1, hn1)
b = torch.cat((s, n), 1).detach()
s_score = discriminator(h1)
n_score = discriminator(b)
tc_loss = opt.dis * (F.cross_entropy(s_score, zeros) + F.cross_entropy(n_score, ones))
s, n = permute_dims(hs2, hn2)
b = torch.cat((s, n), 1).detach()
s_score = discriminator(h2)
n_score = discriminator(b)
tc_loss = tc_loss + opt.dis * (F.cross_entropy(s_score, zeros) + F.cross_entropy(n_score, ones))
dis_optimizer.zero_grad()
tc_loss.backward(retain_graph=True)
dis_optimizer.step()
loss = loss + p_loss + rec
coin += opt.dis_step
optimizer.zero_grad()
relation_optimizer.zero_grad()
ae_optimizer.zero_grad()
loss.backward()
optimizer.step()
relation_optimizer.step()
ae_optimizer.step()
if it % opt.disp_interval == 0 and it:
log_text = 'Iter-[{}/{}]; loss: {:.3f}; kl:{:.3f}; p_loss:{:.3f}; rec:{:.3f}; tc:{:.3f}; gamma:{:.3f};'.format(it,
opt.niter, loss.item(),kl.item(),p_loss.item(),rec.item(), tc_loss.item(), gamma)
log_print(log_text, log_dir)
if it % opt.evl_interval == 0 and it > opt.evl_start:
model.eval()
ae.eval()
# 不可见类:先根据VAE生成视觉特征 然后 输入到解纠缠生成器中生成语义相关和语义无关的视觉特征
gen_feat, gen_label = synthesize_feature_test(model, ae, dataset, opt)
with torch.no_grad():
# 将可见类输入到解纠缠编码器,得到语义相关的视觉特征和语义无关的视觉特征。
train_feature = ae.encoder(dataset.train_feature.to(opt.gpu))[:,:opt.S_dim].cpu()
test_unseen_feature = ae.encoder(dataset.test_unseen_feature.to(opt.gpu))[:,:opt.S_dim].cpu()
test_seen_feature = ae.encoder(dataset.test_seen_feature.to(opt.gpu))[:,:opt.S_dim].cpu()
# 拼接解纠缠后的 可见类特征 和 生成的不可见类特征
train_X = torch.cat((train_feature, gen_feat), 0)
train_Y = torch.cat((dataset.train_label, gen_label + dataset.ntrain_class), 0)
if opt.zsl:
"""ZSL"""
cls = classifier.CLASSIFIER(opt, gen_feat, gen_label, dataset, test_seen_feature, test_unseen_feature,
dataset.ntrain_class + dataset.ntest_class, True, opt.classifier_lr, 0.5, 20,
opt.nSample, False)
result_zsl_soft.update(it, cls.acc)
log_print("ZSL Softmax:", log_dir)
log_print("Acc {:.2f}% Best_acc [{:.2f}% | Iter-{}]".format(
cls.acc, result_zsl_soft.best_acc, result_zsl_soft.best_iter), log_dir)
else:
""" GZSL"""
# 用解纠缠后的可见类特征 和 生成的不可见类特征 训练一个分类器
# 该分类器就是一个 LINEAR_LOGSOFTMAX(self.input_dim, self.nclass)
cls = classifier.CLASSIFIER(opt, train_X, train_Y, dataset, test_seen_feature, test_unseen_feature,
dataset.ntrain_class + dataset.ntest_class, True, opt.classifier_lr, 0.5,
opt.classifier_steps, opt.nSample, True)
result_gzsl_soft.update_gzsl(it, cls.acc_seen, cls.acc_unseen, cls.H)
log_print("GZSL Softmax:", log_dir)
log_print("U->T {:.2f}% S->T {:.2f}% H {:.2f}% Best_H [{:.2f}% {:.2f}% {:.2f}% | Iter-{}]".format(
cls.acc_unseen, cls.acc_seen, cls.H, result_gzsl_soft.best_acc_U_T, result_gzsl_soft.best_acc_S_T,
result_gzsl_soft.best_acc, result_gzsl_soft.best_iter), log_dir)
if result_gzsl_soft.save_model:
files2remove = glob.glob(out_dir + '/Best_model_GZSL_*')
for _i in files2remove:
os.remove(_i)
save_model(it, model, opt.manualSeed, log_text,
out_dir + '/Best_model_GZSL_H_{:.2f}_S_{:.2f}_U_{:.2f}.tar'.format(result_gzsl_soft.best_acc,
result_gzsl_soft.best_acc_S_T,
result_gzsl_soft.best_acc_U_T))
###############################################################################################################
# retrieval code
###############################################################################################################
model.train()
ae.train()
if it % opt.save_interval == 0 and it:
save_model(it, model, opt.manualSeed, log_text,
out_dir + '/Iter_{:d}.tar'.format(it))
print('Save model to ' + out_dir + '/Iter_{:d}.tar'.format(it))
if __name__ == "__main__":
train()