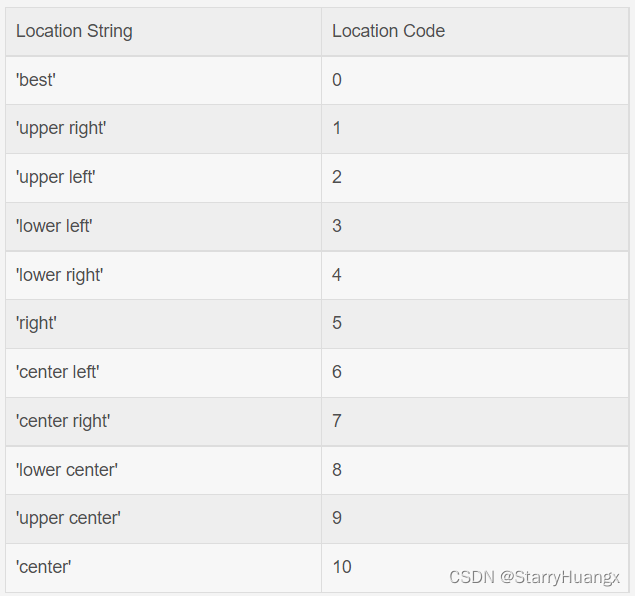
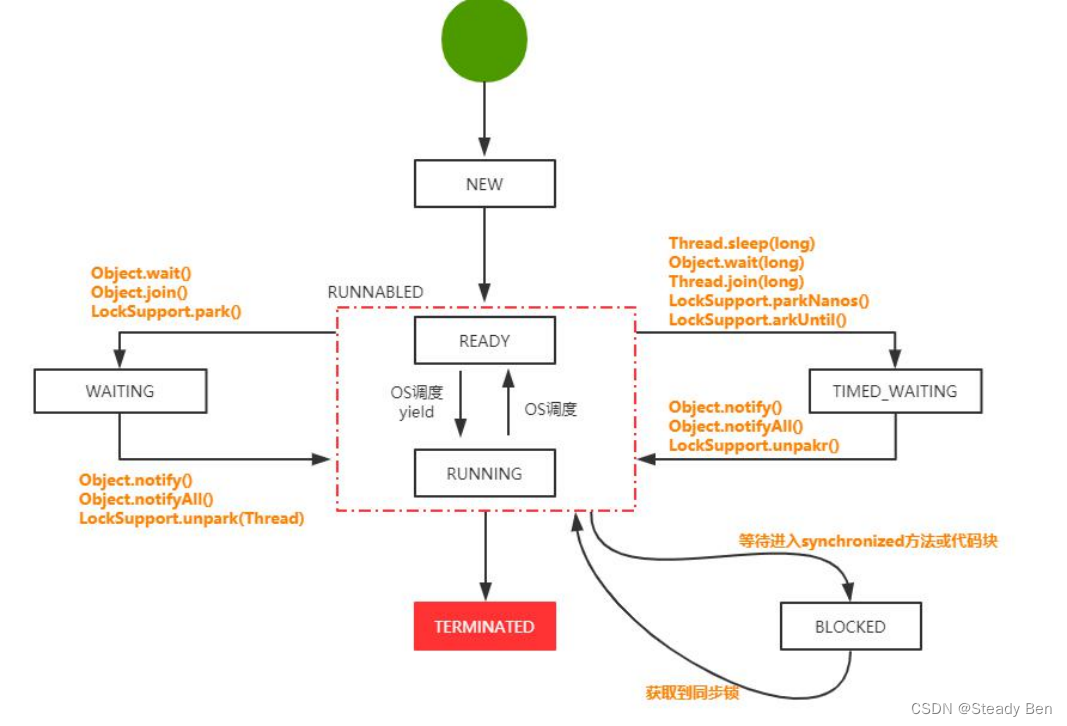
A Survey on Extreme Multi-label Learning
先给地址: https://arxiv.org/abs/2210.03968
博主曾整理过Multi-Label Image Classification(多标签图像分类),但这类任务中所用的数据集往往较小,分类数量并不多。但在更广泛的场景中,标签类别数目可能以百万量级出现,如推荐系统、搜索引擎中等等。如在社交平台上,为用户推荐tag,以自然文本形式出现的tag标签往往是语义广泛的,因此可以被视为是一个多标签学习任务。
任务定义
给定数据X和标签Y,该任务尝试学习一个函数f以映射输入x到y。y的种类通常特别大,通过按照标签y出现的频率进行排序,可以设定阈值
τ
\tau
τ将标签分为头部标签和尾部标签。
任务挑战
标签数量的众多将导致很多棘手的问题,主要有以下三种
-
- Volume。标签数据的增长使输入特征空间和输出标签空间都很大,从而导致可伸缩性问题和存储开销。应对该问题的三个最常见的假设分别是标签独立假设、洛沃兰克假设和层次结构假设(也分别对应着以下三种解决方案)。
-
- Quantity。数量是指标签的频率,分布通常是长尾的,即标签的频率分布高度不平衡,这些很少出现的标签却是数据集中的大多数。下图是维基百科和亚马逊的数据集分布,大量的标签呈现出明显的长尾分布。
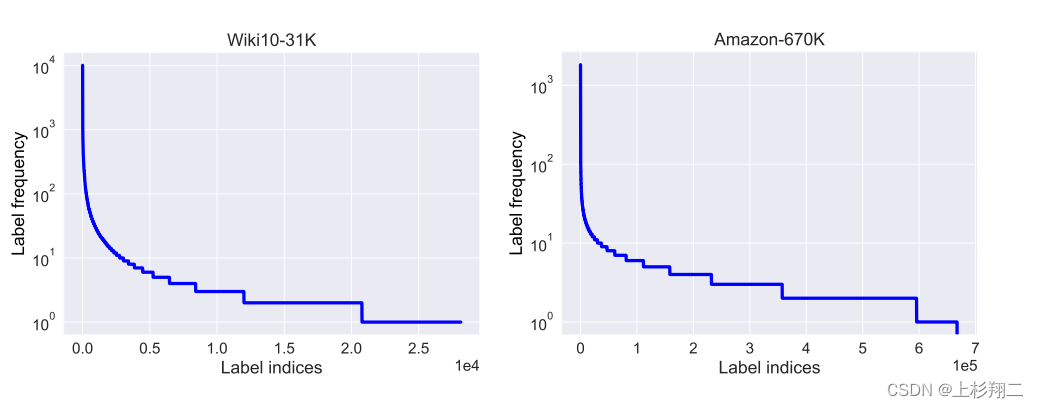
对尾部标签的泛化是极限多标签学习的核心问题之一。
- Quantity。数量是指标签的频率,分布通常是长尾的,即标签的频率分布高度不平衡,这些很少出现的标签却是数据集中的大多数。下图是维基百科和亚马逊的数据集分布,大量的标签呈现出明显的长尾分布。
-
- Quality。质量是指注释标签的质量问题。由于标签集和样本量较大,注释每个实例是非常昂贵的,甚至在很多场景中这一部分都是缺失的。
解决方案
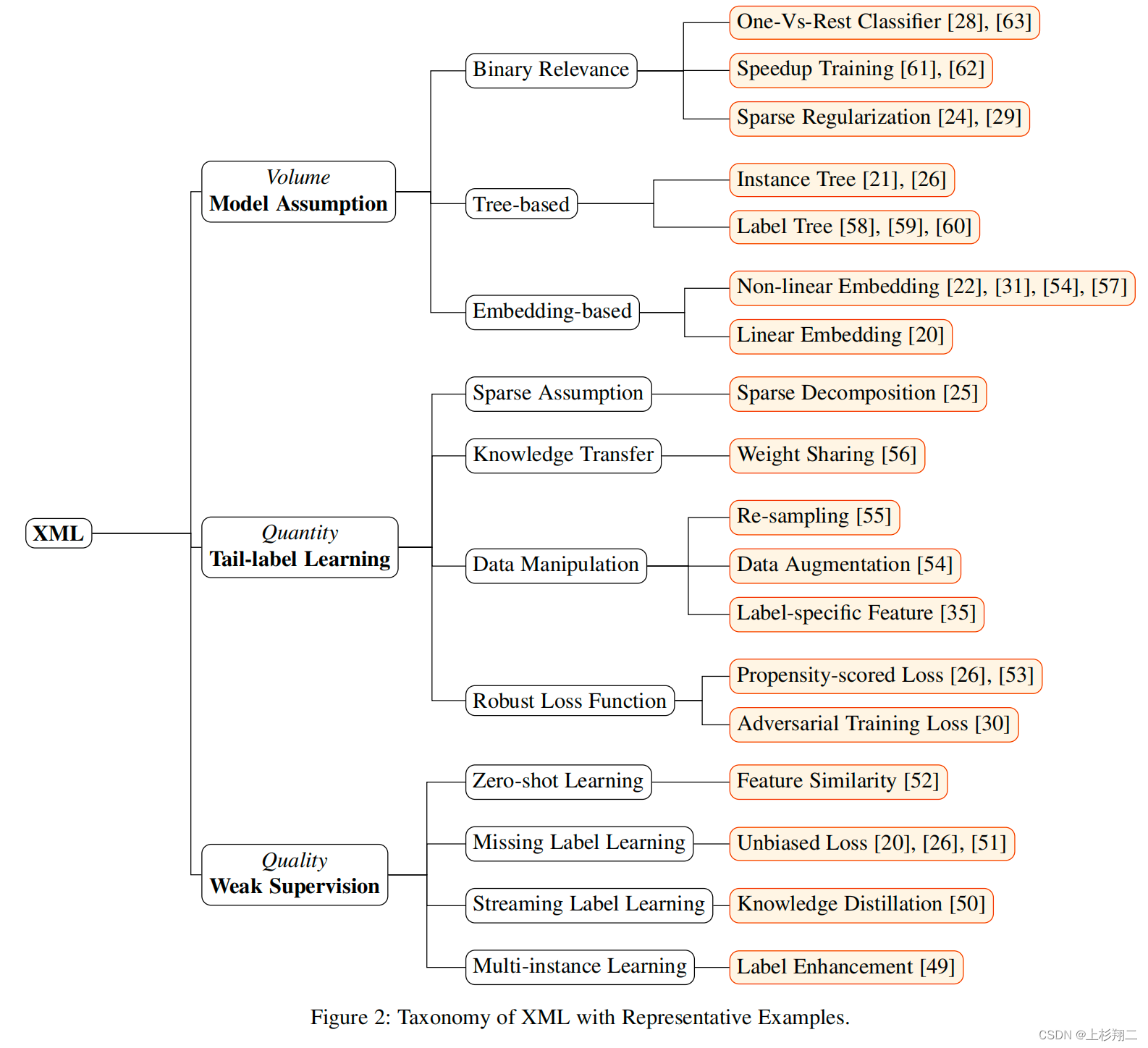
应对这三类挑战,也有一些典型的方法被陆续提出,如下图所示。
-
- Volume。Model Assumption 可以分为:二值关联方法、基于嵌入的方法和基于树的方法。
-
- Quantity。Tail-label Learning 可以分为:鲁棒损失函数、数据增强、知识转移。
-
- Quality。Weak Supervision可 以分为:零样本学习、缺失样本学习、多实例学习。
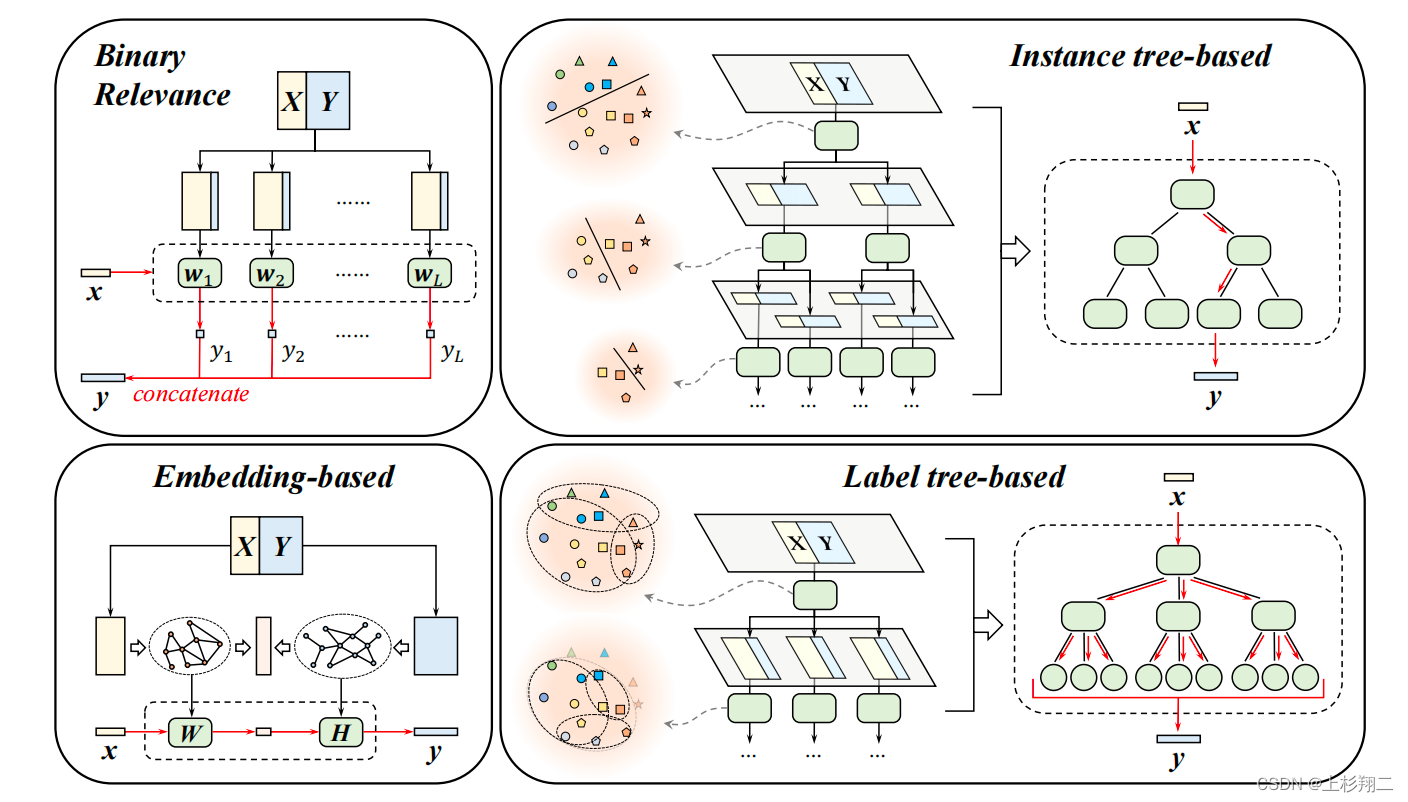
Model Assumption
应对特征空间和输出标签空间大的 Volume问题,Model Assumption 可以分为三个分支:二值关联方法、基于嵌入的方法和基于树的方法。
- 二进制相关性方法(binary relevance),假设标签是相互独立的,然后为每个标签分别学习一个二进制分类器。实现简单,但二进制相关性的时间和内存复杂性与标签的数量呈线性关系,因此存在较高的计算开销。当然,在这种方法前置一个标签滤波器是一个减少开销的方法。
- 基于嵌入的方法(embedding-based),利用标签本身的语义性,它们通常假设标签矩阵是低秩的。通常有两种嵌入方法,即线性或非线性投影。线性嵌入以将特征空间和标签空间一起嵌入到某个联合低维空间,通过在该空间计算相似度得到标签预测。在非线性嵌入中,利用图神经网络学习标签之间的非线性关系较为流行。这类将标签也视为特征的做法,也可以缓解尾标签样本数量不足,减少模型的参数数量和训练成本。此类方法最大的缺点在于嵌入过程中信息的丢失。
- 基于树的方法(tree-based),一般以层次的形式挖掘标签语义,可以大大减少推理时间。通常有两种类型的构树策略:实例树(instance tree-based)和标签树(label tree-based),这取决于在树节点中树分类是按实例或标签进行划分。在实例树中,每个节点由一组训练示例组成,然后逐层分配给子节点,这一点的直觉来源于特征空间的每个区域只包含少量的活动标签。在标签树中,每个节点由一组标签组成,然后将这些标签分配给子节点,一般通过递归的聚类方法来确定分类,直到达到构树的停止条件。基于树的方法的缺点在于,它可能会出现级联效应的影响,即预测误差从顶部传到底部。
Tail-label Learning
标签的长尾问题是一个重要的统计特征,除了头部特征外,尾部标签在许多现实应用中也十分重要,可以使信息更丰富和有益,如个性化推荐。但是不经常出现的标签(称为尾部标签)比经常出现的标签(称为头部标签)更难预测,特别是传统的方法采取所有标签重要性同等,很容易模型训练在头部标签上表现更好,而对尾部标签的预测性能更差。
为了应对标签长尾的问题,Tail-label Learning 可以分为以下分支:
- 鲁棒损失函数(Robust Loss Function)。主要通过设计一些损失函数引导模型增加对尾部标签的优先级,从而提高了尾部标签的泛化性能。
- 数据增强(Data Manipulation)。提高尾部标签性能的另一个简单想法是生成更多的数据,分为扩充数据或增强标签。
- 知识转移(Knowledge Transfer)。主要通过将知识从一些标签转移到另一些标签,如ECC为每个标签依次训练一个二进制分类器,然后给定每个标签,它使用原始特征和前一个标签分类器的预测来训练分类器。或者DeepXML同时在头部标签和尾部标签上训练两个深度模型,然后将头部标签的语义表示转移到尾部标签模型中。
Weak Supervision
为了解决标注昂贵问题,Weak Supervision被使用最多,主要讨论如何解决缺失标签甚至完全没有标签。缺失标签可以通过观察到的标签进行训练模型并处理缺失的标签。完全没有标签的zero-shot状态可以分为几种形式:
- eXtreme Multilabel Learning(XML)。
- Generalized Zero-shot Extreme Multi-label Learning (GZXML)。
- Few-Shot eXtreme Multi-label Learning(FSXML)。
- Extreme Zero-shot eXtreme Multi-label Learning(EZXML)。
未来方向
模型结构:
- 基于树的结构如何优化切分方式,基于聚类是否是最优?
- 基于嵌入如何控制过拟合?
长尾问题:
- 如何划分头部和尾部?目前的划分方法主要通过,设定特定部分为尾部或根据标签频率卡阈值,并没有一个原则的方法。
- 如何平衡头部和尾部准确率?很多工作展示了两类指标难以同时优化,因此有需要根据特定的XML任务进行权衡。
- 如何设计尾部标签的损失函数?
- 如何评估有尾部标签的模型?目前无法清楚地看到头部标签和尾部标签对指标的贡献。
弱监督学习
- 极端的多实例多标签学习(Extreme multi-instance multi-label learning)。例如,在视频分类中,标签是以视频级别进行标记的,人们可能希望预测视频的每一帧的相关标签。
- 开放域的极端多标签学习(Open-set extreme multi-label learning)。在许多真实世界的应用程序中,如何应用出现得特别快的新标签,即开放域标签,其除了对已知标签进行分类外,还需要学习开放域标签。
- 极端的多标签学习与流媒体标签(Extreme multi-label learning with streaming labels)。处理流媒体标签需要对经过训练的模型进行在线更新,目前还没发做的很好。
- 极端的多标签学习与缺失的标签(Extreme multi-label learning with missing labels)。由于标签空间大,缺少标签的现象很普遍,同时应对尾部标签和看不见的标签非常具挑战性。