1.决策树-分类树
sklearn.tree.DecisionTreeClassifier官方地址:
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
在机器学习中,决策树是最常用也是最强大的监督学习算法,决策树主要用于解决分类问题,决策树算法 DecisionTree 是一种树形结构,采用的是自上而下的递归方法。
class sklearn.tree.DecisionTreeClassifier(, criterion=‘gini’, splitter=‘best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)*
1.1基本思想
决策树是以信息熵为度量构造一个熵值下降最快的树,到叶子节点处的熵值为零或最小,此时每个叶子结点中的实例都属于同一个类别。决策树学习算法的最大优点是自学习,在学习过程中只需要对训练实例进行较好的标注,就能够进行学习,是一种无监督的学习。而建立决策树的关键:在当前状态下选择哪个属性作为分类依据,根据不同的目标函数,建立决策树有ID3、C4.5 和 CART 三种算法:
- ID3:Iterative Dichotomiser 采用信息增益最大的特征,ID3算法的核心是在决策树的各个结点上应用信息增益准则进行特征选择,从根节点开始,对结点计算所有可能特征的信息增益,选择信息增益最大的特征作为结点的特征,并由该特征的不同取值构建子节点;对子节点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或者没有特征可选时为止。
- C4.5:在生产决策树的过程中,使用信息增益比来进行特征选择。
- CART:Classification And Regression Tree 对于回归树,采用的是平方误差最小化准则;对于分类树,采用基尼指数最小化准则。

1.2 Parameters
(1) criterion{“gini”, “entropy”, “log_loss”}, default=”gini”
衡量决策树分割质量的函数,有基尼系数、香农信息增益和log_loss,一般默认gini。
(2) splitter{“best”, “random”}, default=”best”
用于在每个节点选择拆分的策略。支持的策略是“最佳”选择最佳分割,“随机”选择最佳随机分割,默认是最佳分割。
(3) max_depth: int, default=None
树的最大深度
(4) min_samples_split: int or float, default=2
拆分内部节点所需的最小样本数
(5) min_samples_leaf: int or float, default=1
叶节点所需的最小样本数
(6) min_weight_fraction_leaf: float, default=0.0
叶节点所需的(所有输入样本的)权重总和的最小加权分数。当未提供sample_weight时,样本具有相等的权重。
(7) max_featuresint, float or {“auto”, “sqrt”, “log2”}, default=None
寻找最佳分割时需要考虑的特征数量
(8) random_stateint, RandomState instance or None, default=None
随机数
(9) max_leaf_nodes: int, default=None
以最佳优先方式生长具有max_leaf_nodes的树。最佳节点定义为节点不纯度的相对减少。如果“无”,则无限制的叶节点数。
(10) min_impurity_decrease: float, default=0.0
如果此拆分导致节点不纯度减少大于或等于此值,则节点将被拆分。
1.3剪枝
决策树对于训练集属于有很好的分类能力,但对未知的测试数据未必有很好的分类能力,泛化能力弱,可能产生过拟合现象,所以必须要剪枝处理。而以上三种决策树的剪枝过程算法相同,区别近似对于当前树的评价标准不同。
剪枝思路
- 由完全整棵树t0开始,剪枝部分节点得到t1,再次剪枝部分节点得到t2……直到仅剩树根的树tk
- 在验证数据集上对这k个树分别评价,选择损失函数最小的树
2.代码示例
# -*- coding: utf-8 -*-
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn import metrics
from sklearn.metrics import classification_report
class TreeModel:
def __int__(self):
pass
@staticmethod
def load_data():
iris = datasets.load_iris()
iris_features = iris.data
iris_target = iris.target
feature_name = iris.feature_names
train_x, test_x, train_y, test_y = train_test_split(iris_features,
iris_target,
test_size=0.3,
random_state=123)
# print(pd.DataFrame(iris_features).corr())
return train_x, test_x, train_y, test_y, feature_name
def train_test_model(self):
train_x, test_x, train_y, test_y, feature_name = self.load_data()
model = tree.DecisionTreeClassifier(criterion='gini')
model.fit(train_x, train_y)
model.score(train_x, train_y)
y_pre = model.predict(test_x)
tree_matrix = metrics.confusion_matrix(test_y, y_pre)
print('混淆矩阵:\n', tree_matrix)
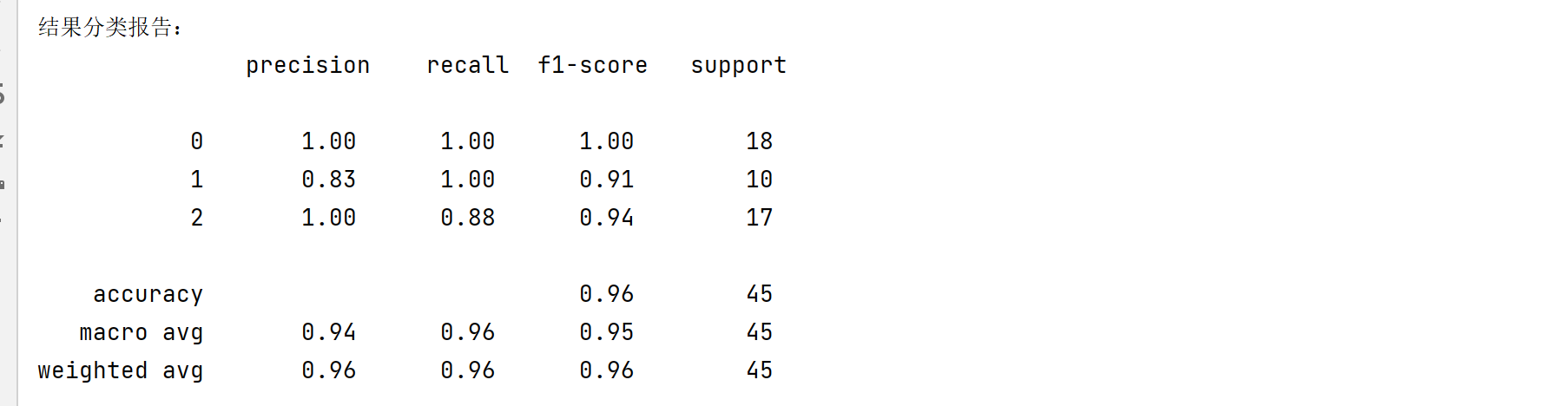
print('结果分类报告:\n', classification_report(test_y, y_pre))
# print('准确率:{:.2%}'.format(metrics.accuracy_score(test_y, y_pre)))
# 特征重要性
# model.feature_importances_
feature_important = pd.DataFrame([*zip(feature_name, model.feature_importances_)],
columns=['features', 'Gini importance'])
print('特征重要度:\n', feature_important.sort_values(by='Gini importance'))
return model
@staticmethod
def plot_tree():
model = self.train_test_model()
feature_name = ['sepal length', 'sepal width', 'petal length', 'petal width']
import graphviz
dot_data = tree.export_graphviz(model,
out_file=None,
feature_names=feature_name,
class_names=['setosa', 'versicolor', 'virginica'],
filled=True,
rounded=True
)
graph = graphviz.Source(dot_data)
graph
if __name__ == '__main__':
TreeModel().train_test_model()
预测效果