目录
1 前言
2 集成利器Docker
2.1 Docker环境安装
2.1.1 环境检查
2.1.2 在线安装
2.1.3 离线安装
2.2 Docker-Compose的安装
2.2.1 概念简介
2.2.2 安装步骤
2.2.2.1 二进制文件安装
2.2.2.2 离线安装
2.2.2.3 yum安装
3 一键安装ES及Kibana
3.1 yml文件的编写
3.1.1 elasticsearch.yml配置
3.1.2 kibana.yml配置
3.2 一键安装
3.3 部署验证
3.4 常见问题
4 安装IK分词插件
4.1 IK分词的下载及安装
4.2 IK分词的使用
5 安装IK同义词插件
5.1 同义词插件改造
5.2 同义词插件部署
5.3 同义词插件使用
5.4 其他注意事项
6 ES日志打印
6.1 打印ES启动日志
6.2 日志格式以及时区调整
1 前言
最近在做搜索引擎相关的项目,搜索使用ES+Milvus。搜索是一个大课题,像京东、淘宝等首页的搜索是常见的场景。 搜索的又可以根据需要划分为不同的阶段,比如预处理、粗召、粗排、精排、重排等等流程。 很多时候商品因为类目挂载的问题,召回的效果差强人意,往往还会引入向量搜索进行矫正。关于搜索引擎的细节这里不展开讲,今天主要记录下如何快速安装ES以及ES对应的IK插件、同义词插件。
2 集成利器Docker
Docker绝对是部署集成的利器,相当方面和便捷,我对docker的使用连入门的级别都还达不到,这里不班门弄斧。重点就记录下在整个过程中,遇到和用到的一些细节点。
docker能干嘛?
① 一次构建,随处运行
② 更快速的应用交付和部署
传统的应用开发完成后,需要提供一堆安装程序和配置说明文档,安装部署后需根据配置文档进行繁杂的配置才能正常运行。Docker化之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像里已经内置好,大大节省部署配置和测试验证时间。
③ 更便捷的升级和扩缩容
随着微服务架构和Docker的发展,大量的应用会通过微服务方式架构,应用的开发构建将变成搭乐高积木一样,每个Docker容器将变成一块“积木”,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容。
④ 更简单的运维
⑤ 更高效的计算资源利用
一台物理机上可以运行很多个容器实例,可大大提升物理服务器的CPU和内存的利用率。
2.1 Docker环境安装
2.1.1 环境检查
docker安装之前,先检查是否满足以下要求:
① 确保操作系统为64位版本且内核版本不低于3.10
# 查看内核的方式:
uname -a
# 或者
cat /proc/version② 确保操作系统为Linux系统,Windows系统需要先安装适用于本地环境的虚拟机管理器(VirtualBox等),Mac系统需要先安装Homebrew工具
#查看操作系统的方式
lsb_release -a
# 或者
cat /etc/redhat-release③ 确保拥有sudo权限,这将允许在系统中安装软件包。安装前因个人情况执行下面命令
- 需用root用户安装
- 使用root权限更新yum包(项目上生产环境需谨慎),`yum -y update`这个命令不是必须执行,看个人情况,后面出现不兼容的情况的话就必须update了。
# 升级所有包同时也升级软件和系统内核
yum -y update
#只升级所有包,不升级软件和系统内核
yum -y upgrade- 卸载旧版本(如果之前安装过的话)
yum remove docker docker-common docker-selinux docker-engine2.1.2 在线安装
① 安装需要的软件包, yum-util 提供yum-config-manager功能,另两个是devicemapper驱动依赖
yum install -y yum-utils device-mapper-persistent-data lvm2② 设置yum源
# 阿里仓库
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo③ 选择可用版本
# 查看有哪些可用的版本
yum list docker-ce --showduplicates | sort -r④ 选择一个版本并安装
yum -y install docker-ce-18.03.1.ce⑤.第三步和第四步不执行,不选版本安装的话,默认安装最新版本
yum install docker-ce⑥ 启动docker
systemctl start docker⑦ 验证docker是否安装成功
docker version⑧ 设置开机自启动
systemctl enable docker2.1.3 离线安装
离线安装比较简单,下载安装包,上传服务,解压,然后启动即可。
# ① docker离线安装包下载
https://download.docker.com/linux/static/stable/x86_64/docker-20.10.7.tgz
# ② 上传到服务器,然后解压
tar -zxvf docker-20.10.7.tgz
cp docker/* /usr/bin/
# ③ 启动Docker守护程序
dockerd &
# ④ 验证docker是否安装成功
docker info2.2 Docker-Compose的安装
2.2.1 概念简介
docker-compose简介
Docker Compose是一个用来定义和运行多个复杂应用的Docker编排工具。例如,一个使用Docker容器的微服务项目,通常由多个容器应用组成。那么部署时不想一个一个的部署且一个一个的手动启动,那么使用Docker Compose编排工具便可快速部署启动容器。
Compose 通过一个配置文件来管理多个Docker容器,在配置文件中,所有的容器通过services来定义,然后使用docker-compose脚本来启动,停止和重启应用和应用中的服务以及所有依赖服务的容器,非常适合组合使用多个容器进行开发的场景。
docker-compose的理念
docker-compose是docker官方的开源项目,托管于github上,由python实现,负责实现对docker容器集群的快速编排。
docker-compose将所管理的容器分为三层, 分别是项目(project),服务(service)以及容器(containner)
最重要的两个概念① 服务 (service):一个应用的容器,实际上可以包括若干运行相同镜像的容器实例。
② 项目 (project):由一组关联的应用容器组成的一个完整业务单元,在 docker-compose.yml 文件中定义。Compose 的默认管理对象是项目,通过子命令对项目中的一组容器进行便捷地生命周期管理。
一个项目当中,可以包含多个服务,每个服务中定义了容器运行的镜像、参数、依赖。
docker-compose的项目配置文件默认是**docker-compose.yml**。可以通过环境变量COMPOSE_FILE -f 参数自定义配置文件,其自定义多个有依赖关系的服务及每个人服务运行的容器。
简单来说:就是来管理多个容器的,定义启动顺序的,合理编排,方便管理。
2.2.2 安装步骤
2.2.2.1 二进制文件安装
# 官方地址
https://github.com/docker/compose/releases/tag/v2.21.0
# 根据docker版本选择对应的docker-compose
# ① 这里我下载的最新版2.21.0,在服务器上用root用户执行下面命令:
wget https://github.com/docker/compose/releases/download/v2.21.0/docker-compose-Linux-x86_64
# ② 将docker-compose-linux-x86_64重命名为docker-compose
mv docker-compose-linux-x86_64 docker-compose
# ③ 将docker-compose移到/usr/local/bin/目录下
mv docker-compose /usr/local/bin/
# ④ 修改该文件的权限为可执行
chmod +x /usr/local/bin/docker-compose
# ⑤ 为方便后期操作,配置环境变量,修改~/.bashrc文件,将/usr/local/bin添加至PATH中
vim ~/.bashrc
export PATH="$PATH:/usr/local/bin"
# ⑥ 重新加载.bashrc文件配置
source ~/.bashrc
# ⑦ 查看docker-compose的版本检查是否安装成功
docker-compose version2.2.2.2 离线安装
安装包下载地址:点击我
下载好安装包之后,上传安装包到服务,执行如下命令:
chmod +x /usr/local/bin/docker-compose
docker-compose version安装过程中可能会遇到一下问题:
① 若执行docker-compose version后出现如下报错安装失败,是因为安装包没有下载完全,重新下载安装。或者到上面官方地址上手动下载然后传到服务器/usr/local/bin/目录下。
/usr/local/bin/docker-compose:行1: html: 没有那个文件或目录 /usr/local/bin/d
/usr/local/bin/docker-compose:行2:未预期的符号'<'附近有语法错误
/usr/local/bin/docker-compose:行3:'<head><title>502 Bad Gateway</title></head>'
② 安装完成后运行docker-compose version 出现如下错误,是因为安装版本问题,更换版本重新安装。
Segmentation fault“(分段错误)
2.2.2.3 yum安装
# 用root用户执行
yum install docker-compose
#查看docker-compose的版本(看是否安装部署成功)
docker-compose version3 一键安装ES及Kibana
一个yml文件搞定全部,docker-compose绝对是部署集成的大杀器。 再次对技术的日新月异感到惊叹和焦虑。
ES版本:7.8.0
3.1 yml文件的编写
yml文件如下
version: '3.5'
services:
elasticsearch:
image: elasticsearch:7.8.0
container_name: elasticsearch
networks:
- elastic_network
volumes:
- ./es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./es/config/log4j2.properties:/usr/share/elasticsearch/config/log4j2.properties
- ./es/config/jvm.options:/usr/share/elasticsearch/config/jvm.options
- ./es/data:/usr/share/elasticsearch/data
- ./es/plugins:/usr/share/elasticsearch/plugins
- ./es/logs:/usr/share/elasticsearch/logs
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms2048m -Xmx4096m"
- TZ=Asia/Shanghai
ports:
- "9200:9200"
kibana:
image: kibana:7.8.0
ports:
- "5601:5601"
volumes:
- ./kibana/kibana.yml:/usr/share/kibana/config/kibana.yml
networks:
- elastic_network
#这里要注意,es和eshd要在相同网络才能被links
networks:
elastic_network:
driver: bridge
ipam:
config:
- subnet: 172.22.0.0/16有几个注意点:
① volumes这个配置比较重要,这是将容器内相关需要固化以及需要保留的内容外挂到容器外面,这样容器即便重启了,相关信息也不会丢。 像/data、/plugins、/logs这些都是外挂在外面,一方面ES数据不会丢,另一方面插件可以根据需要新增,日志也方面查看。
注意:冒号前是宿主机的路径,冒号后是容器里的路径。 冒号前的路径相对当前docker-compose.yml文件的相对路径。
② networks是固定配置,可以不用管,利旧即可
3.1.1 elasticsearch.yml配置
http.port: 9200
http.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
# 开启安全控制
#xpack.security.enabled: true
#xpack.security.transport.ssl.enabled: true
#xpack.security.transport.ssl.keystore.type: PKCS12
#xpack.security.transport.ssl.verification_mode: certificate
#xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
#xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
#xpack.security.transport.ssl.truststore.type: PKCS12
#xpack.security.audit.enabled: true
path.logs: /usr/share/elasticsearch/logs3.1.2 kibana.yml配置
server.name: kibana
# kibana的主机地址 0.0.0.0可表示监听所有IP
server.host: "0.0.0.0"
#
# 这边设置自己es的地址,
elasticsearch.hosts: [ "http://127.0.0.1:9200" ]
elasticsearch.username: 'elastic'
elasticsearch.password: 'elastic'
# # 显示登陆页面
xpack.monitoring.ui.container.elasticsearch.enabled: true
# 开启中文模式
i18n.locale: "zh-CN"3.2 一键安装
到docker-compose.yml文件所在的目录,执行:
docker-compose up -d执行之后,会从中央镜像仓库拉镜像并进行安装,相当方便,执行完之后,ES和Kibana就安装上了。

注:上图是对存量镜像,直接拉起了,所以比较快。 首次的时候可能会比较耗时。
3.3 部署验证
① 命令方式查看是否正常启动
docker-compose ps如下图则为正常启动。

如果有启动失败的,相关进程不会显示。
可以通过以下命令查看日志:
# 查看所有日志
docker logs elasticsearch
# tail方式查看最后200行日志
docker logs -f --tail 200 elasticsearch如果有启动失败的,相关进程不会显示。
② 浏览器中直接访问
http://127.0.0.1:9200 显示ES的基本信息,例如:
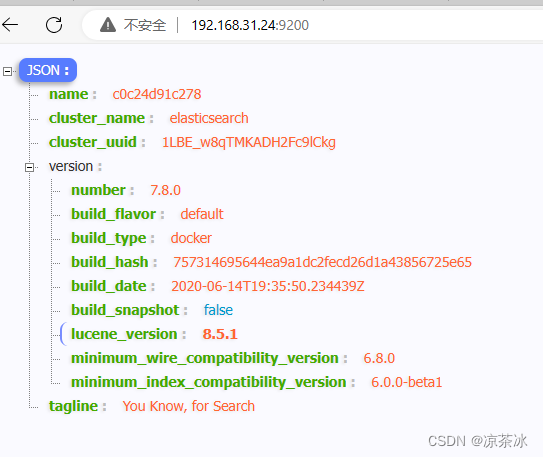
http://127.0.0.1:5601/app/kibana#/home 显示Kibana的页面信息
3.4 常见问题
ES启动失败,最常见的一个问题就是权限问题。所谓权限问题,其实主要就是外挂的目录赋权。如果是root用户部署,则给外挂的目录级联赋权chmod 777最高的权限即可。
容器正常启动之后,进入可以看到用户权限如下:

这块不展开说,我个人对Linux的文件系统以及用户、用户组没有深究,目前外挂的目录都赋予最高权限,容器可以正常启动。
进入容器的命令:
docker exec -it elasticsearch /bin/bash注意:并不是所有进入容器的方式都是如上命令,比如前几天部署的FlowiseAI,进入容器的命令就是
#41bc89efe020是镜像id
docker exec -it 41bc89efe020 /bin/sh4 安装IK分词插件
4.1 IK分词的下载及安装
参考这个链接 参考这个链接,相关版本在git上都可以下载到,具体步骤不再赘述。
4.2 IK分词的使用
IK插件按照版本号解压后,放到plugin目录下,一般情况下就可以正常使用了。 IK插件自带ik_smart和ik_max_word两个分词器,可以通过kibana验证分词器是否生效,如下:
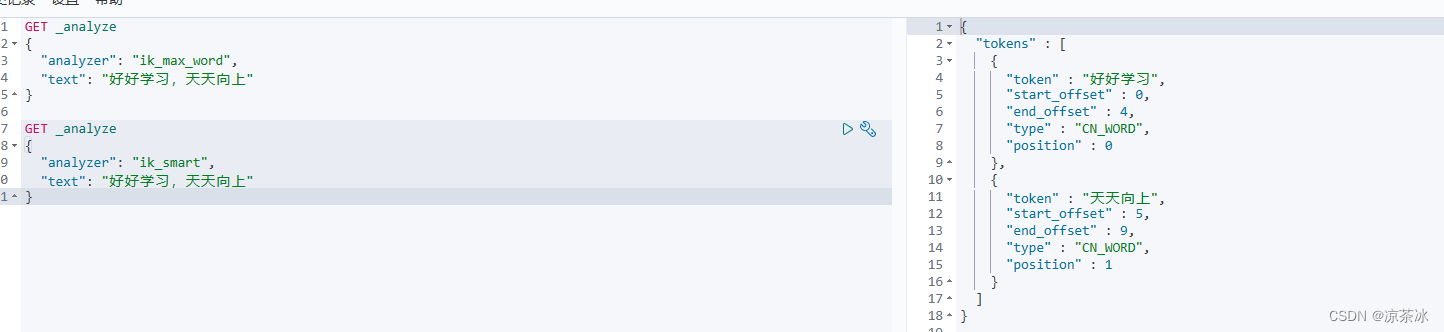
IK分词器的字典分为频用词、停用词两个,可以使用默认的字典,也可以使用在线字典。

config目录下的IKAnalyzer.cfg.xml文件是配置文件,如下:

红框圈住的部分是配置远程字典的地方,可以配置一个http连接。 字典数据可以从数据库中读取,实时热更新,下面给出一个远程字典的简单实现例子,仅供记录和参考。
@RequestMapping(value = "/wordFile", method = RequestMethod.GET)
public void exportWordFile(HttpServletRequest request,HttpServletResponse response) throws Exception {
String since=request.getHeader("If-Modified-Since");
String date=String.valueOf(new Date());
log.info("频用词If-Modified-Since:{},调用时间{}",since,date);
List<String> lastModifiedList=searchFrequentUsedWordsMapper.selectLastModified();
String lastModified=null;
if(lastModifiedList!=null&&lastModifiedList.size()>0){
lastModified= Collections.max(lastModifiedList);
}
if(lastModified!=null){
response.setHeader("Last-Modified", lastModified);
if(lastModified.equals(since)){
return;
}
}else{
response.setHeader("Last-Modified", String.valueOf(new Date()));
}
String match=request.getHeader("If-None-Match");
if(!StringUtils.isEmpty(match)){
response.setHeader("If-None-Match", match);
}else{
response.setHeader("If-None-Match", "ETag");
}
String fileName = "word.txt";
response.setCharacterEncoding("UTF-8");
response.setHeader("Content-disposition", "attachment;filename=" + fileName);
response.setContentType("text/plain");
PrintWriter output = response.getWriter();
//从数据库中查询所有的频用词
List<String> rsp=searchFrequentUsedWordsService.querAllDsWordList();
if(rsp!=null) {
log.info("频用词发生变更,最后更新时间:{},调用时间{}",lastModified,date);
for (String word : rsp) {
output.println(word);
}
}
output.close();
}5 安装IK同义词插件
IK同义词插件可以下载相近版本,然后修改pom中的版本号重新编译。
这篇博文 这篇博文关于IK同义词插件的部署、使用写的很好,这里记录下。
5.1 同义词插件改造
同义词插件下载下来之后,我们根据需要修改pom中的版本号,如下:

正常修改完版本号,就可以重新package进行打包。默认同义词插件的字典,可以走字典文件也可以走远程字典的方式。本地字典不支持热更新,比较麻烦,一般使用远程字典的方式,这里贴一个远程字典实现的例子,如下:
@RequestMapping(value = "/synonymFile", method = RequestMethod.GET)
public void exportSynonymFile(HttpServletRequest request,HttpServletResponse response) throws Exception {
String fileName = "synonyms.txt";
response.setCharacterEncoding("UTF-8");
response.setHeader("Content-disposition", "attachment;filename=" + fileName);
response.setContentType("text/plain");
String since=request.getHeader("If-Modified-Since");
log.debug("同义词If-Modified-Since:{}",since);
// String lastModified=searchSynonymWordsMapper.selectLastModified();
response.setHeader("Last-Modified", String.valueOf(new Date()));
String match=request.getHeader("If-None-Match");
if(!StringUtils.isEmpty(match)){
response.setHeader("If-None-Match", match);
}else{
response.setHeader("If-None-Match", "ETag");
}
PrintWriter output = response.getWriter();
SearchSynonymWordsRsp rsp=searchSynonymWordsService.querySynonymWordsList();
if(rsp!=null&&rsp.getRows()!=null) {
log.debug("同义词发生变更");
for (SearchSynonymWordsBO bo : rsp.getRows()) {
output.println(bo.getWordContent());
}
}
output.close();
}除了远程字典的方式,还可以使用直接从数据库中拉取同义词。基本实现原理如下:
通过集成 ES 的 AnalysisPlugin 和 Plugin 接口,在 ES 启动的时候,自动加载 plugin 插件,将名称为“dynamic_synonym”的 AnalysisProvider 生成并加载。 这 个名称是在插件的代码中定义的,在配置 analysis 的时候也会用到。 插件内容启动了一个定时任务,会定时从 DB 拉取同义词的版本号,判断版本号是否发 生了变化,如果发生了变化,那么从新拉取同义词,并同步到 ES 中。 注意:这里的同步直接通过 mysql 查询到数据就完成了同步,主要是更新 es 内存中 同义词数据。
为了实现同义词的自动同步,配合插件需要新增两张表,建表语句如下:
# 同义词版本表
DROP TABLE IF EXISTS `synonym_version`;
CREATE TABLE `synonym_version` (
`key_code` varchar(120) CHARACTER SET utf8 COLLATE utf8_general_ci
NOT NULL,
`last_modify_version` double NULL DEFAULT NULL COMMENT '版本号',
PRIMARY KEY (`key_code`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci
ROW_FORMAT = Compact;
# 同义词表
DROP TABLE IF EXISTS `sys_synonym_t`;
CREATE TABLE `sys_synonym_t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`words` varchar(1000) CHARACTER SET utf8 COLLATE utf8_general_ci NOT
NULL COMMENT '同义词',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE
= utf8_general_ci ROW_FORMAT = Compact;在录入的时候,同义词有两种格式:
① 双向同义词
这种方式,在录入同义词的时候,所有同义词通过英文逗号拼接即可,如下:

这种方式的同义词,搜索任意一个,都可以把和他相同的其他词都搜索出来。
注意:如 果一个词同时在两条记录中都存在,搜索这个词的时候,会把这两条记录里的词都查找到, 但是如果搜索的是这个词的某个同义词,只会把这个同义词对应记录的同义词搜索到,即: 不会进行非搜索词汇的级联搜索。
② 单向同义词
这种方式,是主词、副词的方式,搜索的时候,会把当前搜索的词转换成主词进行搜索 和返回,格式如下:

这种属于单向同义词,以截图为例,搜索理想的时候,会按照立项搜索。
注意: 在实际操作使用过程中,只要同义词表的数据发生了变化,就要修改版本记录表中的版 本号,让版本号加一,这样被修改的数据才会自动同步过去。
源码改造,支持从DB中读取同义词,参考这篇博客,这里不再赘述。
这里提供一个已经编译好的支持从Mysql拉取同义词的插件,点击去下载。
5.2 同义词插件部署
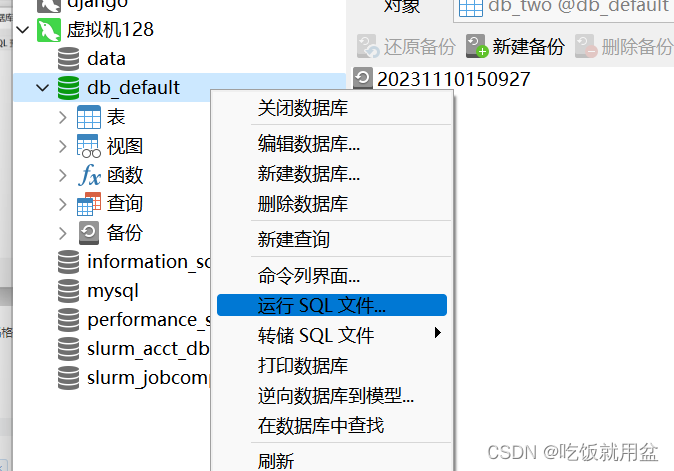
① 创建数据库表
可以将版本表和同义词表创建到任意 es 集群可以连接到的数据库中,直接执行 sql 文件即可。
② 拷贝插件
在 es 的 plugins 目录下新建 dynamic-synonym 目录,将 elasticsearch-analysis-dynamic-synonym-7.8.0.zip 解压到该目 录,解压之后,目录结构如下:

③ 修改配置文件
插件包解压之后,需要修改下 jdbc-reload.properties 文件,该配置文件如下:
# 注意修改以下 ip、port、数据库名、user、password 为第二步中对应的数据库以及用
户信息
jdbc.url=jdbc:mysql://127.0.0.1:3306/test?useUnicode=tru
e&characterEncoding=utf8&serverTimezone=Asia/Shanghai
jdbc.user=root
jdbc.password=root
jdbc.driver=com.mysql.cj.jdbc.Driver
# 查询同义词信息,保持默认,不用修改
jdbc.reload.synonym.sql=select words from sys_synonym_t
# 查询数据库同义词在数据库版本号,保持默认,不用修改
jdbc.reload.swith.synonym.version=SELECT last_modify_version FROM
synonym_version where key_code = 'synonym_doc'④ 重启ES
重启ES,到log中查看启动日志。
5.3 同义词插件使用
同义词插件安装成功之后,需要自定义分词器可以可以使用。 下面给出一个创建索引的样例,具体项目上根据需要调整:
PUT /crm_wiki
{
"settings": {
"index.max_ngram_diff": 4,
"number_of_shards": "2",
"number_of_replicas": "0",
"analysis": {
"filter": {
"mysql_synonym": {
"type": "dynamic_synonym",
"synonyms_path": "fromDB",
"interval": 30
}
},
"analyzer": {
"ik_sync_smart": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": [
"mysql_synonym"
]
},
"ik_sync_max_word": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": [
"mysql_synonym"
]
}
}
}
},
"mappings": {
"properties": {
"wiki_id": {
"type": "text"
},
"wiki_title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ik_sync_max_word"
},
"wiki_content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ik_sync_max_word"
},
"create_time": {
"type": "date"
}
}
}
}这个例子是创建了一个名为 crm_wiki 的索引。 然后在 settings 中创建了一个自定义过 滤器名为“mysql_synonym”,注意里面的 type、synonyms_path 的值是固定写法。Interval 是 词库定时刷新时间,单位是秒。默认设置的 30 秒,可以根据需要调整。
下面的 analyzer 是基于 ik 的 ik_max_word 以及 ik_smart 自定义了两个分词器,让这两 个分词器都支持同义词过滤器。 然后在 mappings 中定义字段的时候,需要使用同义词的字段,可以使用自定义的分词 器。
同样的,代码中开发时候,如果进行分词查询需要使用同义词,也可以指定分词器进 行分词查询。
如下图验证,同义词插件已生效。

5.4 其他注意事项
注意修改config/jvm.options文件,在最后添加一行配置,指定下安全权限,增加如下一行配置:
-Djava.security.policy=/usr/share/elasticsearch/plugins/dynamic-synonym/plugin-security.policy
如果不加这个,ES启动失败,这个主要是给插件赋权,可以访问mysql。
6 ES日志打印
6.1 打印ES启动日志
ES默认日志只打印gc日志,非常不方便,可以通过修改log4j2.properties配置文件来调整日志打印的情况。 前面在部署的时候,已经将logs外挂到宿主机上了,直接到对应的/config目录下修改即可,修改为如下内容:
status = error
# log action execution errors for easier debugging
logger.action.name = org.elasticsearch.action
logger.action.level = debug
appender.console.type = Console
appender.console.name = console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = [%d{yyyy-MM-dd HH:mm:ss.SSS}][%-5p][%-25c{1.}] %marker%m%n
appender.rolling.type = RollingFile
appender.rolling.name = rolling
appender.rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}.log
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = [%d{yyyy-MM-dd HH:mm:ss.SSS}][%-5p][%-25c{1.}] %marker%.-10000m%n
appender.rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}-%d{yyyy-MM-dd}.log
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
rootLogger.level = info
rootLogger.appenderRef.console.ref = console
rootLogger.appenderRef.rolling.ref = rolling
appender.deprecation_rolling.type = RollingFile
appender.deprecation_rolling.name = deprecation_rolling
appender.deprecation_rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_deprecation.log
appender.deprecation_rolling.layout.type = PatternLayout
appender.deprecation_rolling.layout.pattern = [%d{yyyy-MM-dd HH:mm:ss.SSS}][%-5p][%-25c{1.}] %marker%.-10000m%n
appender.deprecation_rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_deprecation-%i.l
og.gz
appender.deprecation_rolling.policies.type = Policies
appender.deprecation_rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.deprecation_rolling.policies.size.size = 1GB
appender.deprecation_rolling.strategy.type = DefaultRolloverStrategy
appender.deprecation_rolling.strategy.max = 4
logger.deprecation.name = org.elasticsearch.deprecation
logger.deprecation.level = warn
logger.deprecation.appenderRef.deprecation_rolling.ref = deprecation_rolling
logger.deprecation.additivity = false
appender.index_search_slowlog_rolling.type = RollingFile
appender.index_search_slowlog_rolling.name = index_search_slowlog_rolling
appender.index_search_slowlog_rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_index_sear
ch_slowlog.log
appender.index_search_slowlog_rolling.layout.type = PatternLayout
appender.index_search_slowlog_rolling.layout.pattern = [%d{yyyy-MM-dd HH:mm:ss.SSS}][%-5p][%-25c] %marker%.-10000m%n
appender.index_search_slowlog_rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_index_s
earch_slowlog-%d{yyyy-MM-dd}.log
appender.index_search_slowlog_rolling.policies.type = Policies
appender.index_search_slowlog_rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.index_search_slowlog_rolling.policies.time.interval = 1
appender.index_search_slowlog_rolling.policies.time.modulate = true
logger.index_search_slowlog_rolling.name = index.search.slowlog
logger.index_search_slowlog_rolling.level = trace
logger.index_search_slowlog_rolling.appenderRef.index_search_slowlog_rolling.ref = index_search_slowlog_rolling
logger.index_search_slowlog_rolling.additivity = false
appender.index_indexing_slowlog_rolling.type = RollingFile
appender.index_indexing_slowlog_rolling.name = index_indexing_slowlog_rolling
appender.index_indexing_slowlog_rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_index_in
dexing_slowlog.log
appender.index_indexing_slowlog_rolling.layout.type = PatternLayout
appender.index_indexing_slowlog_rolling.layout.pattern = [%d{yyyy-MM-dd HH:mm:ss.SSS}][%-5p][%-25c] %marker%.-10000m%n
appender.index_indexing_slowlog_rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_index
_indexing_slowlog-%d{yyyy-MM-dd}.log
appender.index_indexing_slowlog_rolling.policies.type = Policies
appender.index_indexing_slowlog_rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.index_indexing_slowlog_rolling.policies.time.interval = 1
appender.index_indexing_slowlog_rolling.policies.time.modulate = true
logger.index_indexing_slowlog.name = index.indexing.slowlog.index
logger.index_indexing_slowlog.level = trace
logger.index_indexing_slowlog.appenderRef.index_indexing_slowlog_rolling.ref = index_indexing_slowlog_rolling
logger.index_indexing_slowlog.additivity = false
logger.discovery.name = org.elasticsearch.discovery
logger.discovery.level = debug修改之后,可以看到,日志打印如下:

6.2 日志格式以及时区调整
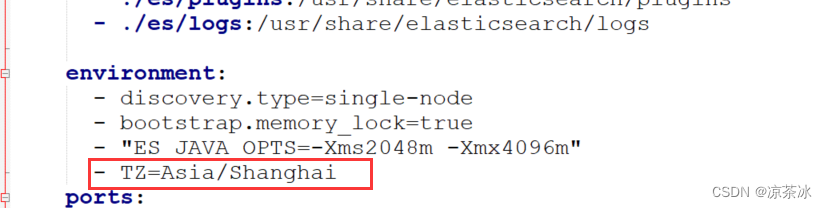
默认情况下ES使用的UTC的时区,打印的日志,时间是和实际时间相差8小时。 可以通过修改ES的时区解决。
如果使用docker-compose安装的话,可以在yml文件中添加环境变量。 如下: