😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀
🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C++、数据结构、音视频🍭
🤣本文内容🤣:🍭介绍内存对齐、手把手教你计算结构体大小🍭
😎金句分享😎:🍭🍭
本文未经允许,不得转发!!!
目录
- 🎄一、内存对齐是什么?
- 🎄二、为什么需要内存对齐?
- 🎄三、计算结构体大小
- ✨3.1 对齐参数
- ✨3.2 计算结构体大小的步骤和例子
- 🎄四、#pragma pack 的使用方法
- ✨4.1 用法一:#pragma pack (n)、#pragma pack ()
- ✨4.2 用法二:#pragma pack(push)、#pragma pack(n)、#pragma pack(pop)
- 🎄五、总结
![]()
🎄一、内存对齐是什么?
内存对齐(Memory Alignment) 是指将数据存储在内存中时,是按照特定的规则将数据放置在地址为其大小倍数的位置上。具体而言,内存对齐要求变量的起始地址是它对齐参数的整数倍。
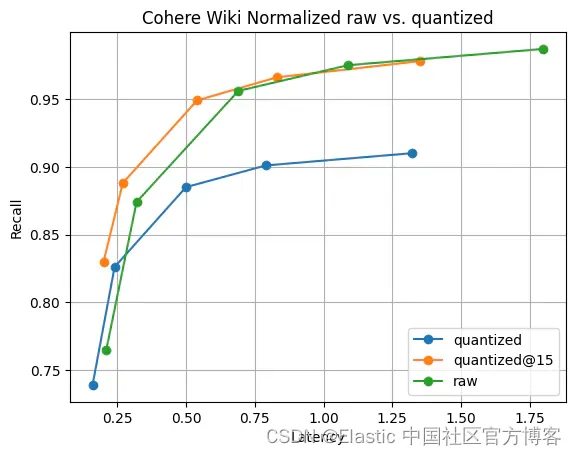
看下面这两个结构体,看看按照内存对齐的要求,是怎么存储的:
struct Test1
{
char c1;
short s;
char c2;
int i;
};
struct Test2
{
char c1;
char c2;
short s;
int i;
};
两个结构体虽然结构体成员一样,但他们所占用的内存大小却不一样,Test1占用12个字节,Test2占用8个字节,他们在内存中的存储大致如下图:
看看struct Test1按照内存对齐要求是怎样安排的,假设结构体首地址为0:
- 成员
c1自身大小为 1 个字节,是结构体第一成员,所以直接在地址0; - 成员
s自身大小为 2 个字节,按照要求,其起始地址必须是 2 的整数倍,所以不能放在地址1的位置,起始地址为地址2; - 成员
c1自身大小为 1 个字节,起始地址需要为 1 的整数倍,直接安排在地址4; - 成员
i自身大小为 4 个字节,起始地址需要为 4 的整数倍,从地址5开始往后找,地址8是4的整数倍。

![]()
🎄二、为什么需要内存对齐?
计算机处理器为了访问未对齐的内存,处理器需要作两次内存访问;然而,对齐的内存访问仅需要一次访问。
所以,内存对齐的主要目的是提高访问数据的效率。当数据按照规定的对齐方式存放在内存中时,处理器可以更快地读取和存储数据,而不需要执行额外的内存操作。未对齐的数据可能导致性能下降,甚至在某些架构中导致程序崩溃。
所以,默认情况下,编译器都会将结构、栈中的成员数据进行内存对齐。
![]()
🎄三、计算结构体大小
按照内存对齐的要求,结构体在内存中是怎么存储的?这小节介绍复杂结构体各个成员在内存中怎么存储?
这里的复杂结构体是指包含了结构体和数组的结构体。先看看下面结构体ST_2,你能清楚它各个成员的在结构体中的偏移量吗?
typedef struct st
{
char c; // 起始地址 0; 结束地址 1
int i; // 起始地址 4; 结束地址 8
double d; // 起始地址 8; 结束地址 16
}ST; // 结构体大小 16 字节
typedef struct st2
{
char c;
int i;
ST st;
double d;
char c2;
ST st_arr[3];
long l;
int i_arr[9];
}ST2;
✨3.1 对齐参数
在计算结构体大小之前,先了解几个概念:
- 对齐参数:编译器进行内存对齐时,会涉及到一个对齐参数,不同的对齐参数,计算出来的结构体大小会不一样。可以通过下面代码查看编译器的默认对齐参数,(并非"32位系统就是4,64位系统为8");
// default_align.c // gcc default_align.c -std=c11 #include <stdio.h> #include <stddef.h> int main(void) { printf("Default alignment: %zu\n", __alignof__(max_align_t)); printf("Biggest alignment: %d\n", __BIGGEST_ALIGNMENT__); return 0; } - 基础数据类型的对齐方式:对齐参数就是类型大小;
- 数组的对齐方式:对齐参数就是
单个数组元素的大小。比如:char a[3];它的对齐方式和分别写 3 个 char 是一样的;也就是说它还是按 1 个字节对齐。 - 结构体的对齐方式:对齐参数就是
成员中的最大对齐参数。比如:上面的结构体ST,对齐参数就是成员d的对齐参数 8。
✨3.2 计算结构体大小的步骤和例子
计算结构体大小的步骤(计算各个成员的地址):
- 1、确定成员对齐参数:成员的对齐参数是
自身对齐参数与系统对齐参数中较小的一个。- 2、确定成员起始地址:起始地址为
成员对齐参数的整数倍;- 3、确定结构体大小:最终结构体大小必须是最大对齐参数的整数倍。
按照步骤计算上面ST2结构体大小,假设结构体起始地址为0,系统对齐参数为 4,系统是32位系统:
第一个成员
c:位于结构体第一个,起始地址为 0,结束地址为 1;第二个成员
i:自身对齐参数为 4 (sizeof(int)=4),等于系统对齐参数 4,所以成员对齐参数为4;
起始地址为:从上个成员结束地址1开始数,找到4的整数倍,结果为 4,所以起始地址为 4,结束地址为 8;第三个成员
st:自身对齐参数为 8 (ST结构体最大对齐参数为8),大于系统对齐参数 4,所以成员对齐参数为4;
起始地址为:从上个成员结束地址8开始数,找到4的整数倍,结果为 8,所以起始地址为 4,结束地址为 24;第四个成员
d:自身对齐参数为 8 (sizeof(double)=8),大于系统对齐参数 4,所以成员对齐参数为4;
起始地址为:从上个成员结束地址24开始数,找到4的整数倍,结果为 24,所以起始地址为 24,结束地址为 32;第五个成员
c2:自身对齐参数为 1 (sizeof(char)=1),小于系统对齐参数 4,所以成员对齐参数为1;
起始地址为:从上个成员结束地址32开始数,找到1的整数倍,结果为 32,所以起始地址为 32,结束地址为 33;第六个成员
st_arr:是一个结构体数组,对齐参数就是单个数组元素的对齐参数,数组元素又是一个结构体ST,按照该结构体最大对齐参数8作为自身对齐参数,大于系统对齐参数 4,所以成员对齐参数为4;
起始地址为:从上个成员结束地址33开始数,找到4的整数倍,结果为 36,所以起始地址为 36,结束地址为 84;第七个成员
l:自身对齐参数为 4 (sizeof(double)=4),等于系统对齐参数 4,所以成员对齐参数为4;
起始地址为:从上个成员结束地址84开始数,找到4的整数倍,结果为 84,所以起始地址为 84,结束地址为 88;第八个成员
i_arr:是一个结构体int型数组,数据元素是int类型的,所以自身对齐参数为 4 (sizeof(int)=4),等于系统对齐参数 4,所以成员对齐参数为4;
起始地址为:从上个成员结束地址88开始数,找到4的整数倍,结果为 88,所以起始地址为 88,结束地址为 124;
计算完成员地址后,找出最大对齐参数,这个例子是 4,目前内存存储到124个字节,是4的整数倍,所以结构体
ST2的大小是 124。

可以使用下面的代码验证是否计算正确:
// memAlign.c
// gcc memAlign.c -o memAlign
#include <stdio.h>
#include <stddef.h>
#pragma pack (4)
typedef struct st
{
char c; // 起始地址 0; 结束地址 1
int i; // 起始地址 4; 结束地址 8
double d; // 起始地址 8; 结束地址 16
}ST; // 结构体大小 16 字节
typedef struct st2
{
char c;
int i;
ST st;
double d;
char c2;
ST st_arr[3];
long l;
int i_arr[9];
}ST2;
#pragma pack ()
int main(void)
{
printf("c:%zu i:%zu st:%zu d:%zu c2:%zu st_arr:%zu l:%zu i_arr:%zu\n",
offsetof(ST2, c), offsetof(ST2, i), offsetof(ST2, st),
offsetof(ST2, d), offsetof(ST2, c2), offsetof(ST2, st_arr),
offsetof(ST2, l), offsetof(ST2, i_arr));
return 0;
}
![]()
🎄四、#pragma pack 的使用方法
#pragma pack 可以用来改变编译器的默认对齐方式,也就是改变上文提到的系统对齐参数;
#pragma pack(n) 的n只能是2的次方幂,目前测试了,n的值可以为1、2、3、8、16,当设置32时会报错。
✨4.1 用法一:#pragma pack (n)、#pragma pack ()
使用指令#pragma pack (n),编译器将按照 n 个字节对齐。
使用指令#pragma pack (),编译器将取消自定义字节对齐方式。
用法可以参考下面代码,表示从#pragma pack (4)开始到#pragma pack ()之间的代码的系统对齐参数是4:
#pragma pack (4)
typedef struct st
{
char c; // 起始地址 0; 结束地址 1
int i; // 起始地址 4; 结束地址 8
double d; // 起始地址 8; 结束地址 16
}ST; // 结构体大小 16 字节
typedef struct st2
{
char c;
int i;
ST st;
double d;
char c2;
ST st_arr[3];
long l;
int i_arr[9];
}ST2;
#pragma pack ()
✨4.2 用法二:#pragma pack(push)、#pragma pack(n)、#pragma pack(pop)
#pragma pack(push):保存当前对其方式到 packing stack;
#pragma pack(n):设置编译器按照 n 个字节对齐;
#pragma pack(pop):packing stack 出栈,并设置为对齐参数;
用法参考下面代码:
#pragma pack (push) // 保存现在的对齐参数
#pragma pack (4) // 将对齐参数改为 4
typedef struct st
{
char c; // 起始地址 0; 结束地址 1
int i; // 起始地址 4; 结束地址 8
double d; // 起始地址 8; 结束地址 16
}ST; // 结构体大小 16 字节
typedef struct st2
{
char c;
int i;
ST st;
double d;
char c2;
ST st_arr[3];
long l;
int i_arr[9];
}ST2;
#pragma pack (pop) // 恢复之前保存的对齐参数
![]()
🎄五、总结
本文介绍内存对齐,也解释了为什么需要内存对齐,最后演示了一个结构体是怎样按照计算占用内存大小的。

如果文章有帮助的话,点赞👍、收藏⭐,支持一波,谢谢 😁😁😁






![伪造referer [极客大挑战 2019]Http1](https://img-blog.csdnimg.cn/95a8c2c87cbf4afbb042007076f2df9e.png)