文章目录
- HDFS介绍
- HDFS体系
- HDFS的Shell介绍
- HDFS的常见Shell操作
- HDFS案例实操
- Java操作HDFS
- 配置环境
- HDFS的回收站
- HDFS的安全模式
- 实战:定时上传数据至HDFS
- HDFS的高可用和高扩展
- HDFS的高可用(HA)
- HDFS的高扩展(Federation)
HDFS介绍
HDFS是一个分布式的文件系统
假设让我们来设计一个分布式的文件系统,我们该如何设计呢?
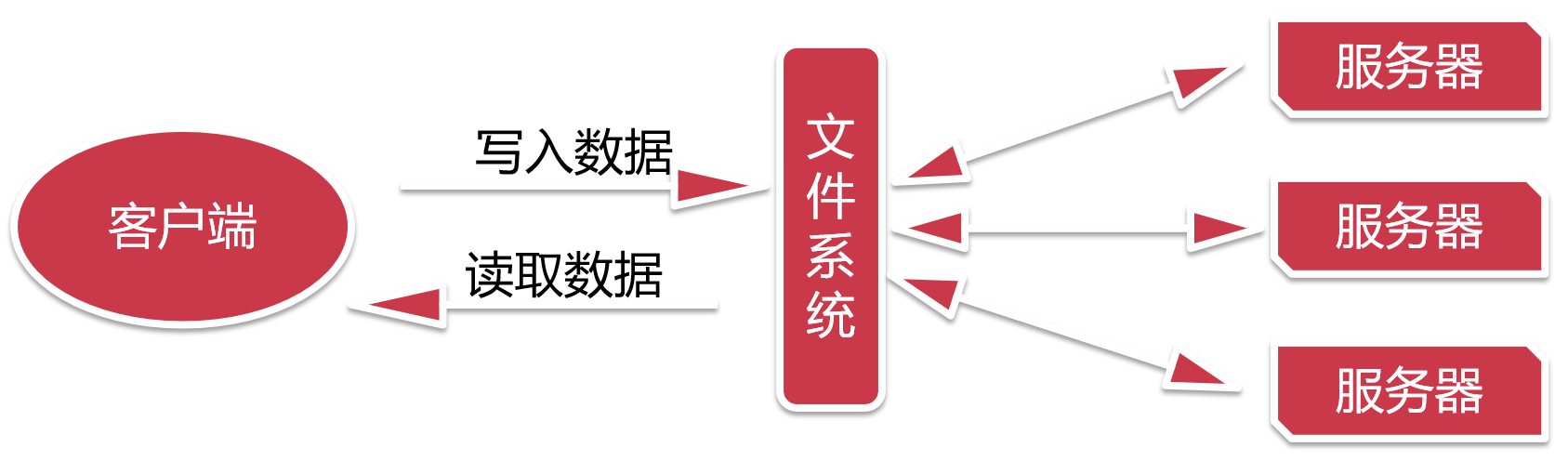
这个统一由文件系统进行管理,我们只需要和文件系统进行交互就可以了。
这样是不是就实现了分布式存储了,这种方案在实际应用中可行吗?
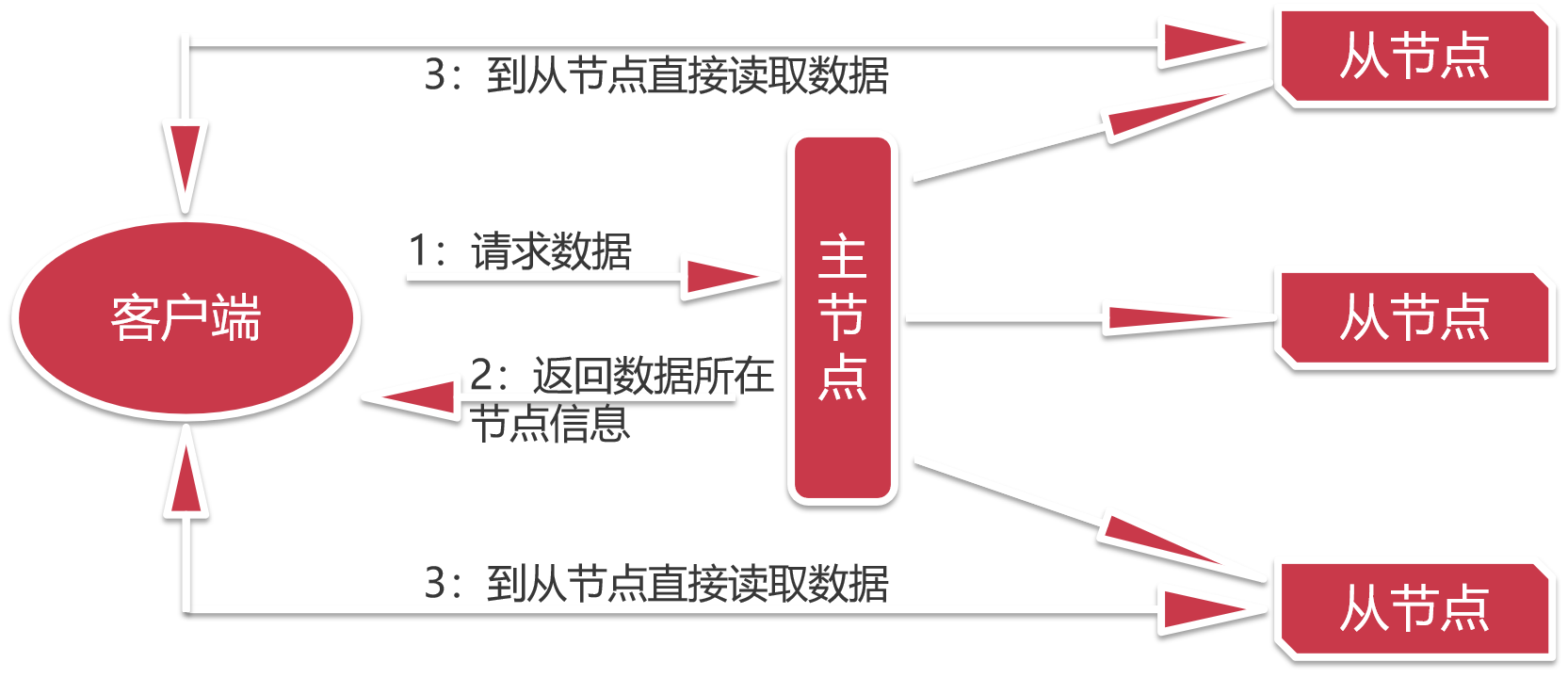
现在这种设计是,我们去找一个中介公司,这里的主节点就可以理解为一个中介公司
这里的从节点就可以理解为是房源,中介公司会在每块房源都安排一个工作人员,当我们找房子的时候,
先联系中介公司,中介公司会告诉我们哪里有房子,并且把对应工作人员的信息告诉我们,我们就可以直接去找对应的工作人员去租房子。这样对于中介公司而言,就没什么压力了。这个就是HDFS这个分布式文件系统的设计思想。
HDFS的全称是Hadoop Distributed File System ,Hadoop的 分布式 文件 系统。它是一种允许文件通过网络在多台主机上分享的文件系统,可以让多台机器上的多个用户分享文件和存储空间。其实分布式文件管理系统有很多。HDFS只是其中一种实现而已,还有 GFS(谷歌的)、TFS(淘宝的)、S3(亚马逊的)。
为什么会有多种分布式文件系统呢?这样不是重复造轮子吗?
不是的,因为不同的分布式文件系统的特点是不一样的,HDFS是一种适合大文件存储的分布式文件系统,不适合小文件存储,什么叫小文件,例如,几KB,几M的文件都可以认为是小文件。
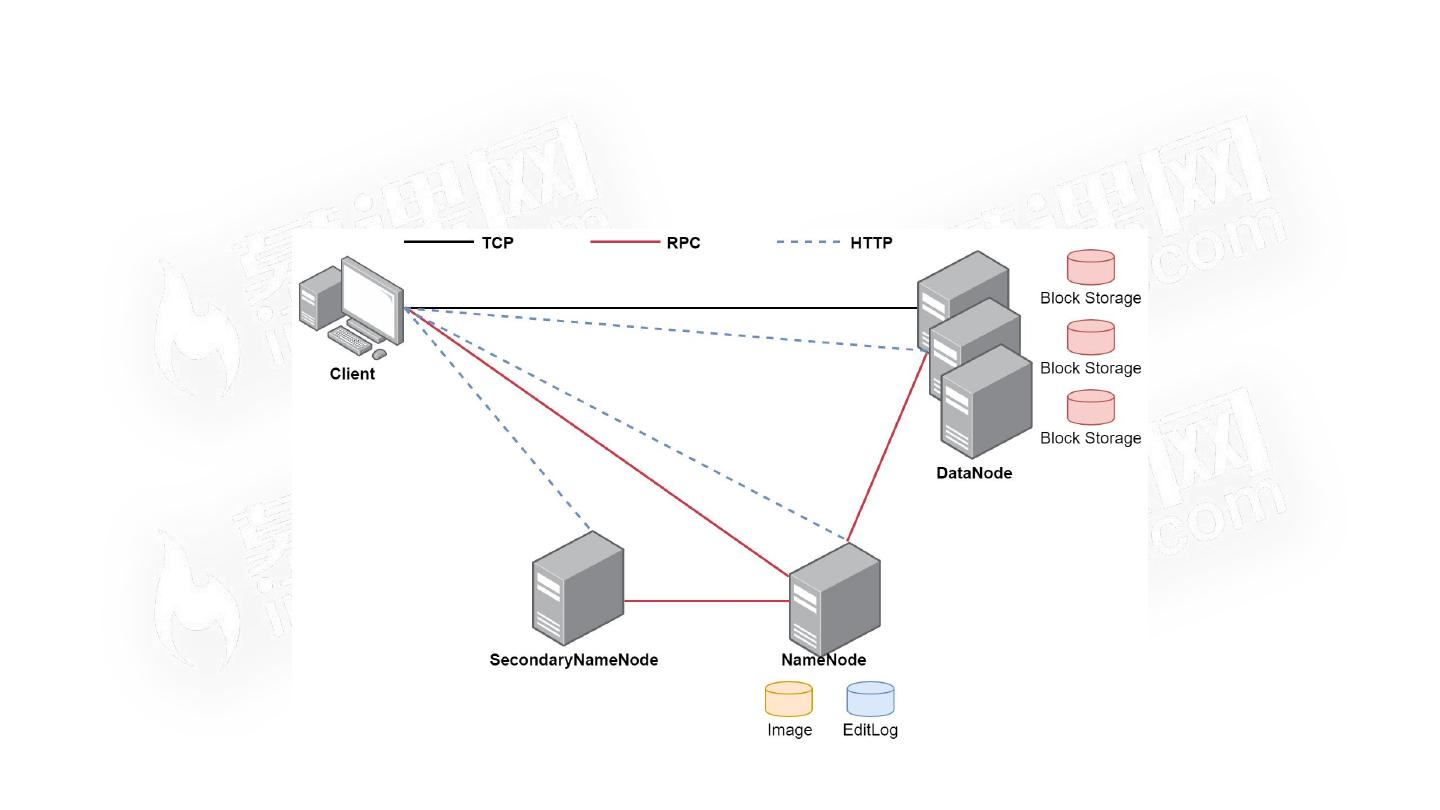
HDFS体系
- HDFS支持主从结构,主节点称为 NameNode ,支持多个从节点称为 ,支持多个
- HDFS中还包含一个 进程
HDFS的Shell介绍
针对HDFS,我们可以在shell命令行下进行操作,就类似于我们操作linux中的文件系统一样,但是具体命
令的操作格式是有一些区别的格式如下:
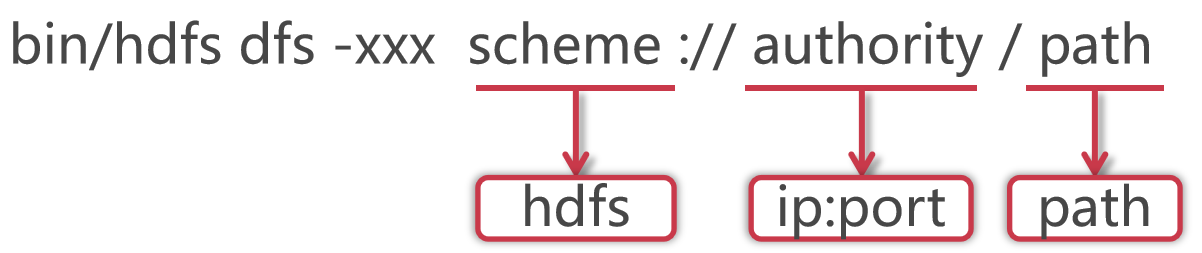
使用hadoop bin目录的hdfs命令,后面指定dfs,表示是操作分布式文件系统的,这些属于固定格式。
如果在PATH中配置了hadoop的bin目录,那么这里可以直接使用hdfs就可以了
这里的xxx是一个占位符,具体我们想对hdfs做什么操作,就可以在这里指定对应的命令了
大多数hdfs 的命令和对应的Linux命令类似
HDFS的常见Shell操作
直接在命令行中输入hdfs dfs,可以查看dfs后面
- -ls:查询指定路径信息
- -put:从本地上传文件
- -cat:查看HDFS文件内容
- -get:下载文件到本地
- -mkdir [-p]:创建文件夹
- -rm [-r]:删除文件/文件夹
HDFS案例实操
需求:统计HDFS中文件的个数和每个文件的大小
1) 我们先向HDFS中上传几个文件,把hadoop目录中的几个txt文件上传上去
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put LICENSE.txt /
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put NOTICE.txt /
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put README.txt /
- 统计根目录下文件的个数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls / |grep /| wc -l
3
/LICENSE.txt 150569
/NOTICE.txt 22125
/README.txt 1361
Java操作HDFS
shell中操作hdfs是比较常见的操作,但是在工作中也会遇到一些需求是需要通过代码操作hdfs的
配置环境
1)在这里我们使用apache-maven-3.0.5-bin.zip ,当然了,其它版本也可以,没有什么本质的区别
把apache-maven-3.0.5-bin.zip解压到某一个目录下面,在这里我解压到了D:\Program Files (x86)\apache-maven-3.0.5目录解压之后,建议修改一下maven的配置文件,把maven仓库的地址修改到其它盘,例如D盘,默认是在C盘的用户目录下修改D:\Program Files (x86)\apache-maven-3.0.5\conf下的settings.xml文件将localRepository标签从注释中移出来,然后将值改为 D:.m2 ,效果如下:
<localRepository>D:\.m2</localRepository>
这样修改之后,maven管理的依赖jar包都会保存到D:.m2目录下了。
2)接下来需要配置maven的环境变量,和windows中配置JAVA_HOME环境变量是一样的。
先在环境变量中配置M2_HOME=D:\Program Files (x86)\apache-maven-3.0.5
然后在PATH环境变量中添加%M2_HOME%\bin即可
环境变量配置完毕以后,打开cmd窗口,输入mvn命令,只要能正常执行就说明windows本地的maven环境配置好了。还需要在idea中指定我们本地的maven配置
点击idea左上角的File–>Settings,进入如下界面,搜索maven,把本地的maven添加到这里面即可。
3) 创建一个maven项目
在这里我们需要引入hadoop-client依赖包,到maven仓库中去找,添加到pom.xml文件中
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
4) 编写代码
package com.imooc.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.net.URI;
/**
* Java代码操作HDFS
* 文件操作:上传文件、下载文件、删除文件
*/
public class HdfsOp {
public static void main(String[] args) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis,fos,1024,true);
}
}
执行代码,发现报错,提示权限拒绝,说明windows中的这个用户没有权限向HDFS中写入数据
解决办法有两个
- 第一种:去掉hdfs的用户权限检验机制,通过在hdfs-site.xml中配置dfs.permissions.enabled为false即可
- 第二种:把代码打包到linux中执行
在这里为了在本地测试方便,我们先使用第一种方式
在主节点上操作:
[root@bigdata01 hadoop-3.2.0]# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
同步到其他节点
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/hdfs-site.xml bigdata02:/d
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/hdfs-site.xml bigdata03:/d
重新启动集群:
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
HDFS的回收站
HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户在Shell命令行删除的文件/目录,会进入到对应的回收站目录中,在回收站中的数据都有一个生存周期,也就是当回收站中的文件/目录在一段时间之内没有被用户恢复的话,HDFS就会自动的把这个文件/目录彻底删除,之后,用户就永远也找不回这个文件/目录了。
默认情况下hdfs的回收站是没有开启的,需要通过一个配置来开启,在core-site.xml中添加如下配置,value的单位是分钟,1440分钟表示是一天的生存周期
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
注意:如果删除的文件过大,超过回收站大小的话会提示删除失败。需要指定参数 -skipTrash ,指定这个参数表示删除的文件不会进回收站
HDFS的安全模式
平时操作HDFS的时候,有时候可能会遇到这个问题,特别是刚启动集群的时候去上传或者删除文
件,会发现报错,提示NameNode处于safe mode。
这个属于HDFS的安全模式,因为在集群每次重新启动的时候,HDFS都会检查集群中文件信息是否完整,例如副本是否缺少之类的信息,所以这个时间段内是不允许对集群有修改操作的,如果遇到了这个情况,可以稍微等一会,等HDFS自检完毕,就会自动退出安全模式。
通过hdfs命令也可以查看当前的状态:
[root@bigdata01 hadoop-3.2.0]# hdfs dfsadmin -safemode get
Safe mode is ON
如果想快速离开安全模式,可以通过命令强制离开,正常情况下建议等HDFS自检完毕,自动退出
[root@bigdata01 hadoop-3.2.0]# hdfs dfsadmin -safemode leave
Safe mode is OFF
实战:定时上传数据至HDFS
需求分析:
在实际工作中会有定时上传数据到HDFS的需求,我们有一个web项目每天都会产生日志文件,日志文件的格式为access_2020_01_01.log这种格式的,每天产生一个,我们需要每天凌晨将昨天生成的日志文件上传至HDFS上,按天分目录存储,HDFS上的目录格式为20200101
针对这个需求,我们需要开发一个shell脚本,方便定时调度执行
- 第一步:我们需要获取到昨天日志文件的名称
- 第二步:在HDFS上面使用昨天的日期创建目录
- 第三步:将昨天的日志文件上传到刚创建的HDFS目录中
- 第四步:要考虑到脚本重跑,补数据的情况
- 第五步:配置crontab任务
开始开发shell脚本,脚本内容如下:
[root@bigdata01 ~]# mkdir -p /data/shell
[root@bigdata01 ~]# cd /data/shell
[root@bigdata01 shell]# vi uploadLogData.sh
#!/bin/bash
# 获取昨天日期字符串
yesterday=$1
if [ "$yesterday" = "" ]
then
yesterday=`date +%Y_%m_%d --date="1 days ago"`
fi
# 拼接日志文件路径信息
logPath=/data/log/access_${yesterday}.log
# 将日期字符串中的_去掉
hdfsPath=/log/${yesterday//_/}
# 在hdfs上创建目录
hdfs dfs -mkdir -p ${hdfsPath}
# 将数据上传到hdfs的指定目录中
hdfs dfs -put ${logPath} ${hdfsPath}
生成测试数据,注意,文件名称中的日期根据昨天的日期命名
[root@bigdata01 shell]# mkdir -p /data/log
[root@bigdata01 shell]# cd /data/log
[root@bigdata01 log]# vi access_2020_04_08.log
log1
执行脚本
[root@bigdata01 log]# cd /data/shell/
[root@bigdata01 shell]# sh -x uploadLogData.sh
+ yesterday=
+ '[' '' = '' ']'
++ date +%Y_%m_%d '--date=1 days ago'
+ yesterday=2020_04_08
+ logPath=/data/log/access_2020_04_08.log
+ hdfsPath=/log/20200408
+ hdfs dfs -mkdir -p /log/20200408
+ hdfs dfs -put /data/log/access_2020_04_08.log /log/20200408
[root@bigdata01 shell]# hdfs dfs -ls /log/20200408
Found 1 items
-rw-r--r-- 2 root supergroup 15 2020-04-09 16:05 /log/20200408/acce
注意:如果想要指定日期上传数据,可以通过在脚本后面传递参数实现
这样后期如果遇到某天的数据漏传了,或者需要重新上传,就可以通过手工指定日期实现上传操作,在实际工作中这种操作是不可避免的,所以我们在开发脚本的时候就直接考虑好补数据的情况,别等需要用的时候了再去增加这个功能。
最后配置crontab定时任务,每天凌晨1点执行
[root@bigdata01 shell]# vi /etc/crontab
0 1 * * * root sh /data/shell/uploadLogData.sh >> /data/shell/uploadLogData.log
HDFS的高可用和高扩展
NameNode负责接收用户的操作请求,所有的读写请求都会经过它,如果它挂了怎么办?
这个时候集群是不是就无法正常提供服务了?是的,那现在我们这个集群就太不稳定了,因为NameNode只有一个,是存在单点故障的,咱们在现实生活中,例如,县长,是有正的和副的,这样就是为了解决当正县长遇到出差的时候,副县长可以顶上去。
所以在HDFS的设计中,NameNode也是可以支持多个的,一个主的 多个备用的,,当主的挂掉了,备用的可以顶上去,这样就可以解决NameNode节点宕机导致的单点故障问题了,也就实现了HDFS的高可用。
还有一个问题是,前面我们说了NameNode节点的内存是有限的,只能存储有限的文件个数,那使用一个主NameNode,多个备用的NameNode能解决这个问题吗? 不能!
一个主NameNode,多个备用的NameNode的方案只能解决NameNode的单点故障问题,无法解决单个NameNode内存不够用的问题,那怎么办呢?不用担心,官方提供了Federation机制,可以翻译为联邦,它可以解决单节点内存不够用的情况,具体实现思路我们稍后分析,这个就是HDFS的高扩展
HDFS的高可用(HA)
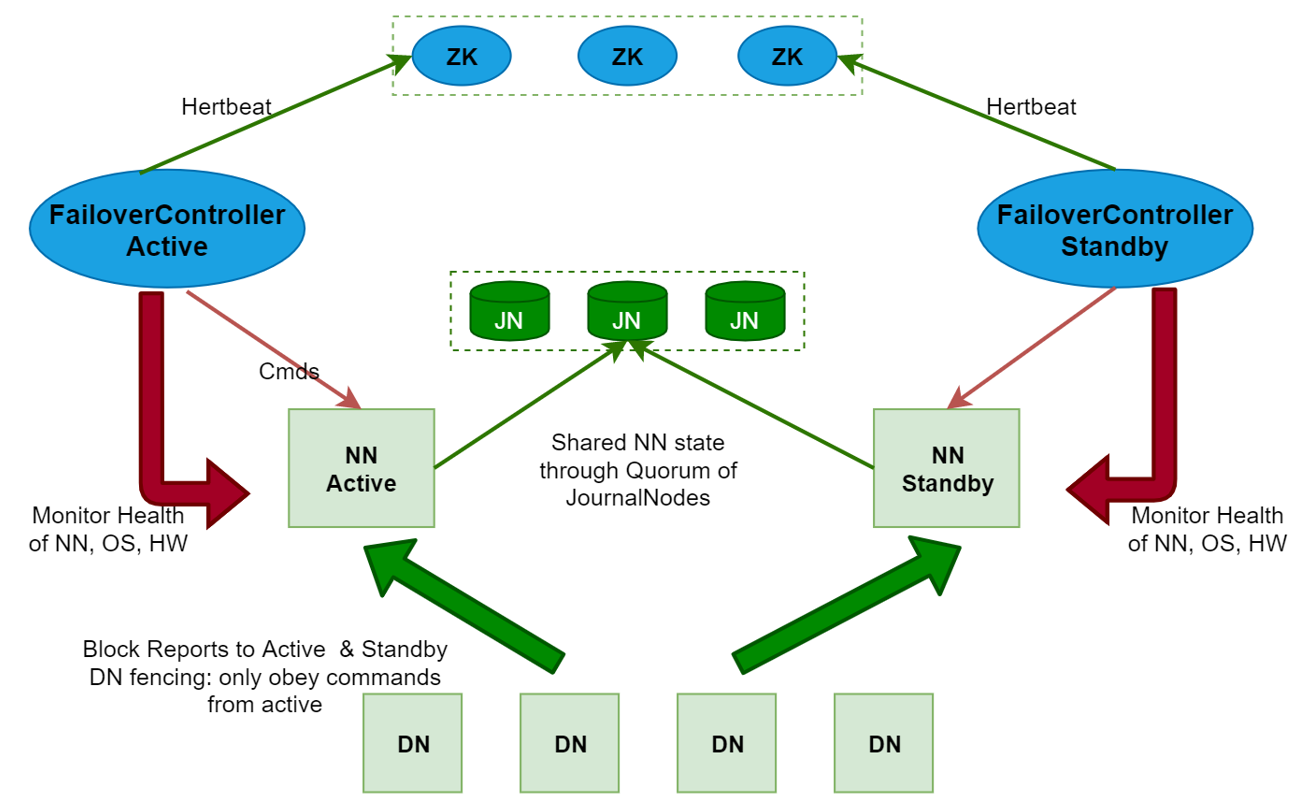
-
HDFS的HA,指的是在一个集群中存在多个NameNode,分别运行在独立的物理节点上。在任何时间点,只有一个NameNode是处于Active状态,其它的是处于Standby状态。 Active NameNode(简写为Active NN)负责所有的客户端的操作,而Standby NameNode(简写为Standby NN)用来同步ActiveNameNode的状态信息,以提供快速的故障恢复能力。
-
为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向这些NameNode发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”(简写为JN),用来同步Edits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JNs上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的Edits信息,并更新自己内部的命名空间。一旦Active NN遇到错误,Standby NN需要保证从JNs中读出了全部的Edits,然后切换成Active状态,如果有多个Standby NN,还会涉及到选主的操作,选择一个切换为Active 状态。
需要注意一点,为了保证Active NN与Standby NN节点状态同步,即元数据保持一致
这里的元数据包含两块,一个是静态的,一个是动态的
- 静态的是fsimage和edits,其实fsimage是由edits文件合并生成的,所以只需要保证edits文件内容的一致性。这个就是需要保证多个NameNode中edits文件内容的事务性同步。这块的工作是由JournalNodes集群进行同步的
- 动态数据是指block和DataNode节点的信息,这个如何保证呢?当DataNode启动的时候,上报数据信息的时候需要向每个NameNode都上报一份。这样就可以保证多个NameNode的元数据信息都一样了,当一个NameNode down掉以后,立刻从Standby NN中选择一个进行接管,没有影响,因为每个NameNode 的元数据时刻都是同步的。
注意:使用HA的时候,不能启动SecondaryNameNode,会出错。
之前是SecondaryNameNode负责合并edits到fsimage文件 那么现在这个工作被standby NN负责了。
NameNode 切换可以自动切换,也可以手工切换,如果想要实现自动切换,需要使用到zookeeper集群。
使用zookeeper集群自动切换的原理是这样的:当多个NameNode 启动的时候会向zookeeper中注册一个临时节点,当NameNode挂掉的时候,这个临时节点也就消失了,这属于zookeeper的特性,这个时候,zookeeper就会有一个watcher监视器监视到,就知道这个节点down掉了,然后会选择一个节点转为Active,把down掉的节点转为Standby。注意:下面的配置步骤建议大家有空闲时间了再来操作就行,作为一个课外扩展,因为在工作中这个配置是不需要我们做的,我们只需要知道这种特性即可
HDFS的高扩展(Federation)
HDFS Federation可以解决单一命名空间存在的问题,使用多个NameNode,每个NameNode负责一个命令空间
这种设计可提供以下特性:
1:HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再因内存的限制制约文件存储数目。
2:性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
3:良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
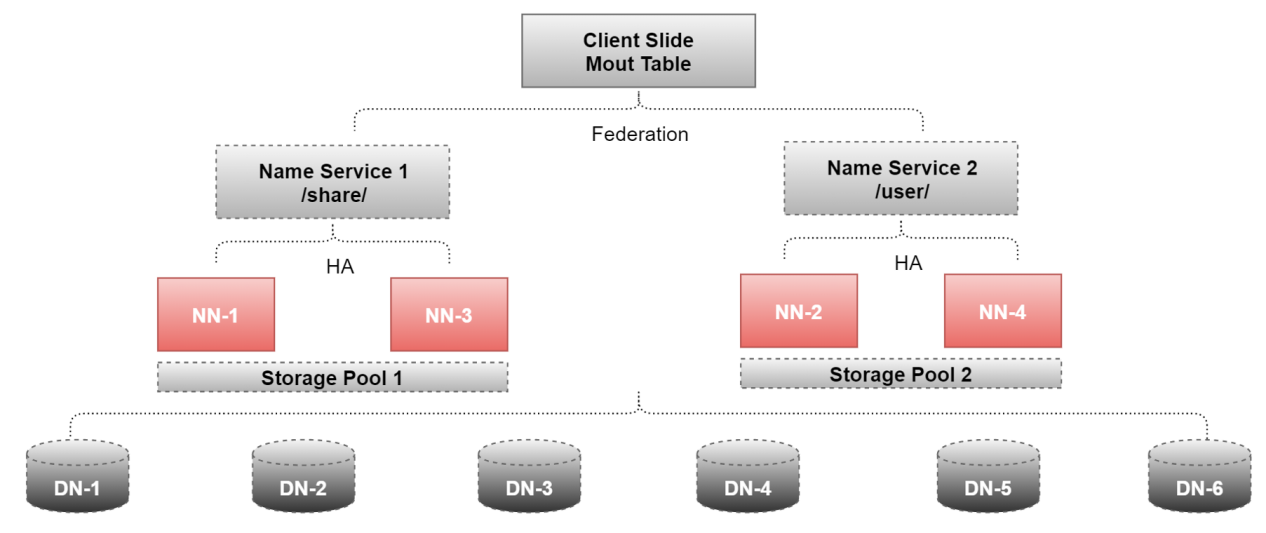
这里面用到了4个NameNode和6个DataNode
NN-1、NN-2、NN-3、NN-4
DN-1、DN-2、DN-3、DN-4、DN-5、DN-6、
其中NN-1、和NN-3配置了HA,提供了一个命令空间,/share,其实可理解为一个顶级目录
NN-2和NN-4配置了HA,提供了一个命名空间,/user
这样后期我们存储数据的时候,就可以根据数据的业务类型来区分是存储到share目录下还是user目录下,此时HDFS的存储能力就是/share和/user两个命名空间的总和了。
注意:由于Federation+HA需要的机器比较多,大家本地的机器开不了那么多虚拟机,所以暂时在这就不再提供对应的安装步骤了,大家主要能理解它的原理就可以了,在工作中也不需要我们去配置。