Geometric Features Informed Multi-person Human-object Interaction Recognition in Videos解读
- 摘要
- 简介
- 2. Related Work
- 2.1 图像中的HOI检测
- 2.2 视频中的HOI识别
- 2.3 HOI识别数据集
- 2.4 几何特征为HOI分析提供信息
- 3. 多人HOI数据集(MPHOI-72)
- 4. Two-level Geometric Features Informed Graph Convolutional Network (2G-GCN)
- 4.1 几何特征
- 4.2 Geometric-level Graph
- 4.3 Fusion-Level Graph
- 5. 实验
- 5.1 数据集
- 5.2 实现细节
- 5.3 定量比较
- Multi-person HOIs
- Single-person HOIs
- Two-hand HOIs
- 5.4 定性比较
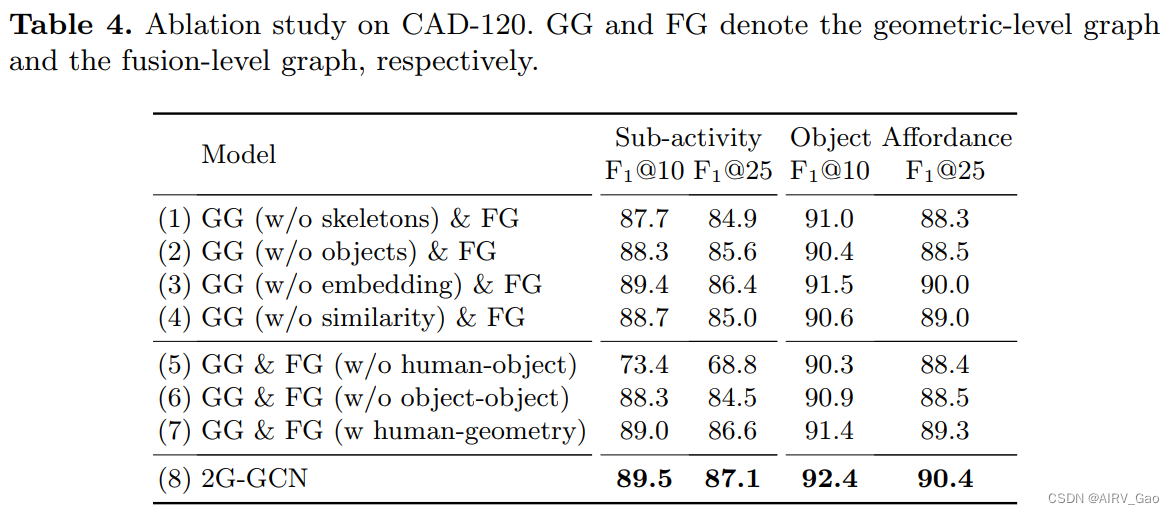
- 5.5 烧蚀研究
论文地址:https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136640467.pdf
论文代码:https://github.com/tanqiu98/2G-GCN
论文出处:2022ECCV
论文单位:Durham University, UK
摘要
- 视频中的人-物交互(HOI)识别对于分析人的活动具有重要意义。
- 大多数现有的专注于视觉特征的工作通常在现实场景中受到遮挡的影响。
- 当多个人和多个对象都参与到HOI中时,这个问题会变得更加复杂。
- 考虑到人体姿态和物体位置等几何特征为理解HOI提供了有意义的信息,我们认为将视觉特征和几何特征在HOI识别中结合起来,并提出了一种新的基于两级几何特征的图卷积网络(Two-level
Geometric feature-informed Graph Convolutional Network,2G-GCN)。 - 几何级图(geometric-level graph )对人与物体的几何特征之间的相互依存关系进行建模,而融合级图(fusion-level graph )则将其与人与物体的视觉特征进一步融合。
- 为了证明我们的方法在具有挑战性的场景中的新颖性和有效性,我们提出了一个新的多人HOI数据集(MPHOI-72)。
- 对MPHOI-72(多人HOI), CAD-120(单人HOI)和Bimanual Actions(双手HOI)数据集进行了广泛的实验HOI,展示了我们与SOAT的技术相比的卓越性能。
简介
- 现实世界的人类活动往往与周围的物体密切相关,人-物交互(HOI)识别的重点是学习和分析人与物体实体之间的交互作用,以进行活动识别。
- HOI识别涉及对视频中单个人类子活动/对象可视性(如饮酒和放置)的分割和识别,以获得对整体人类活动的洞察。在此基础上,可以开发诸如安全监控、医疗保健监控和人机交互等下游应用。
- 早期的HOI检测工作仅限于检测一张图像中的相互作用。随着HOI视频数据集的提出,已经开发出模型来学习用于HOI识别的时空域上的动作表示。
- 基于视频的HOI识别的一个
主要挑战是视觉特征通常会受到遮挡。这在涉及多个人和多个对象的现实场景中尤其成问题。 - 最近的研究表明,提取的姿态特征比视觉特征对部分遮挡的鲁棒性更强。
- 自底向上的姿态估计方法可以在关节的局部图像斑块不被遮挡的情况下提取人体姿态。
- 使用**图形卷积网络(GCN)**等高级框架,几何管道通常比视觉管道在严重遮挡的数据集上表现更好。因此,几何特征为视觉特征提供了补充信息。
- 本文提出了一种融合几何特征和视觉特征的视频HOI识别方法。我们的研究观点是,几何特征丰富了细粒度的人-物交互,正如之前基于图像的HOI检测研究所证明的那样。
- 我们提出了一种新的两级几何特征图卷积网络(2G-GCN),该网络提取几何特征并将其与视觉特征融合,用于视频中的HOI识别。
- 我们利用 geometric-level图来建模人与物体之间具有代表性的几何特征,并通过fusion-level图来融合视觉特征,从而实现网络的实现。
- 为了展示我们模型的有效性,我们进一步提出了一个用于人-对象交互(MPHOI)的多人数据集,该数据集紧密集成了包含多人与多个对象交互的现实世界活动。我们的数据集包括日常生活中常见的多人活动和自然遮挡(图1)。
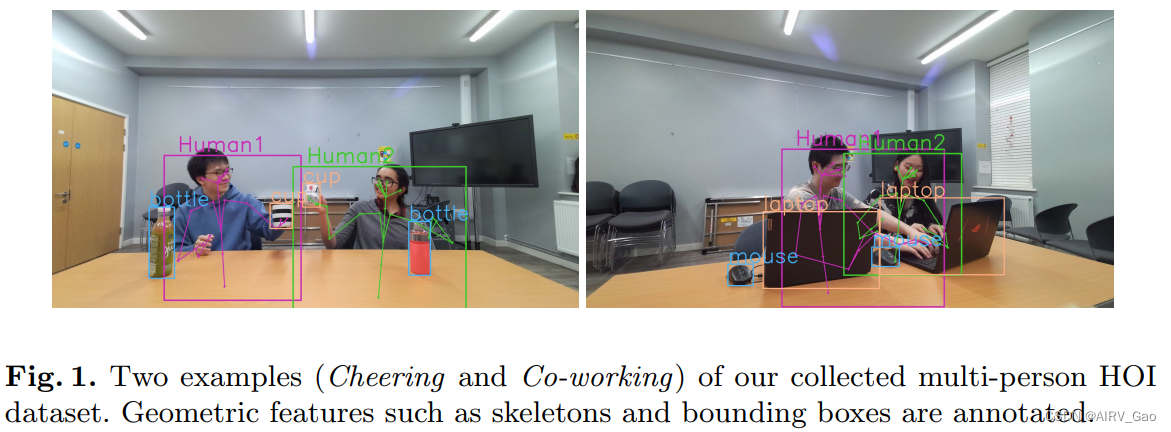
- 它带有人体骨骼姿势的几何特征,人类和物体绑定框以及 ground-truth HOI活动标签的注释,可作为多种任务的通用基准,例如基于视觉或基于骨骼的人类活动分析或混合。
- 我们在多个数据集,包括我们的新颖的MPHOI-72数据集,单人HOI CAD-120数据集,两手的Bimanual Actions数据集上都超越了SOAT方法。
- 我们还在消融研究中广泛评估2G-GCN的核心成分。我们的主要贡献如下:
(1)我们提出了一种新的基于几何信息的2G-GCN网络用于视频中的HOI识别。该网络由一个two-level graph结构组成,该结构模拟人与物体之间的几何特征以及相应的视觉特征。
(2)我们使用新的MPHOI-72数据集在视频中提出了新的MPHOI问题,展示了现有方法无法直接解决的新挑战。源代码和数据集是公开的.
(3)我们在MPHOI-72数据集、CAD-120数据集和bimmanual Actions数据集中优于最先进的HOI识别网络。
2. Related Work
2.1 图像中的HOI检测
- HOI检测旨在了解人与物体之间的相互作用,并在单个图像中识别它们的相互依赖性。这需要识别人类活动以及他们在图像中与之交互的对象实例。
- 近年来提出了多个大规模数据集来探索图像中的HOI检测,如VCOCO、HICO-DET和HCVRD。
- 这些早期的方法侧重于图像中实体之间的视觉关系,而在hoi中没有任何潜在的结构关系。
- 图卷积网络(GCN)可以用来吸收有价值的图结构数据表达式。GCN方法在图像数据中取得了显著的性能,为视频中的HOI识别提供了基础。
2.2 视频中的HOI识别
- 视频中的HOI识别需要高度的人与物体之间的空间和时间推理。
- 一些早期的尝试利用时空背景来实现多背景的HOI识别。最近的研究将图形模型与深度神经网络(DNN)相结合。
- 尽管以前的方法在特定任务中取得了令人印象深刻的改进,但它们都是基于视觉特征,这在现实生活中包含人与物体实体之间遮挡的HOI活动中是不可靠的。
2.3 HOI识别数据集
- 针对不同的任务,可以使用多个数据集来研究视频中的HOI。
- CAD-120、Bimanual Actions、Bimanual Actions等用于单人HOI识别。后两者也提供了bimanual HOI识别任务,因为它们记录了使用双手进行物体交互的人类活动。
- Something-Else, VLOG, EPIC Kitchens 可用于single-handHOI识别任务,其中EPIC Kitchens数据集也可用于bimanual HOI识别,因为它捕获了烹饪过程中的双手。
- UCLA HHOI数据集侧重于人-人-物交互,最多涉及两个人和一个物体。
- 由于真正的多人HOI应该涉及多个人和多个对象,我们提出了一个新的MPHOI数据集,该数据集收集了多个人与多个对象交互的日常活动。
2.4 几何特征为HOI分析提供信息
- 最近的研究开始将人体姿态用于图像中的HOI任务,这利用了捕获人体骨骼结构连接的优势。
- 然而,由于一些原因,将几何特征(如人体姿势和物体的关键点)引入视频中的HOI学习是具有挑战性的,并且尚未得到充分探索。
- 一方面,在视频中,交互的定义可能是模糊的,比如举起杯子vs放置杯子,接近vs撤退vs到达。由于视觉相似性,这些动作可能被检测为相同的图像标签。
- 视频允许使用暂时的视觉线索,这在图像中无法呈现。另一方面,模型需要考虑视频中的人类动态以及场景中物品的移动方向与人类的关系。这使得很难直接将基于图像的模型扩展到利用人-物体联合的感兴趣区域(ROI)特征的视频。
- 我们提出了一种新的两级图来改进交互表示;第一个图模拟了人与物体几何关键点之间的相互依存关系,第二个图模拟了视觉特征与学习到的几何表示之间的相互依存关系。
3. 多人HOI数据集(MPHOI-72)
- 我们提出了一个具有多人活动的HOI数据集(MPHOI-72),这是具有挑战性的,因为人类和物体之间存在许多身体遮挡。
- 我们有3名男性和2名女性,年龄在23-27岁之间,他们随机分为8组,每组2人,进行3种不同的HOI活动,与2-4个物体互动。
- 我们还准备了6件物品:杯子、瓶子、剪刀、吹风机、鼠标和笔记本电脑。
- 定义:
3 activities = {Cheering, Hair cutting, Co-working}
13 sub-activities = {Sit, Approach, Retreat, Place, Lift, Pour, Drink, Cheers, Cut, Dry, Work, Ask, Solve} 。 - 该数据集由从3个不同角度以30 fps的速度捕获的72个视频组成,总计26,383帧,平均长度为12秒。
- 图2显示了我们的MPHOI-72数据集中三个活动的一些示例视频帧,并且每个主题的子活动标签都是按帧注释的。

- 最上面一排展示的是从正面看Hair cutting,其中一个受试者坐着,另一个受试者与一把剪刀和一个吹风机互动。站在后面的主体身体的大部分是看不见的。
- 第二行展示了一种流行的人类活动——Cheering,在这个活动中,两个人从自己的瓶子里倒水,举起杯子欢呼,然后喝。在整个活动过程中,人、杯子和瓶子之间存在着高度闭塞。
- 最下面一排是Co-working,它模拟了两个同事提问和解决问题的情况。此外,我们还考虑了不同的人的体型、肤色和性别平衡。这些样本说明了我们数据集的多样性。
- 我们使用Azure Kinect SDK来收集3840 × 2160分辨率的RGB-D视频,并使用他们的身体跟踪SDK来捕捉两个主体骨架的完整动态。
- 对象边界框是按帧手动标注的。
- 对于每个视频,我们都提供了这样的几何特征: 2D人体骨架和参与活动的主体和对象的边界框(图1)。
4. Two-level Geometric Features Informed Graph Convolutional Network (2G-GCN)
- 为了了解人与物体交互过程中的相关性,我们提出了一个两级图结构来模拟几何特征的相互依赖性,称为2G-GCN。
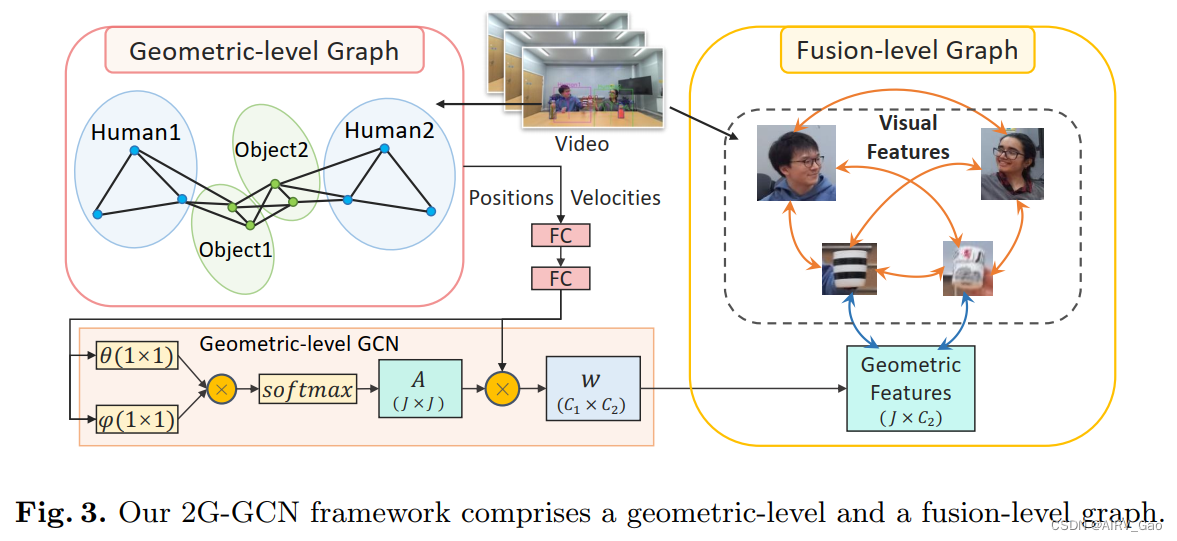
- 该模型由两个关键组件组成:用于建模几何和对象特征以方便图卷积学习的geometry-level graph,以及用于融合几何和视觉特征的fusion-level graph(图3)。
4.1 几何特征
- 人类的几何特征可以用各种方式来表示。人体骨骼包含一个明确的图形结构,关节作为节点,骨骼作为边缘。
- 关节的位置和速度为人体运动提供了细粒度的动态,而关节角度也为3D骨骼数据提供了空间线索。
- 另外,身体形状和它们在运动过程中如何变形也可以由表面模型或隐式模型表示。
- 我们使用具有关节位置和速度的人体骨骼,因为它们是人体运动的基本线索。此外,与体型不同,它们与人类的外表是不变的。
- 我们用一种有效的表示来表示人体姿势,以影响HOI识别。对于人体骨骼,我们选择特定的身体关键点并将其表示为一个集合S。

其中M表示human h 在时间 t 的k型人体关节。T 表示video的全部帧数,H 和 K 表示一帧中人的总数和人体的关键点。 - 对于给定的人体关键点M,我们定义它的位置为:
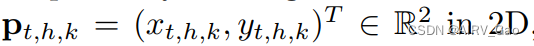
速度为:
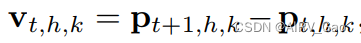
- 在每个人体骨架关键点的通道中,我们将其位置 p_t,h,k和速度 v_t,h,k在通道域中串联起来,形成人体几何上下文 h_t,h,k = [p_t,h,k, v_t,h,k]∈R4。
- 由于 object 在HOI视频中起着至关重要的作用,我们还考虑了它们的几何特征。物体边界框的两个对角线点用来表示物体的位置。
4.2 Geometric-level Graph
- 我们设计了一个新的几何级图,包括人类骨架和物体关键点,以探索它们在活动中的相关性(图3左)。
- 我们使用 g_t 来表示具有关键点几何特征的图节点,关键点可以是帧 t 上的人的h_t,h,k,或者是的对象的o_t,f,u。
- 因此,第 t 帧的所有关键点表示为:Gt = (g_t,1; · · · ; g_t,J),其中J = H ×K +F × 2个关节,每个关节有个4通道尺寸,包括其二维位置和速度。这使我们能够通过学习他们的动态空间线索来增强GCN捕获HOI活动中人和物体关键点之间相关性的能力。
- 我们使用两个全连接层来嵌入g_t:
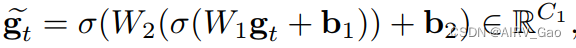
- 我们提出了一种利用GCN中几何特征相似性的自适应邻接矩阵。
- 我们在 g_t 中使用点积相似度,因为它允许我们确定在同一帧 t 中的两个关键点之间是否存在以及有多强的连接。与其他策略(如传统邻接矩阵,表示人体的物理结构或完全学习的邻接矩阵,不需要图表示的监督)相比,这是一个更好的选择。
- 我们将邻接矩阵 At 与第 j1 和第 j2 个关键点表示为:
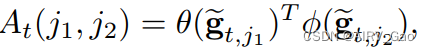
其中θ,φ∈RC2 表示两个变换函数,每个变换函数由 1 × 1卷积层施加。 - 然后对At的每一行进行 SoftMax 激活,保证一个节点所有边权的积分等于1。
- 我们随后从GCN得到几何级图的输出为
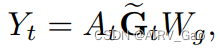
4.3 Fusion-Level Graph
- 我们提出了一种融合级图来连接从GCN中学习到的几何特征和视觉特征。
- 之前关于视频中基于CNN的HOI识别的工作过于强调视觉特征而忽略了人和物体的几何特征。
- 相比之下,我们首先通过ROI池提取每个人或物体实体的视觉特征,然后引入GCN的几何输出Yt 作为辅助特征来补充视觉表示。 然后将所有实体的特征向量通过具有ReLU激活函数的两层MLP嵌入到相同的隐藏大小。
- Fusion-Level Graph 的一个关键设计是一个注意机制,以估计相互作用的相邻实体的相关性。
- 如图3的 Fusion-Level Graph 所示,每个人和物体通过时间表示一个实体,而 Yt 则形成一个附加的实体加入到图中。
- 视频中所有人和物体的视觉特征之间的所有联系都被捕获,用橙色箭头表示。蓝色箭头表示几何和物体视觉特征之间的联系。
- 根据经验,连接 geometry-object 对 始终比应用具有 geometry-human 连接的全连接图表现得更好。一个可能的原因是,人类通常体型较大,因此有更大的机会被遮挡。
- 将这些相对嘈杂的人类视觉和几何特征关联起来,要比将这些物体对应起来困难得多。在消融研究中评估融合策略。
- 融合级图中使用的注意力机制计算来自相邻节点的贡献的加权平均值,通过具有相同键和值的缩放点积注意力的变体实现
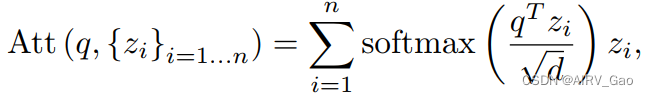
其中q为查询向量,{zi}为大小为n的键/值向量集合,d为特征维数。 - 在构建了融合级图之后,我们使用ASSIGN作为HOI识别的主干。ASSIGN是一种循环图网络,可以自动检测视频中与异步和稀疏实体相关的HOI结构。
- 我们的融合级图与ASSIGN中的HOI图结构兼容,允许我们使用网络来根据数据集预测人类的子活动和 object 的对象可视性。
5. 实验
5.1 数据集
- 我们在我们的MPHOI-72数据集、CAD-120数据集和bimmanual Actions数据集上进行了实验,展示了2G-GCN在多人、单人和双手 HOI识别上的优越效果。
- CAD-120被广泛用于HOI识别。它由120个RGB-D视频组成,由4名参与者分别进行10个不同的活动,每个活动重复3次。参与者在每个视频中与1-5个对象交互。总共有10个人类子活动(例如,吃,喝)和12个对象能供性 (例如,静止的,可饮用的),它们每帧被注释。
- bimmanual Actions 是第一个HOI活动数据集,其中受试者使用两只手与物体交互(例如,左手握住一块木头,而右手锯它)。它包含540个RGB-D视频,6个受试者进行9种不同的活动,每种活动重复10次。每只手总共有14个动作标签,视频中的每个实体都是按帧进行注释的。
5.2 实现细节
- 网络设置:我们通过Faster R-CNN模块检测到的视频中从人和物体的2D边界框中提取2048维ROI池特征,该模块在视觉基因组数据集上进行实体视觉特征的预训练。我们将两个FC层的神经元数量分别设置为64,128,用于几何级图中Eq. 2的嵌入和转换函数(即C1 = 64, C2 = 128)。
- 实验设置:2G-GCN通过两个任务进行评估:1) joined segmentation; 2) 给定已知分割的标签识别。
(1)第一个任务需要模型分割和识别视频中每个实体的时间轴。
(2) 第二个任务是前一个任务的变体,其中ground-truth segmentation是已知的,并且模型需要命名现有的片段。 - 对于Bimanual Actions和CAD-120数据集,我们使用留一受试者交叉验证来评估2G-GCN在未知受试者中的泛化效果。
- 在MPHOI-72上,我们定义了一个交叉验证方案,选择两个不存在于训练集中的受试者作为测试集。
5.3 定量比较
Multi-person HOIs
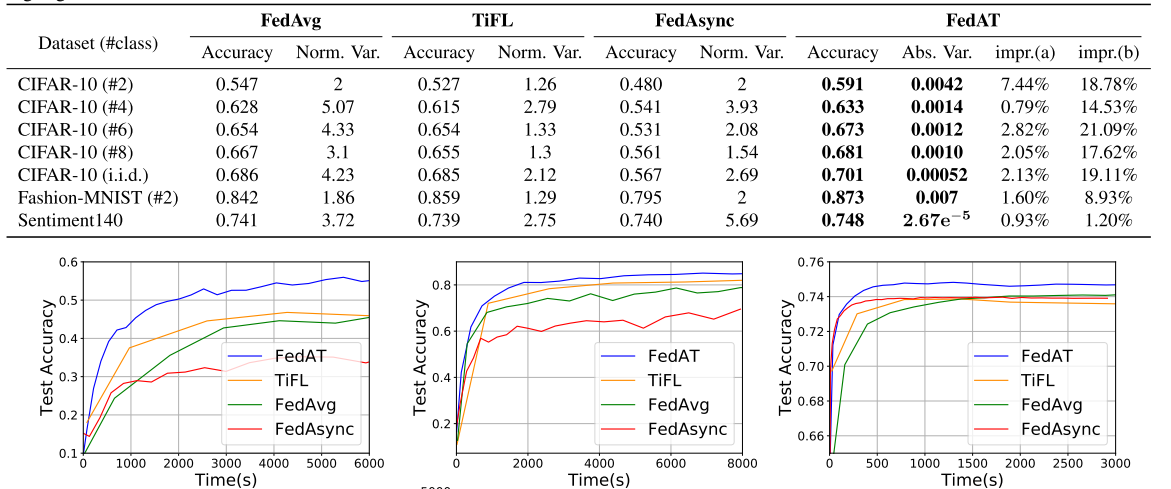
- 在我们具有挑战性的MPHOI-72数据集中,2G-GCN以相当大的差距击败了ASSIGN(表1)。

- 证明了几何特征的应用及其与视觉特征的融合可以激励我们的模型学习稳定和基本的特征,即使在HOI中出现明显的遮挡。
Single-person HOIs
- 2G-GCN的通用配方在单人HOI识别中具有优异的性能。
- 表2给出了在CAD-120上使用最先进的2G-GCN和两个基于BiRNN的基线的结果。
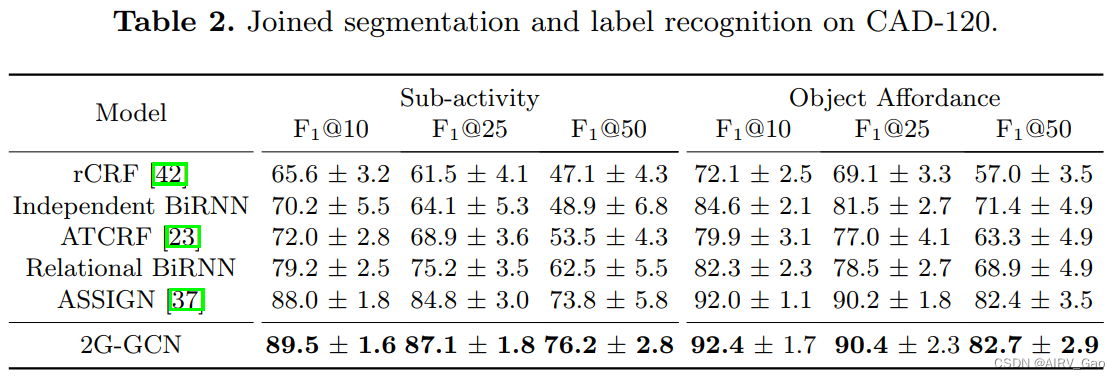
- 这些发现证明了使用人体骨骼和物体边界盒的几何特征,而不是只使用视觉特征(如ASSIGN)的好处。
Two-hand HOIs
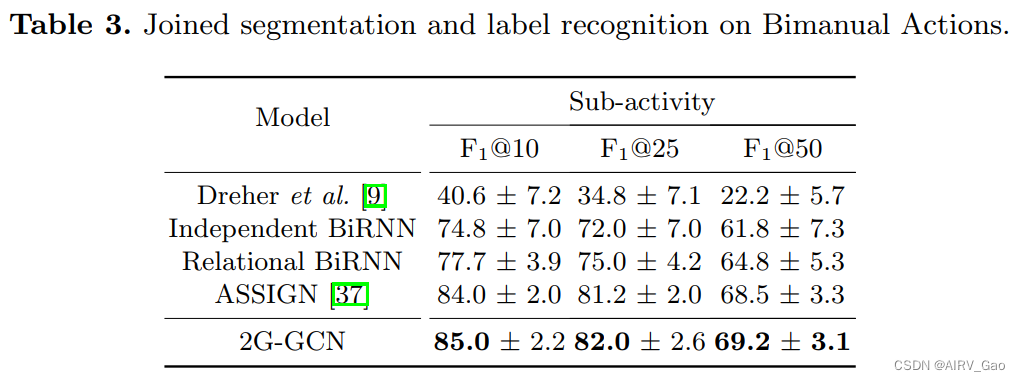
- 对于双手HOI识别在Bimanual Actions数据集上,2G-GCN优于ASSIGN约1%。
- 我们将加入分割和标记任务的性能与Dreher等人的,ASSIGN和BiRNN基线进行比较(表3)。
5.4 定性比较
- 我们在具有挑战性的MPHOI-72数据集上比较了2G-GCN的可视化和相关方法。
- 图4显示了使用2G-GCN和ASSIGN方法的分割和标记结果的示例,并将其与Cheering活动的groundtruth进行了比较。

我们用红色虚线框突出了一些主要的分割错误。 - 图5显示了在CAD-120数据集上taking food活动的示例。
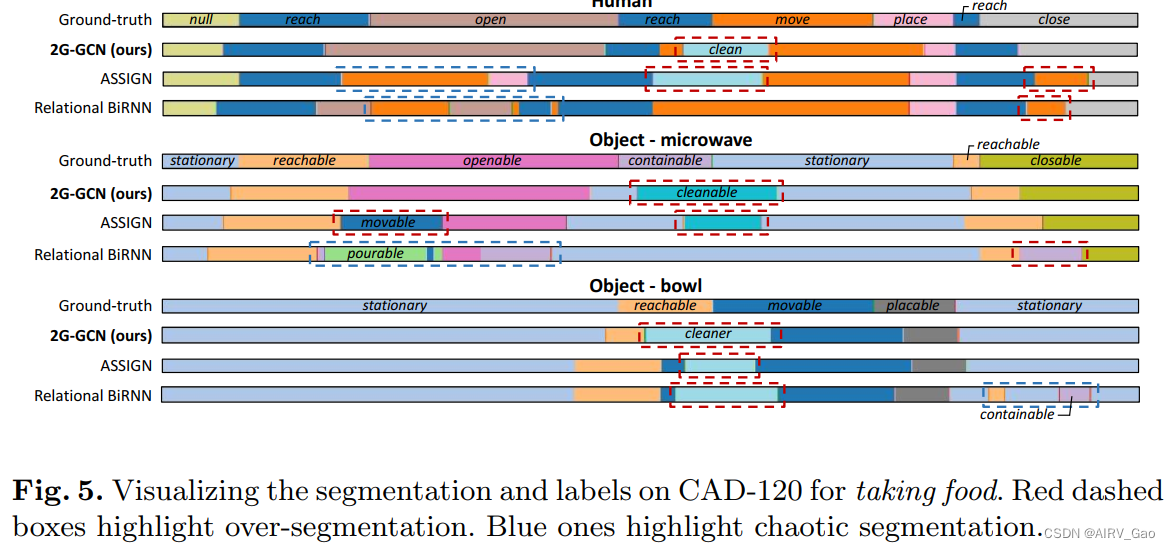
- 图6描述了在bimmanual Actions数据集上cooking活动的定性可视化。

5.5 烧蚀研究
- 在我们的方法中提出的两个图包含重要的结构信息。
- 我们删除了各种基本模块,并在CAD-120数据集上对它们进行了评估,以展示不同2G-GCN组件的作用,如表4所示,其中GG和FG分别表示geometric-level图和geometric-level图。