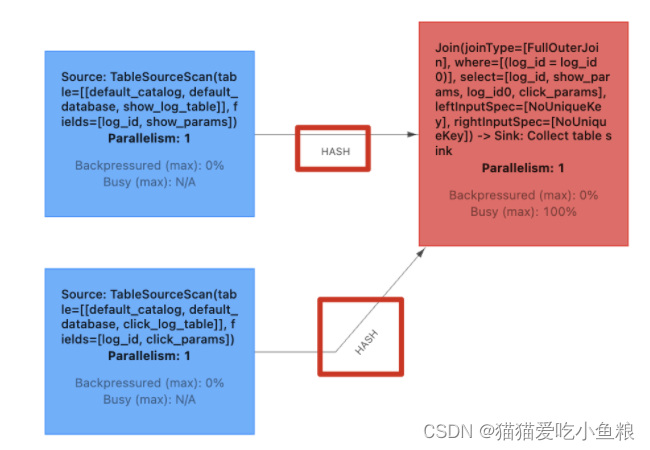
Flink ⽀持⾮常多的数据 Join ⽅式,主要包括以下三种:
- 动态表(流)与动态表(流)的 Join
- 动态表(流)与外部维表(⽐如 Redis)的 Join
- 动态表字段的列转⾏(⼀种特殊的 Join)
细分 Flink SQL ⽀持的 Join:
Regular Join:流与流的 Join,包括 Inner Equal Join、Outer Equal Join
Interval Join:流与流的 Join,两条流⼀段时间区间内的 Join
Temporal Join:流与流的 Join,包括事件时间,处理时间的 Temporal Join,类似于离线中的快照 Join
Lookup Join:流与外部维表的 Join
Array Expansion:表字段的列转⾏,类似于 Hive 的 explode 数据炸开的列转⾏
Table Function:⾃定义函数的表字段的列转⾏,⽀持 Inner Join 和 Left Outer Join
1.Regular Join
**Regular Join 定义(⽀持 Batch\Streaming):**Regular Join 和离线 Hive SQL ⼀样的 Regular Join,通过条件关联两条流数据输出。
**应⽤场景:**⽐如⽇志关联扩充维度数据,构建宽表;⽇志通过 ID 关联计算 CTR。
Regular Join 包含以下⼏种(以 L 作为左流中的数据标识, R 作为右流中的数据标识):
- Inner Join(Inner Equal Join):流任务中,只有两条流 Join 到才输出,输出 +[L, R]
- Left Join(Outer Equal Join):流任务中,左流数据到达之后,⽆论有没有 Join 到右流的数据,都会输出(Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] ),如果右流数据到达之后,发现左流之前输出过没有 Join 到的数据,则会发起回撤流,先输出 -[L, null] ,然后输出 +[L, R]
- Right Join(Outer Equal Join):有 Left Join ⼀样,左表和右表的执⾏逻辑完全相反
- Full Join(Outer Equal Join):流任务中,左流或者右流的数据到达之后,⽆论有没有 Join 到另外⼀条流的数据,都会输出(对右流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[null, R] ;对左流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] )。如果⼀条流的数据到达之后,发现另⼀条流之前输出过没有 Join 到的数据,则会发起回撤流(左流数据到达为例:回撤 -[null, R] ,输出+[L, R] ,右流数据到达为例:回撤 -[L, null] ,输出 +[L, R] )
**实际案例:**案例为曝光⽇志关联点击⽇志,筛选既有曝光⼜有点击的数据,并且补充点击的扩展参数
a)Inner Join 案例 :
-- 曝光⽇志数据
CREATE TABLE show_log_table (
log_id BIGINT,
show_params STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '2',
'fields.show_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '100'
);
-- 点击⽇志数据
CREATE TABLE click_log_table (
log_id BIGINT,
click_params STRING
)
WITH (
'connector' = 'datagen',
'rows-per-second' = '2',
'fields.click_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE sink_table (
s_id BIGINT,
s_params STRING,
c_id BIGINT,
c_params STRING
) WITH (
'connector' = 'print'
);
-- 流的 INNER JOIN,条件为 log_id
INSERT INTO sink_table
SELECT
show_log_table.log_id as s_id,
show_log_table.show_params as s_params,
click_log_table.log_id as c_id,
click_log_table.click_params as c_params
FROM show_log_table
INNER JOIN click_log_table
ON show_log_table.log_id = click_log_table.log_id;
输出结果如下:
+I[5, d, 5, f]
+I[5, d, 5, 8]
+I[5, d, 5, 2]
+I[3, 4, 3, 0]
+I[3, 4, 3, 3]
b)Left Join 案例:
CREATE TABLE show_log_table (
log_id BIGINT,
show_params STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.show_params.length' = '3',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE click_log_table (
log_id BIGINT,
click_params STRING
)
WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.click_params.length' = '3',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE sink_table (
s_id BIGINT,
s_params STRING,
c_id BIGINT,
c_params STRING
) WITH (
'connector' = 'print'
);
set sql-client.execution.result-mode=changelog;
INSERT INTO sink_table
SELECT
show_log_table.log_id as s_id,
show_log_table.show_params as s_params,
click_log_table.log_id as c_id,
click_log_table.click_params as c_params
FROM show_log_table
LEFT JOIN click_log_table
ON show_log_table.log_id = click_log_table.log_id;
输出结果如下:
+I[5, f3c, 5, c05]
+I[5, 6e2, 5, 1f6]
+I[5, 86b, 5, 1f6]
+I[5, f3c, 5, 1f6]
-D[3, 4ab, null, null]
-D[3, 6f2, null, null]
+I[3, 4ab, 3, 765]
+I[3, 6f2, 3, 765]
+I[2, 3c4, null, null]
+I[3, 4ab, 3, a8b]
+I[3, 6f2, 3, a8b]
+I[2, c03, null, null]
...
c)Full Join 案例:
CREATE TABLE show_log_table (
log_id BIGINT,
show_params STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '2',
'fields.show_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE click_log_table (
log_id BIGINT,
click_params STRING
)WITH (
'connector' = 'datagen',
'rows-per-second' = '2',
'fields.click_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE sink_table (
s_id BIGINT,
s_params STRING,
c_id BIGINT,
c_params STRING
) WITH (
'connector' = 'print'
);
INSERT INTO sink_table
SELECT
show_log_table.log_id as s_id,
show_log_table.show_params as s_params,
click_log_table.log_id as c_id,
click_log_table.click_params as c_params
FROM show_log_table
FULL JOIN click_log_table
ON show_log_table.log_id = click_log_table.log_id;
输出结果如下:
+I[null, null, 7, 6]
+I[6, 5, null, null]
-D[1, c, null, null]
+I[1, c, 1, 2]
+I[3, 1, null, null]
+I[null, null, 7, d]
+I[10, 0, null, null]
+I[null, null, 2, 6]
-D[null, null, 7, 6]
-D[null, null, 7, d]
...
关于 Regular Join 的注意事项:
-
实时 Regular Join 可以不是 等值 join,等值 join 和 ⾮等值 join 区别在于,等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游; ⾮等值 join 数据 shuffle 策略是 Global,所有数据发往⼀个并发,按照⾮等值条件进⾏关联。
等值 Join:
非等值 Join:
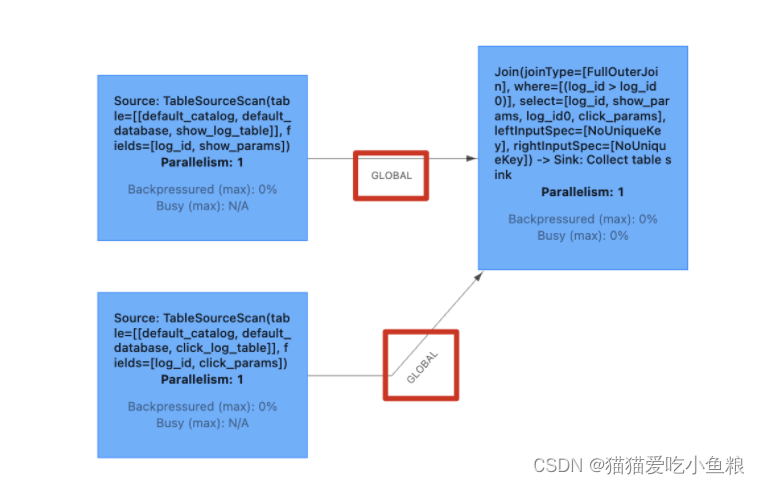
-
Join 的流程是左流新来⼀条数据之后,会和右流中符合条件的所有数据做 Join,然后输出。
-
流的上游是⽆限的数据,要做到关联的话,Flink 会将两条流的所有数据都存储在 State 中,所以 Flink 任务的 State 会⽆限增⼤,需要为 State 配置合适的 TTL,以防⽌ State 过⼤。
2.Interval Join(时间区间 Join)
**Interval Join 定义(⽀持 Batch\Streaming):**Interval Join 可以让⼀条流去 Join 另⼀条流中前后⼀段时间内的数据。
**应⽤场景:**Regular Join 会产⽣回撤流,在实时数仓中⼀般写⼊的 sink 是类似于 Kafka 的消息队列,然后接 clickhouse 等引擎,这些引擎不具备处理回撤流的能⼒,Interval Join ⽤于消灭回撤流的。
Interval Join 包含以下⼏种(以 L 作为左流中的数据标识, R 作为右流中的数据标识):
- Inner Interval Join:流任务中,只有两条流 Join 到(满⾜ Join on 中的条件:两条流的数据在时间区间 + 满⾜其他等值条件)才输出,输出 +[L, R]
- Left Interval Join:流任务中,左流数据到达之后,如果没有 Join 到右流的数据,就会等待(放在 State 中等),如果右流之后数据到达,发现能和刚刚那条左流数据 Join 到,则会输出 +[L,R] 。事件时间中随着 Watermark 的推进(也⽀持处理时间)。如果发现发现左流 State 中的数据过期了,就把左流中过期的数据从 State 中删除,然后输出 +[L, null] ,如果右流 State 中的数据过期了,就直接从 State 中删除。
- Right Interval Join:和 Left Interval Join 执⾏逻辑⼀样,只不过左表和右表的执⾏逻辑完全相反。
- Full Interval Join:流任务中,左流或者右流的数据到达之后,如果没有 Join 到另外⼀条流的数据,就会等待(左流放在左流对应的 State 中等,右流放在右流对应的 State 中等),如果之后另⼀条流数据到达之后,发现能和刚刚那条数据 Join 到,则会输出 +[L, R] 。事件时间中随着 Watermark 的推进(也⽀持处理时间),发现 State 中的数据过期了,就将这些数据从 State 中删除并且输出(左流过期输出+[L, null] ,右流过期输出 -[null, R] )
**Inner Interval Join 和 Outer Interval Join 的区别在于:**Outer 在随着时间推移的过程中,如果有数据过期了之后,会根据是否是 Outer 将没有 Join 到的数据也给输出。
**实际案例:**曝光⽇志关联点击⽇志,筛选既有曝光⼜有点击的数据,条件是曝光发⽣之后,4 ⼩时之内的点击,并且补充点击的扩展参数
a)Inner Interval Join
CREATE TABLE show_log_table (
log_id BIGINT,
show_params STRING,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.show_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE click_log_table (
log_id BIGINT,
click_params STRING,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time
)
WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.click_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE sink_table (
s_id BIGINT,
s_params STRING,
c_id BIGINT,
c_params STRING
) WITH (
'connector' = 'print'
);
INSERT INTO sink_table
SELECT
show_log_table.log_id as s_id,
show_log_table.show_params as s_params,
click_log_table.log_id as c_id,
click_log_table.click_params as c_params
FROM show_log_table
INNER JOIN click_log_table
ON show_log_table.log_id = click_log_table.log_id
AND show_log_table.row_time BETWEEN click_log_table.row_time - INTERVAL '4' SECOND AND click_log_table.row_time
输出结果如下:
6> +I[2, a, 2, 6]
6> +I[2, 6, 2, 6]
2> +I[4, 1, 4, 5]
2> +I[10, 8, 10, d]
2> +I[10, 7, 10, d]
2> +I[10, d, 10, d]
2> +I[5, b, 5, d]
6> +I[1, a, 1, 7]
b)Left Interval Join
CREATE TABLE show_log (
log_id BIGINT,
show_params STRING,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.show_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE click_log (
log_id BIGINT,
click_params STRING,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time
)
WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.click_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE sink_table (
s_id BIGINT,
s_params STRING,
c_id BIGINT,
c_params STRING
) WITH (
'connector' = 'print'
);
INSERT INTO sink_table
SELECT
show_log.log_id as s_id,
show_log.show_params as s_params,
click_log.log_id as c_id,
click_log.click_params as c_params
FROM show_log LEFT JOIN click_log ON show_log.log_id = click_log.log_id
AND show_log.row_time BETWEEN click_log.row_time - INTERVAL '5' SECOND AND click_log.row_time
输出结果如下:
+I[6, e, 6, 7]
+I[11, d, null, null]
+I[7, b, null, null]
+I[8, 0, 8, 3]
+I[13, 6, null, null]
c)Full Interval Join
CREATE TABLE show_log (
log_id BIGINT,
show_params STRING,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.show_params.length' = '1',
'fields.log_id.min' = '5',
'fields.log_id.max' = '15'
);
CREATE TABLE click_log (
log_id BIGINT,
click_params STRING,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time
)
WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.click_params.length' = '1',
'fields.log_id.min' = '1',
'fields.log_id.max' = '10'
);
CREATE TABLE sink_table (
s_id BIGINT,
s_params STRING,
c_id BIGINT,
c_params STRING
) WITH (
'connector' = 'print'
);
INSERT INTO sink_table
SELECT
show_log.log_id as s_id,
show_log.show_params as s_params,
click_log.log_id as c_id,
click_log.click_params as c_params
FROM show_log FULL JOIN click_log ON show_log.log_id = click_log.log_id
AND show_log.row_time BETWEEN click_log.row_time - INTERVAL '5' SECOND AND click_log.row_time
输出结果如下:
+I[6, 1, null, null]
+I[7, 3, 7, 8]
+I[null, null, 6, 6]
+I[null, null, 4, d]
+I[8, d, null, null]
+I[null, null, 3, b]
关于 Interval Join 的注意事项:
实时 Interval Join 可以不是 等值 join ,等值 join 和 ⾮等值 join 区别在于, 等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游; ⾮等值 join 数据 shuffle 策略是 Global,所有数据发往⼀个并发,将满⾜条件的数据进⾏关联输出。
3.Temporal Join(快照 Join)
**Temporal Join 定义(⽀持 Batch\Streaming):**同离线中的 拉链快照表 ,Flink SQL 中对应的表叫做 Versioned Table ,使⽤⼀个明细表去 join 这个 Versioned Table 的 join 操作就叫做 Temporal Join。
Temporal Join 中,Versioned Table 是对同⼀条 key(在 DDL 中以 primary key 标记同⼀个 key)的历史版本(根据时间划分版本)做维护,当有明细表 Join 这个表时,可以根据明细表中的时间版本选择 Versioned Table 对应时间区间内的快照数据进⾏ join。
**应⽤场景:**⽐如汇率数据(实时的根据汇率计算总⾦额),在 12:00 之前(事件时间),⼈⺠币和美元汇率是 7:1,在 12:00 之后变为 6:1,那么在 12:00 之前数据就要按照 7:1 进⾏计算,12:00 之后就要按照 6:1 计算。
**Verisoned Table:**Verisoned Table 中存储的数据通常来源于 CDC 或者会发⽣更新的数据。Flink SQL 会为 Versioned Table 维护 Primary Key 下的所有历史时间版本的数据。
**示例:**汇率计算中定义 Versioned Table 的两种⽅式。
-- 定义⼀个汇率 versioned 表
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3) METADATA FROM `values.source.timestamp` VIRTUAL,
WATERMARK FOR update_time AS update_time,
-- PRIMARY KEY 定义⽅式
PRIMARY KEY(currency) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'value.format' = 'debezium-json',
/* ... */
);
-- 将数据源表按照 Deduplicate ⽅式定义为 Versioned Table
CREATE VIEW versioned_rates AS
SELECT currency, conversion_rate, update_time -- 1. 定义 `update_time` 为时间字段
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY currency -- 2. 定义 `currency` 为主键
ORDER BY update_time DESC -- 3. ORDER BY 中必须是时间戳列
) AS rownum
FROM currency_rates)
WHERE rownum = 1;
**Temporal Join ⽀持的时间语义:**事件时间、处理时间
**实际案例:**汇率计算以 事件时间 任务举例
-- 1. 定义⼀个输⼊订单表
CREATE TABLE orders (
order_id BIGINT,
price BIGINT,
currency STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time
) WITH (
'connector' = 'filesystem',
'path' = 'file:///Users/hhx/Desktop/orders.csv',
'format' = 'csv'
);
1,100,a,2023-11-01 10:10:10.100
2,200,a,2023-11-02 10:10:10.100
3,300,a,2023-11-03 10:10:10.100
4,300,a,2023-11-04 10:10:10.100
5,300,a,2023-11-05 10:10:10.100
6,300,a,2023-11-06 10:10:10.100
-- 2. 定义⼀个汇率 versioned 表,其中 versioned 表的概念下⽂会介绍到
CREATE TABLE currency_rates (
currency STRING,
conversion_rate BIGINT,
update_time TIMESTAMP(3),
WATERMARK FOR update_time AS update_time,
PRIMARY KEY(currency) NOT ENFORCED
) WITH (
'connector' = 'filesystem',
'path' = 'file:///Users/hhx/Desktop/currency_rates.csv',
'format' = 'csv'
);
a,10,2023-11-01 09:10:10.100
a,11,2023-11-01 10:00:10.100
a,12,2023-11-01 10:10:10.100
a,13,2023-11-01 10:20:10.100
a,14,2023-11-02 10:20:10.100
a,15,2023-11-03 10:20:10.100
a,16,2023-11-04 10:20:10.100
a,17,2023-11-05 10:20:10.100
a,18,2023-11-06 10:00:10.100
a,19,2023-11-06 10:11:10.100
SELECT
order_id,
price,
orders.currency,
conversion_rate,
order_time,
update_time
FROM orders
-- 3. Temporal Join 逻辑
-- SQL 语法为:FOR SYSTEM_TIME AS OF
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;
可以看到相同的货币汇率会根据具体数据的事件时间不同, Join 到对应时间的汇率【Join 到最近可用的汇率】:

注意:
事件时间的 Temporal Join ⼀定要给左右两张表都设置 Watermark。
事件时间的 Temporal Join ⼀定要把 Versioned Table 的主键包含在 Join on 的条件中。
**实际案例:**汇率计算以 处理时间 任务举例
10:15> SELECT * FROM LatestRates;
currency rate
======== ======
US Dollar 102
Euro 114
Yen 1
10:30> SELECT * FROM LatestRates;
currency rate
======== ======
US Dollar 102
Euro 114
Yen 1
-- 10:42 时,Euro 的汇率从 114 变为 116
10:52> SELECT * FROM LatestRates;
currency rate
======== ======
US Dollar 102
Euro 116
Yen 1
-- 从 Orders 表查询数据
SELECT * FROM Orders;
amount currency
====== =========
2 Euro <== 在处理时间 10:15 到达的⼀条数据
1 US Dollar <== 在处理时间 10:30 到达的⼀条数据
2 Euro <== 在处理时间 10:52 到达的⼀条数据
-- 执⾏关联查询
SELECT
o.amount,
o.currency,
r.rate,
o.amount * r.rate
FROM
Orders AS o
JOIN LatestRates FOR SYSTEM_TIME AS OF o.proctime AS r
ON r.currency = o.currency
-- 结果如下:
amount currency rate amount*rate
====== ========= ======= ============
2 Euro 114 228 <== 在处理时间 10:15 到达的⼀条数据
1 US Dollar 102 102 <== 在处理时间 10:30 到达的⼀条数据
2 Euro 116 232 <== 在处理时间 10:52 到达的⼀条数据
处理时间语义中是根据左流数据到达的时间决定拿到的汇率值,Flink 就只为 LatestRates 维护了最新的状态数据,不需要关⼼历史版本的数据。
注意:
Processing-time temporal join is not supported yet.
4.Lookup Join(维表 Join)
**Lookup Join 定义(⽀持 Batch\Streaming):**Lookup Join 是维表 Join,实时数仓场景中,实时获取外部缓存。
**应⽤场景:**Regular Join,Interval Join 等上⾯说的 Join 都是流与流之间的 Join,⽽ Lookup Join 是流与 Redis,Mysql,HBase 这种存储介质的 Join,Lookup 的意思是实时查找。
**实际案例:**使⽤曝光⽤户⽇志流(show_log)关联⽤户画像维表(user_profile)关联到⽤户的维度之后,提供给下游,计算分性别,年龄段的曝光⽤户数使⽤。
输⼊数据: 曝光⽤户⽇志流(show_log)数据(数据存储在 kafka 中):
log_id timestamp user_id
1 2021-11-01 00:01:03 a
2 2021-11-01 00:03:00 b
3 2021-11-01 00:05:00 c
4 2021-11-01 00:06:00 b
5 2021-11-01 00:07:00 c
⽤户画像维表(user_profile)数据(数据存储在 redis 中)
user_id(主键) age sex
a 12-18 男
b 18-24 ⼥
c 18-24 男
**注意:**redis 中的数据结构是按照 key,value 存储的,其中 key 为 user_id,value 为 age,sex 的 json。
CREATE TABLE show_log (
log_id BIGINT,
`timestamp` TIMESTAMP(3),
user_id STRING,
proctime AS PROCTIME()
) WITH (
'connector' = 'filesystem',
'path' = 'file:///Users/hhx/Desktop/show_log.csv',
'format' = 'csv'
);
1 2021-11-01 00:01:03 a
2 2021-11-01 00:03:00 b
3 2021-11-01 00:05:00 c
4 2021-11-01 00:06:00 b
5 2021-11-01 00:07:00 c
CREATE TABLE user_profile (
user_id STRING,
age STRING,
sex STRING,
proctime AS PROCTIME(),
PRIMARY KEY(user_id) NOT ENFORCED
) WITH (
'connector' = 'filesystem',
'path' = 'file:///Users/hhx/Desktop/currency_rates.csv',
'format' = 'csv'
);
a 12-18 男
b 18-24 ⼥
c 18-24 男
CREATE TABLE sink_table (
log_id BIGINT,
`timestamp` TIMESTAMP(3),
user_id STRING,
proctime TIMESTAMP(3),
age STRING,
sex STRING
) WITH (
'connector' = 'print'
);
-- Processing-time temporal join is not supported yet.
-- lookup join 的 query 逻辑
INSERT INTO sink_table
SELECT
s.log_id as log_id
, s.`timestamp` as `timestamp`
, s.user_id as user_id
, s.proctime as proctime
, u.sex as sex
, u.age as age
FROM show_log AS s
LEFT JOIN user_profile FOR SYSTEM_TIME AS OF s.proctime AS u
ON s.user_id = u.user_id
输出数据如下:
log_id timestamp user_id age sex
1 2021-11-01 00:01:03 a 12-18 男
2 2021-11-01 00:03:00 b 18-24 ⼥
3 2021-11-01 00:05:00 c 18-24 男
4 2021-11-01 00:06:00 b 18-24 ⼥
5 2021-11-01 00:07:00 c 18-24 男
实时的 lookup 维表关联能使⽤ 处理时间 去做关联。
注意:
a)同⼀条数据关联到的维度数据可能不同
实时数仓中常⽤的实时维表是不断变化的,当前流表数据关联完维表数据后,如果同⼀个 key 的维表的数据发⽣了变化,已关联到的维表的结果数据不会再同步更新。
举个例⼦,维表中 user_id 为 1 的数据在 08:00 时 age 由 12-18 变为了 18-24,那么当任务在 08:01 failover 之后从 07:59 开始回溯数据时,原本应该关联到 12-18 的数据会关联到 18-24 的 age 数据,有可能会影响数据质量。
b)会发⽣实时的新建及更新的维表应该建⽴起数据延迟的监控,防⽌流表数据先于维表数据到达,关联不到维表数据
c)维表常⻅的性能问题及优化思路
维表性能问题: ⾼ qps 下访问维表存储引擎产⽣的任务背压,数据产出延迟问题。
举个例⼦:
**在没有使⽤维表的情况下:**⼀条数据从输⼊ Flink 任务到输出 Flink 任务的时延假如为 0.1 ms ,那么并⾏度为 1 的任务的吞吐可以达到 1 query / 0.1 ms = 1w qps 。
**在使⽤维表之后:**每条数据访问维表的外部存储的时⻓为 2 ms ,那么⼀条数据从输⼊ Flink 任务到输出 Flink 任务的时延就会变成 2.1 ms ,那么同样并⾏度为 1 的任务的吞吐只能达到 1 query / 2.1 ms = 476 qps ,两者的吞吐量相差 21 倍,导致维表 join 的算⼦会产⽣背压,任务产出会延迟。
常⽤的优化⽅案-DataStream:
- **按照 redis 维表的 key 分桶 + local cache:**通过按照 key 分桶的⽅式,让⼤多数据的维表关联的数据访问⾛之前访问过得 local cache 即可,把访问外部存储 2.1 ms 处理⼀个 query 变为访问内存的 0.1 ms 处理⼀个 query 的时⻓。
- **异步访问外存:**DataStream api 有异步算⼦,可以利⽤线程池去同时多次请求维表外部存储,把 2.1 ms 处理 1 个 query 变为 2.1 ms 处理 10 个 query,吞吐可变优化到 10 / 2.1 ms = 4761 qps。
- **批量访问外存:**除了异步访问之外,还可以批量访问外部存储,举例:在访问 redis 维表的 1 query 占⽤ 2.1 ms 时⻓中,其中可能有 2 ms 都是在⽹络请求上⾯的耗时 ,其中只有 0.1 ms 是 redis server 处理请求的时⻓,可以使⽤ redis 提供的 pipeline 能⼒,在客户端(也就是 flink 任务 lookup join 算⼦中),攒⼀批数据,使⽤ pipeline 去同时访问 redis sever,把 2.1 ms 处理 1 个 query 变为 7ms(2ms + 50 * 0.1ms) 处理 50 个 query,吞吐可变为 50 query / 7 ms = 7143 qps。
**实测:**上述优化效果中,最好⽤的是 1 + 3,2 相⽐ 3 还是⼀条⼀条发请求,性能会差⼀些。
常⽤的优化⽅案-Flink SQL:
**按照 redis 维表的 key 分桶 + local cache:**sql 中做分桶,得先做 group by,如果做了 group by 的聚合,就只能在 udaf 中做访问 redis 处理,并且 UDAF 产出的结果只能是⼀条,实现复杂,因此选择不做 keyby 分桶,直接使⽤ local cache 做本地缓存,虽然【直接缓存】的效果⽐【先按照 key 分桶再做缓存】的效果差,但是也能减少访问 redis 压⼒。
**异步访问外存:**官⽅实现的 hbase connector ⽀持异步访问,搜索 lookup.async。
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/hbase/
**批量访问外存:**基于 redis 的批量访问外存优化功能,参考下⽂。
https://mp.weixin.qq.com/s/ku11tCZp7CAFzpkqd4J1cQ
5.Regular Join 、Interval Join、Temporal Join、Lookup Join 总结
a)FlinkSQL 的 Join 按照流的性质分为
- 流与流的 Join:Regular Join+Interval Join+Temporal Join
- 流于外部存储的 Join:Lookup Join
b)Inner Join 与 Outer Join 区别
Inner Join:只有两条流 Join 上才会发出,不涉及回撤流
Outer Join:Join 不上会发出 null,如果是 Regular Outer Join 涉及回撤流,Interval Outer Join 不涉及回撤流
c)Regular Join 、Interval Join、Temporal Join 区别
Regular Join:如果不设置状态的 TTL,两条流的所有数据都会暂存进行 Join,涉及回撤流
Interval Join:可以选定 一条流 的 指定时间区间内 的 数据 进行 Join,不涉及回撤流
Temporal Join:根据 一条流的时间字段 选择 另一条流的历史时间区间 进行 Join,不涉及回撤流