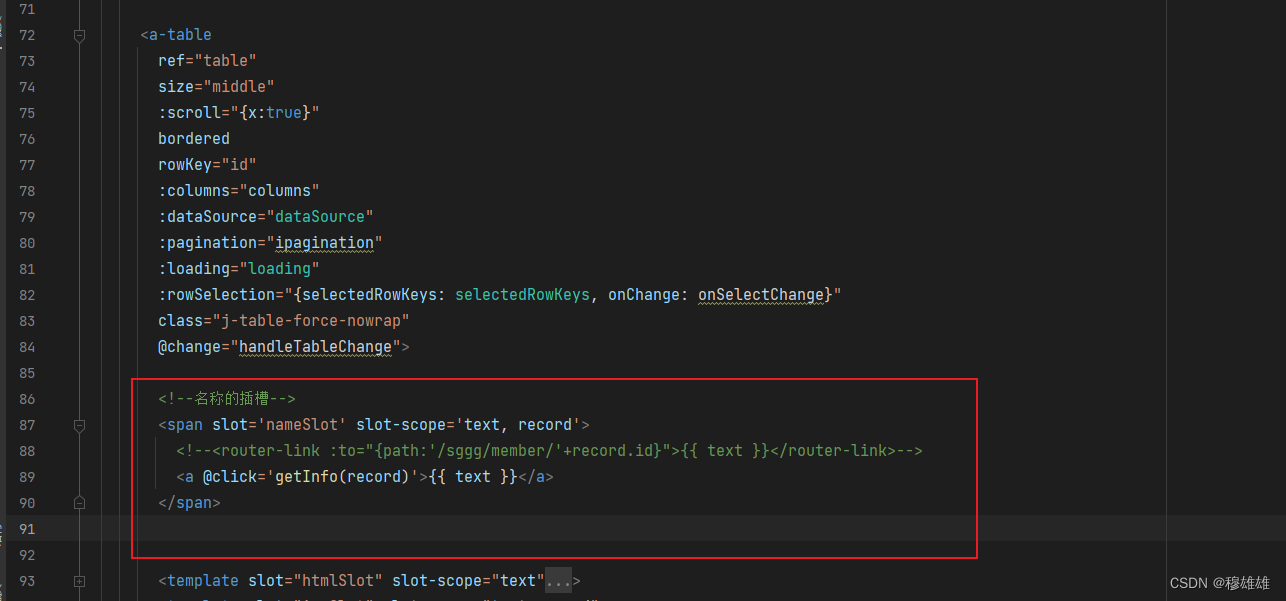
Regularized Normal Equation for Linear Re-gression Given a data set
{ar(), y()}i=1,.-.,m with x()∈ R" and g(∈ R, the generalform of
regularized linear regression is as follows n (he(zr)- g)3+入>0号 (1) ”
2m i=1 j=1 Derive the normal equation.

设
X = [ ( x ( 1 ) ) T ( x ( 2 ) ) T . . . ( x ( m ) ) T ] X=\begin{bmatrix} (x^{(1)})^T \\ (x^{(2)})^T \\ ... \\ (x^{(m)})^T \end{bmatrix} X= (x(1))T(x(2))T...(x(m))T , Y = [ y ( 1 ) y ( 2 ) . . . y ( m ) ] Y=\begin{bmatrix} y^{(1)} \\ y^{(2)} \\ ... \\ y^{(m)} \end{bmatrix} Y= y(1)y(2)...y(m) ,
因此, X θ − Y = [ ( x ( 1 ) ) T θ ( x ( 2 ) ) T θ . . . ( x ( m ) ) T θ ] − [ y ( 1 ) y ( 2 ) . . . y ( m ) ] = [ h θ ( x ( 1 ) ) − y ( 1 ) h θ ( x ( 2 ) ) − y ( 2 ) . . . h θ ( x ( m ) ) − y ( m ) ] X \theta-Y=\begin{bmatrix} (x^{(1)})^T\theta \\ (x^{(2)})^T\theta \\ ... \\ (x^{(m)})^T\theta \end{bmatrix}-\begin{bmatrix} y^{(1)} \\ y^{(2)} \\ ... \\ y^{(m)} \end{bmatrix}=\begin{bmatrix} h_{\theta}(x^{(1)})-y^{(1)} \\ h_{\theta}(x^{(2)})-y^{(2)} \\ ... \\ h_{\theta}(x^{(m)})-y^{(m)} \end{bmatrix} Xθ−Y= (x(1))Tθ(x(2))Tθ...(x(m))Tθ − y(1)y(2)...y(m) = hθ(x(1))−y(1)hθ(x(2))−y(2)...hθ(x(m))−y(m) ,
损失函数可以表达为 J ( θ ) = 1 2 m [ ( X θ − Y ) T ( X θ − Y ) + λ θ T θ ] J(\theta)=\frac{1}{2m}[(X \theta-Y)^T(X \theta-Y)+\lambda\theta^T\theta] J(θ)=2m1[(Xθ−Y)T(Xθ−Y)+λθTθ],
∇
θ
J
(
θ
)
=
∇
θ
1
2
m
[
(
X
θ
−
Y
)
T
(
X
θ
−
Y
)
+
λ
θ
T
θ
]
\nabla_{\theta}J(\theta)=\nabla_{\theta}\frac{1}{2m}[(X \theta-Y)^T(X \theta-Y)+\lambda\theta^T\theta]
∇θJ(θ)=∇θ2m1[(Xθ−Y)T(Xθ−Y)+λθTθ]
=
1
2
m
[
∇
θ
(
X
θ
−
Y
)
T
(
X
θ
−
Y
)
+
∇
θ
λ
θ
T
θ
]
=\frac{1}{2m}[\nabla_{\theta}(X \theta-Y)^T(X \theta-Y)+\nabla_{\theta}\lambda\theta^T\theta]
=2m1[∇θ(Xθ−Y)T(Xθ−Y)+∇θλθTθ]
∇ θ λ θ T θ = λ ∇ θ θ T θ = λ ∇ θ t r ( θ θ T ) = λ L θ \nabla_{\theta}\lambda\theta^T\theta=\lambda\nabla_{\theta}\theta^T\theta=\lambda\nabla_{\theta}tr(\theta\theta^T)=\lambda L\theta ∇θλθTθ=λ∇θθTθ=λ∇θtr(θθT)=λLθ
因此, ∇ θ J ( θ ) = 1 2 m ( X T X θ − X T Y + λ L θ ) \nabla_{\theta}J(\theta)=\frac{1}{2m}(X^TX\theta-X^TY+\lambda L\theta) ∇θJ(θ)=2m1(XTXθ−XTY+λLθ)
令 ∇ θ J ( θ ) = 0 \nabla_{\theta}J(\theta)=0 ∇θJ(θ)=0,当 X X X矩阵各列向量线性独立时, X T X X^TX XTX矩阵可逆,存在唯一解 θ = ( X T X + λ L ) − 1 X T Y \theta=(X^TX+\lambda L)^{-1}X^TY θ=(XTX+λL)−1XTY.
aussian Discriminant Analysis Model Given m training data {x() ,
g)}i=1,… ,m,assume that y ~ Bernoulli(b),ay =0~N(uo,2),x \ y = 1
~N(u1,>).Hence, we have p(y)= ”(1 一 )1一u .p(zl y =0)=(2z7)"/72 3(1/
exp(一士(a一 uo)T>-1(a 一o))op(al y= 1)=(2n)n/l2(1/a exp (一是(a
一u1)TE-1(a一ui))The log-likelihood function is m l(, /Lo,41,>)= log ][
[p(r(), g); o, uo,41,) i二1 m
=logp(x()| g() ; ,uo,41,2)p(g() ; ) i—1 Solve p,o,u1 and 2 by maximizing l(, Lo,u1,>). Hint: xtr(AX-1B)=一(X-1BAX-1)T,VA|A=|A|(A-1)T

这里 高斯判别分析(GDA)公式推导
3MLE for Naive Bayes Consider the following definition of MLE problem
for multinomials. Theinput to the problem is a finite set J,and a
weight cg > 0 for each gy ∈ y. The output from the problem is the
distribution p* that solves the followingmaximization problem. p*= arg
max > c y log py y∈ (i) Prove that,the vector p* has components p,-Cy
for Vy ∈ y,where N = >ucycy.(Hint: Use the theory of
Lagrangemultiplier) (1i) Using the above consequence,prove that,the
maximum-likelihood esti- mates for Naive Bayes model are as follows
p)=之1 1(y()=gy) m and Ps(a l y)=>E1 1(g=y Aa,=z) 〉岩11(g(阈)= g)


(i)设拉格朗日函数为
L
(
Ω
,
α
)
=
∑
y
∈
Y
c
y
l
o
g
p
y
−
α
(
∑
y
∈
Y
p
y
−
1
)
L(\Omega,\alpha)=\sum_{y\in Y}c_ylogp_y-\alpha(\sum_{y\in Y}p_y-1)
L(Ω,α)=∑y∈Ycylogpy−α(∑y∈Ypy−1),其中
α
\alpha
α为拉格朗日乘子,
对 p y p_y py求偏导,令 ∂ ∂ p y L ( Ω , α ) = 0 \frac{\partial}{\partial p_y}L(\Omega,\alpha)=0 ∂py∂L(Ω,α)=0,
求得 p y ∗ = c y α p_y^{*}=\frac{c_y}{\alpha} py∗=αcy,代入 ∑ y ∈ Y p y ∗ = 1 \sum_{y\in Y} p_y^{*}=1 ∑y∈Ypy∗=1得 ∑ y ∈ Y c y α = 1 \frac{\sum_{y\in Y}c_y}{\alpha}=1 α∑y∈Ycy=1,
而 N = ∑ y ∈ Y c y N=\sum_{y\in Y}c_y N=∑y∈Ycy,因此 α = N \alpha=N α=N,进而 p y ∗ = c y N p_y^{*}=\frac{c_y}{N} py∗=Ncy
(ii)贝叶斯的最大似然模型的目标函数为
m a x ∑ i = 1 m l o g p ( y ( i ) ) + ∑ i = 1 m ∑ j = 1 n l o g p j ( x j ( i ) ∣ y ( i ) ) max\ {\sum^{m}_{i=1}logp(y^{(i)})}+\sum^{m}_{i=1}\sum^{n}_{j=1}logp_j(x_j^{(i)}|y^{(i)}) max ∑i=1mlogp(y(i))+∑i=1m∑j=1nlogpj(xj(i)∣y(i))
设标签种类数为 k k k,则 p ( y ) p(y) p(y)满足约束 ∑ i = 1 k p ( y ) = 1 \sum^k_{i=1} p(y)=1 ∑i=1kp(y)=1,以及 p ( x j ∣ y ) p(x_{j}|y) p(xj∣y)满足约束 ∑ j = 1 n p ( x j ∣ y ) = 1 \sum^n_{j=1} p(x_{j}|y)=1 ∑j=1np(xj∣y)=1,且所有概率均是非负的。
注意到加号两边可以分开独立进行优化,对于加号左边考虑优化模型:
m a x ∑ i = 1 m l o g p ( y ( i ) ) max\ {\sum^{m}_{i=1}logp(y^{(i)})} max ∑i=1mlogp(y(i))
s . t . ∑ i = 1 k p ( y ) = 1 s.t. \sum^k_{i=1} p(y)=1 s.t.∑i=1kp(y)=1
将标签 y y y在训练集中的出现次数 c n t ( y ) cnt(y) cnt(y)视为权重 c y c_y cy,其中 c n t ( y ) = ∑ i = 1 m 1 ( y ( i ) = y ) cnt(y)=\sum^m_{i=1}1(y^{(i)}=y) cnt(y)=∑i=1m1(y(i)=y),因此
m a x ∑ i = 1 m l o g p ( y ( i ) ) = m a x ∑ i = 1 k c n t ( y ) l o g p ( y ) max\ {\sum^{m}_{i=1}logp(y^{(i)})}=max\ {\sum^{k}_{i=1}cnt(y)logp(y)} max ∑i=1mlogp(y(i))=max ∑i=1kcnt(y)logp(y),根据第一问的结论有 p ∗ ( y ) = c n t ( y ) m = ∑ i = 1 m 1 ( y ( i ) = y ) m p^*(y)=\frac{cnt(y)}{m}=\frac{\sum^m_{i=1}1(y^{(i)}=y)}{m} p∗(y)=mcnt(y)=m∑i=1m1(y(i)=y).
同理,将特征 x j x_j xj在训练集标签为 y y y的样本中的出现次数 c n t ( x j ∣ y ) cnt(x_j|y) cnt(xj∣y)视为权重 c y c_y cy,其中 c n t ( x j ∣ y ) = ∑ i = 1 m 1 ( y ( i ) = y ∧ x j ( i ) = x ) cnt(x_j|y)=\sum^m_{i=1}1(y^{(i)}=y \land x_j^{(i)}=x) cnt(xj∣y)=∑i=1m1(y(i)=y∧xj(i)=x),因此
m a x ∑ i = 1 m ∑ j = 1 n l o g p j ( x j ( i ) ∣ y ( i ) ) = m a x ∑ j = 1 n ∑ i = 1 m l o g p j ( x j ( i ) ∣ y ( i ) ) = m a x ∑ j = 1 n c n t ( x j ∣ y ) l o g p j ( x j ∣ y ) max\ \sum^{m}_{i=1}\sum^{n}_{j=1}logp_j(x_j^{(i)}|y^{(i)})\\=max\ \sum^{n}_{j=1}\sum^{m}_{i=1}logp_j(x_j^{(i)}|y^{(i)})\\=max \sum^{n}_{j=1}cnt(x_j|y)logp_j(x_j|y) max ∑i=1m∑j=1nlogpj(xj(i)∣y(i))=max ∑j=1n∑i=1mlogpj(xj(i)∣y(i))=max∑j=1ncnt(xj∣y)logpj(xj∣y)
根据第一问的结论有 p j ∗ ( x j ∣ y ) = c n t ( x j ∣ y ) c n t ( y ) = ∑ i = 1 m 1 ( y ( i ) = y ∧ x j ( i ) = x ) ∑ i = 1 m 1 ( y ( i ) = y ) p^*_j(x_j|y)=\frac{cnt(x_j|y)}{cnt(y)}=\frac{\sum^m_{i=1}1(y^{(i)}=y \land x_j^{(i)}=x)}{\sum^m_{i=1}1(y^{(i)}=y)} pj∗(xj∣y)=cnt(y)cnt(xj∣y)=∑i=1m1(y(i)=y)∑i=1m1(y(i)=y∧xj(i)=x),证毕。