目录标题
- 消费者生产者模型的理解
- 单生产单消费模拟实现
- blockqueue.cpp准备工作
- MainCp.cpp的准备工作
- 构造函数和析构函数的模拟实现
- push函数的实现
- pop函数的实现
- poductor_func函数的实现
- consumer_func函数的实现
- 程序的测试
- 程序改进一
- 程序的改进二
- 程序的改进三
- 多生产多消费模拟实现
- 生产者消费者模型的意义
消费者生产者模型的理解
在前面的学习我们知道了什么是生产者消费者模型,那么这篇文章我们将一步一步的将这个模型实现,首先我们知道要实现消费者生产者模型本质上就是维护好3 2 1原则,3表示的是3种关系分别为生产者和生产者的关系,消费者和消费者的关系,生产者和消费者之间的关系,2表示的两个角色:生产者和消费者,1表示一个缓冲区这个消费者从这个缓冲区中拿取数据,生产者往这个缓冲区中存放数据,那么我们接下来就要通过阻塞队列(Blocking Queue)来实现消费者生产者消费者当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞),那么接下来我们就先模拟实现一个单生产单消费的模型。
单生产单消费模拟实现
blockqueue.cpp准备工作
首先创建一个类用来描述这个模型,类名为:BlockQueue ,因为缓冲区中会存放各种各样的数据所以该类还得是一个模板类:
//blockqueue.hpp
template<class T>
class BlockQueue
{
public:
private:
};
然后我们就要思考这个类中得包含哪些成员变量,首先类中必须得有队列来作为缓冲区来临时的存放数据,因为目标队列是阻塞队列所以还得创建一个锁对象来保证消费者和生产者之间的阻塞访问,因为我们要防止当某个条件不满足的时候依然会有线程不停的占用锁资源所以我们还得创建两个条件变量一个用来将消费者线程挂起一个用来将生产者线程挂起,最后还得创建一个变量用来表示当前的缓冲区最对能够存储数据,那么这就是类中所有成员变量:
//blockqueue.hpp
template<class T>
class BlockQueue
{
public:
private:
//需要一个锁变量
pthread_mutex_t _mutex;
//需要一个生产者条件变量
pthread_cond_t _pcond;
//需要一个消费者条件变量
pthread_cond_t _ccond;
//表示当前队列最多存储数据个数
int _maxcap;
//queue来存储数据
queue<T> _q;
};
然后我们就要实现这个函数的构造函数和析构函数,并且还得提供push函数用来往队列中插入数据,还得提供一个pop函数用来将获取队列中的数据并将该队列中的数据删除,因为push函数只需要将数据插入即可,所以该函数的参数类型就是const &类型,因为pop还得获取内容所以他的参数得是一个指针也就是输入型参数,那么这里的代码如下:
//blockqueue.hpp
template<class T>
class BlockQueue
{
public:
static const int gmaxcap;
BlockQueue(int maxcap=gmaxcap)
{
}
void push(const T& in)//插入到容器中的数据
{
}
void pop(T* out)//输出型参数
{
}
~BlockQueue()
{
}
private:
//需要一个锁变量
pthread_mutex_t _mutex;
//需要一个生产者条件变量
pthread_cond_t _pcond;
//需要一个消费者条件变量
pthread_cond_t _ccond;
//表示当前队列最多存储数据个数
int _maxcap;
//queue来存储数据
queue<T> _q;
};
template<class T>
const int BlockQueue<T>::gmaxcap=10;
那么这就是blockqueue.cpp的准备工作。
MainCp.cpp的准备工作
这个文件里面就是装的就是main函数,在main函数里面我们首先创建两个pthread_t对象和一个blockqueue对象,然后调用两个pthread_create函数创建两个线程并执行对应的函数,因为新线程要执行对应的函数,所以我们这里还得创建两个对应的函数,因为在执行的函数里面要使用blockqueue对象里面的函数,所以pthread_create函数在传递参数的时候就可以将blockqueue对象的地址传递过去,待线程执行完成之后我们就可以使用pthread_join函数将线程进行回收,那么这里的代码就如下:
#include<iostream>
#include"blockqueue.hpp"
using namespace std;
void *consumer_func(void * args)
{
return nullptr;
}
void *poductor_func(void* args)
{
return nullptr;
}
int main()
{
pthread_t consumer,poductor;
BlockQueue<int>* bq =new BlockQueue<int>();
pthread_create(&consumer,nullptr,consumer_func,(void*) bq);
pthread_create(&poductor,nullptr,poductor_func,(void*) bq);
pthread_join(consumer,nullptr);
pthread_join(poductor,nullptr);
return 0;
}
构造函数和析构函数的模拟实现
对于构造函数就一个参数用来表示队列的大小,那么这个参数可以用gmaxcap作为默认参数将该参数赋值给_maxcap即可,然后在构造函数里面吗将两个条件变量和锁进行初始化即可:
BlockQueue(int maxcap=gmaxcap)
:_maxcap(maxcap)
{
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_ccond,nullptr);
pthread_cond_init(&_pcond,nullptr);
}
那么析构函数做的事情就完全相反将两个条件变量和锁资源销毁就可以,那么这里的代码如下:
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_pcond);
pthread_cond_destroy(&_ccond);
}
push函数的实现
该函数的第一步就是调用pthread_mutex_lock函数申请对象中的锁资源,申请成功了就得用if语句判断一下当前容器是否还有空间可以插入数据,那么这里我们就可以创建一个函数来专门实现这个功能:
bool is_full()
{
if(_q.size()==_maxcap)
{
return true;
}
return false;
}
如果当前容器满了就调用pthread_cond_wait函数将当前的线程挂起:
void push(const T& in)//插入到容器中的数据
{
//先申请锁
pthread_mutex_lock(&_mutex);
//申请成功之后就判断一下当前容器中的数据是否是满的
if(is_full())
{
//如果是满的就挂起等待
pthread_cond_wait(&_pcond,&_mutex);
}
}
如果当前的元素没有满的话我们就可以往队列里面插入数据,因为将数据插入之后当前的队列就一定不为空,所以就可以使用pthread_cond_signal函数来唤醒消费者线程线程,然后就可以将锁资源进行释放,那么这里的代码如下:
void push(const T& in)//插入到容器中的数据
{
//先申请锁
pthread_mutex_lock(&_mutex);
//申请成功之后就判断一下当前容器中的数据是否是满的
if(is_full())
{
//如果是满的就挂起等待
pthread_cond_wait(&_pcond,&_mutex);
}
_q.push(in);
//如果走到了这里就说明当前的存储空间一定是有数据的
//这个时候就得将将消费者线程唤醒
pthread_cond_signal(&_ccond);
pthread_mutex_unlock(&_mutex);
}
pop函数的实现
pop函数也是同样的道理首先也是申请锁资源,然后判断当前的队列是否有资源,那么这里我们也可以创建一个函数来实现这个功能:
bool is_empty()
{
if(_q.size()==0)
{
return true;
}
return false;
}
如果当前的容器一个资源都没有的话就可以将当前的线程挂起
void pop(T* out)//输出型参数
{
pthread_mutex_lock(&_mutex);
if(is_empty())
{
pthread_cond_wait(&_ccond,&_mutex);
}
}
线程被唤醒了就表明当前的队列中存在数据,那么这个时候就可以将out执行的内容赋值为队列的头部元素,然后将队列的头部元素删除,因为删除元素之后队列中就存在空缺的资源所以这个时候就可以将生产者的线程唤醒,然后释放锁的资源,那么这里的代码如下:
void pop(T* out)//输出型参数
{
pthread_mutex_lock(&_mutex);
if(is_empty())
{
pthread_cond_wait(&_ccond,&_mutex);
}
*out=_q.front();
_q.pop();
pthread_cond_signal(&_pcond);
pthread_mutex_unlock(&_mutex);
}
poductor_func函数的实现
因为我们一开始实现的比较简单,队列中存放的是整形数据,所以我们这里就可以使用srand函数和rand函数生成随机数据,在这个函数的最开始我们干的第一件事就是将参数的类型进行转换将其转化为blockqueue指针的类型,然后我们就可以使用rand函数生产随机数据并调用blockqueue对象中的push函数插入到队列里面然后打印一段话用来作为标记,因为要插入的数据并不止一个所以可以将上面的内容放到一个循环里面来不停的执行最后返回nullptr即可,那么这里的代码如下:
void *poductor_func(void* args)
{
BlockQueue<int>*bq=static_cast<BlockQueue<int>*>(args);
while(true)
{
int data=rand()%10+1;
bq->push(data);
cout<<"生产了一个数据:"<<data<<endl;
}
return nullptr;
}
consumer_func函数的实现
同样的道理这里一开始也是将参数的类型进行强转,然后创建一个循环在循环体里面创建一个变量用来接收数据,然后调用blockqueue对象中的pop函数并将变量的地址传递进去,然后打印一句话用来作为标识值,最后返回nullptr来结束函数,那么这里的代码如下:
void *consumer_func(void * args)
{
BlockQueue<int>*bq=static_cast<BlockQueue<int>*>(args);
while(true)
{
int data;
bq->pop(&data);
cout<<"消费了一个数据: "<<data<<endl;
}
return nullptr;
}
程序的测试
程序完整的代码如下:
//MainCp.hpp
#include<iostream>
#include<unistd.h>
#include"blockqueue.hpp"
using namespace std;
void *consumer_func(void * args)
{
BlockQueue<int>*bq=static_cast<BlockQueue<int>*>(args);
while(true)
{
int data;
bq->pop(&data);
cout<<"消费了一个数据: "<<data<<endl;
}
return nullptr;
}
void *poductor_func(void* args)
{
BlockQueue<int>*bq=static_cast<BlockQueue<int>*>(args);
while(true)
{
int data=rand()%10+1;
bq->push(data);
cout<<"生产了一个数据:"<<data<<endl;
}
return nullptr;
}
int main()
{
srand((unsigned long)time(nullptr));
pthread_t consumer,poductor;
BlockQueue<int>* bq =new BlockQueue<int>();
pthread_create(&consumer,nullptr,consumer_func,(void*) bq);
pthread_create(&poductor,nullptr,poductor_func,(void*) bq);
pthread_join(consumer,nullptr);
pthread_join(poductor,nullptr);
return 0;
}
//blockqueue.hpp
#include<iostream>
#include<queue>
#include<pthread.h>
using namespace std;
template<class T>
class BlockQueue
{
static const int gmaxcap;
public:
BlockQueue(int maxcap=gmaxcap)
:_maxcap(maxcap)
{
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_ccond,nullptr);
pthread_cond_init(&_pcond,nullptr);
}
void push(const T& in)//插入到容器中的数据
{
//先申请锁
pthread_mutex_lock(&_mutex);
//申请成功之后就判断一下当前容器中的数据是否是满的
if(is_full())
{
//如果是满的就挂起等待
pthread_cond_wait(&_pcond,&_mutex);
}
_q.push(in);
//如果走到了这里就说明当前的存储空间一定是有数据的
//这个时候就得将将消费者线程唤醒
pthread_cond_signal(&_ccond);
pthread_mutex_unlock(&_mutex);
}
void pop(T* out)//输出型参数
{
pthread_mutex_lock(&_mutex);
if(is_empty())
{
pthread_cond_wait(&_ccond,&_mutex);
}
*out=_q.front();
_q.pop();
pthread_cond_signal(&_pcond);
pthread_mutex_unlock(&_mutex);
}
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_pcond);
pthread_cond_destroy(&_ccond);
}
private:
bool is_full()
{
if(_q.size()==_maxcap)
{
return true;
}
return false;
}
bool is_empty()
{
if(_q.size()==0)
{
return true;
}
return false;
}
//需要一个锁变量
pthread_mutex_t _mutex;
//需要一个生产者条件变量
pthread_cond_t _pcond;
//需要一个消费者条件变量
pthread_cond_t _ccond;
//表示当前队列最多存储数据个数
int _maxcap;
//queue来存储数据
queue<T> _q;
};
template<class T>
const int BlockQueue<T>::gmaxcap=10;
如果大家就拿上面的代码进行测试的话会发现这里的数据打印的非常的快而且非常的乱,所以我们就可以在生产者线程的循环里面添加一个sleep语句让其一秒钟生产插入一个数据,这样消费者线程就总是处于挂起的状态,这样我们就可以看到生产者生产一个数据消费者就消费一个数据的现象,那么这里的运行的现象如下:
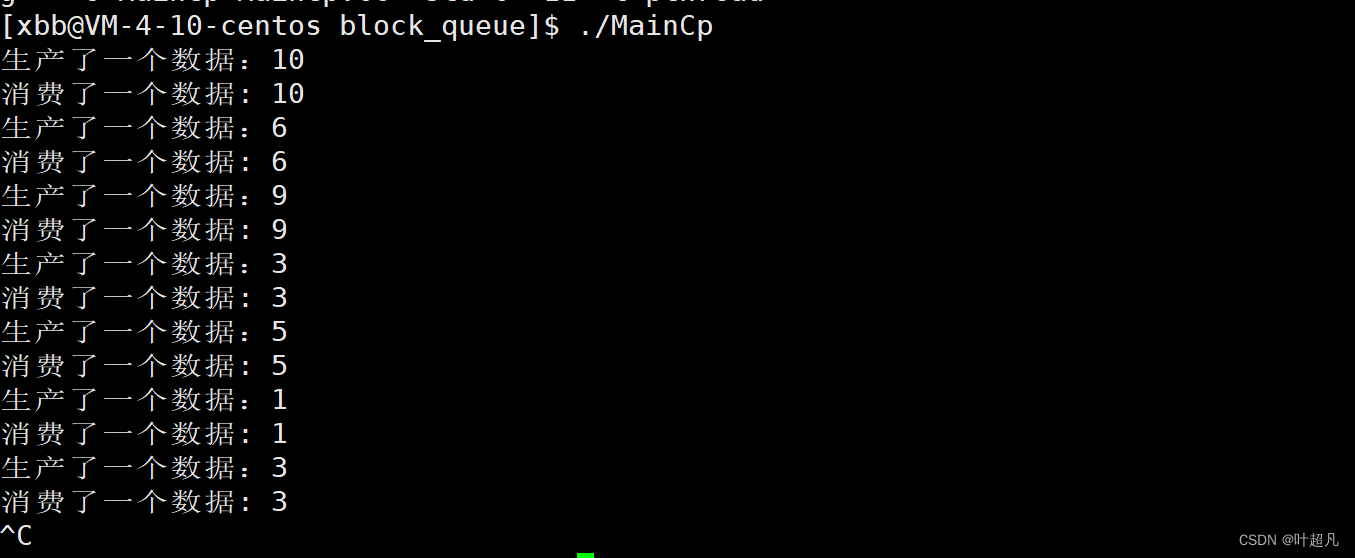
程序改进一
上面的代码在判断容器是否为空或者满的地方可能会出现伪唤醒的问题,上面在唤醒线程的时候采用的是pthread_cond_signal函数,这个函数一次只会唤醒一个线程,但是当前等待的线程可能会存在多个,而且if语句只会判断一次,所以未来一旦将唤醒函数改成pthread_cond_broadcast的话就可能会出现问题,比如说当前的队列只有一个数据,但是等待的消费者线程有10个而且if语句值判断一次并且在等待之前就已经判断了,如果一次性将其全部唤醒的话就会出现错误,所以这里改进的方式就是将if语句的判断改成while语句的判断:
void push(const T& in)//插入到容器中的数据
{
//先申请锁
pthread_mutex_lock(&_mutex);
//申请成功之后就判断一下当前容器中的数据是否是满的
while(is_full())
{
//如果是满的就挂起等待
pthread_cond_wait(&_pcond,&_mutex);
}
_q.push(in);
//如果走到了这里就说明当前的存储空间一定是有数据的
//这个时候就得将将消费者线程唤醒
pthread_cond_signal(&_ccond);
pthread_mutex_unlock(&_mutex);
}
void pop(T* out)//输出型参数
{
pthread_mutex_lock(&_mutex);
while(is_empty())
{
pthread_cond_wait(&_ccond,&_mutex);
}
*out=_q.front();
_q.pop();
pthread_cond_signal(&_pcond);
pthread_mutex_unlock(&_mutex);
}
程序的改进二
我们上面测试的代码只是简单的做到了将整形变量放到了队列当中,然后从队列里面再获取整形变量,这样做似乎没有发挥模版的功能,那么这里我们想让该模型实现更多的功能所以这里就再创建一个文件,在文件里面再创建一个类用来存放数据和处理数据有关的函数,有了这个类之后就可以将该类创建出来的对象放到队列里面,然后消费者线程再从这个队列里面获取数据,然后消费者就可以根据类对象中的函数来实现不同的功能,比如说实现两个数据的+ - * / %生产者线程创建两个数据和一个操作符发送到队列里面,然后消费者线程就拿到这些数据并计算其对应的结果,那么这里我们就创建一个名为CalTask的类,那么生产者就将两个数据和一个操作符放到这个类里面,又因为类中得有对应的函数用来对数据进行操作,所以类中还得存在一个function对象,那么这里的代码如下:
class CalTask
{
using func_t=function<int(int,int,char)>;
public:
private:
int _x;
int _y;
char _op;
func_t _callback;
};
那么该类的构造函数就是接收两个数据和一个操作符和一个调用对象对类内变量进行初始化,又因为存在只创建不需要初始化的现象,所以这里还得添加一个无参的默认构造函数,在这个函数里面什么事情都不用做:
CalTask()
{}
CalTask(int x,int y,char op,func_t func)
:_x(x)
,_y(y)
,_op(op)
,_callback(func)
{}
当消费者线程得到该类的对象时是直接使用该类的函数调用重载来执行相应的任务,所以还得添加函数调用重载,这个重载里面就是创建变量然后通过函数计算数据执行的结果,最后创建一个缓冲区记录数据计算的结果最后打印出来,那么这里的代码如下:
string operator()()
{
int result=_callback(_x,_y,_op);
char buffer[64];
snprintf(buffer,sizeof(buffer),"%d %c %d = %d",_x,_op,_y,result);
return buffer;
}
当消费者线程调用这个重载的时候就会打印这么一句话来作为标记,那么同样的道理当生产者线程创建这个对象的时候也得打印一些内容来作为标记,所以我们还得创建一个函数用来作为生产者线程的标记:
string toTaskString()
{
char buffer[64];
snprintf(buffer,sizeof(buffer),"%d %c %d = ?",_x,_op,_y);
return buffer;
}
这样我们的类就创建完成了,但是在创建这个类对象的时候得创建传递一个函数调用,那么这个函数还得来实现,函数的功能就是计算两个数据的+ - * / %的结构,函数需要三个参数两个用来表示数据一个用来表示计算的操作符:
int mymath(int x,int y,char oper)
{}
那么在函数里面我们就可以创建一个变量result用来计算结果,然后通过oper的值来创建一个switch语句根据不同的值来执行不同的case语句,然后在case语句里面将计算结构赋值给result变量然后将其返回即可,那么这里的代码如下:
int mymath(int x,int y,char oper)
{
int result=0;
switch(oper)
{
case '+':
result=x+y;
break;
case '-':
result=x-y;
break;
case '*':
result=x*y;
break;
case '/':
result=x/y;
break;
case '%':
result=x%y;
break;
default:
break;
}
return result;
}
但是这里存在一个问题就是不能出现除以0或者%0的表达式所以在%和/的case语句里面就得判断一下如果y的值为0的话就使用打印出现了什么错误,然后将result的值赋值为-1并break结束,这样当结果出现-1的时候我们就知道是正常计算得到的-1还是出现错误得到的-1,那么函数的实现如下:
int mymath(int x,int y,char oper)
{
int result=0;
switch(oper)
{
case '+':
result=x+y;
break;
case '-':
result=x-y;
break;
case '*':
result=x*y;
break;
case '/':
if(y==0)
{
cerr << "div zero error!" << endl;
result = -1;
break;
}
result=x/y;
break;
case '%':
if(y==0)
{
cerr<<"div zero error!"<<endl;
result=-1;
break;
}
result=x%y;
break;
default:
break;
}
return result;
}
将这个完成之后就可以来看看线程函数该如何实现,首先是生产者线程同样的原理先将参数的类型进行修改:
void *poductor_func(void* args)
{
BlockQueue<CalTask>*bq=static_cast<BlockQueue<CalTask>*>(args);
return nullptr;
}
然后依然是创建一个while循环,在循环里面根据rand函数得到x和y的值,那如何来得到随机的操作符呢?方法也很简单我们可以创建一个全局的string对象对象里面存放+ - * / %,然后就可以根据rand函数来随机得到string对象的下标,根据该下标就可以得到对应的操作符,有了数据和操作符之后就可以创建一个TaskCal类对象并将该对象插入到队列并使用对象中的toTaskString函数来打印内容出来作为标记:
void *poductor_func(void* args)
{
BlockQueue<CalTask>*bq=static_cast<BlockQueue<CalTask>*>(args);
while(true)
{
int x=rand()%10;
int y=rand()%10;
int z=rand()%oper.size();
CalTask T(x,y,oper[z],mymath);
cout<<"生产任务:"<<T.toTaskString()<<endl;
bq->push(T);
sleep(1);
}
return nullptr;
}
那么对于的消费者线程就是创建一个名为data的对象并将该对象的地址传递给pop函数,这样就可以调用data的函数操函数调用重载打印出一些内容,那么这里的代码如下:
void *consumer_func(void * args)
{
BlockQueue<CalTask>*bq=static_cast<BlockQueue<CalTask>*>(args);
while(true)
{
CalTask data;
bq->pop(&data);
cout<<"消费任务:"<<data()<<endl;
}
return nullptr;
}
那么完整的代码如下:
//task.hpp
#include<iostream>
#include<string>
#include<functional>
#include<cstdio>
using namespace std;
const string oper="+-*/%";
class CalTask
{
using func_t=function<int(int,int,char)>;
public:
CalTask()
{}
CalTask(int x,int y,char op,func_t func)
:_x(x)
,_y(y)
,_op(op)
,_callback(func)
{}
string operator()()
{
int result=_callback(_x,_y,_op);
char buffer[64];
snprintf(buffer,sizeof(buffer),"%d %c %d = %d",_x,_op,_y,result);
return buffer;
}
string toTaskString()
{
char buffer[64];
snprintf(buffer,sizeof(buffer),"%d %c %d = ?",_x,_op,_y);
return buffer;
}
private:
int _x;
int _y;
char _op;
func_t _callback;
};
int mymath(int x,int y,char oper)
{
int result=0;
switch(oper)
{
case '+':
result=x+y;
break;
case '-':
result=x-y;
break;
case '*':
result=x*y;
break;
case '/':
if(y==0)
{
cerr << "div zero error!" << endl;
result = -1;
break;
}
result=x/y;
break;
case '%':
if(y==0)
{
cerr<<"div zero error!"<<endl;
result=-1;
break;
}
result=x%y;
break;
default:
break;
}
return result;
}
//MainCp.cc
#include<iostream>
#include<unistd.h>
#include"blockqueue.hpp"
#include"Task.hpp"
using namespace std;
void *consumer_func(void * args)
{
BlockQueue<CalTask>*bq=static_cast<BlockQueue<CalTask>*>(args);
while(true)
{
CalTask data;
bq->pop(&data);
cout<<"消费任务:"<<data()<<endl;
}
return nullptr;
}
void *poductor_func(void* args)
{
BlockQueue<CalTask>*bq=static_cast<BlockQueue<CalTask>*>(args);
while(true)
{
int x=rand()%10;
int y=rand()%10;
int z=rand()%oper.size();
CalTask T(x,y,oper[z],mymath);
cout<<"生产任务:"<<T.toTaskString()<<endl;
bq->push(T);
sleep(1);
}
return nullptr;
}
int main()
{
srand((unsigned long)time(nullptr));
pthread_t consumer,poductor;
BlockQueue<CalTask>* bq =new BlockQueue<CalTask>();
pthread_create(&consumer,nullptr,consumer_func,(void*) bq);
pthread_create(&poductor,nullptr,poductor_func,(void*) bq);
pthread_join(consumer,nullptr);
pthread_join(poductor,nullptr);
return 0;
}
代码的运行结果如下:
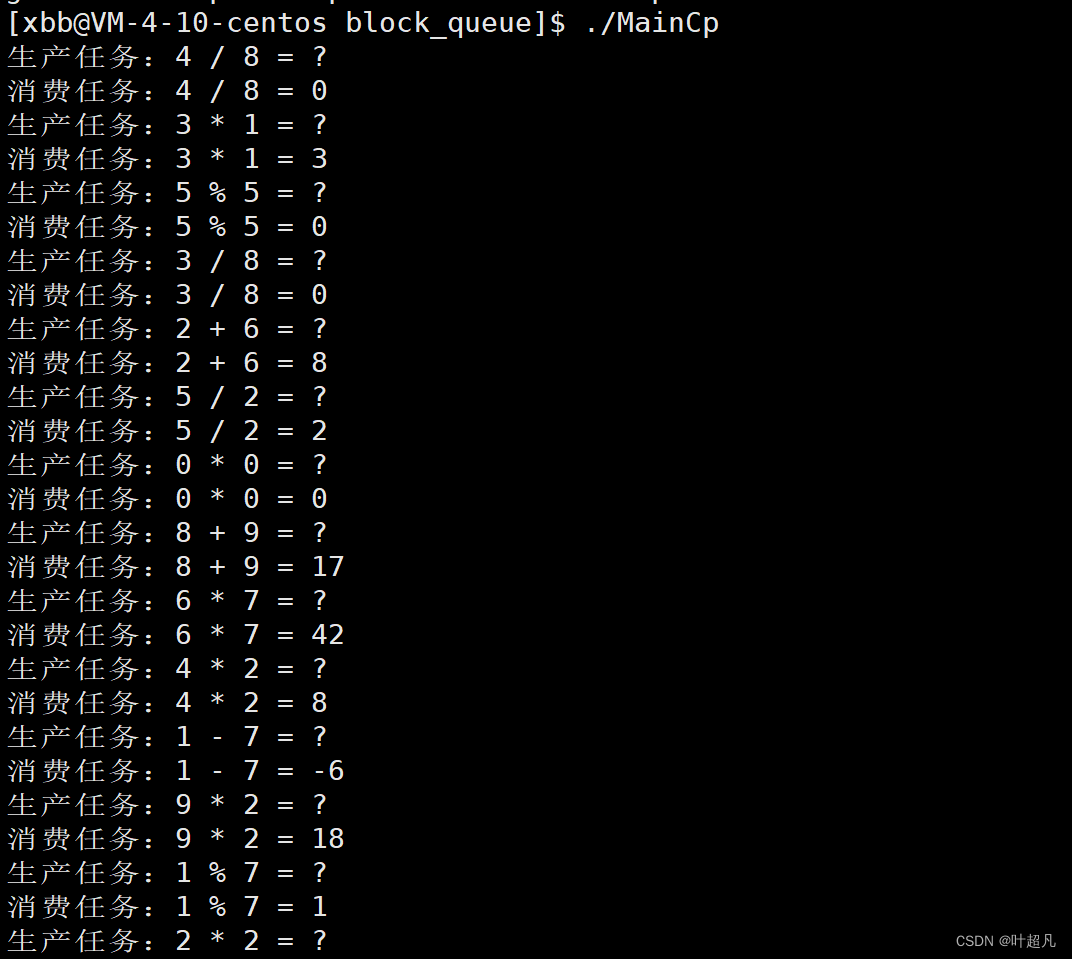
可以看到这里的运行结构明显就比之前丰富多了,所以未来我们想要实现更多的功能就只用设计对应的类与其对数据的处理函数即可。
程序的改进三
我们可以用下面的图片来描述一下上面写的代码:
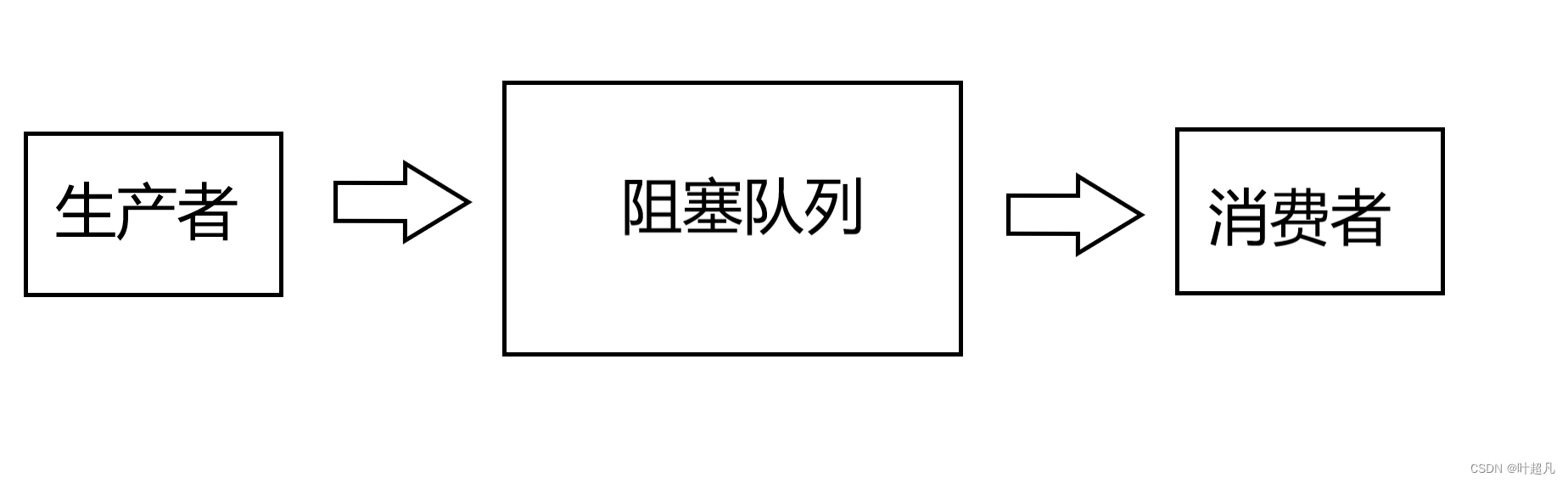
上面的代码就是创建了一个生产者线程和一个消费者线程然后通过阻塞队列的形式将数据进行传递,那么这就只创建一个了阻塞队列,我们接下来改进的方式就是创建多个阻塞队列,也就是将上面的图片变成下面这样:
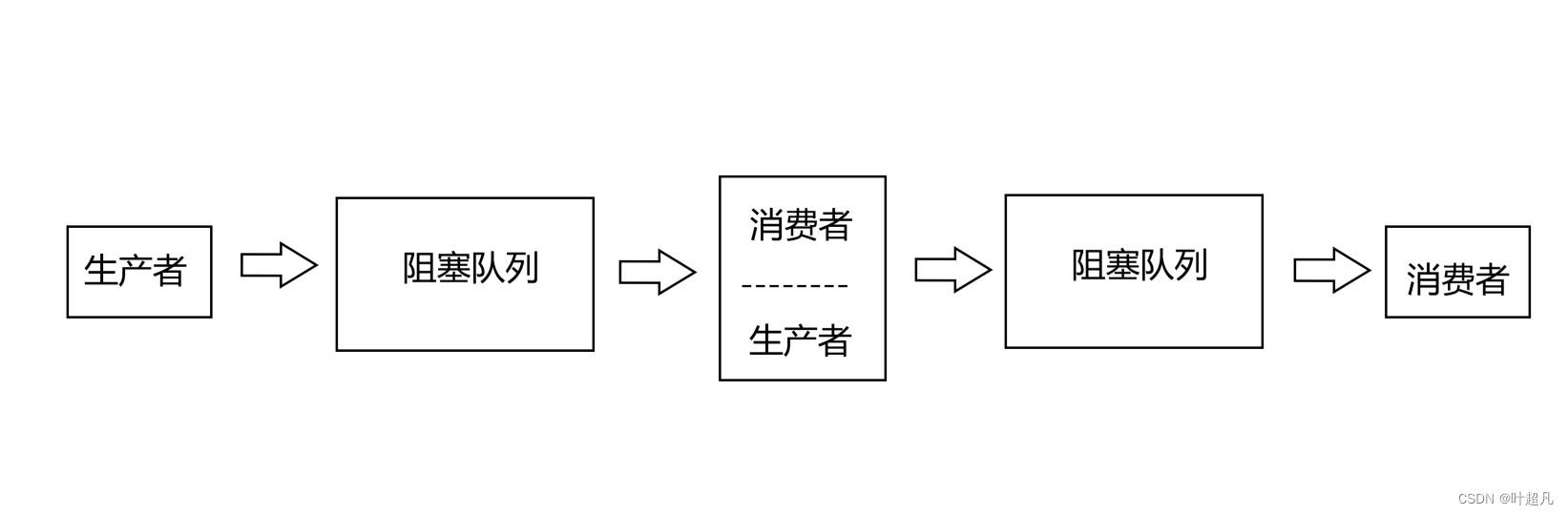
我们让其中的一个线程即使生产者也是消费者,所以我们可以将上面的程序修改成这样,第一个线程产生任务将任务放到阻塞队列1中,然后第二个线程从阻塞队列1中获取任务并执行任务将任务执行的结果打印到屏幕上的同时也将执行的结果放到阻塞队列二当中,然后线程3从阻塞队列二中获取结果并将结果保存到一个文件里面,那么这就是程序改进的大致样貌,那么接下来我们就一步一步的执行。之前我们说过未来我们想要实现更多的功能就只用设计对应的类和函数即可,而保存数据和计算数据是两个不同的功能,所以我们这里就创建一个新类用来传递保存数据这个功能所需要的数据和方法,首先类中得有一个string对象来保存数据,还得有一个function对象来存储对应的函数调用,这个函数的返回值是void参数是string的引用其意义就是将string中的内容保存到文件当中:
class SaveTask
{
using func_t =function<void(string&)>;
public:
private:
string _message;
func_t _func;
};
然后就要实现这个函数的构造函数,对于构造函数就需要两个参数一个用来接收string对象一个参数用来接收函数对象将这两个对象赋值给两个类内数据即可,然后还得创建一个什么都不用干的默认构造函数:
SaveTask()
{}
SaveTask(string& message,func_t func)
:_message(message)
,_func(func)
{}
然后还创建一个函数调用的操作符重载,在这个函数里面调用类内的function对象即可:
class SaveTask
{
using func_t =function<void(string&)>;
public:
SaveTask()
{}
SaveTask(string& message,func_t func)
:_message(message)
,_func(func)
{}
void operator()()
{
_func(_message);
}
private:
string _message;
func_t _func;
};
有了这个类之后我们就可以将数据放到阻塞队列里面,那么接下来我们就要实现对应的存储方法,首先这个函数跟类中的function对象是保持一致的返回值为void参数是string的引用(这里的顺序应该是先有函数然后再有function对象):
void Save(string& message)
{}
那么函数的第一步就是创建string对象记录要打开文件的相对位置,然后使用fopen函数以追加的方式打开这个文件,因为文件的打开可能会出现失败的情况,所以这里得加个if语句进行判断,如果成功了就调用fputs函数将数据写入到文件里面
然后就可以使用fclose函数将文件给关掉:
void Save(string& message)
{
const string target_file="./log.txt";
FILE* fp=fopen(target_file.c_str(),"a+");
if(fp==nullptr)
{
cerr<<"open error"<<endl;
return;
}
fputs(message.c_str(),fp);
fputs("\n",fp);//因为futs不会自带/n所以加上这个方便查看
fclose(fp);
}
有了对应的类对象和函数之后就可以修改对应的线程函数和main函数,首先来修改main函数中的内容因为上图中存在三个线程和两个阻塞队列,并且中间的线程得同时访问两个阻塞队列但是执行线程函数的时候只能传递一个参数,所以这里可以创建一个新的类类中有两个阻塞队列的指针,因为阻塞队列是有模版的并且类中的两个队列存储的数据类型可能是不一样的所以新创建的类也得是模版类并且模版中有两个参数:
template<class C,class S>//c表示计算的类,s表示存储的类
class BlockQueues
{
public:
BlockQueue<C>* c_bq;
BlockQueue<S>* s_bq;
};
有了这个类之后在main函数里面就可以只创建一个这样的对象即可,然后创建三个线程让其执行三个不同的函数:
int main()
{
srand((unsigned long)time(nullptr));
pthread_t consumer,poductor,saver;//创建用于保存的线程
BlockQueues<CalTask,SaveTask>* bqs =new BlockQueues<CalTask,SaveTask>();
bqs->c_bq=new BlockQueue<CalTask>();
bqs->s_bq=new BlockQueue<SaveTask>();
pthread_create(&consumer,nullptr,consumer_func,(void*) bqs);
pthread_create(&poductor,nullptr,poductor_func,(void*) bqs);
pthread_create(&saver,nullptr,saver_func,(void*) bqs);
pthread_join(consumer,nullptr);
pthread_join(poductor,nullptr);
pthread_join(saver,nullptr);
return 0;
}
对于生产者函数唯一的变化就是在参数类型转换的时候,我们先将参数强制转换成为BlockQueues*类型这样就可以合法的获取对象中的数据,因为消费者线程要需要的是装载CalTask的队列,所以就创建一个BlockQueue<CalTask>*的指针对象,让其指向BlockQueues中的c_bq:
void *poductor_func(void* args)
{
BlockQueue<CalTask>*cal_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->c_bq;
while(true)
{
int x=rand()%10;
int y=rand()%10;
int z=rand()%oper.size();
CalTask T(x,y,oper[z],mymath);
cout<<"生产任务:"<<T.toTaskString()<<endl;
cal_bq->push(T);
sleep(1);
}
return nullptr;
}
对于中间的消费者线程不仅需要CalTask的阻塞队列还需要SaveTask的阻塞队列,所以在consumer_func中得创建两个指针对象并执行两次强制类型转换:
BlockQueue<CalTask>*cal_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->c_bq;
BlockQueue<SaveTask>*save_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->s_bq;
然后就是先从cal_bq中获取任务将任务执行的结果打印保存下来打印之后便创建一个SaveTask对象并调用save_bq中的push函数将对象和函数放到save_bq里面即可:
void *consumer_func(void * args)
{
BlockQueue<CalTask>*cal_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->c_bq;
BlockQueue<SaveTask>*save_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->s_bq;
while(true)
{
CalTask data;
cal_bq->pop(&data);
cout<<"完成任务:"<<data()<<endl;
string result=data();
SaveTask save_result(result,Save);
save_bq->push(save_result);
}
return nullptr;
}
最后就是saver_func函数也是创建一个while然后创建一个savetask对象,然后调用save_bq中的pop函数将数据放到savetask对象里面即可,然后调用该对象的函数调用重载即可,那么这里的代码如下:
void*saver_func(void*args)
{
BlockQueue<SaveTask>*save_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->s_bq;
while(true)
{
SaveTask result;
save_bq->pop(&result);
result();
cout<<"保存任务"<<endl;
}
return nullptr;
}
那么完整的代码如下:
//MainCp.cc
#include<iostream>
#include<unistd.h>
#include"blockqueue.hpp"
#include"Task.hpp"
using namespace std;
template<class C,class S>//c表示计算的类,s表示存储的类
class BlockQueues
{
public:
BlockQueue<C>* c_bq;
BlockQueue<S>* s_bq;
};
void *consumer_func(void * args)
{
BlockQueue<CalTask>*cal_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->c_bq;
BlockQueue<SaveTask>*save_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->s_bq;
while(true)
{
CalTask data;
cal_bq->pop(&data);
cout<<"完成任务:"<<data()<<endl;
string result=data();
SaveTask save_result(result,Save);
save_bq->push(save_result);
}
return nullptr;
}
void *poductor_func(void* args)
{
BlockQueue<CalTask>*cal_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->c_bq;
while(true)
{
int x=rand()%10;
int y=rand()%10;
int z=rand()%oper.size();
CalTask T(x,y,oper[z],mymath);
cout<<"生产任务:"<<T.toTaskString()<<endl;
cal_bq->push(T);
sleep(1);
}
return nullptr;
}
void*saver_func(void*args)
{
BlockQueue<SaveTask>*save_bq=(static_cast<BlockQueues<CalTask,SaveTask>*>(args))->s_bq;
while(true)
{
SaveTask result;
save_bq->pop(&result);
result();
cout<<"保存任务"<<endl;
}
return nullptr;
}
int main()
{
srand((unsigned long)time(nullptr));
pthread_t consumer,poductor,saver;//创建用于保存的线程
BlockQueues<CalTask,SaveTask>* bqs =new BlockQueues<CalTask,SaveTask>();
bqs->c_bq=new BlockQueue<CalTask>();
bqs->s_bq=new BlockQueue<SaveTask>();
pthread_create(&consumer,nullptr,consumer_func,(void*) bqs);
pthread_create(&poductor,nullptr,poductor_func,(void*) bqs);
pthread_create(&saver,nullptr,saver_func,(void*) bqs);
pthread_join(consumer,nullptr);
pthread_join(poductor,nullptr);
pthread_join(saver,nullptr);
return 0;
}
//Task.hpp
#include<iostream>
#include<string>
#include<functional>
#include<cstdio>
using namespace std;
const string oper="+-*/%";
class CalTask
{
using func_t=function<int(int,int,char)>;
public:
CalTask()
{}
CalTask(int x,int y,char op,func_t func)
:_x(x)
,_y(y)
,_op(op)
,_callback(func)
{}
string operator()()
{
int result=_callback(_x,_y,_op);
char buffer[64];
snprintf(buffer,sizeof(buffer),"%d %c %d = %d",_x,_op,_y,result);
return buffer;
}
string toTaskString()
{
char buffer[64];
snprintf(buffer,sizeof(buffer),"%d %c %d = ?",_x,_op,_y);
return buffer;
}
private:
int _x;
int _y;
char _op;
func_t _callback;
};
int mymath(int x,int y,char oper)
{
int result=0;
switch(oper)
{
case '+':
result=x+y;
break;
case '-':
result=x-y;
break;
case '*':
result=x*y;
break;
case '/':
if(y==0)
{
cerr << "div zero error!" << endl;
result = -1;
break;
}
result=x/y;
break;
case '%':
if(y==0)
{
cerr<<"div zero error!"<<endl;
result=-1;
break;
}
result=x%y;
break;
default:
break;
}
return result;
}
class SaveTask
{
using func_t =function<void(string&)>;
public:
SaveTask()
{}
SaveTask(string& message,func_t func)
:_message(message)
,_func(func)
{}
void operator()()
{
_func(_message);
}
private:
string _message;
func_t _func;
};
void Save(string& message)
{
const string target_file="./log.txt";
FILE* fp=fopen(target_file.c_str(),"a+");
if(fp==nullptr)
{
cerr<<"open error"<<endl;
return;
}
fputs(message.c_str(),fp);
fputs("\n",fp);//因为futs不会自带/n所以加上这个方便查看
fclose(fp);
}
代码的运行的结果如下:
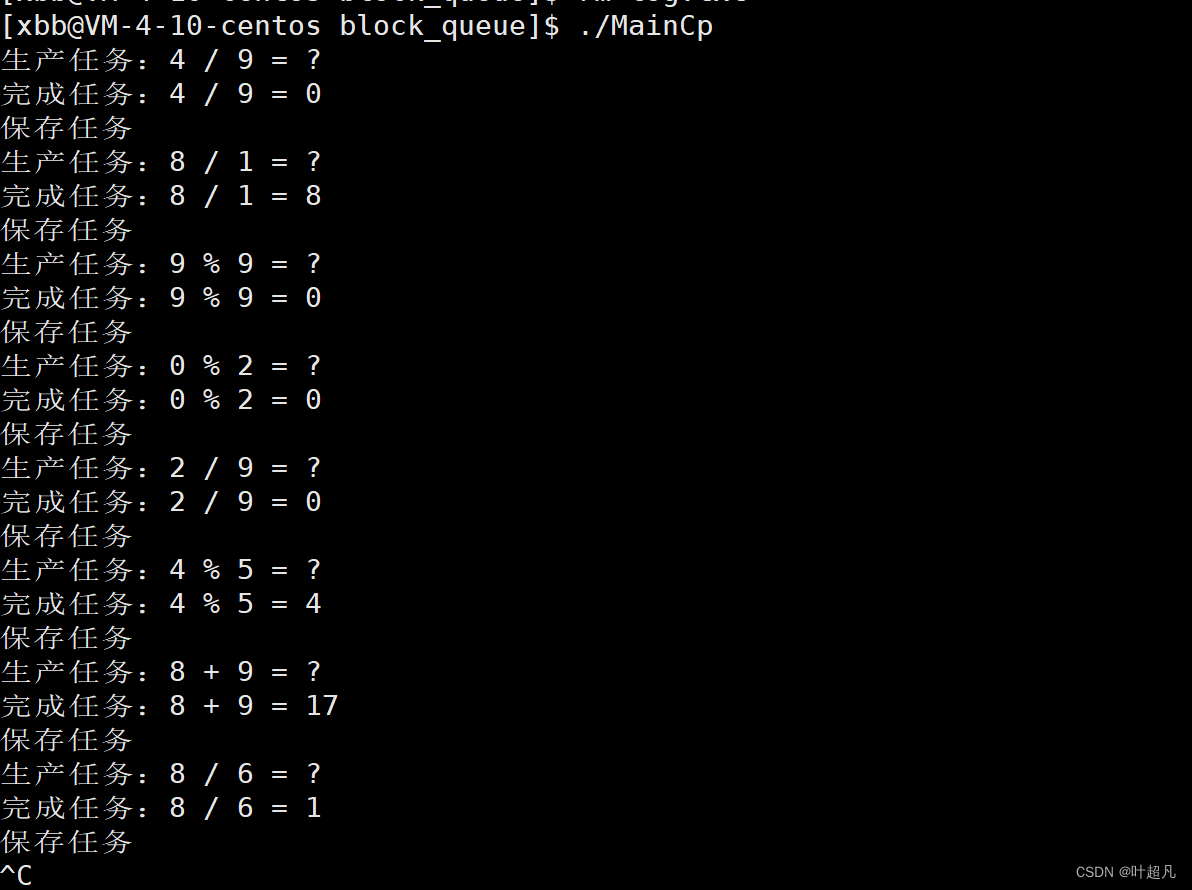
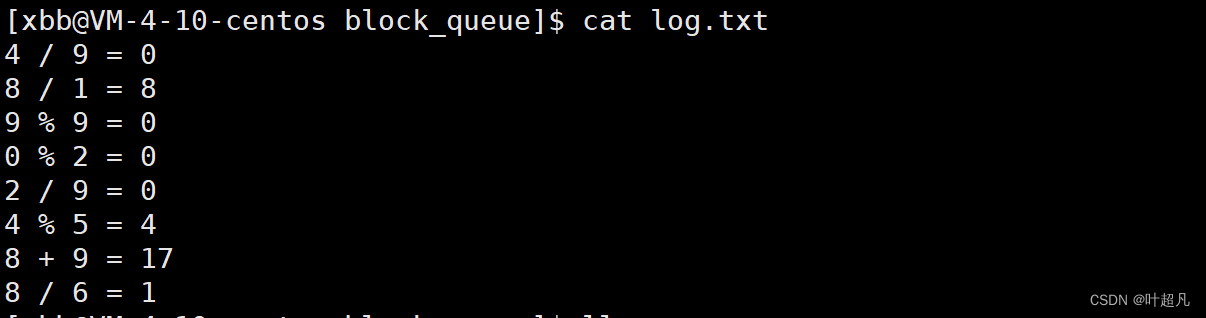
当前路径下有一个名为log.txt的文件,文件的内容如下:
那么这就是我们对程序三的另外一个改进。
多生产多消费模拟实现
通过上面的学习我们知道了如何实现单生产单消费模型的实现,那么接下来我们就要模拟实现多生产多消费的模型,首先得对main函数中的代码进行修改,使用数组记录多个线程的id,然后使用循环依让这些线程执行对应的函数,最后使用循环将其进行回收:
int main()
{
srand((unsigned long)time(nullptr));
pthread_t consumer[5],poductor[5],saver;//创建用于保存的线程
BlockQueues<CalTask,SaveTask>* bqs =new BlockQueues<CalTask,SaveTask>();
bqs->c_bq=new BlockQueue<CalTask>();
bqs->s_bq=new BlockQueue<SaveTask>();
for(int i=0;i<5;i++)
{
pthread_create(&consumer[i],nullptr,consumer_func,(void*) bqs);
pthread_create(&poductor[i],nullptr,poductor_func,(void*) bqs);
}
pthread_create(&saver,nullptr,saver_func,(void*) bqs);
for(int i=0;i<5;i++)
{
pthread_join(consumer[i],nullptr);
pthread_join(poductor[i],nullptr);
}
pthread_join(saver,nullptr);
return 0;
}
然后我们试着将其运行一下看看能不能运行成功:
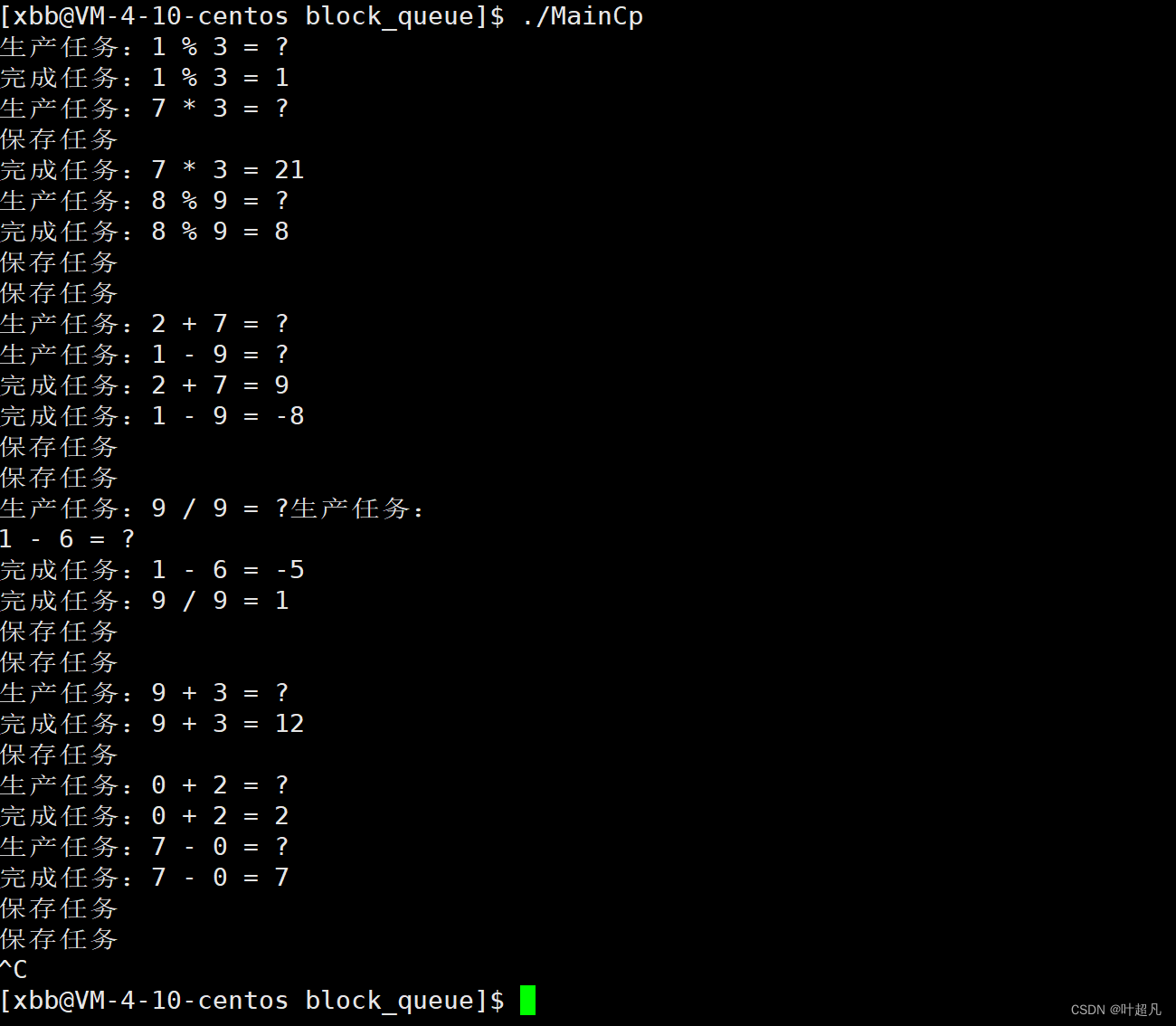
文件中保存的内容如下:
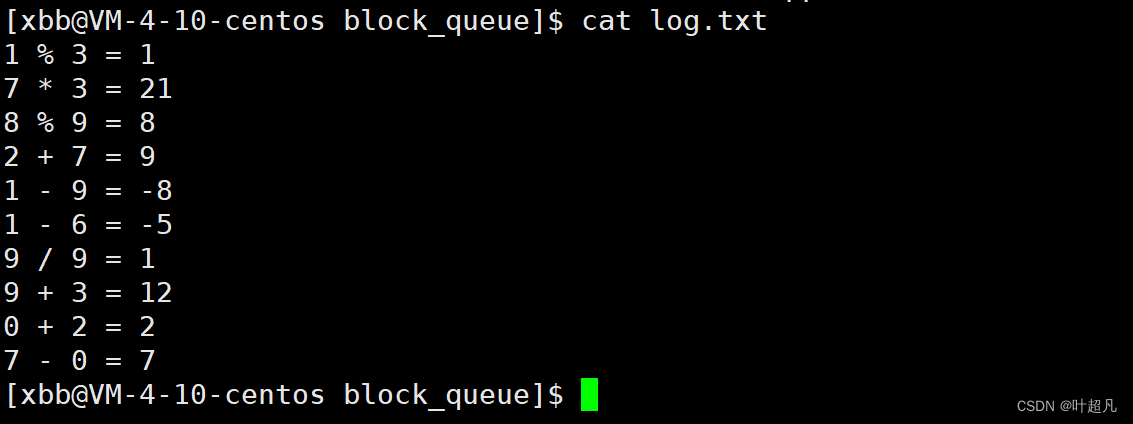
仔细的对比一下发现这里无论是计算结果还是任务被处理的顺序都是对的上的,那么这就说明多生产多消费的模型实现的是正确的,而我们之前说这样的模型要保证消费者和消费者之间是互斥的,生产者和生产者之间是互斥的,那这里是如何做到的呢?答案是pop函数和push函数中对同一把锁的竞争,当多个生产者争夺同一锁的时候生产者之间就是互斥的,多个消费者争夺同一把锁的时候消费者之间就是互斥的,而生产者和消费者之间争夺的也是同一把所以生产者和消费者之间也是互斥的,所以上述的代码在实现单生产和单消费的时候就已经达到了多生产和多消费的功能。
生产者消费者模型的意义
在之前的学习中我们总是听到这么一个观点:该模型能够提高效率,但是通过上面的分析我们可以看到因为锁的存在不管当前生产者中存在多少个线程只有一个线程能向队列里面放数据,不管创建了多少个生产者线程也只有一个线程能从队列当中获取数据,并且生产者放置数据和消费者获取数据的操作还是互斥的,那这个高效究竟高效在哪呢?比如说下面的图片:
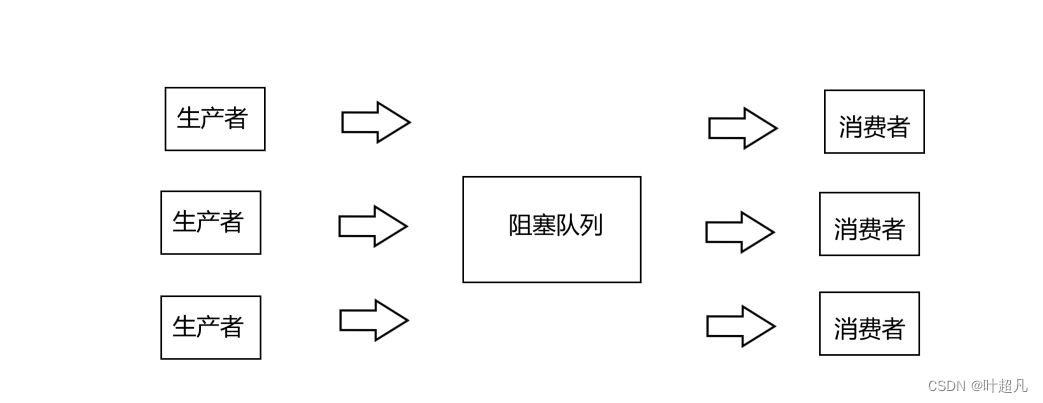
那么要想知道这个问题首先我们的目光就不能停留在阻塞队列上面,我们首先来看看生产者将任务放到阻塞队列这件事,这个任务是怎么来的呢?答案是生产者制造的获取到的,那获取任务构造任务的时候需要消耗时间吗?答案是肯定需要的毕竟任务不是凭空而来的,其次我们再看看消费者将任务取出来这件事,消费者获取任务之后难道就什么事情都不做了吗?肯定不是的消费者获取任务之后也得对任务做出一些操作,这些操作肯定是需要消耗时间的,所以该模型的高效并不是存数据拿数据的高效,而是我们可以让多个线程并发处理多个任务的同时其他的线程还可以从队列中拿数据存放数据,也就是下面图片这样:
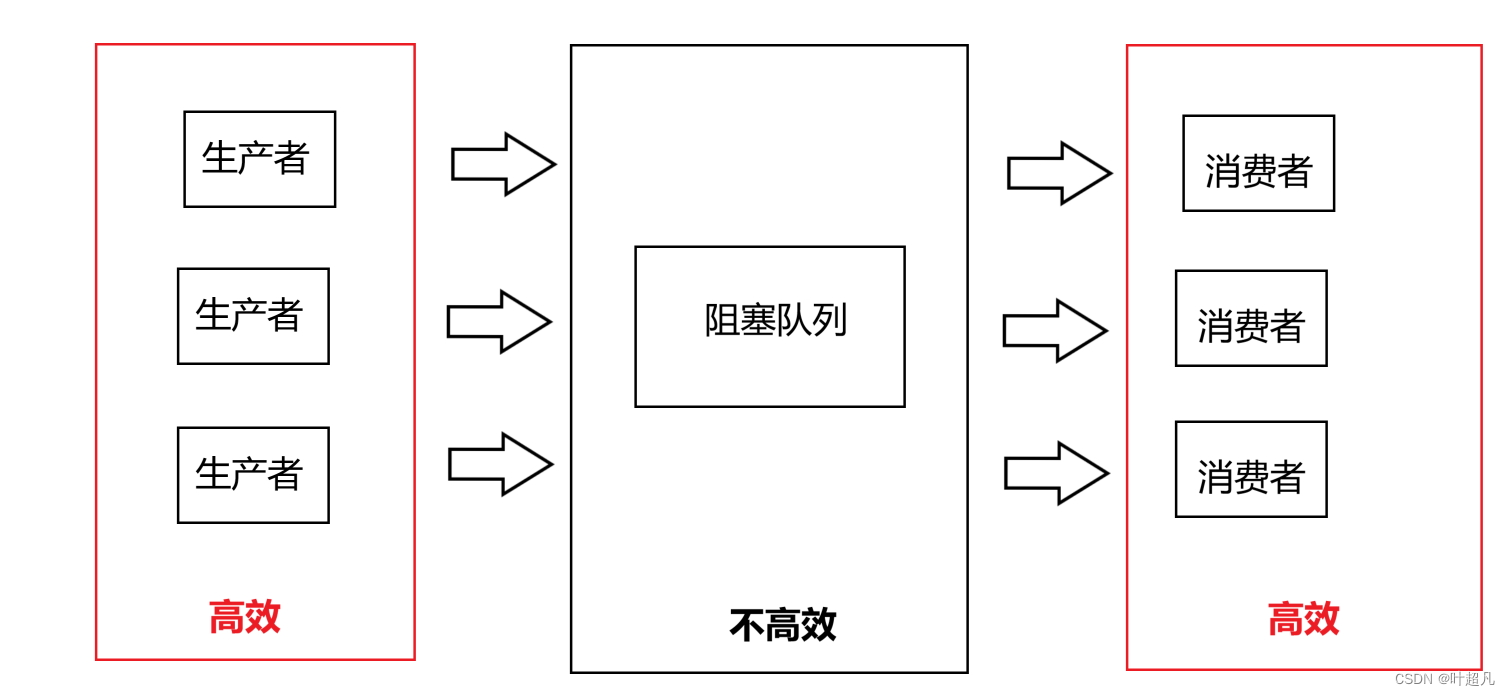
也就是在存放任务之前和拿取任务之后,让生产者线程并发执行让消费者并发执行从而达到高效的目的。











![VM虚拟机逆向---[羊城杯 2021]Babyvm 复现【详解】](https://img-blog.csdnimg.cn/632f8a02e2d144c0ae2f1462606049fb.png)