百万数据报表概述
文章目录
- **百万数据报表概述**
- **1、** **概述**
- **2、 JDK性能监控工具介绍**
- **2.1、 Jvisualvm概述**
- **2.2、 Jvisualvm的位置**
- **2.3、 Jvisualvm的使用**
- **3、** **解决方案分析**
- **4**、**百万数据报表导出**
- **4.1** **需求分析**
- **4.2** **解决方案**
- **4.2.1** **思路分析**
- **4.2.2** **原理分析**
- **4.3** **代码实现**
- 4.3.1、UserReportResult
- 4.3.2、UserReportController
- **4.4、对比测试**
- **5**、**百万数据报表读取**
- **5.1** **需求分析**
- **5.2** **解决方案**
- **5.2.1** **思路分析**
- **5.2.2** **步骤分析**
- **5.2.3** **原理分析**
- **5.3** **代码实现**
- **5.3.1** **自定义处理器**
- **5.3.2** **自定义解析**
- **5.3.3 PoiEntity**
- **5.3.4 数据放resources下**
- **5.3.5 UserReportController**
- **5.4** **总结**
1、 概述
我们都知道Excel可以分为早期的Excel2003版本(使用POI的HSSF对象操作)和Excel2007版本(使用POI的XSSF
操作),两者对百万数据的支持如下:
-
Excel 2003:在POI中使用HSSF对象时,excel 2003最多只允许存储65536条数据,一般用来处理较少的数据 量。这时对于百万级别数据,Excel肯定容纳不了。
-
Excel 2007:当POI升级到XSSF对象时,它可以直接支持excel2007以上版本,因为它采用ooxml格式。这时 excel可以支持1048576条数据,单个sheet表就支持近百万条数据。但实际运行时还可能存在问题,原因是执 行POI报表所产生的行对象,单元格对象,字体对象,他们都不会销毁,这就导致OOM的风险。
2、 JDK性能监控工具介绍
没有性能监控工具一切推论都只能停留在理论阶段,我们可以使用Java的性能监控工具来监视程序的运行情况,包 括CUP,垃圾回收,内存的分配和使用情况,这让程序的运行阶段变得更加可控,也可以用来证明我们的推测。这里我们使用JDK提供的性能工具Jvisualvm来监控程序运行。
2.1、 Jvisualvm概述
VisualVM 是Netbeans的profifile子项目,已在JDK6.0 update 7 中自带,能够监控线程,内存情况,查看方法的
CPU时间和内存中的对 象,已被GC的对象,反向查看分配的堆栈
2.2、 Jvisualvm的位置
Jvisualvm位于JAVA_HOME/bin目录下,直接双击就可以打开该程序。如果只是监控本地的java进程,是不需要配
置参数的,直接打开就能够进行监控。首先我们需要在本地打开一个Java程序,例如我打开员工微服务进程,这时
在jvisualvm界面就可以看到与IDEA相关的Java进程了:
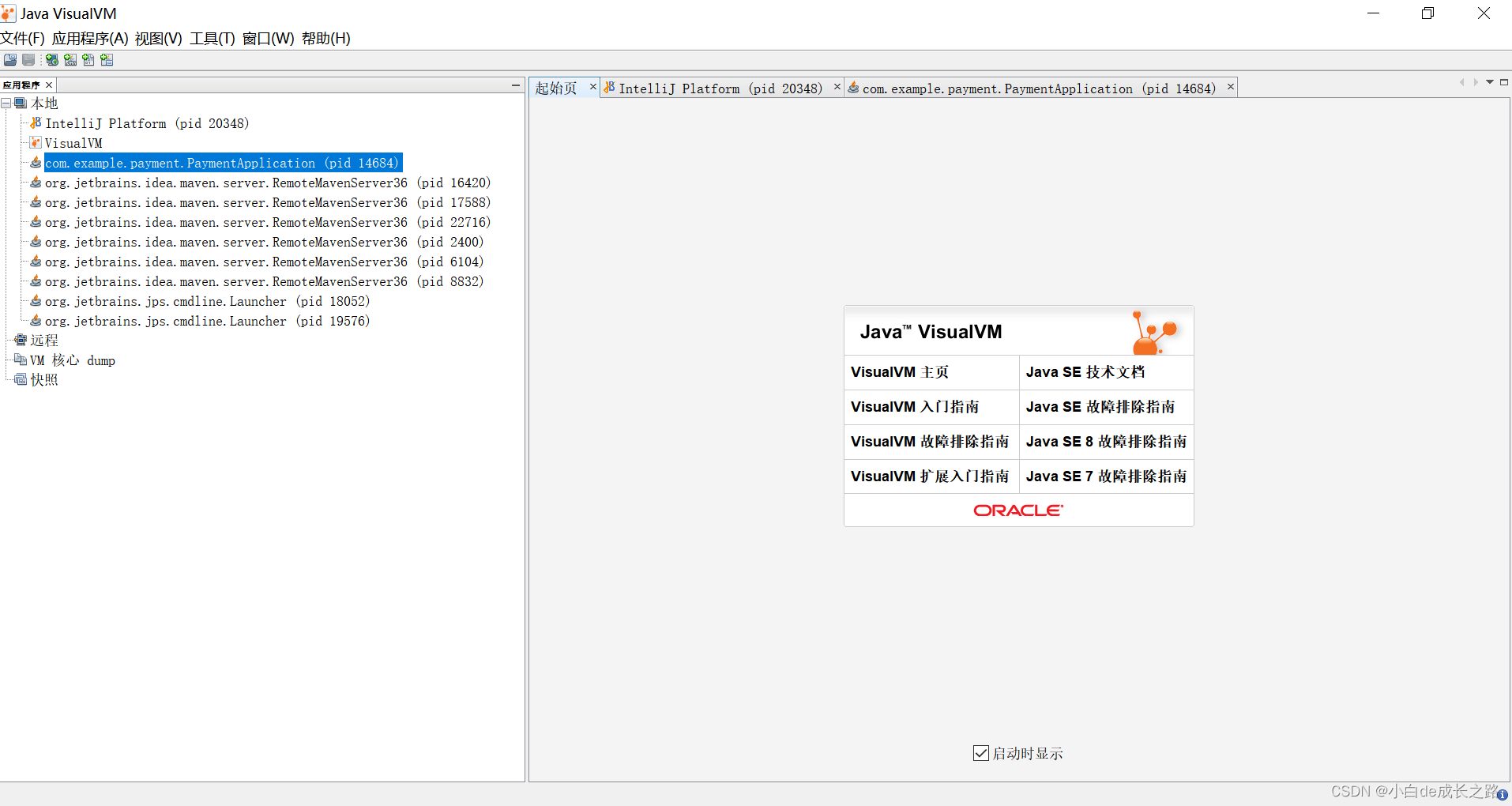
2.3、 Jvisualvm的使用
Jvisualvm使用起来比较简单,双击点击当前运行的进程即可进入到程序的监控界面
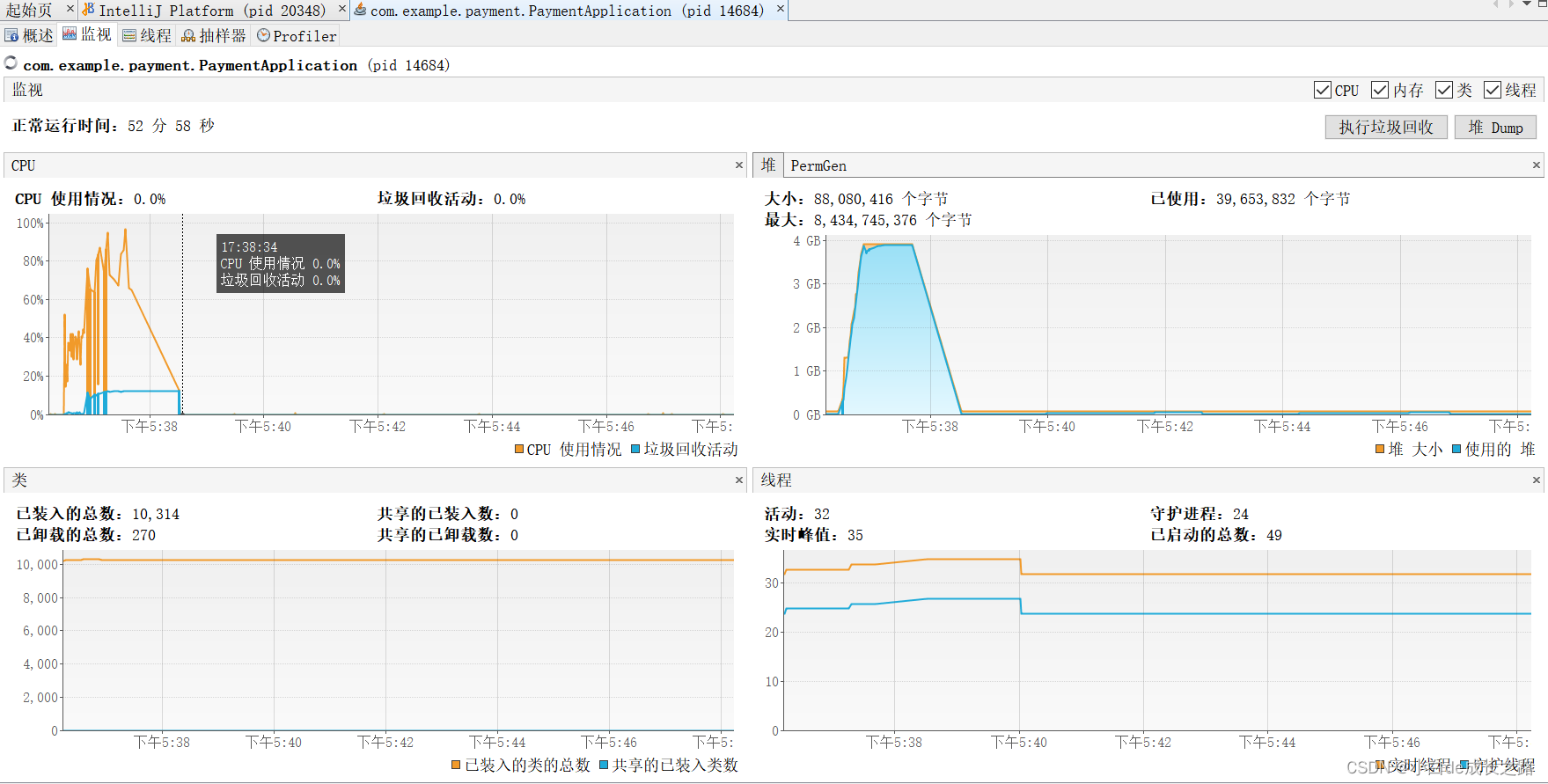
- 概述:可以看到进程的启动参数。
- 监视:左上:cpu利用率,gc状态的监控,右上:堆利用率,永久内存区的利用率,左下:类的监控,右下: 线程的监控 。
- 线程:能够显示线程的名称和运行的状态,在调试多线程时必不可少,而且可以点进一个线程查看这个线程 的详细运行情况 。
3、 解决方案分析
对于百万数据量的Excel导入导出,只讨论基于Excel2007的解决方法。在ApachePoi 官方提供了对操作大数据量的
导入导出的工具和解决办法,操作Excel2007使用XSSF对象,可以分为三种模式:
- 用户模式:用户模式有许多封装好的方法操作简单,但创建太多的对象,非常耗内存(之前使用的方法)
- 事件模式:基于SAX方式解析XML,SAX全称Simple API for XML,它是一个接口,也是一个软件包。它是一 种XML解析的替代方法,不同于DOM解析XML文档时把所有内容一次性加载到内存中的方式,它逐行扫描文 档,一边扫描,一边解析。
- SXSSF对象:是用来生成海量excel数据文件,主要原理是借助临时存储空间生成excel
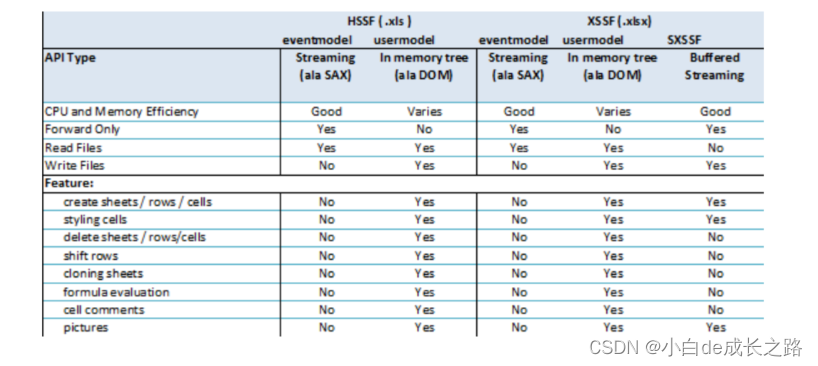
这是一张Apache POI官方提供的图片,描述了基于用户模式,事件模式,以及使用SXSSF三种方式操作Excel的特
性以及CUP和内存占用情况。
4、百万数据报表导出
4.1 需求分析
使用Apache POI完成百万数据量的Excel报表导出
4.2 解决方案
4.2.1 思路分析
基于XSSFWork导出Excel报表,是通过将所有单元格对象保存到内存中,当所有的Excel单元格全部创建完成之后 一次性写入到Excel并导出。当百万数据级别的Excel导出时,随着表格的不断创建,内存中对象越来越多,直至内 存溢出。Apache Poi提供了SXSSFWork对象,专门用于处理大数据量Excel报表导出。
4.2.2 原理分析
在实例化SXSSFWork这个对象时,可以指定在内存中所产生的POI导出相关对象的数量(默认100),一旦内存中 的对象的个数达到这个指定值时,就将内存中的这些对象的内容写入到磁盘中(XML的文件格式),就可以将这些 对象从内存中销毁,以后只要达到这个值,就会以类似的处理方式处理,直至Excel导出完成。
4.3 代码实现
在原有代码的基础上替换之前的XSSFWorkbook,使用SXSSFWorkbook完成创建过程即可。
4.3.1、UserReportResult
package com.example.payment.pojo;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
/**
* @author :
* @date :Created in 10:12 2022/12/22
* @description :
* @version: 1.0
*/
@Getter
@Setter
@NoArgsConstructor
@ToString
public class UserReportResult {
private String userId;
private String username;
private String departmentName;
private String mobile;
private String timeOfEntry;
private String companyId;
private String sex;
/**
* 出生日期
*/
private String dateOfBirth;
/**
* 最高学历
*/
private String theHighestDegreeOfEducation;
/**
* 国家地区
*/
private String nationalArea;
/**
* 护照号
*/
private String passportNo;
/**
* 身份证号
*/
private String idNumber;
/**
* 身份证照片-正面
*/
private String idCardPhotoPositive;
/**
* 身份证照片-背面
*/
private String idCardPhotoBack;
/**
* 籍贯
*/
private String nativePlace;
/**
* 民族
*/
private String nation;
/**
* 英文名
*/
private String englishName;
/**
* 婚姻状况
*/
private String maritalStatus;
/**
* 员工照片
*/
private String staffPhoto;
/**
* 生日
*/
private String birthday;
/**
* 属相
*/
private String zodiac;
/**
* 年龄
*/
private String age;
/**
* 星座
*/
private String constellation;
/**
* 血型
*/
private String bloodType;
/**
* 户籍所在地
*/
private String domicile;
/**
* 政治面貌
*/
private String politicalOutlook;
/**
* 入党时间
*/
private String timeToJoinTheParty;
/**
* 存档机构
*/
private String archivingOrganization;
/**
* 子女状态
*/
private String stateOfChildren;
/**
* 子女有无商业保险
*/
private String doChildrenHaveCommercialInsurance;
/**
* 有无违法违纪行为
*/
private String isThereAnyViolationOfLawOrDiscipline;
/**
* 有无重大病史
*/
private String areThereAnyMajorMedicalHistories;
/**
* QQ
*/
private String qq;
/**
* 微信
*/
private String wechat;
/**
* 居住证城市
*/
private String residenceCardCity;
/**
* 居住证办理日期
*/
private String dateOfResidencePermit;
/**
* 居住证截止日期
*/
private String residencePermitDeadline;
/**
* 现居住地
*/
private String placeOfResidence;
/**
* 通讯地址
*/
private String postalAddress;
/**
* 联系手机
*/
private String contactTheMobilePhone;
/**
* 个人邮箱
*/
private String personalMailbox;
/**
* 紧急联系人
*/
private String emergencyContact;
/**
* 紧急联系电话
*/
private String emergencyContactNumber;
/**
* 社保电脑号
*/
private String socialSecurityComputerNumber;
/**
* 公积金账号
*/
private String providentFundAccount;
/**
* 银行卡号
*/
private String bankCardNumber;
/**
* 开户行
*/
private String openingBank;
/**
* 学历类型
*/
private String educationalType;
/**
* 毕业学校
*/
private String graduateSchool;
/**
* 入学时间
*/
private String enrolmentTime;
/**
* 毕业时间
*/
private String graduationTime;
/**
* 专业
*/
private String major;
/**
* 毕业证书
*/
private String graduationCertificate;
/**
* 学位证书
*/
private String certificateOfAcademicDegree;
/**
* 上家公司
*/
private String homeCompany;
/**
* 职称
*/
private String title;
/**
* 简历
*/
private String resume;
/**
* 有无竞业限制
*/
private String isThereAnyCompetitionRestriction;
/**
* 前公司离职证明
*/
private String proofOfDepartureOfFormerCompany;
/**
* 备注
*/
private String remarks;
/**
* 离职时间
*/
private String resignationTime;
/**
* 离职类型
*/
private String typeOfTurnover;
/**
* 申请离职原因
*/
private String reasonsForLeaving;
}
4.3.2、UserReportController
package com.example.payment.controller;
import com.example.payment.pojo.UserReportResult;
import com.example.payment.service.RiskCalculateService;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.xssf.streaming.SXSSFWorkbook;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.ByteArrayOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
/**
* @author :
* @date :Created in 10:00 2022/12/23
* @description :
* @version: 1.0
*/
@Controller
@RequestMapping("/userReport")
@Slf4j
public class UserReportController {
@GetMapping("/download")
public void download(HttpServletResponse response){
log.info("[userReport-download]开始:{}");
try {
//1.模拟用户数据报表数据
List<UserReportResult> list = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
UserReportResult userReportResult = new UserReportResult();
userReportResult.setEducationalType(i+"");
userReportResult.setAge(i+"");
userReportResult.setBirthday(i+"");
userReportResult.setUserId(i+"");
userReportResult.setUsername(i+"");
userReportResult.setMobile(i+"");
userReportResult.setTheHighestDegreeOfEducation(i+"");
userReportResult.setNationalArea(i+"");
userReportResult.setPassportNo(i+"");
userReportResult.setNativePlace(i+"");
userReportResult.setZodiac(i+"");
userReportResult.setTimeOfEntry(i+"");
userReportResult.setTypeOfTurnover(i+"");
userReportResult.setReasonsForLeaving(i+"");
userReportResult.setResignationTime(i+"");
list.add(userReportResult);
}
//2.构造Excel
//创建工作簿
//SXSSFWorkbook : 百万数据报表
//Workbook wb = new XSSFWorkbook();
SXSSFWorkbook wb = new SXSSFWorkbook(100); //阈值,内存中的对象数量最大数量
//构造sheet
Sheet sheet = wb.createSheet();
//创建行
//标题
String [] titles = "编号,姓名,手机,最高学历,国家地区,护照号,籍贯,生日,属相,入职时间,用户类型,描述,时间".split(",");
//处理标题
Row row = sheet.createRow(0);
int titleIndex=0;
for (String title : titles) {
Cell cell = row.createCell(titleIndex++);
cell.setCellValue(title);
}
int rowIndex = 1;
Cell cell=null;
for(int i=0;i<10;i++) {
for (UserReportResult userReportResult : list) {
row = sheet.createRow(rowIndex++);
// 编号,
cell = row.createCell(0);
cell.setCellValue(userReportResult.getUserId());
// 姓名,
cell = row.createCell(1);
cell.setCellValue(userReportResult.getUsername());
// 手机,
cell = row.createCell(2);
cell.setCellValue(userReportResult.getMobile());
// 最高学历,
cell = row.createCell(3);
cell.setCellValue(userReportResult.getTheHighestDegreeOfEducation());
// 国家地区,
cell = row.createCell(4);
cell.setCellValue(userReportResult.getNationalArea());
// 护照号,
cell = row.createCell(5);
cell.setCellValue(userReportResult.getPassportNo());
// 籍贯,
cell = row.createCell(6);
cell.setCellValue(userReportResult.getNativePlace());
// 生日,
cell = row.createCell(7);
cell.setCellValue(userReportResult.getBirthday());
// 属相,
cell = row.createCell(8);
cell.setCellValue(userReportResult.getZodiac());
// 入职时间,
cell = row.createCell(9);
cell.setCellValue(userReportResult.getTimeOfEntry());
// 离职类型,
cell = row.createCell(10);
cell.setCellValue(userReportResult.getTypeOfTurnover());
// 离职原因,
cell = row.createCell(11);
cell.setCellValue(userReportResult.getReasonsForLeaving());
// 离职时间
cell = row.createCell(12);
cell.setCellValue(userReportResult.getResignationTime());
}
}
String fileName = URLEncoder.encode("2022-12-22用户信息.xlsx", "UTF-8");
response.setContentType("application/octet-stream");
response.setHeader("content-disposition", "attachment;filename=" + new String(fileName.getBytes("ISO8859-1")));
response.setHeader("filename", fileName);
wb.write(response.getOutputStream());
}catch (Exception e) {
log.error("[userReport-download]error:{}", e.getMessage());
}
}
4.4、对比测试
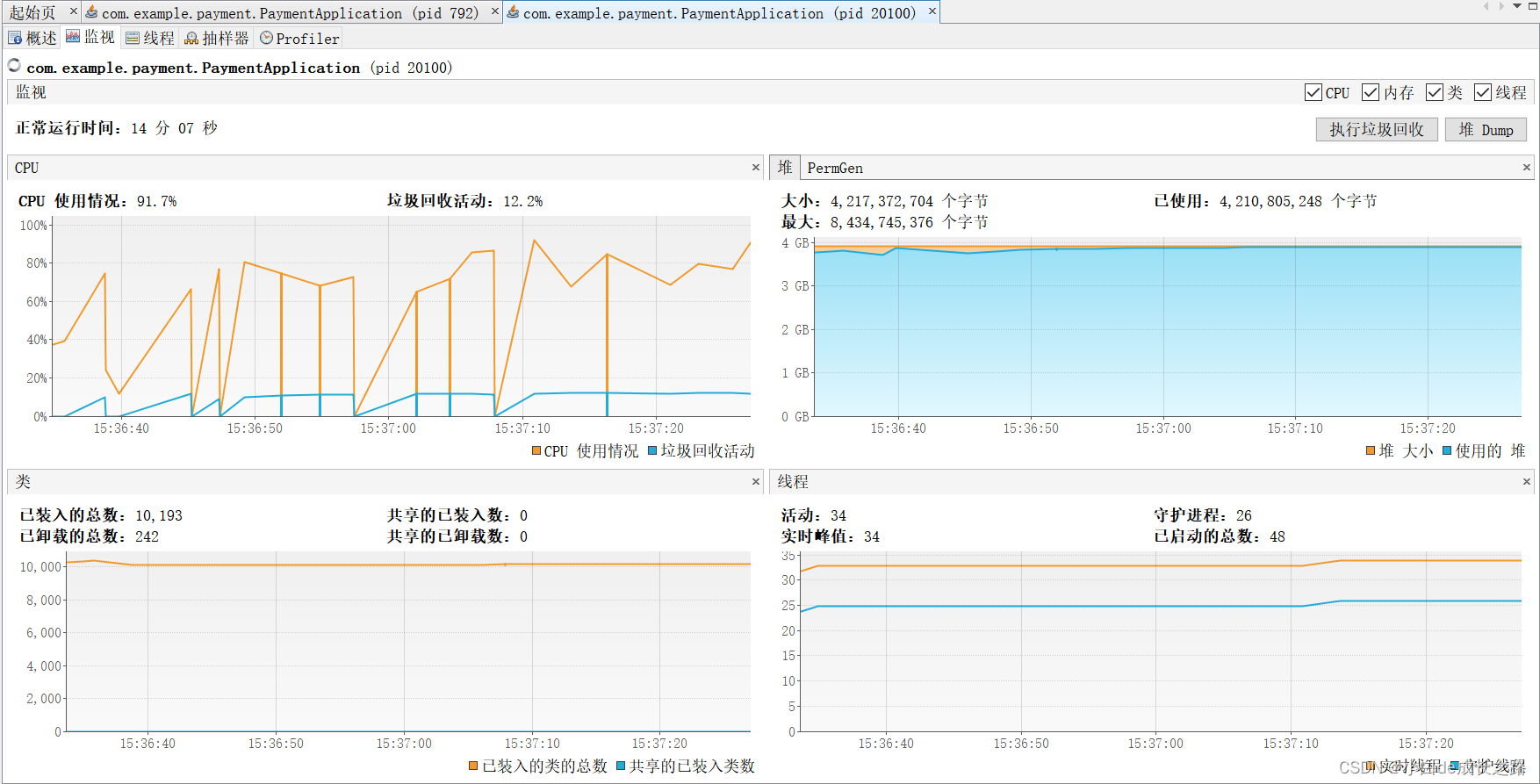
(1)XSSFWorkbook生成百万数据报表
使用XSSFWorkbook生成Excel报表,时间较长,随着时间推移,内存占用原来越多,直至内存溢出
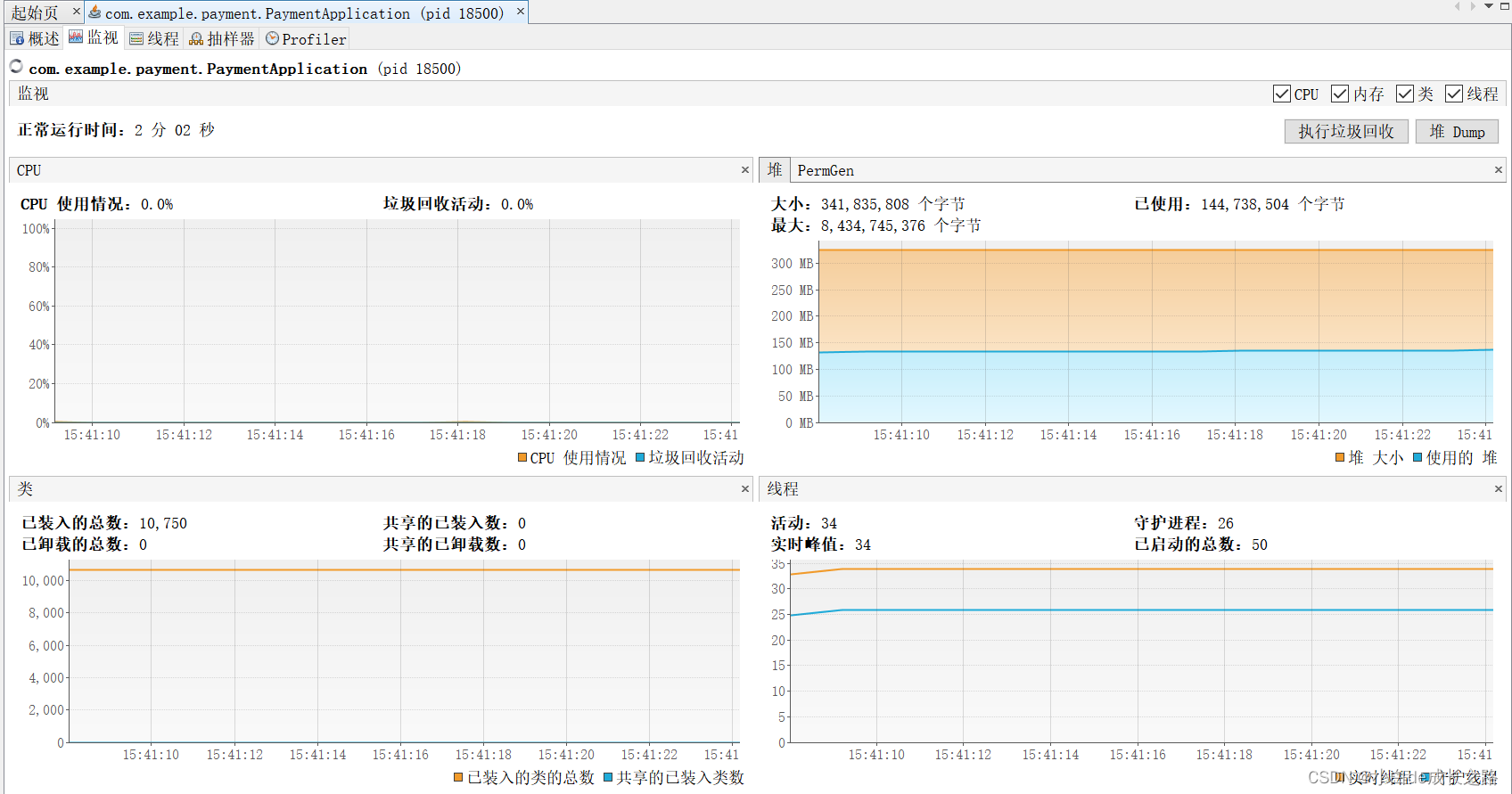
(2)SXSSFWorkbook生成百万数据报表
使用SXSSFWorkbook生成Excel报表,内存占用比较平缓
5、百万数据报表读取
5.1 需求分析
使用POI基于事件模式解析案例提供的Excel文件
5.2 解决方案
5.2.1 思路分析
- 用户模式:加载并读取Excel时,是通过一次性的将所有数据加载到内存中再去解析每个单元格内容。当Excel 数据量较大时,由于不同的运行环境可能会造成内存不足甚至OOM异常。
- 事件模式:它逐行扫描文档,一边扫描一边解析。由于应用程序只是在读取数据时检查数据,因此不需要将 数据存储在内存中,这对于大型文档的解析是个巨大优势。
5.2.2 步骤分析
(1)设置POI的事件模式
- 根据Excel获取文件流 ;
- 根据文件流创建OPCPackage ;
- 创建XSSFReader对象 ;
(2)Sax解析
- 自定义Sheet处理器 ;
- 创建Sax的XmlReader对象 ;
- 设置Sheet的事件处理器 ;
- 逐行读取 ;
5.2.3 原理分析
我们都知道对于Excel2007的实质是一种特殊的XML存储数据,那就可以使用基于SAX的方式解析XML完成Excel的 读取。SAX提供了一种从XML文档中读取数据的机制。它逐行扫描文档,一边扫描一边解析。由于应用程序只是在 读取数据时检查数据,因此不需要将数据存储在内存中,这对于大型文档的解析是个巨大优势 。
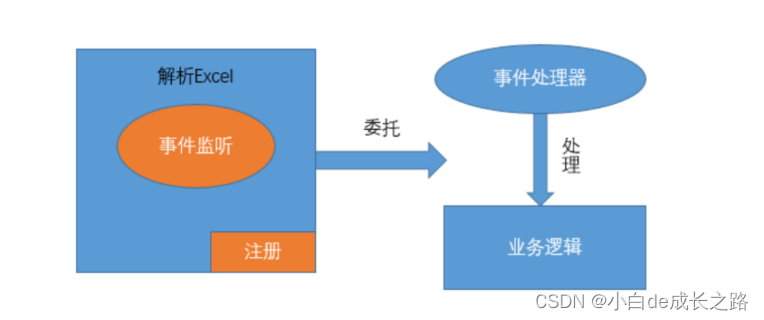
5.3 代码实现
5.3.1 自定义处理器
| 重点关注endRow方法 |
package com.example.payment.utils;
import com.example.payment.pojo.PoiEntity;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler;
import org.apache.poi.xssf.usermodel.XSSFComment;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author :
* @date :Created in 17:02 2022/12/22
* @description :自定义Sheet基于Sax的解析处理器
* @version: 1.0
*/
@Slf4j
public class SheetHandler implements XSSFSheetXMLHandler.SheetContentsHandler {
//封装实体对象
private PoiEntity entity;
private AtomicInteger count = new AtomicInteger(0);
/**
* 解析行开始
*/
@Override
public void startRow(int rowNum) {
if (rowNum > 0) {
entity = new PoiEntity();
}
}
/**
* 解析每一个单元格
*/
@Override
public void cell(String cellReference, String formattedValue, XSSFComment comment) {
if(entity != null) {
switch (cellReference.substring(0, 1)) {
case "A":
entity.setId(formattedValue);
break;
case "B":
entity.setBreast(formattedValue);
break;
case "C":
entity.setAdipocytes(formattedValue);
break;
case "D":
entity.setNegative(formattedValue);
break;
case "E":
entity.setStaining(formattedValue);
break;
case "F":
entity.setSupportive(formattedValue);
break;
default:
break;
}
}
}
/**
* 解析行结束
*/
public void endRow(int rowNum) {
//TODO 将数据存表等操作
log.info("[解析行结束]第{}行,entity:{}", count.incrementAndGet(), entity);
}
/**
* 处理头尾
*/
public void headerFooter(String text, boolean isHeader, String tagName) {
}
}
5.3.2 自定义解析
package com.example.payment.utils;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.model.StylesTable;
import org.xml.sax.InputSource;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLReaderFactory;
import java.io.InputStream;
/**
* @author :
* @date :Created in 17:13 2022/12/22
* @description :自定义Excel解析器
* @version: 1.0
*/
public class ExcelParser {
public void parse(InputStream is) throws Exception {
//1.根据Excel获取OPCPackage对象
OPCPackage pkg = OPCPackage.open(is);
try {
//2.创建XSSFReader对象
XSSFReader reader = new XSSFReader(pkg);
//3.获取SharedStringsTable对象
SharedStringsTable sst = reader.getSharedStringsTable();
//4.获取StylesTable对象
StylesTable styles = reader.getStylesTable();
//5.创建Sax的XmlReader对象
XMLReader parser = XMLReaderFactory.createXMLReader();
//6.设置处理器
parser.setContentHandler(new XSSFSheetXMLHandler(styles, sst, new SheetHandler(), false));
XSSFReader.SheetIterator sheets = (XSSFReader.SheetIterator)
reader.getSheetsData();
//7.逐行读取
while (sheets.hasNext()) {
InputStream sheetstream = sheets.next();
InputSource sheetSource = new InputSource(sheetstream);
try {
parser.parse(sheetSource);
} finally {
sheetstream.close();
}
}
} finally {
pkg.close();
}
}
}
5.3.3 PoiEntity
package com.example.payment.pojo;
public class PoiEntity {
private String id;
private String breast;
private String adipocytes;
private String negative;
private String staining;
private String supportive;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getBreast() {
return breast;
}
public void setBreast(String breast) {
this.breast = breast;
}
public String getAdipocytes() {
return adipocytes;
}
public void setAdipocytes(String adipocytes) {
this.adipocytes = adipocytes;
}
public String getNegative() {
return negative;
}
public void setNegative(String negative) {
this.negative = negative;
}
public String getStaining() {
return staining;
}
public void setStaining(String staining) {
this.staining = staining;
}
public String getSupportive() {
return supportive;
}
public void setSupportive(String supportive) {
this.supportive = supportive;
}
@Override
public String toString() {
return "PoiEntity{" +
"id='" + id + '\'' +
", breast='" + breast + '\'' +
", adipocytes='" + adipocytes + '\'' +
", negative='" + negative + '\'' +
", staining='" + staining + '\'' +
", supportive='" + supportive + '\'' +
'}';
}
}
5.3.4 数据放resources下

@Slf4j
public class UserReportController {
@GetMapping("/read")
public void download(HttpServletResponse response){
log.info("[userReport-download]开始:{}");
try {
ExcelParser excelParser = new ExcelParser();
InputStream is = this.getClass().getClassLoader().getResourceAsStream("demo.xlsx");
excelParser.parse(is);
}catch (Exception e) {
log.error("[userReport-download]error:{}", e.getMessage());
}
}
5.4 总结
通过简单的分析以及运行两种模式进行比较,可以看到用户模式下使用更简单的代码实现了Excel读取,但是在读 取大文件时CPU和内存都不理想;而事件模式虽然代码写起来比较繁琐,但是在读取大文件时CPU和内存更加占 优。