作者:BENJAMIN TRENT
我们如何将标量量化引入 Lucene。

Lucene 中的自动字节量化
虽然 HNSW 是一种强大而灵活的存储和搜索向量的方法,但它确实需要大量内存才能快速运行。 例如,查询 768 维的 1MM float32 向量大约需要 1,000,000*4*(768+12)=3120000000bytes≈3GB 的 RAM。 一旦你开始搜索大量向量,这就会变得昂贵。 减少大约 75% 内存使用的一种方法是通过字节量化。 Lucene 和 Elasticsearch 支持索引字节向量已有一段时间了,但构建这些向量一直是用户的责任。 这种情况即将改变,因为我们在 Lucene 中引入了 int8 标量量化。
标量量化 101
所有量化技术都被视为原始数据的有损变换。 这意味着由于空间原因,一些信息丢失了。 有关标量量化的深入解释,请参阅:标量量化 101。从高层次来看,标量量化是一种有损压缩技术。 一些简单的数学计算可以节省大量空间,而对召回率的影响很小。
节点、分片、段,天哪!
习惯使用 Elasticsearch 的人可能已经熟悉这些概念,但这里是搜索文档分布的快速概述。
每个 Elasticsearch 索引都由多个分片组成。 虽然每个分片只能分配给单个节点,但每个索引多个分片可以让你跨节点进行并行计算。
每个分片都由一个 Lucene 索引组成。 Lucene 索引由多个只读段组成。 在索引期间,文档被缓冲并定期刷新到只读段中。 当满足某些条件时,这些片段可以在后台合并成更大的片段。 所有这些都是可配置的,并且有其自身的复杂性。 但是,当我们谈论段和合并时,我们谈论的是只读 Lucene 段以及这些段的自动定期合并。 这里更深入地探讨了段合并和设计决策。
每段量化
Lucene 中的每个段都存储以下内容:各个向量、HNSW 图索引、量化向量和计算的分位数。 为了简洁起见,我们将重点关注 Lucene 如何存储量化向量和原始向量。 对于每个片段,我们跟踪 vec 文件中的原始向量、量化向量和 veq 中的单个校正乘数浮点数,以及 vemq 文件中有关量化的元数据。



因此,对于每个段,我们不仅存储量化向量,还存储用于生成这些量化向量和原始原始向量的分位数。 但是,为什么我们要保留原始向量呢?
与你一起成长的量化
由于 Lucene 会定期刷新只读段,因此每个段仅具有所有数据的部分视图。 这意味着计算的分位数仅直接适用于整个数据的该样本集。 现在,如果你的样本足以代表你的整个语料库,那么这并不是什么大问题。 但是 Lucene 允许你以各种方式对索引进行排序。 因此,你可以对按分位数计算增加偏差的方式排序的数据建立索引。 此外,你可以随时刷新数据! 你的样本集可能很小,甚至只有一个向量。 另一个难题是你可以控制何时发生合并。 虽然 Elasticsearch 已配置默认值和定期合并,但你可以随时通过 _force_merge API 请求合并。 那么,我们如何仍然允许所有这些灵活性,同时提供良好的量化以提供良好的召回率?
Lucene 的向量量化会随着时间的推移自动调整。 由于 Lucene 采用只读段架构设计,因此我们可以保证每个段中的数据没有更改,并在代码中明确划分何时可以更新。 这意味着在分段合并期间,我们可以根据需要调整分位数,并可能重新量化向量。

但重新量化不是很昂贵吗? 它确实有一些开销,但 Lucene 会智能地处理分位数,并且仅在必要时才完全重新量化。 我们以图 4 中的段为例。 让我们为段 A 和 B 各提供 1,000 个文档,而段 C 仅提供 100 个文档。 Lucene 将对分位数进行加权平均,如果生成的合并分位数足够接近片段的原始分位数,我们就不必重新量化该片段,并将利用新合并的分位数。

在图 5 中可视化的情况中,我们可以看到生成的合并分位数与 A 和 B 中的原始分位数非常相似。因此,它们没有必要进行重新量化向量。 C段,好像偏差太大了。 因此,C 中的向量将使用新合并的分位数值重新量化。
确实存在合并分位数与任何原始分位数显着不同的极端情况。 在这种情况下,我们将从每个分段中抽取样本并完全重新计算分位数。
性能与数字
那么,它的速度快吗,并且还能提供良好的召回率吗? 以下数据是在 c3-standard-8 GCP 实例上运行实验时收集到的。 为了确保与 float32 进行公平比较,我们使用了一个足够大的实例来在内存中保存原始向量。 我们使用最大内积(maximum-inner-product)索引了 400,000个 Cohere Wiki 向量。
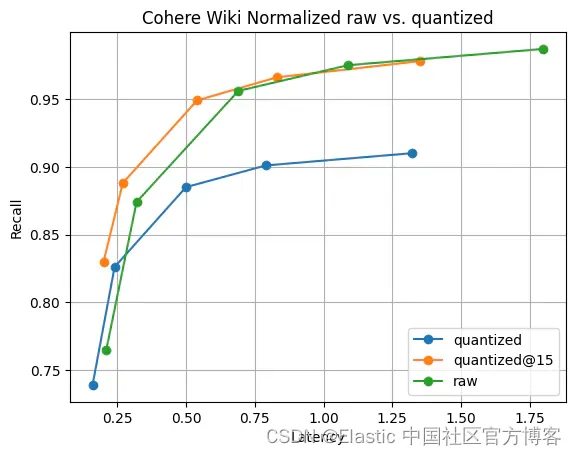
图 6 显示了这个故事。 尽管存在召回率差异,但正如预期的那样,差异并不显着。 而且,仅再收集 5 个向量,召回率差异就消失了。 所有这一切都通过 2 倍更快的段合并和 float32 向量的 1/4 内存实现。
结论
Lucene 为难题提供了独特的解决方案。 量化不需要 “训练” 或 “优化” 步骤。 在 Lucene 中,它会正常工作。 如果数据发生变化,无需担心必须 “重新训练” 向量索引。 Lucene 将检测重大变化,并在数据的生命周期内自动处理这些变化。 期待我们将此功能引入 Elasticsearch!
原文:Introducing Scalar Quantization in Lucene — Elastic Search Labs






![伪造referer [极客大挑战 2019]Http1](https://img-blog.csdnimg.cn/95a8c2c87cbf4afbb042007076f2df9e.png)