目录
- 1.数据库约束
- 1.1 unique
- 1.2 not null
- 1.3 default
- 1.5 primary key
- 1.6 foreign key
- 2. 将A的记录插入到B中
- 3.聚合函数
- 3.1 count()函数
- 3.2 sum()函数
- 3.3 avg()函数
- 3.4 max()函数
- 3.5 MIN()函数
- 3.6 group by
- 4.联合查询
- 4.1 内连接
- 4.2 外连接
- 4.3 自连接
- 4.4 子连接
1.数据库约束
约束就是数据库在使用的时候,对于里面能够存的数据提出的要求和限制.程序猿就可以借助约束来对数据完成更好的校验.
| 数据库约束类型: 1.not null,指示某列不能存储 NULL 值,如果插入了空值会报错. 2.unique,保证某列的每行必须有唯一的值,如果插入了重复的值,就会报错 3.default,约定一个默认值 4.primary key,主键约束,相当于数据唯一的身份标识,类似于身份证号 5.foreign key,外键,表示两个表之间的关联关系,表1里的数据要存在于表2之中. 6.check,制定一个条件,根据条件来判断,但是MySQL不支持这个约束. 7.上述提到的约束是根据每个列来单独设置的,不同列之间没有影响 |
1.1 unique
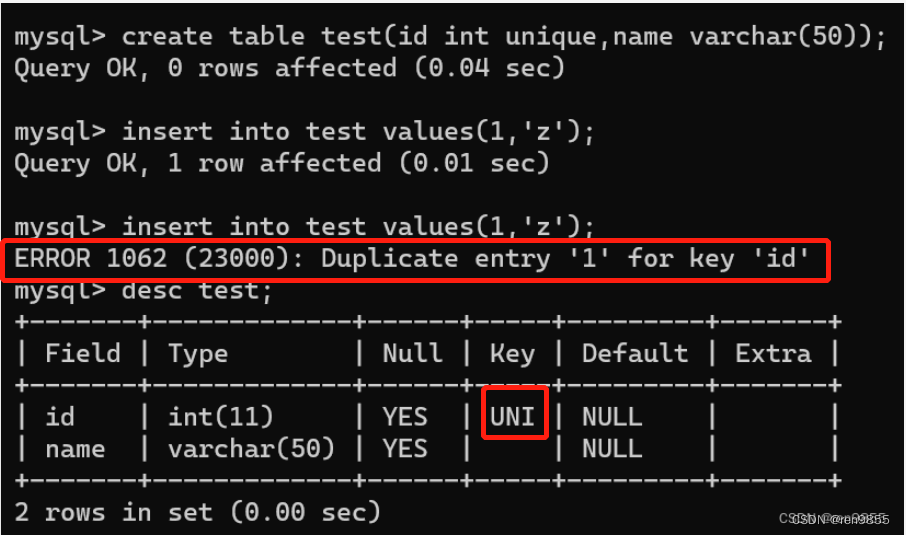
1.2 not null
not null 可以给多列设置,而不只是单单一列.

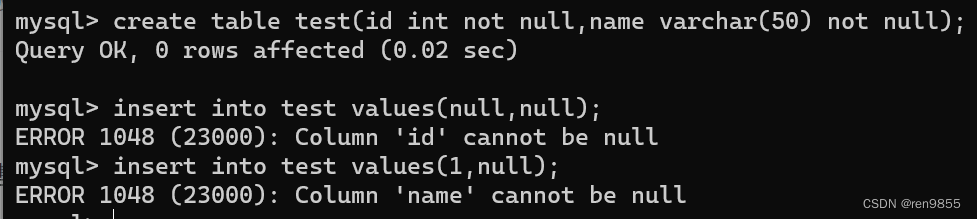
1.3 default
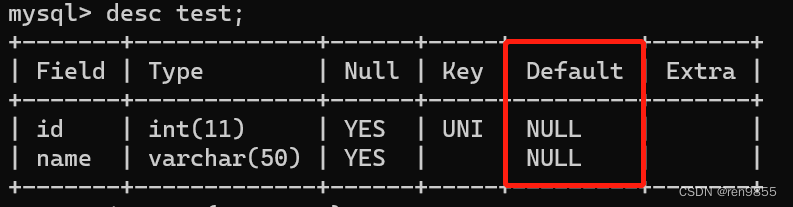

我们可以把默认值改成自己想要的内容,在创建表的时候,在default后面添加想要的名称.

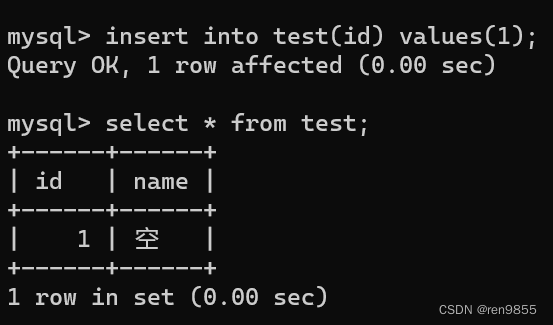
1.5 primary key
对于一个表来说,只能有一列被设置为主键
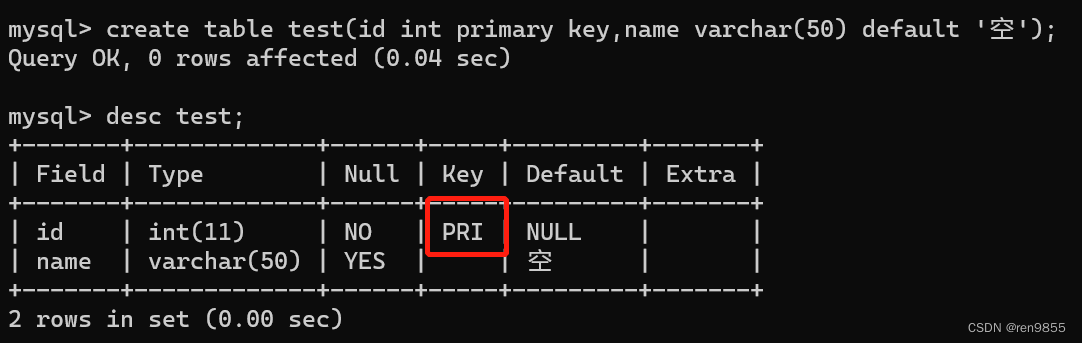
主键不能为空,也不能被重复插入.
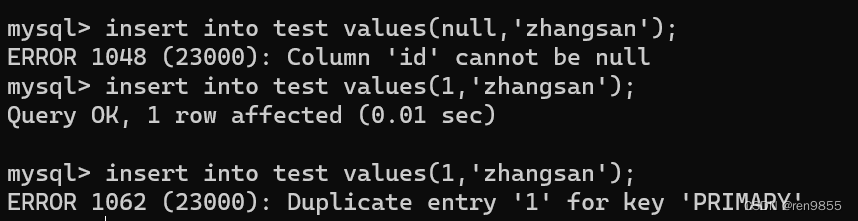
关于主键,典型的用法就是使用1,2,3,4这样整数自增的方式来进行,MySQL内置了自增主键
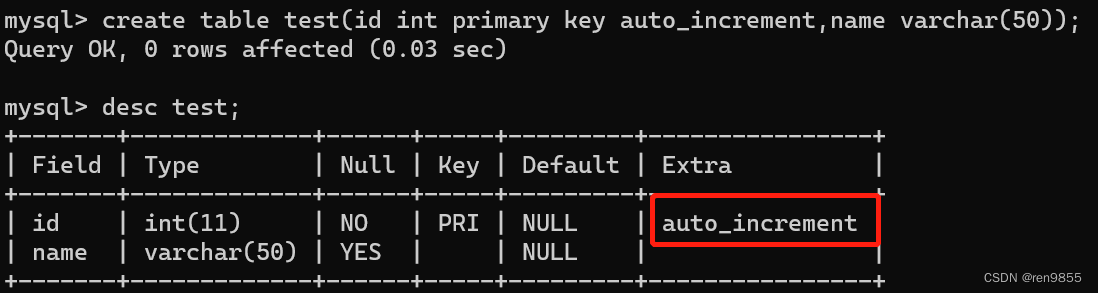
当设定好自增主键之后,插入记录时,我们就可以不指定主键的值(里面可以通过null来表示),交给MySQL自行处理即可,依靠自增主键来分配.
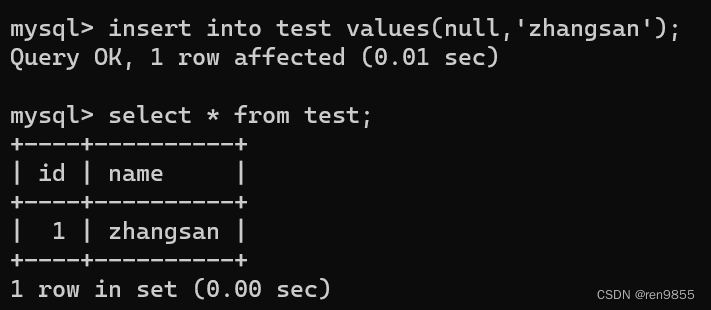
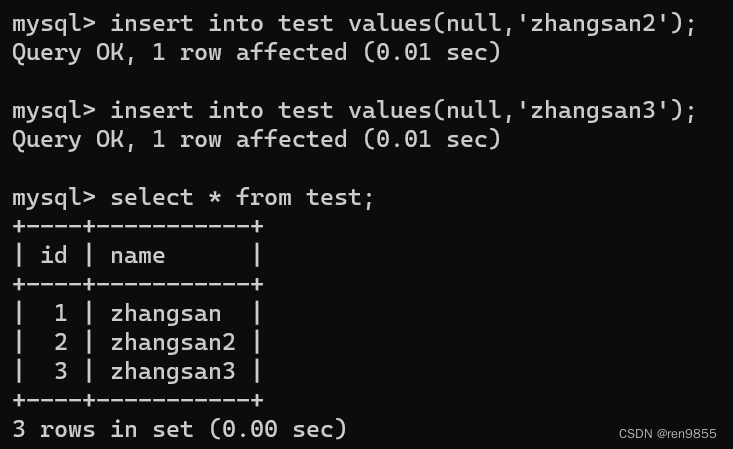
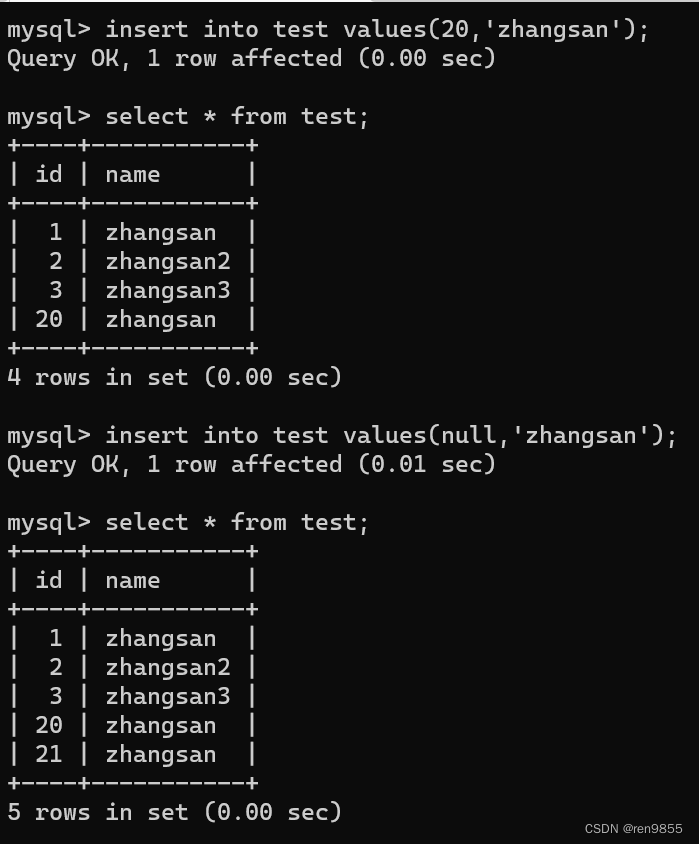
如果我们手动指定了自增主键的值,那么之后插入的数据都会根据手动指定值之后的值来增加,比如下图手动指定了20,那么3-20之间的值都用不了了,从21开始.
1.6 foreign key
外键用于关联其他表的主键或唯一键
foreign key (字段名) references 主表(列)
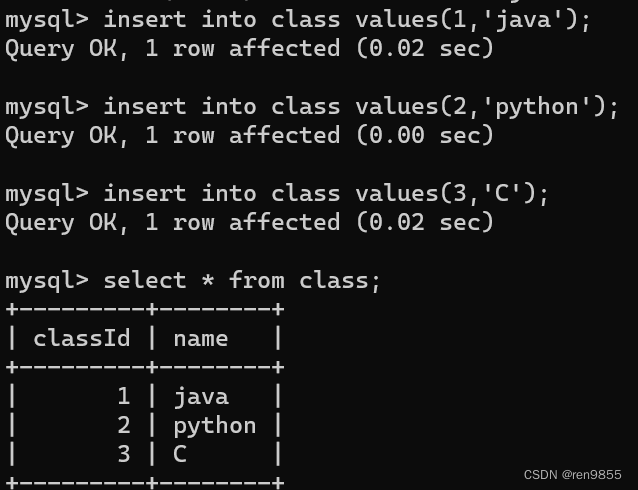
比如我们要创建一个学生表和班级表,可以得出一个班级包含多个学生,多个学生属于一个班级,学生表依赖班级表,学生表称为字表,班级表称为父表.
创建班级表:

创建学生表,关联班级表,外键约束描述的是两张表的两个列之间的“依赖关系",子表依赖于父表(子表用自父表),要求子表中对应的记录得在父表中存在:

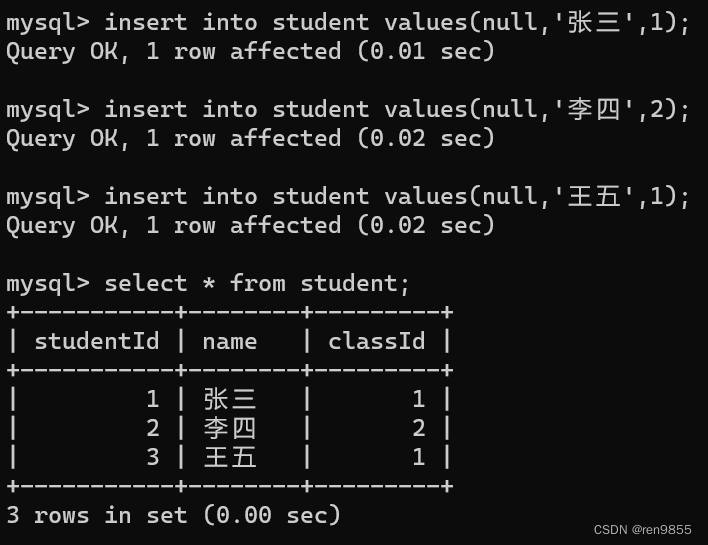

这条记录中,指定的 classld 为 5,在 class 表中不存在, 不能插入成功
 外键约束的工作原理:
外键约束的工作原理:
在子表中插入新的记录的时候,就会先根据对应的值,在父表中先查询,查询到之后,才能够执行后续的插入,这里的查询操作,可能是一个成本较高的操作(比较耗时),外键约束其实要求父表中被依赖的这一列,必须要有索引有了索引就能大大的提高查询速度,class 表的 classld 这一列,得是 primary key或者 unique(有了这俩约束的列, 就会自动的创建出索引了)
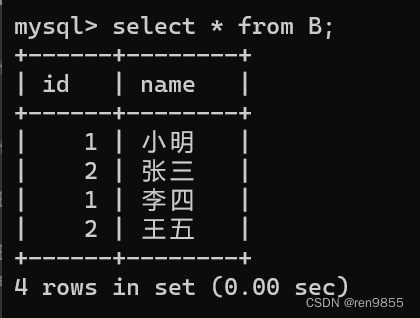
2. 将A的记录插入到B中

3.聚合函数
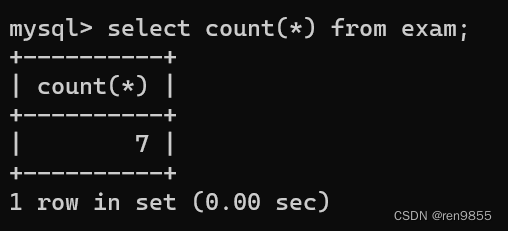
3.1 count()函数
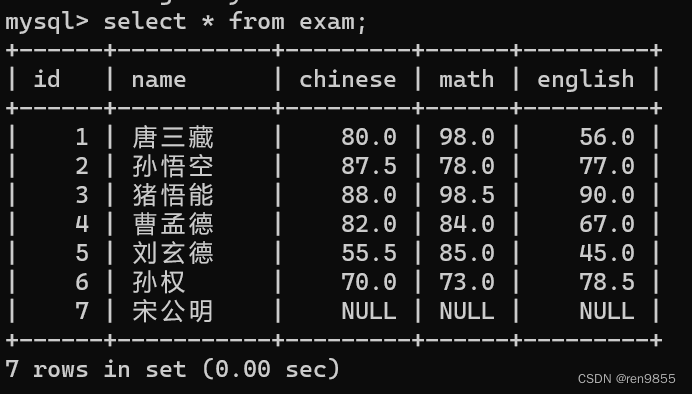
select count(*) from exam;
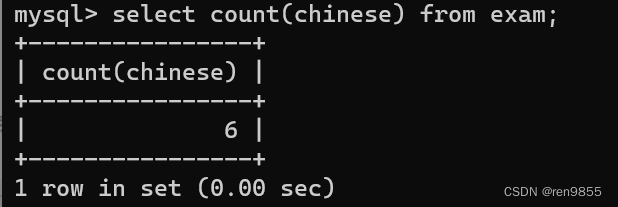
COUNT(*) 计算表中的总行数,不管某列是否有数值或者为空行。就相当于是针对 select * from exam result的结果集合进行计算行数,这里的count不一定就要写 * 号,也可以是列名,COUNT(字段名) 计算指定列下总的行数,计算时将忽略空值的行,NULL值没有记录其中。
3.2 sum()函数
SUM()是一个求总和的函数,返回指定的列值的总和,SUM()函数在计算时,忽略列值为NULL的行
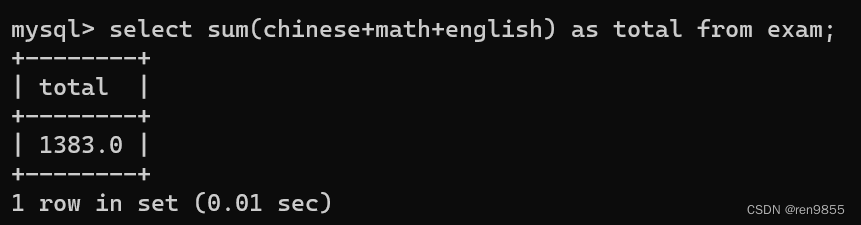
sum()只能针对数字相加,不能针对字符串使用
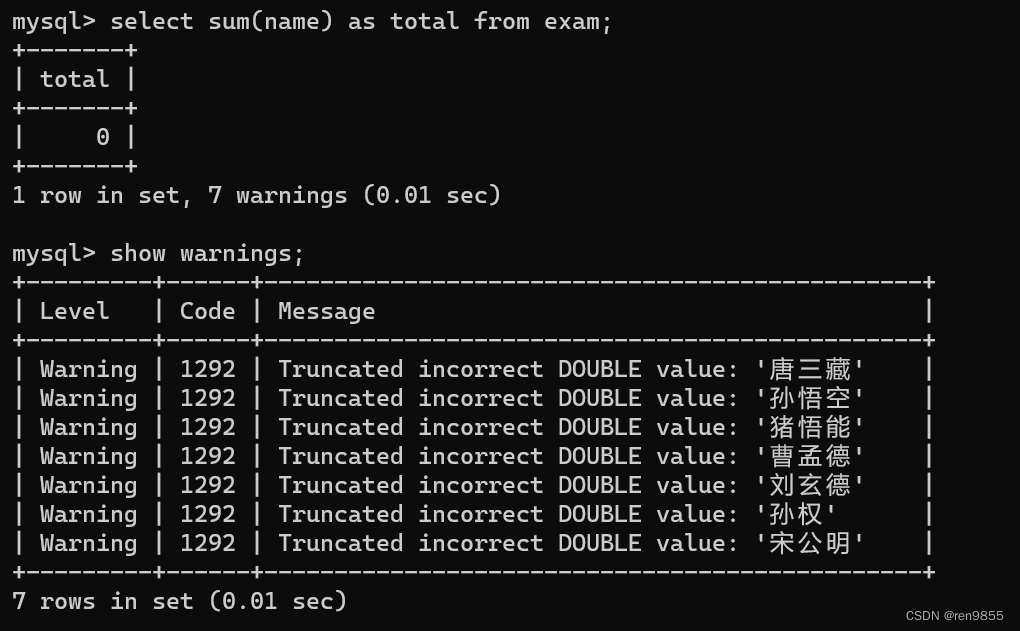
涉及到where时会先进行条件筛选,再进行聚合运算。
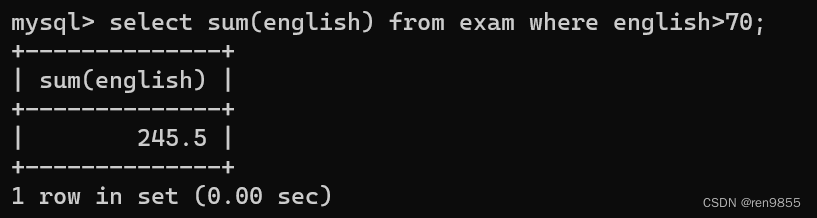
3.3 avg()函数
AVG()函数通过计算返回的行数和每一行数据的和,求得指定列数据的平均值,计算 avg 的时候NULL 这样的记录是不计入其中的,不会影响到平均值的结果
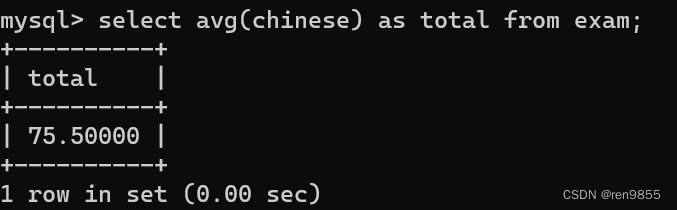
3.4 max()函数
MAX()返回指定列中的最大值

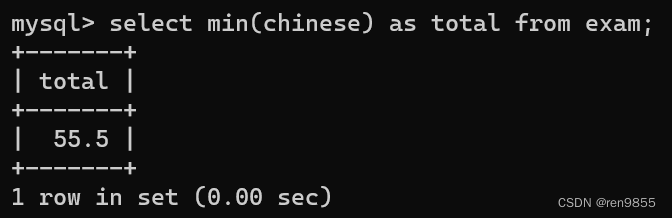
3.5 MIN()函数
MIN()返回查询列中的最小值
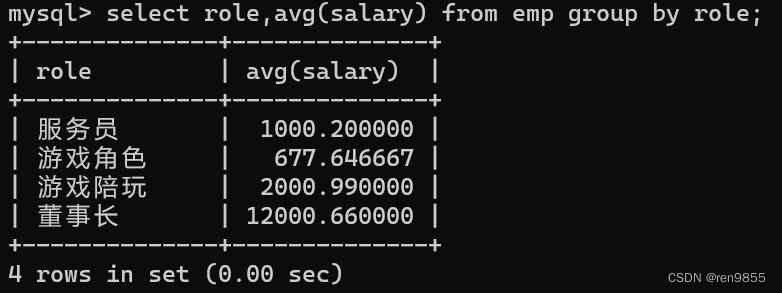
3.6 group by
group by会将这张表先分组,分组之后针对每一组进行聚合函数。

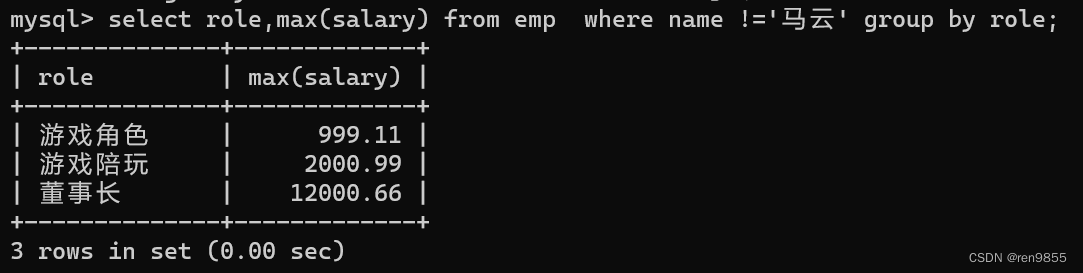
group by 是可以使用 where. 只不过 where 是在分组之前执行.如果要对分组之后的结果进行条件筛选,就需要使用 having,比如我们指定分组之前指定条件:求去掉马云之后每种角色的平均薪资
select role,avg(salary) from emp where name != '马云' group by role
这里就是先去掉马云然后再分组.(分组之前指定的条件就要使用 where)
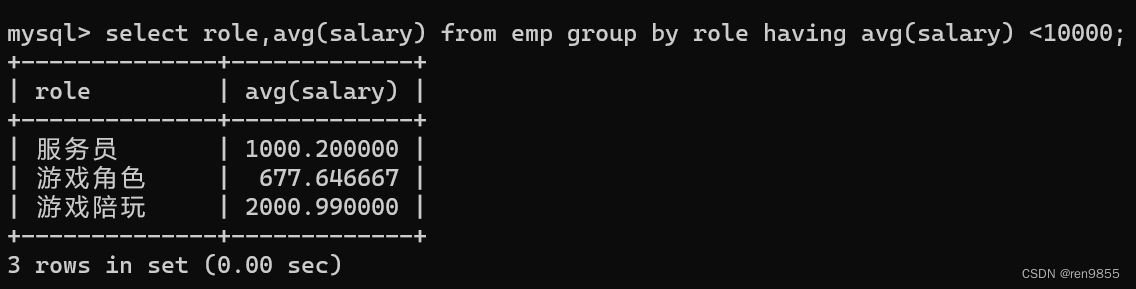
分组之后指定条件筛选:
求每种角色,平均薪资,只保留平均薪资 1w 以下,
这里就是得先分组计算,知道了平均工资,才能进一步的筛选,(分组之后,指定的条件,就需要使用 having 了),此时我们可以看到很明显的看到,董事长这个平均薪资超过 1w 的记录已经没有了
select role,avg(salary) from emp group by role having avg(salary) <10000;
4.联合查询
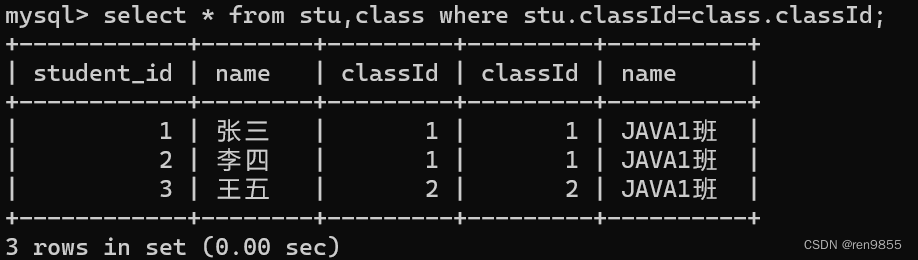
联合查询,把多个表的记录往一起合并,一起进行查询,会用到笛卡尔积
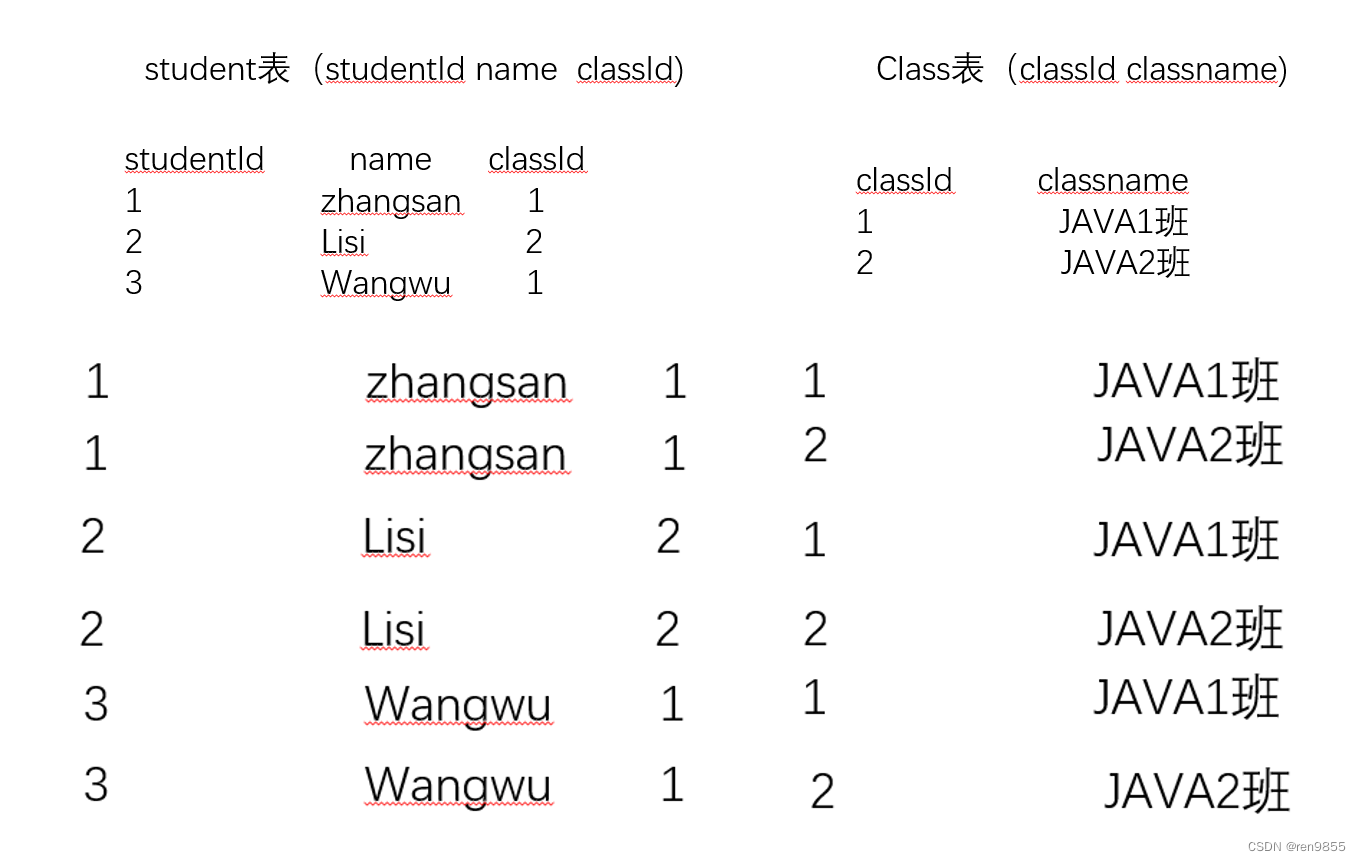
笛卡尔积的计算非常简单,就类似于排列组合,笛卡尔积是针对任意两张表之间进行的运算。笛卡尔积的运算过程:先拿第一张表的第一条记录和第二张表的每个记录,分别组合,得到了一组新的记录继续再拿第一张表的第二条记录重复刚才操作,如下图所示:
针对A和B两张表,计算笛卡尔积此时笛卡尔积的列数,就是A的列数+B的列数,笛卡尔积的行数, 就是 A的行数*B 的行数.
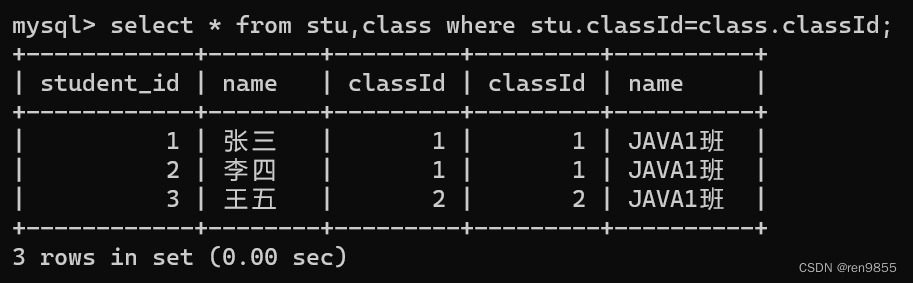
两张表中都有 classld 这一列.classld 的值对应相等的记录,其实就是应该要保留的记录,像这里的 classld 相等这样的条件, 就称为“连接条件",带有连接条件的笛卡尔积其实就是多表查询了.
如果笛卡尔积中的两个列名字相同,在写条件的时候就可以通过表名.列名的方式来访问
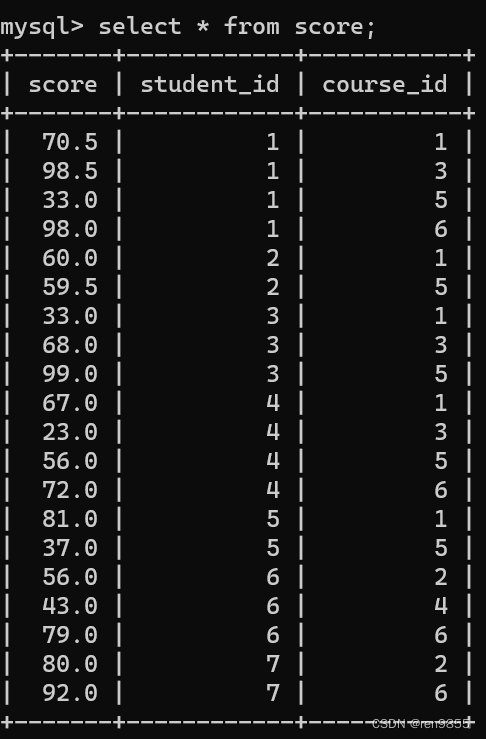
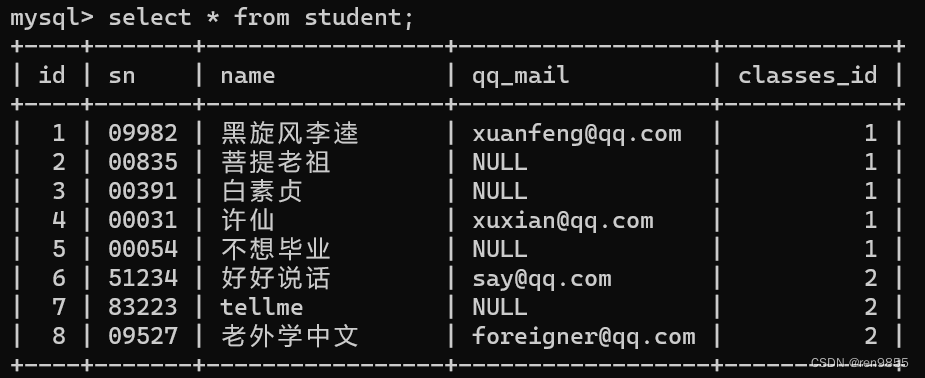
4.1 内连接
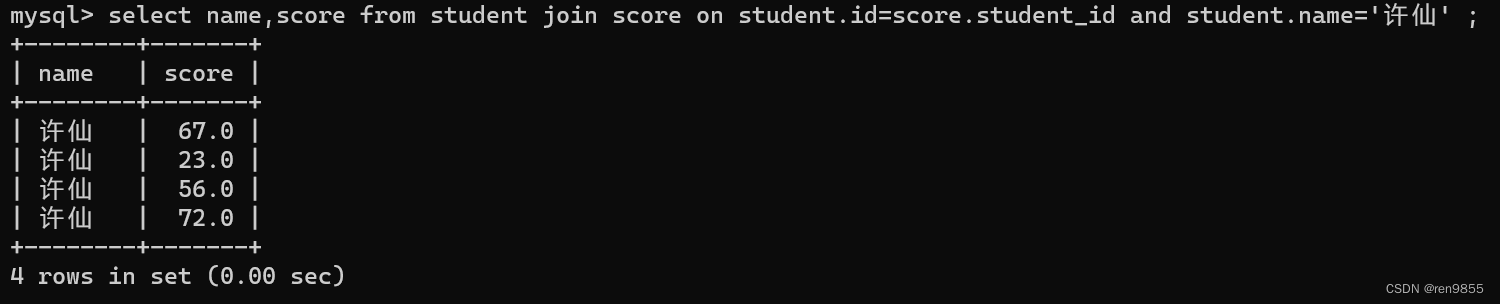
(1)查询“许仙”同学的 成绩
分析这样的问题,就要先想清楚 要查询的数据都来自于哪些表里

实现刚才这个多表查询,直接 from 多张表,是一种写法,除此之外,还有另外一种写法基于 join on 这样的关键字也能实现多表查询
from 表1 join 表2 on 条件
4.2 外连接
上面说的这个 from 多个表 where 写法叫做“内连接",使用join on 的写法既可以表示内连接还可以表示外连接
select列 from 表1 left join 表2 on 条件; 左外连接
select 列 from 表1 right join 表2 on 条件; 右外连接
内连接会把共有的两个表中共有的数据展示出来
left join 以左侧的表为主,会尽可能的把左侧的表的记录都列出来, 大不了后侧的表的对应列填成 NULL
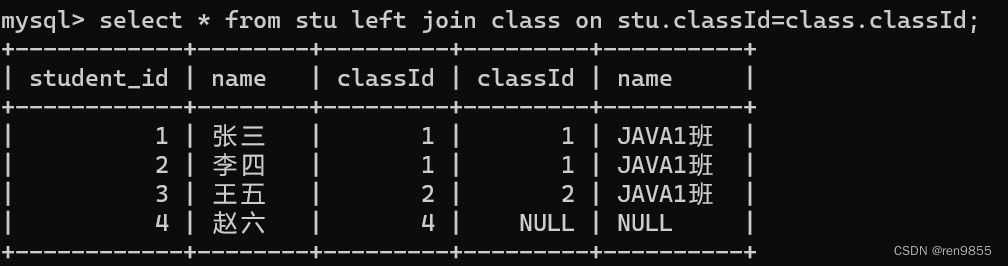
right join 也是类似,以右侧的表为主,尽可能把右侧的记录都列出来,大不了左侧的表对应的列填成 NULL
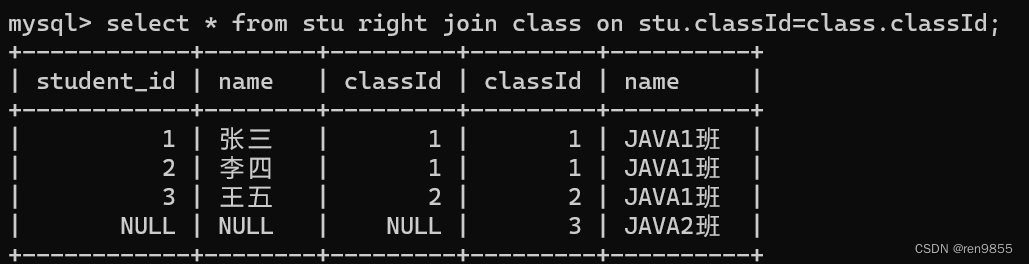
4.3 自连接
自连接是指在同一张表连接自身进行查询
比如要显示所有“计算机原理”成绩比“Java”成绩高的成绩信息:
4.4 子连接
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
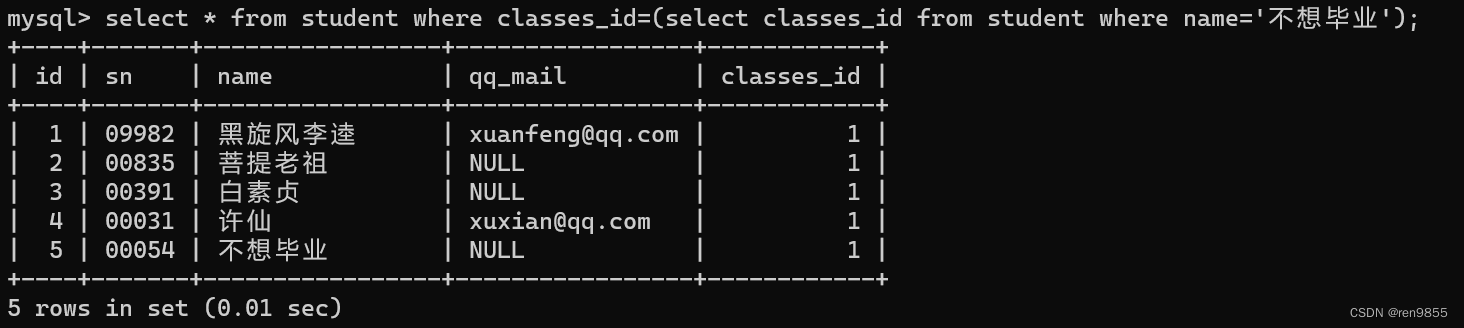
查询与“不想毕业” 同学的同班同学:
select * from student where classes_id=(select classes_id from student where name='不想毕业');





![[Python学习系列] 走进Django框架](https://img-blog.csdnimg.cn/25df00b39891417a80e9463099c351ae.png)