0x01 前言
CodeQL的自动化代码审计之路(上篇)
CodeQL的自动化代码审计之路(中篇)
在上一篇文章中,我们基于CodeQL官方提供的sdk实现了自动化查询数据库功能,在文章中也提到实现完整的自动化代码审计还缺少“数据库生成”相应的功能,本文主要针对“数据库生成”这一阶段来阐述整个过程实践中的优缺点。
生成数据库是整个CodeQL使用中最重要的一个步骤,对于java语言来说,生成数据库的过程要比其他语言更难。CodeQL的数据库中本质上保存的是与代码相关的AST语法树,通过VSCode提供的AST Viewer功能,可以很清晰地看出来最终生成地AST结果,如图1.1所示。熟悉词法和语法分析的小伙伴相信不会对AST的结构感到陌生。
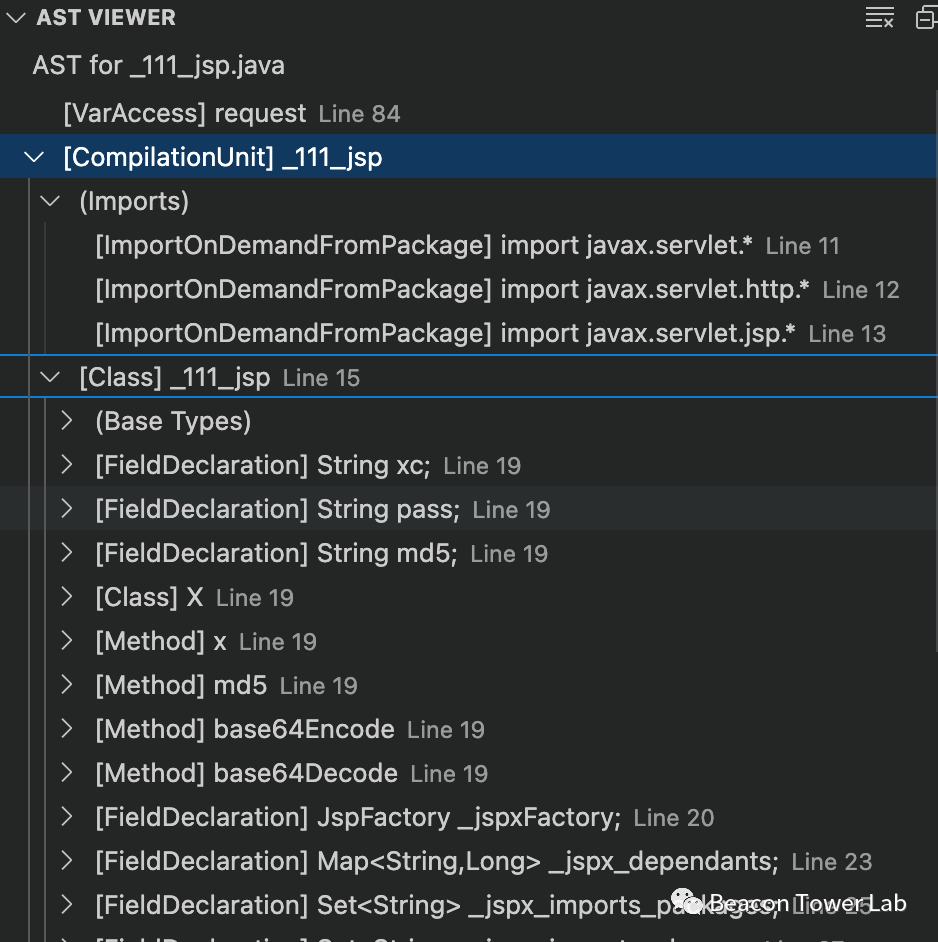
图1.1 使用CodeQL生成的AST语法树
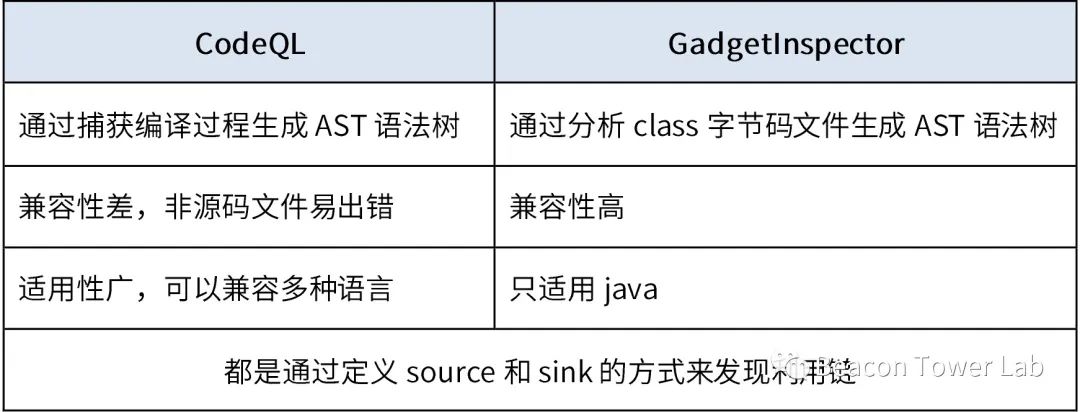
熟悉JAVA安全的小伙伴可能听过另一种生成AST语法树的方法GadgetInspector。如果单纯只是针对JAVA语言的话,个人觉得GadgetInspector的实现思路和效果是要优于CodeQL的,主要对比如表1.1所示。
表1.1 CodeQL和GadgetInspector对比
个人一直研究基于CodeQL的代码审计工具,主要是想解决多种语言的代码审计问题,虽然目前的严重重点还是在java语言中,但是对其他语言的兼容会是后续的研究重点。
0x02 初探
对于脚本语言(例如python)CodeQL在生成数据库的时候是很简单的,命令如下所以,注意对于脚本语言不应使用--command参数。非ARM系统去除“arch -x86_64”,后续所有命令均按此处理,不再赘述。
arch -x86_64 codeql database create /Users/xxx/CodeQL/databases/giza --language=python --source-root=/Users/xxx/Downloads/giza在成功生成数据库之后一般会有successfully的提示,如图2.1所示。一般脚本语言创建数据库的过程都很简单,不容易出现问题。
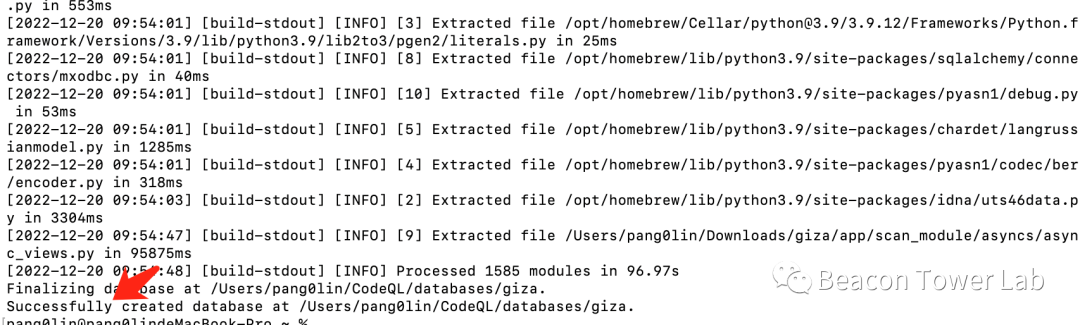
图2.1 使用CodeQL创建python语言对应的数据库
由于java是一种编译型语言,创建的过程中需要指定编译命令。对于源码文件来说,典型的java语言创建数据库的命令如下所示,结果如图2.2所示。
arch -x86_64 codeql database create /Users/test/CodeQL/databases/mvn_test --language=java --command='mvn clean install -DskipTests' --source-root=/Users/pang0lin/java/projects/mvn_test --overwrite--language: 指定对应源码的语言类型
--command: 执行的编译命令,对于编译型语言,此参数必填
--source-root: 指定源码路径
--overwrite: 覆盖保存生成的数据库,如果当前数据库以存在,则必填

图2.2 使用CodeQL创建java语言对应的数据库
上面的过程中几乎属于是CodeQL官方给出的关于创建数据库的典型案例,但是在现实环境中确不一定能直接拿到目标编译前的源码,一般情况下可以获取到的源码都是编译后的源码,主要表现形式如下。
1) 用于部署SpringBoot项目的jar包或者用于部署tomcat项目的war包。
2) 直接从目标WEB目录拷贝的源码文件,一般包含jsp文件、class文件、配置文件等。
在开始我们的探索之前,首先需要明确一个观点是,使用原生的CodeQL创建数据库的指令不会创建jsp文件对应的AST语法树。为了演示这个现象,我们创建一个SpringMVC的项目,并且在webapp目录中增加一个jsp文件,如图2.3所示。
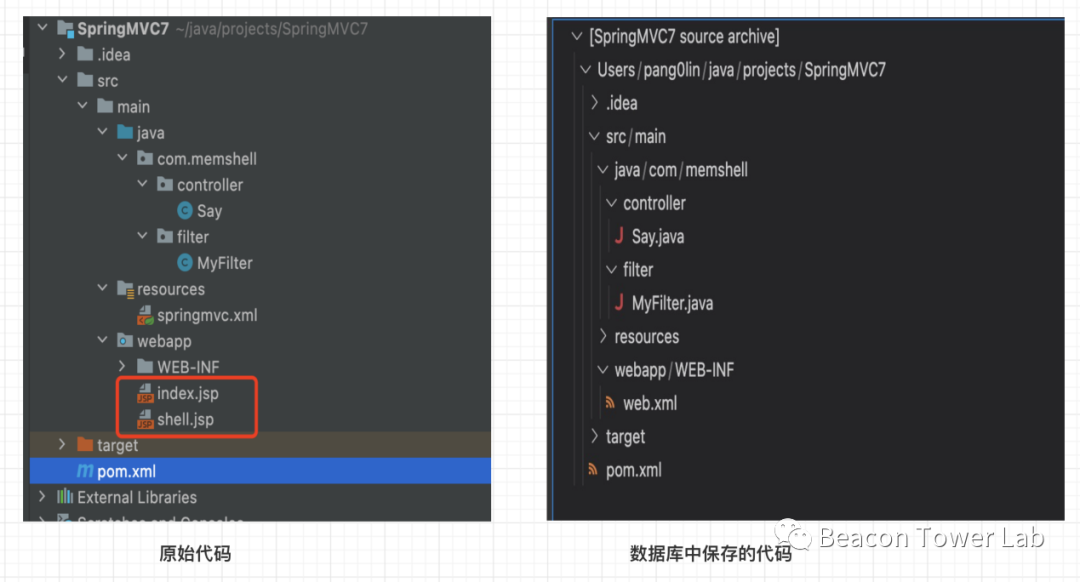
图2.3 对比SpringMVC生成数据库中的文件和源代码中的区别
从图2.3中可以看出,对于SpringMVC类型的源代码,如果直接采用CodeQL官方demo的方式来生成数据库,并不会创建jsp文件对应的AST语法树。所以在图2.3右边生成的数据库中没有找到shell.jsp和index.jsp对应的文件。
如果需要了解详细的关于CodeQL创建数据库的原理,可以参考大佬的文章https://paper.seebug.org/1921/。
从大佬的文章中可以得出一个结论,如果需要CodeQL创建对应的数据库,则该文件必须要有“编译”过程。所以在实际环境中,不论是jsp文件、class文件,还第三方的jar包,都是不能直接被创建到数据库中的。
如果要用编译后的文件来生成数据库,则必须首先对把对应的文件反编译成java源文件,然后再对java源文件进行“编译”才能成功生成对应文件对应的数据库。
0x03 研究
从上面的分析中,我们首先需要明确的一个事情,就是需要对编译后的源码进行反编译。目前市面上关于java反编译的工具有很多,但是作为idea的忠实粉丝,最初的选择还是直接使用idea自带的反编译工具java-decompiler.jar。
安装了idea之后都存在java-decompiler.jar文件,默认位置是/Applications/IntelliJ IDEA.app/Contents/plugins/java-decompiler/lib/java-decompiler.jar。直接拷贝对应的jar包,源于java-decompiler.jar的用法如下:
java -cp java-decompiler.jar org.jetbrains.java.decompiler.main.decompiler.ConsoleDecompiler -dgs=true test/ xxx/图3.1 使用java-decompiler.jar对目标进行反编译
但是在后面实际的利用过程中发现有大量的文件在反编译之后没法再进行编译,如图3.2所示,这是使用idea进行反编译之后得到的部分代码,在代码中可以很清晰的看到重复定义了变量_hashCode。所以再对这个代码进行编译的时候就会报错。
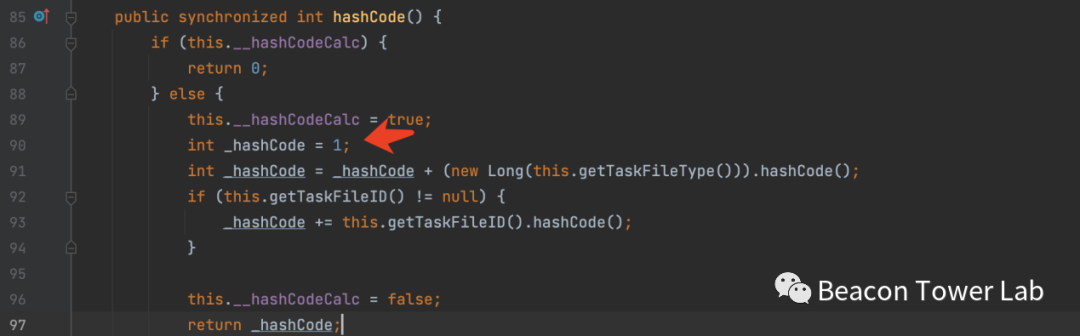
图3.2 Idea反编译时遇到的重复定义变量的问题
对上面的代码换一个反编译工具,使用jd-gui来对同样的代码进行反编译,得到的代码如图3.3所示。
图3.3 使用jd-gui来反编译代码
从代码中可以明显的看出jd-gui并不会出现重复定义变量的问题,类似的问题还有int i=False;这种,如图3.4所示,在IDEA反编译的代码中会出现类型不匹配的问题,但是jd-gui并不会。所以,经过实践之后,我最终抛弃了idea的java-decompiler.jar,转而开始使用jd-gui。但是jd-gui是属于界面版本工具,我们需要使用其命令行版本jd-cli。
图3.4 由于类型不匹配导致的编译错误
下一个要解决的问题是从jsp文件转java文件,熟悉java的小伙伴应该都很了解tomcat的运行机制,在tomcat解析jsp文件的过程中,会首先通过tomcat-jasper.jar包来把jsp转化为对应的java类文件,如图3.5所示。
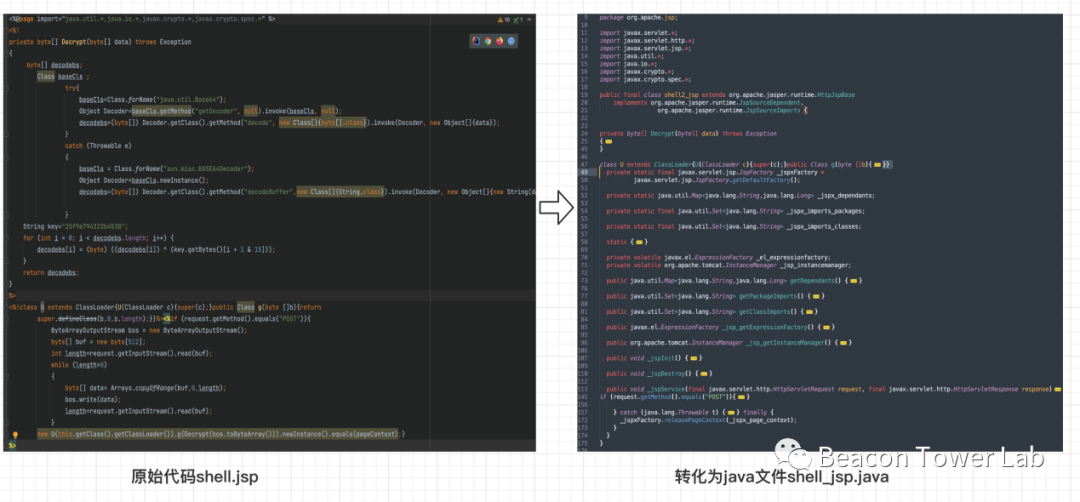
图3.5 把shell.jsp文件转化为shell_jsp.java文件
从图3.5可以看出shell.jsp文件已经被jsper转化为shell_jsp.java类文件,此文件是可以被“编译”的。那么我们后续如果要通过CodeQL来生成jsp文件对应的数据库,本质上还是生成的类似于shell_jsp.java文件对应的数据库。
那么,如何利用tomcat-jasper.jar来把jsp转化为java?其实只需要一小段代码,如图3.6所示。
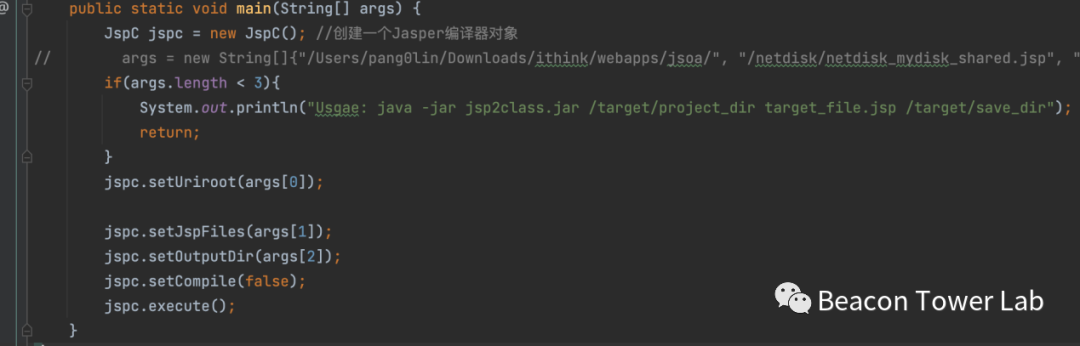
图3.6 通过JspC类把jsp文件转化为java类文件
为了能够直接在python的代码中调用对应的java代码,我把java代码打包成可以直接在命令行中调用的jar包jsp2class.jar(相关文件见源码),使用如图3.7所示。
第一个参数:jsp文件所在网站的跟目录。
第二个参数:jsp文件全路径名,相对于网站跟目录的相对路径。
第三个参数:生成的java文件保存的路径。
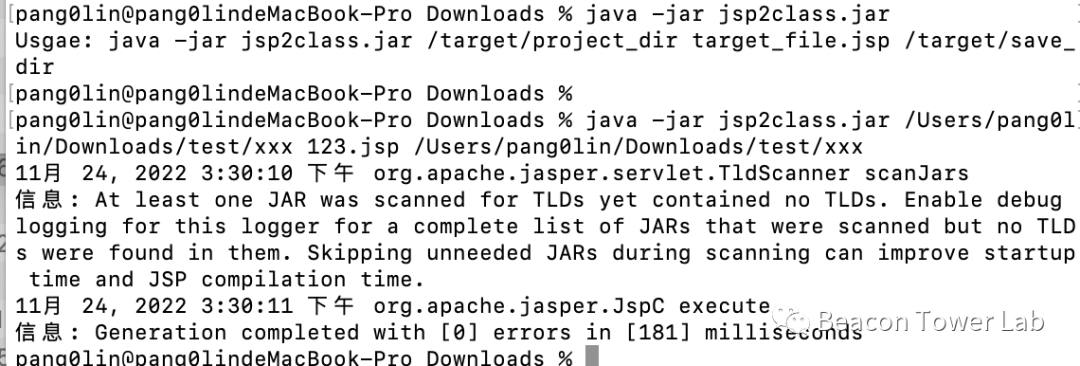
图3.7 使用打包好的jsp2class文件来转化jsp文件
目前我们已经解决了反编译需要的问题,剩下就是编译需要的问题。CodeQL给出的官方demo中是通过maven来触发代码的编译过程,但是实际环境中并不是所有的目标环境都是maven,参考大佬https://paper.seebug.org/1921/文章中提到的方式,可以采用ecj.jar来对目标代码进行编译。
使用ecj.jar与传统使用javac的方式对目标进行编译有容错率更高的优点,javac在编译的过程中遇到错误会报错并退出,但是ecj存在忽略错误并继续编译的选项。通过反编译方式得到的源码在编译过程中遇到错误是很正常的现象,而ecj可忽略错误的特性很好的满足了CodeQL生成数据库的要求,对于CodeQL而言更需要的是编译过程能更全的覆盖源代码文件,而不是编译之后的结果要可运行。
ecj.jar要求jdk1.8的环境运行,完整的ecj支持的参数可以参考官方文档https://www.ibm.com/docs/zh/radfws/9.6?topic=SSRTLW_9.6.0/org.eclipse.jdt.doc.user/tasks/task-using_batch_compiler.html。如图3.8所示。

图3.8 关于ecj.jar支持的参数列表
详细了解ecj.jar支持的参数列表对于我们后期优化ecj编译过程至关重要,因为后面很容易出现的一个情况就是存在的源码在CodeQL数据库中没有生成。典型的运行方式如下所示。
java -jar ecj-4.6.1.jar -extdirs /Users/xxx/lib -encoding UTF-8 -8 -warn:none -proceedOnError -noExit @/Users/xxx/test/CodeQLpy/file.txt-proceedOnError:指定ecj忽略错误继续运行,这对于CodeQL生成数据库很重要。
-warn:none:忽略所有警告,一般来说警告太多了,没有什么意义。
-extdirs:指定ecj编译过程中依赖的外部jar包目录。
@/Users/xxx/test/CodeQLpy/file.txt::指定要编译的目标java文件列表。
把上面编译的命令保存到sh文件中,然后就可以通过下面的命令来生成数据库,如图3.9所示。
arch -x86_64 codeql database create /Users/xxx/CodeQL/databases/test1 --language=java --command='sh /Users/xxx/Downloads/test/1.sh'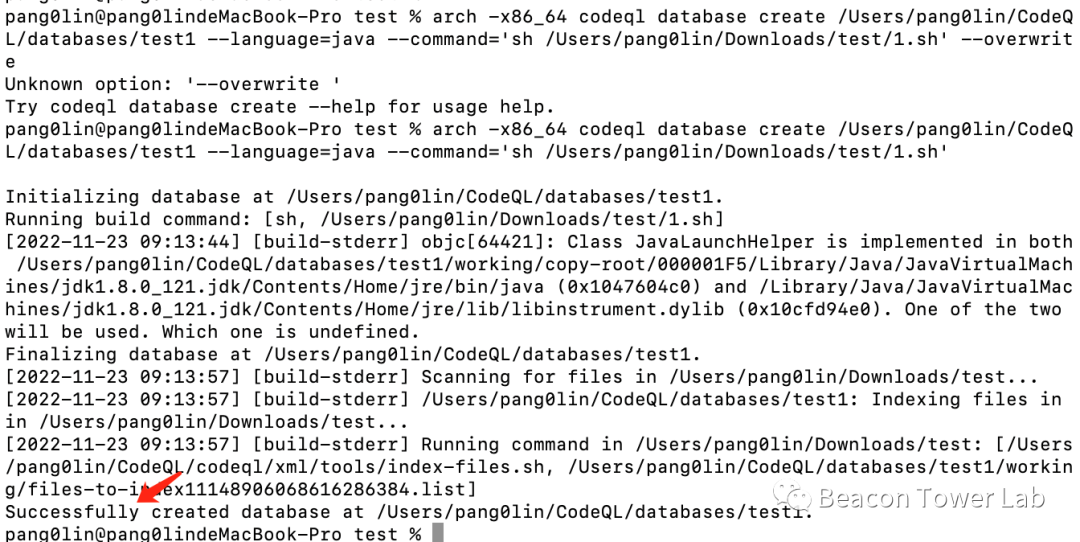
图3.9 通过ecj编译过程生成数据库
0x04 工具
我的初衷是基于CodeQL来达到半自动化代码审计的效果,通过python语言来实现整个工具的流程,虽然目前流程中还有很多已知的不足,但是基本的雏形已经有了,后面就是不断对代码进行优化的过程。
目前已经支持的功能如表4.1所示。
表4.1 项目支持的功能列表

项目运行时截图如图4.1所示。
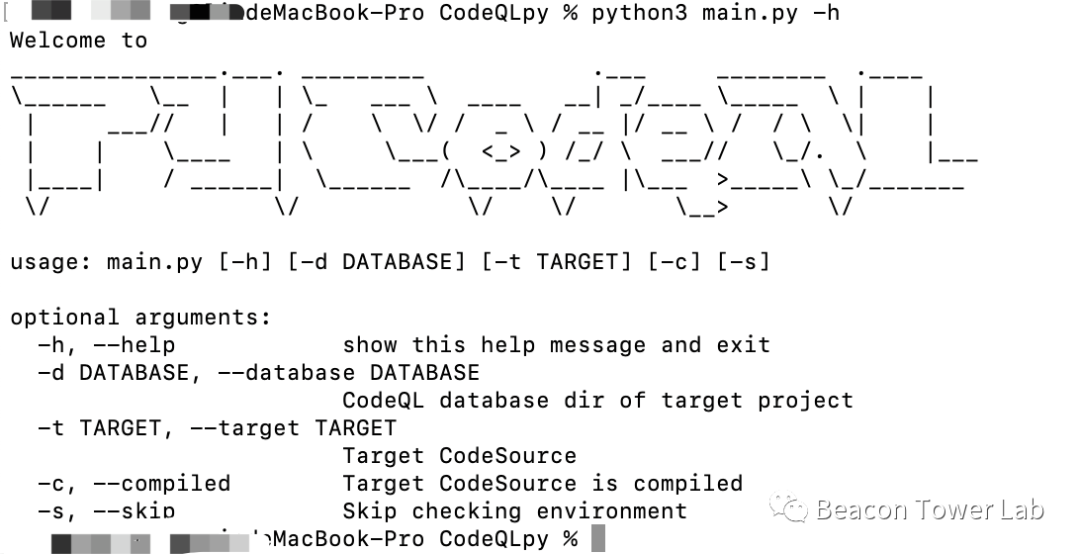
图4.1 程序支持的参数列表
-d: 指定要进行扫描的数据库,-d和-t参数二选一出现。
-t: 指定目标源码,可以是jar包,war包,文件夹或者maven源代码。-d和-t参数二选一出现。
-c: 指定源码是属于编译前的源码还是编译后的源码,默认是属于编译前源码。
-s: 指定是否跳过环境检查。
注意,如果是-t指定的源码是属于文件夹类型,则要求文件夹必须是网站跟路径。如果不是跟路径会出现相对路径错误导致的异常。
本地运行需要依据实际情况配置config/config.ini文件。
目前的版本更多的考虑是流程功能实现,暂未考虑并发和效率,所以现在跑一个目标花的时间比较久,运行之后会在out/result/目录生成结果,如图4.2,图4.3所示。
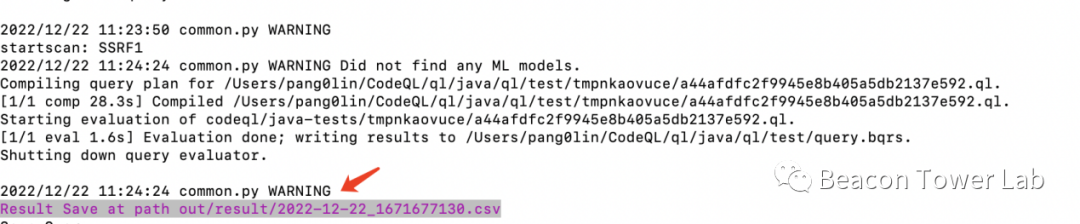
图4.2 运行完成的结果

图4.3 运行完成之后结果保存在csv文件
环境搭建过程中注意配置config/config.ini文件。目前已知的问题如下所示。
-
如果生成数据库的过程中出现很长一段时间无响应,可以使用页面响应的最后一条指令手动生成数据库。
codeql database create out/database/target_db --language=java --command='/bin/bash -c /Users/xxx/test/CodeQLpy/out/decode/run.sh'-
由于web.xml配置文件错误导致jsp文件反编译异常的。解决办法是替换web.xml文件,任意找一个可用的web.xml文件替换即可。
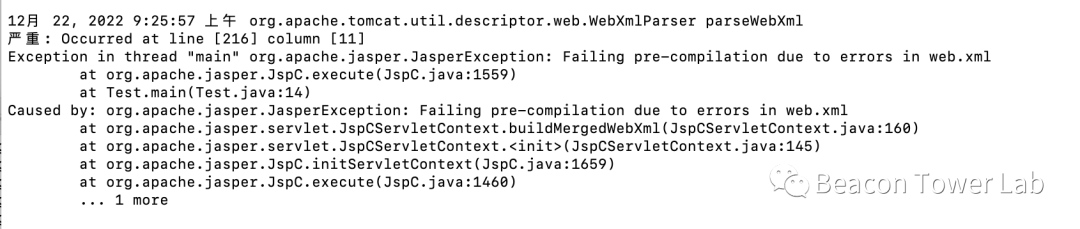
图4.4 异常报错情况
原创工具下载地址:
https://github.com/webraybtl/codeQlpy
如有更好建议欢迎留言交流

![[Square 2022] Hard Copy 复现](https://img-blog.csdnimg.cn/6cd71c6576b24c4081f6be6a84c88d3c.jpeg)