前言
es底层复用的Lucene的能力,Lucene在以前的文章中有所讲解,感兴趣可查看 https://blog.csdn.net/u013978512/article/details/125474873?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169771769916777224433628%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=169771769916777224433628&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-1-125474873-null-null.nonecase&utm_term=Lucene&spm=1018.2226.3001.4450
本文主要讲解es的数据存储过程。
Lucene中, 倒排索引一旦被创建就不可改变, 要添加或修改文档, 就需要重建整个倒排索引, 这就对一个index所能包含的数据量, 或index可以被更新的频率造成了很大的限制.
为了在保持不变性的前提下更新倒排索引,Lucene引入了一种新的方法:使用更多的索引。通过增加新的补充索引来反映最新的修改,而不是直接重写整个倒排索引。这样可以确保从最早的版本开始,每个倒排索引都可以被查询到,并在查询完成后将结果进行合并。下面我们通过es的推演过程,来分析es是怎么能够实现当前的这种查询速度和稳定性的。
es索引的推演过程
我们知道,数据最终是要保存到磁盘上的,所以,最简单的存储过程,就是来一条数据,就同步到磁盘上,如下图
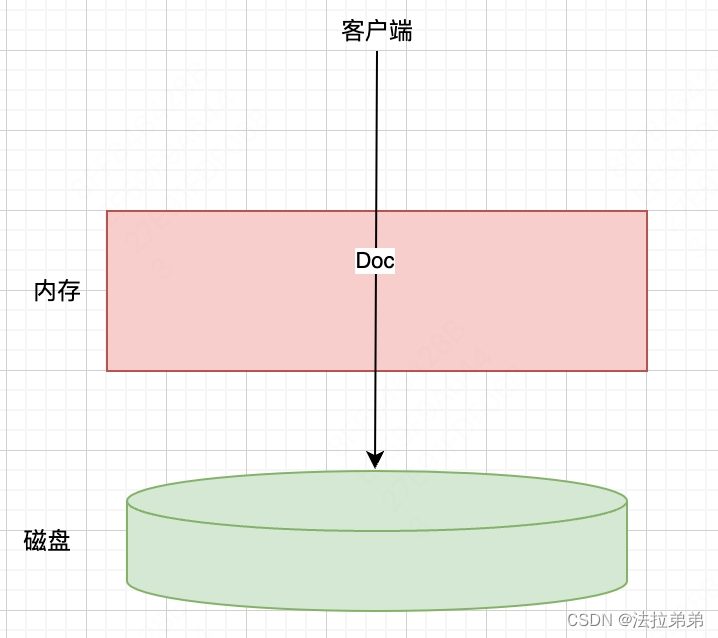
但是大家应该知道,磁盘操作是很耗时的,磁盘的随机存取的速度和内存相比,至少要大3至4个数量级,所以这种方式是不可取的。所以如果想达到es的近实时搜索的效果,那么一定是缩小数据同步到磁盘的时间,或者说缩小数据从写入到可提供搜索的时间。
因为每来一条就同步至磁盘性能太差,所以很容易想到能不能在内存中开辟一个缓冲区,等攒了一些数据之后,批量同步至磁盘
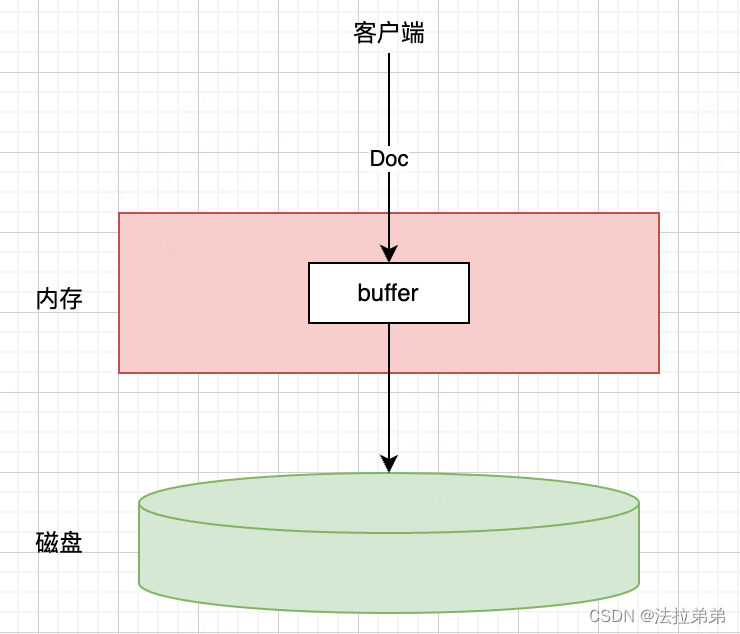
这样虽然减少了磁盘IO的频率,但是因为文档内容同步到file中才能被索引到,如果一直等到buffer满了之后再同步到磁盘,就会导致time delay严重。
为了解决上面的问题,我们可以OS自己的能力
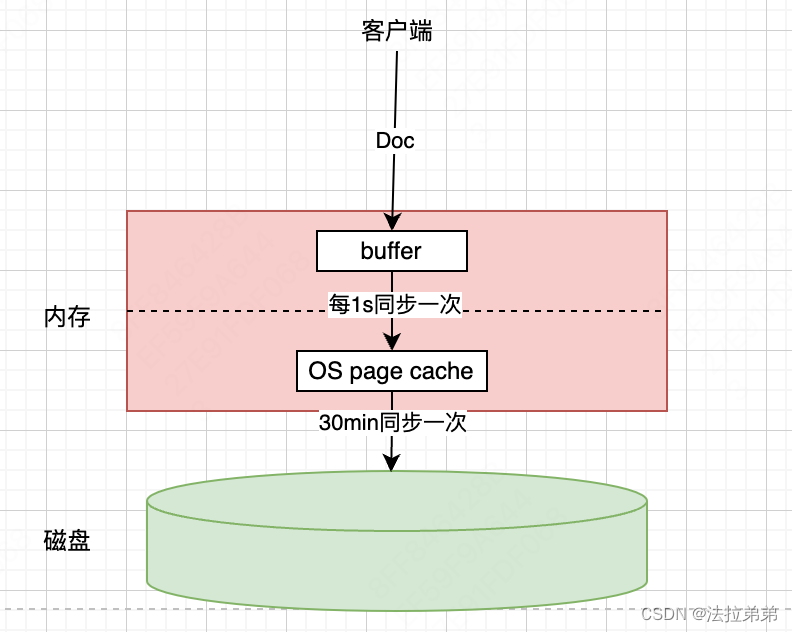
page cache是OS提供的能力,即虽然数据还在内存中,但是可以认为就是正常的file,已经可以对外提供搜索能力了。这样,就可以把buffer中的文档数据相对频繁的同步给OS page cache,虽然频繁,但是毕竟是内存之间的操作,要比同步至磁盘快得多。es默认的buffer同步OS page cache的频率是1qps,OS page cache中的内容毕竟还是在内存中的,并不安全,最终还是要同步至磁盘中。es默认30min同步一次磁盘。
大家从上面图示来看,感觉已经很完美了,降低了进实时搜索的time delay。是的,这个模型事实上是已经可以提供es的读写能力了。但是,内存中的数据掉电是会丢失的,现在OS page cache同步到磁盘是30min一次,那么如果快到30min的时候,突然停电了,那么OS page cache中的数据就会全部丢失掉,未同步到磁盘的数据就再也找不到了。为了尽量避免前面提到的问题,es又增加了translog。
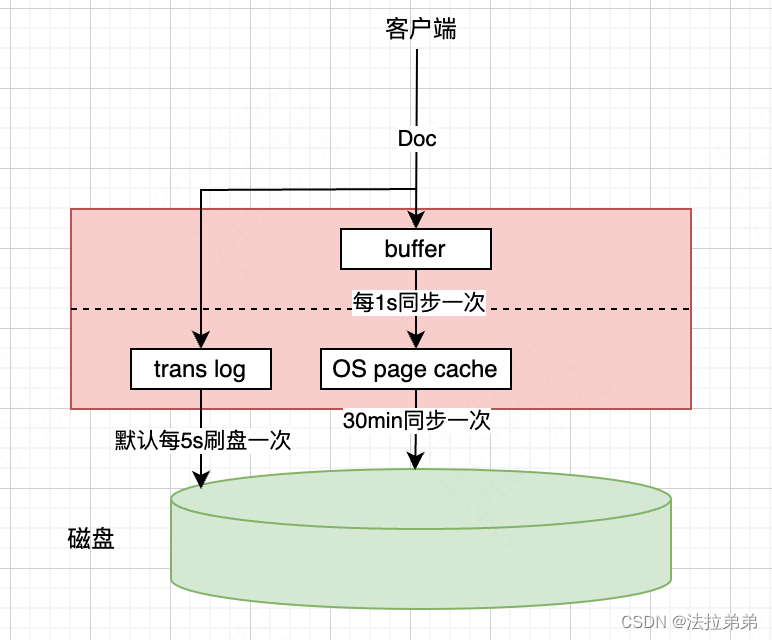
文档数据写到buffer的同时,会写到translog中,translog也是file,最终会同步至磁盘,从上图可以看到,translog每5s同步一次磁盘,这样如果OS page cache中的数据还未执行同步至磁盘的动作就停电了,怎么办呢?这时候,因为translog的绝大多数数据已经同步到磁盘了,所以在重启的时候可以通过translog重做最近的数据,当然,因为translog每5s同步一次,所以可能会丢失几秒的数据,如果还要降低丢失几秒数据的概率,可以引入多副本。
上面肯定会有人有疑问:既然translog也要同步磁盘,那么直接让OS page cache同步磁盘的时间间隔由30min降到5s不就可以了吗?为什么还要多此一举搞出个log。原因就是translog是append-only的方式同步至磁盘的,这种追加的方式减少了磁盘的寻道过程,速度还是相当惊人的(有些资料显示追加方式写磁盘和内存操作的速度基本在同一个数量级,kafka就是通过append-only方式保存消息的,但是kafka的速度之快,大家是公认的)。
es存储过程
- 索引数据在写入内存buffer(缓冲区)的同时, 也写入到translog日志文件中;
- 每隔refresh_interval的时间就执行一次refresh:
2.1 将buffer中的数据作为新的 index segment, 刷到文件系统的cache(缓存)中;
2.2 index segment一旦被写入文件cache(缓存), 就立即打开该segment供搜索使用; - 清空当前内存buffer(缓冲区), 等待接收新的文档;
- 重复①~③, translog文件中的数据不断增加;
- 每隔一定时间(默认30分钟), 或者当translog文件达到一定大小时, 发生flush操作, 并执行一次全量提交:
5.1 将此时内存buffer(缓冲区)中的所有数据写入一个新的segment, 并commit到文件系统的cache中;
5.2 打开这个新的segment, 供搜索使用;
5.3 清空当前的内存buffer(缓冲区);
5.4 将translog文件中的所有segment通过fsync强制刷到磁盘上;
5.5 将此次写入磁盘的所有segment记录到commit point中, 并写入磁盘;
5.6 删除当前translog, 创建新的translog接收下一波创建请求.
写入过程优化
存在的问题
从上述的近实时搜索特性中,我们可以了解到,Elasticsearch(ES)默认每秒都会生成一个新的segment文件,而在每次进行搜索查询时,它需要遍历所有的这些segment文件,这无疑会对搜索性能产生不小的影响。
为了解决这一问题,ES会对这些零散的segment文件进行合并(merge)操作,这种操作旨在将索引中大量的、体积较小的segment文件整合为数量更少、体积更大的segment文件。这种方法大大减少了搜索时需要处理的文件数量,从而显著提高了搜索效率。
负责进行这个合并过程的是独立的merge线程,它的工作不会影响到新的segment文件的生成。同时,在进行segment文件的合并过程中,被标记为删除的文档也会被彻底地从物理存储中删除。
merge操作的流程
- 准备阶段:Elasticsearch会定期检查索引中的segment文件。当检测到有太多的segment文件(默认情况下,当segment数量超过10%时),它将开始为merge做准备。
- 选出待合并的segment:准备阶段完成后,Elasticsearch会选出那些需要合并的segment。一般来说,这些segment都是较小的,且在最近的merge窗口内创建的。
- 创建新的segment:在选出待合并的segment后,Elasticsearch会为新的segment分配一个新的、唯一的ID。这个新的segment会包含所有待合并的segment中的数据。
- 合并数据:接下来,Elasticsearch会从每个待合并的segment中读取数据,然后将这些数据写入新的segment。在这个过程中,Elasticsearch会处理任何可能出现的冲突,例如两个segment中都有相同的文档,但文档的状态不同。
- 标记已合并的segment:当一个新的segment创建完成后,Elasticsearch会将所有待合并的segment标记为已合并,以便下次合并时不再考虑这些segment。
- 更新索引结构:最后,Elasticsearch会更新其索引结构,将新的segment添加到索引中,并从索引中移除已合并的segment。
需要注意的是,虽然merge操作可以提高搜索性能,但也会占用大量的CPU和I/O资源。因此,Elasticsearch通常会在后台、低流量时段执行merge操作,以最小化对系统性能的影响。