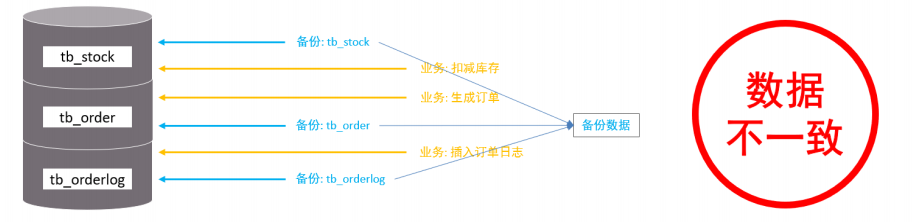
以uvm_error 为例浅析其背后的故事:

uvm_error 是一个宏,在声明的时候只需要传入ID 和 msg,均为字符类型;
分析以上源码,发现起内部主要是调用了一个叫做uvm_report_enabled的函数进行判断,打印函数使用的是uvn_report_error。接下来首先了解一下uvm_report_enabled函数。
uvm_report_enabled(uvm_report_object.svh):

函数内部调用了get_report_erbosity_level函数,其输出值与传入的verbosity进行比较,取真假; 同时还调用了get_report_action函数,与uvm_action`(uvm_no_action)的类型转换值进行相等判断,取真假。
好吧,又多了两个函数:get_report_verbosity_level & get_report_action,继续介绍:
get_report_verbosity_level(uvm_report_object.svh):

get_report_verbosity_level 函数内部调用了uvm_report_handler的get_verbosity_level函数,从名字也可以看出,get_report_verbosity_level函数最后输出的应该是一个verbosity数。这里出现一个新的变量,uvm_report_handler,它会在每个 component 实例化的时候被实例化,也就是说,每个 component 对应一个 m_rh,此变量用于记录这个component 的一些报告信息,如是否单独对此 component 设置了报告冗余度级别 (verbosity_lever) 。
接着往下挖,get_verbosity_level:

在get_verbosity_level函数中,首先判断severity_id_verbosities关联数组是否存在key为severity的情况,如果存在,取出来,其内容是uvm_id_verbosities_array类型,也是一个关联数组,再去检查在uvm_id_verbosities_array关联数组中是否存在key为ID的情况,存在直接取出,作为get_verbosity_level函数输出,由上边分析,uvm_id_verbosities_array关联数组的内容应该是verbosity.
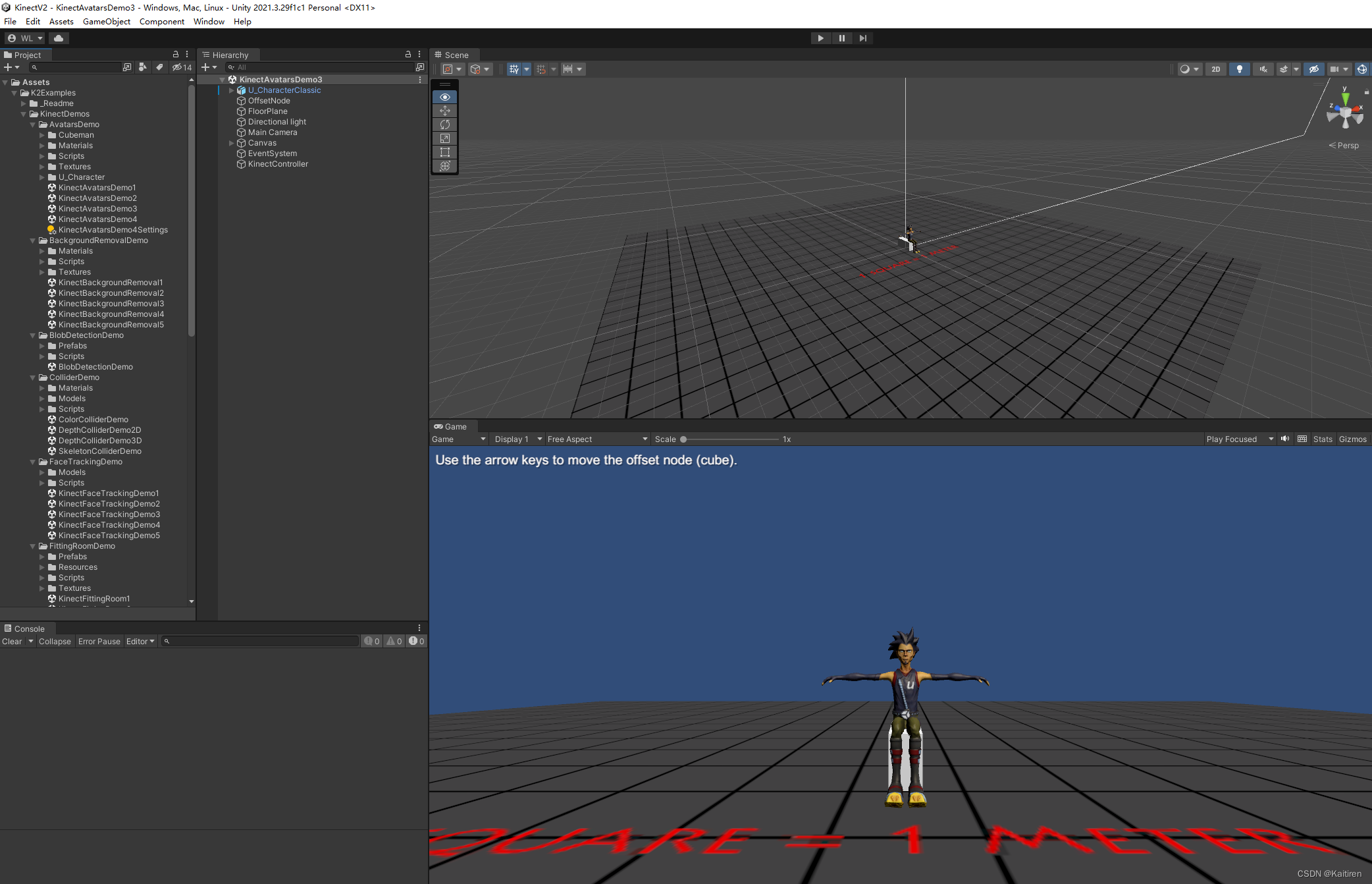
实际上,也确是如此,以下为uvm_id_verbosities_array关联数组源码,其内容实质上是一个 uvm_pool。

而 uvm_pool 的本质是一个派生自 uvm_object 的联合数组;
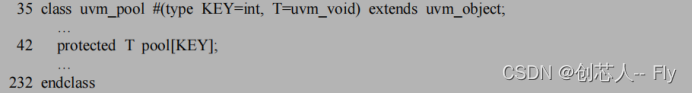
目前,可以下这样一个定论:
severity_id_verbosities 是这样的一个联合数组:它的索引是 uvm_severity(整数型),而其内容则是一个 uvm_object,在这个 object 中有着一个联合数组,这个联合数组的索引是string 类型的,而内容则是整数类型的verbosity。
好,到目前为止,get_verbosity_level的第一个判断理清楚了,接着看第二个判断:
![]()

id_verbosities 是一个 uvm_id_verbosities_array 类型的变量。
246 行的意思其实就是说检查一下 id_verbosities 内部的联合数组中是否存在与 ID 相匹配的记录。从这里我们可以看到,UVM 对于这种信息报告的控制到了非常精细的地步。例如假如在 main_phase 中我们使用 main 这个 ID 来报告信息,而在 shutdown_phase 中使用 shutdown 这个 ID,那么我们可以分别对这两个 ID 的信息报告冗余级别进行设置,如可以把 main 设置为 UVM_HIGH,而把 shutdown 设置为UVM_MEDIUM。

如果 id_verbosities 中也没有记录的话,那么将会直接返回m_max_verbosity_level,这是一个 int 类型的变量,会在系统初始化的时候设置为UVM_MEDIUM。
三个return 顺序执行,优先按severity_id_verbosity查找,找不到使用id_verbosity 查找,在找不到直接用系统定义的verbosity。
所以到这里,初步可以这样下个定论,我也不知道对不对啊,后边在验证,在宏声明的时候,根据应用场景的不同,我们可能会在不同的phase中进行打印,对于第一个传入的参数id是必要的,因为源码会依据ID决定他的verbosity存储到哪一个关联数组中;另外不同类型的severity是源码遍历的大方向。大致可以通过一下图形表示:
get_report_verbosity_level 函数到此就结束了,返回uvm_report_enabled函数,继续看第二个判断中的get_report_action 函数。
get_report_action:

我们发现get_report_action 和get_report_verbosity_level 的内容相似,在get_report_action中调用的是m_rh.get_action,m_rh在上边已经介绍过,此处不做过多赘述。

这个函数与 get_report_verbossity_level 几乎就是姐妹函数,它根据 severity_id_actions 和 id_actions 中的记录来给出返回值。这两者都是 uvm_id_actions_array 类型的变量;
![]()
其实在uvm中,报告机制除了对ID 进行冗余级别的控制之外,还会进行行为级别的控制。
二者相互补充具有很强的关联度,想了解的同学可以自己加深学习。
uvm_action 具体如下:

所以,uvm_report_enabled的作用实际上就是判断severity 下的verbosity/action设置是否符合打印条件的verbosity/action,符合的ID 返回1,执行uvm_report_error函数。
关于uvm_report_error(uvm_report_object):

这个函数会调用uvm_report_handler的report函数:

在report 中,继续调用uvm_report_server的report函数:

这里在259行会得到一个uvm_report_handler的句柄,这个句柄具体是:比如,在agent中调用了uvm_error,那么这个句柄就是agent, 这里使用uvm_report_object 类型的client,保证了派生至uvm_report_object 的component 都可以使用,但如果是object 类型,其实也是可以这样的,最后会通过uvm_root , 实际上还是调用uvm_report_object。


接下来在report函数中会进行判断,调用 uvm_report_enabled 函数,这个函数前面已经有过介绍,就是判断设定的verbosity 和action 与该severity 下的verbosity 和action 的关系,返回值,并根据返回的值来决定是否打印信息。

能走到273行,说明有满足打印条件的ID,下一步就是如何让打印输出到指定文件,这里在273行首先会拿到一个输出文件的句柄,后边会将打印的文件放到里边。
279 行的判断场景是使用了report回调函数的情况,如果这样,就要调用uvm_report_handler里边的run_hooks:

这里会根据severity 分别调用report_*_hook,以 report_error_hook 为例:

直接返回1.其实这边只是预留了一个回调函数的接口。使用&=重载操作符将右侧的值复制到左侧的ok变量返回。
继续看report函数:


286 行将会调用 uvm_report_catcher 的 process_all_report_catchers 函数,uvm_report_catcher派生至uvm_callback类,其process_all_report_catchers主要是捕获相关callback函数的信息。
291 行调用compose_massage 函数,把要打印的信息,如时间,ID,文件行数等组织在一个字符串里,之后把这个字符串作为参数,调用processs_report函数:
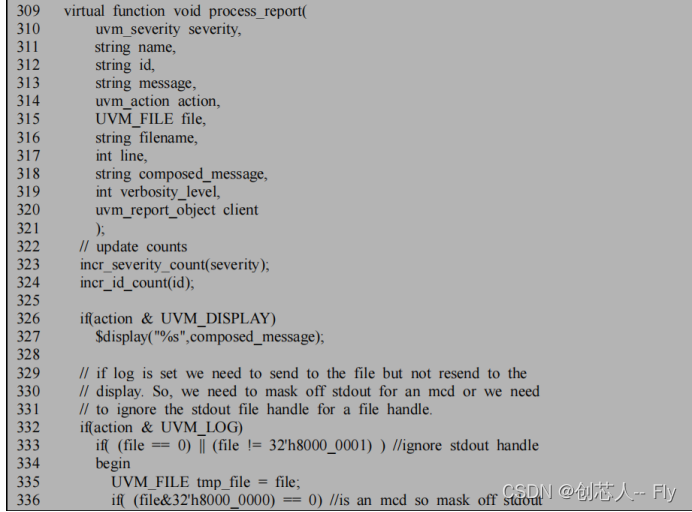

326 行则决定是否把信息输出到屏幕上,332 到 341 行用于把信息送到 log 文件里。343 行则决定是否调用 die 函数,这个函数定义在 uvm_report_object 类中:

这里会调用 uvm_root 的 m_do_pre_abort 函数,进行仿真结束前的清理工作,之后调用 report_summarize 函数,把所有的统计信息打印出来,如有多少个UVM_ERROR 出现等,每个不同的 ID 有多少条信息打印。最后会调用$finish 退出仿真。例如如果是一个uvm_fatal 宏的话,这里就会结束仿真。

345 到 352 行用来查看 UVM_ERROR 数是否已经达到了预先设定的值,如果是的话那也会直接结束仿真。
354 行则根据 action 来调用系统的$stop 函数,以挂起仿真。
简单分析了一下uvm_error的背后故事,我们可以总结,实现打印信息的控制,可以通过:
- 第一,通过控制 ID 来实现不同的输出控制。
- 第二,通过设置不同 ID 的信息报告冗余级别。
- 第三,通过设置不同 ID 的 action。
- 第四,从 uvm_report_catcher 派生一个类,然后把这个 callback 加入到callback池中。