1 加入依赖
首先创建一个项目,在项目中加入 ES 相关依赖,具体依赖如下所示:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.1.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.1.0</version>
</dependency>
2 创建 ES 配置
在配置文件 application.properties 中配置 ES 的相关参数,具体内容如下:
elasticsearch.host=localhost
elasticsearch.port=9200
elasticsearch.connTimeout=3000
elasticsearch.socketTimeout=5000
elasticsearch.connectionRequestTimeout=500
其中指定了 ES 的 host 和端口以及超时时间的设置,另外我们的 ES 没有添加任何的安全认证,因此 username 和 password 就没有设置。
然后在 config 包下创建 ElasticsearchConfiguration 类,会从配置文件中读取到对应的参数,接着申明一个 initRestClient 方法,返回的是一个 RestHighLevelClient,同时为它添加 @Bean(destroyMethod = “close”) 注解,当 destroy 的时候做一个关闭,这个方法主要是如何初始化并创建一个 RestHighLevelClient。
@Configuration
public class ElasticsearchConfiguration {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
@Value("${elasticsearch.connTimeout}")
private int connTimeout;
@Value("${elasticsearch.socketTimeout}")
private int socketTimeout;
@Value("${elasticsearch.connectionRequestTimeout}")
private int connectionRequestTimeout;
@Bean(destroyMethod = "close", name = "client")
public RestHighLevelClient initRestClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost(host, port))
.setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder
.setConnectTimeout(connTimeout)
.setSocketTimeout(socketTimeout)
.setConnectionRequestTimeout(connectionRequestTimeout));
return new RestHighLevelClient(builder);
}
}
3 定义文档实体类
首先在 constant 包下定义常量接口,在接口中定义索引的名字为 user:
public interface Constant {
String INDEX = "user";
}
然后在 document 包下创建一个文档实体类:
public class UserDocument {
private String id;
private String name;
private String sex;
private Integer age;
private String city;
// 省略 getter/setter
}
4 ES 基本操作
在这里主要介绍 ES 的索引、文档、搜索相关的简单操作,在 service 包下创建 UserService 类。
4.1 索引操作
在创建索引的时候可以在 CreateIndexRequest 中设置索引名称、分片数、副本数以及 mappings,在这里索引名称为 user,分片数 number_of_shards 为 1,副本数 number_of_replicas 为 0,具体代码如下所示:
public boolean createUserIndex(String index) throws IOException {
CreateIndexRequest createIndexRequest = new CreateIndexRequest(index);
createIndexRequest.settings(Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 0)
);
createIndexRequest.mapping("{\n" +
" \"properties\": {\n" +
" \"city\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"sex\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"age\": {\n" +
" \"type\": \"integer\"\n" +
" }\n" +
" }\n" +
"}", XContentType.JSON);
CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
return createIndexResponse.isAcknowledged();
}
通过调用该方法,就可以创建一个索引 user,索引信息如下:

关于 ES 的 Mapping会专门出一篇文章进行讲解
4.2 删除索引
在 DeleteIndexRequest 中传入索引名称就可以删除索引,具体代码如下所示:
public Boolean deleteUserIndex(String index) throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(index);
AcknowledgedResponse deleteIndexResponse = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
return deleteIndexResponse.isAcknowledged();
}
介绍完索引的基本操作,下面介绍文档的相关操作:
4.3 文档操作
在这里演示下创建文档、批量创建文档、查看文档、更新文档以及删除文档:
4.3.1 创建文档
创建文档的时候需要在 IndexRequest 中指定索引名称,id 如果不传的话会由 ES 自动生成,然后传入 source,具体代码如下:
public Boolean createUserDocument(UserDocument document) throws Exception {
UUID uuid = UUID.randomUUID();
document.setId(uuid.toString());
IndexRequest indexRequest = new IndexRequest(Constant.INDEX)
.id(document.getId())
.source(JSON.toJSONString(document), XContentType.JSON);
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
return indexResponse.status().equals(RestStatus.OK);
}
下面通过调用这个方法,创建两个文档,具体内容如下:

4.3.2 批量创建文档
在一个 REST 请求中,重新建立网络开销是十分损耗性能的,因此 ES 提供 Bulk API,支持在一次 API 调用中,对不同的索引进行操作,从而减少网络传输开销,提升写入速率。
下面方法是批量创建文档,一个 BulkRequest 里可以添加多个 Request,具体代码如下:
public Boolean bulkCreateUserDocument(List<UserDocument> documents) throws IOException {
BulkRequest bulkRequest = new BulkRequest();
for (UserDocument document : documents) {
String id = UUID.randomUUID().toString();
document.setId(id);
IndexRequest indexRequest = new IndexRequest(Constant.INDEX)
.id(id)
.source(JSON.toJSONString(document), XContentType.JSON);
bulkRequest.add(indexRequest);
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
return bulkResponse.status().equals(RestStatus.OK);
}
下面通过该方法创建些文档,便于下面的搜索演示。
4.3.3 查看文档
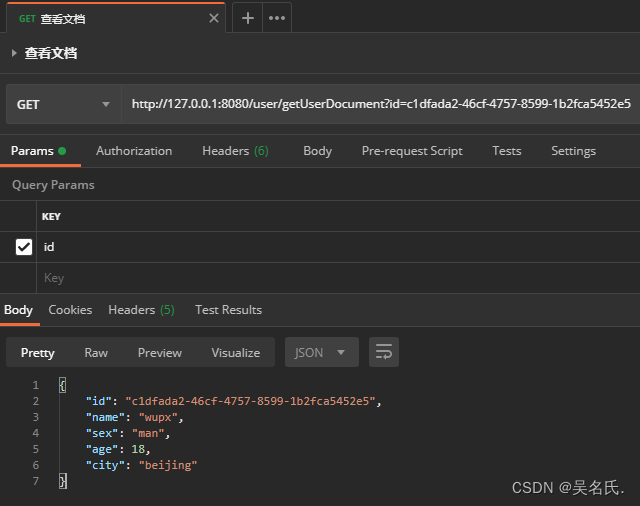
查看文档需要在 GetRequest 中传入索引名称和文档 id,具体代码如下所示:
public UserDocument getUserDocument(String id) throws IOException {
GetRequest getRequest = new GetRequest(Constant.INDEX, id);
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
UserDocument result = new UserDocument();
if (getResponse.isExists()) {
String sourceAsString = getResponse.getSourceAsString();
result = JSON.parseObject(sourceAsString, UserDocument.class);
} else {
logger.error("没有找到该 id 的文档");
}
return result;
}
下面传入文档 id 调用该方法,结果如下所示:
4.3.4 更新文档
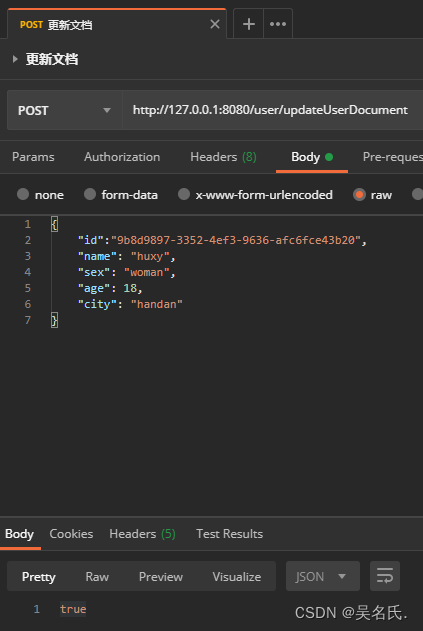
更新文档则是先给 UpdateRequest 传入索引名称和文档 id,然后通过传入新的 doc 来进行更新,具体代码如下:
public Boolean updateUserDocument(UserDocument document) throws Exception {
UserDocument resultDocument = getUserDocument(document.getId());
UpdateRequest updateRequest = new UpdateRequest(Constant.INDEX, resultDocument.getId());
updateRequest.doc(JSON.toJSONString(document), XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
return updateResponse.status().equals(RestStatus.OK);
}
下面将文档 id 为 9b8d9897-3352-4ef3-9636-afc6fce43b20 的文档的城市信息改为 handan,调用方法结果如下:
4.3.5 删除文档
删除文档只需要在 DeleteRequest 中传入索引名称和文档 id,然后执行 delete 方法就可以完成文档的删除,具体代码如下:
public String deleteUserDocument(String id) throws Exception {
DeleteRequest deleteRequest = new DeleteRequest(Constant.INDEX, id);
DeleteResponse response = client.delete(deleteRequest, RequestOptions.DEFAULT);
return response.getResult().name();
}
介绍完文档的基本操作,接下来对搜索进行简单介绍:
4.4 搜索操作
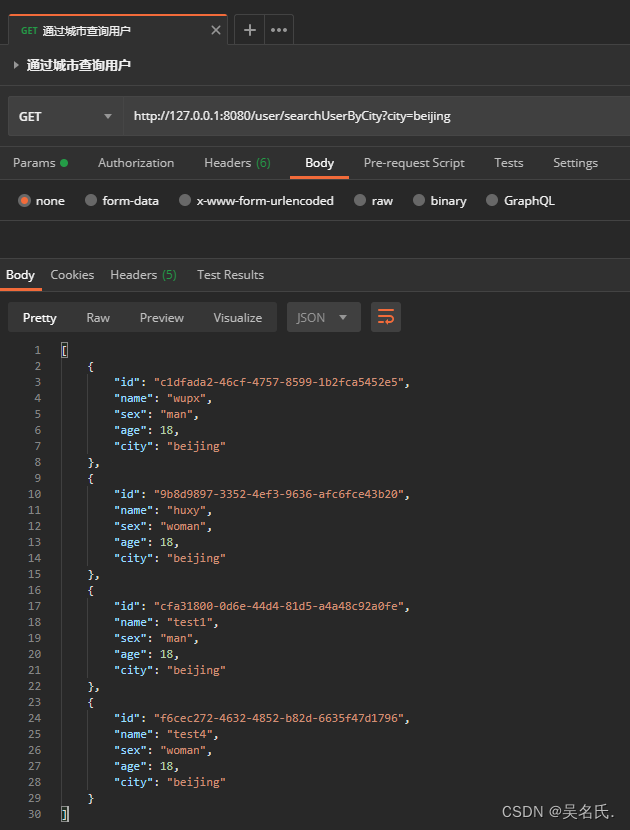
简单的搜索操作需要在 SearchRequest 中设置将要搜索的索引名称(可以设置多个索引名称),然后通过 SearchSourceBuilder 构造搜索源,下面将 TermQueryBuilder 搜索查询传给 searchSourceBuilder,最后将 searchRequest 的搜索源设置为 searchSourceBuilder,执行 search 方法实现通过城市进行搜索,具体代码如下所示:
public List<UserDocument> searchUserByCity(String city) throws Exception {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(Constant.INDEX);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", city);
searchSourceBuilder.query(termQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
return getSearchResult(searchResponse);
}
4.4.1 聚合搜索
聚合搜索就是给 searchSourceBuilder 添加聚合搜索,下面方法是通过 TermsAggregationBuilder 构造一个先通过城市就行分类聚合,其中还包括一个子聚合,是对年龄求平均值,然后在获取聚合结果的时候,可以使用通过在构建聚合时的聚合名称获取到聚合结果,具体代码如下所示:
public List<UserCityDTO> aggregationsSearchUser() throws Exception {
SearchRequest searchRequest = new SearchRequest(Constant.INDEX);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_city")
.field("city")
.subAggregation(AggregationBuilders
.avg("average_age")
.field("age"));
searchSourceBuilder.aggregation(aggregation);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
Terms byCityAggregation = aggregations.get("by_city");
List<UserCityDTO> userCityList = new ArrayList<>();
for (Terms.Bucket buck : byCityAggregation.getBuckets()) {
UserCityDTO userCityDTO = new UserCityDTO();
userCityDTO.setCity(buck.getKeyAsString());
userCityDTO.setCount(buck.getDocCount());
// 获取子聚合
Avg averageBalance = buck.getAggregations().get("average_age");
userCityDTO.setAvgAge(averageBalance.getValue());
userCityList.add(userCityDTO);
}
return userCityList;
}
下面是执行该方法的结果:
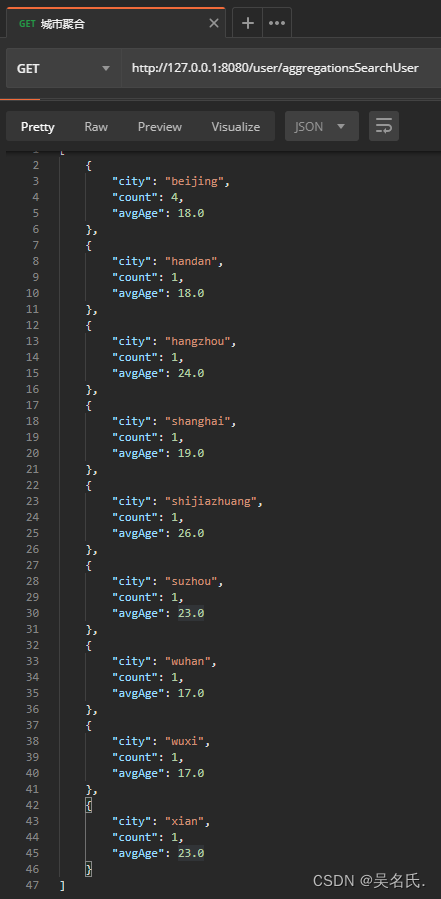
到此为止,ES 的基本操作就简单介绍完了,大家可以多动手试试,不会的可以看下官方文档。
5 总结
本文的完整代码在https://github.com/363153421/springboot-elasticsearch下。
Spring Boot 结合 ES 还是比较简单的,大家可以下载项目源码,自己在本地运行调试这个项目,更好地理解如何在 Spring Boot 中构建基于 ES 的应用。






![伪造referer [极客大挑战 2019]Http1](https://img-blog.csdnimg.cn/95a8c2c87cbf4afbb042007076f2df9e.png)