模型实战(2)之YOLOv5 实时实例分割+训练自己数据集
本文将详解YOLOv5实例分割模型的使用及从头训练自己的数据集得到最优权重,可以直接替换数据集进行训练的训练模型可通过我的gitcode进行下载:https://gitcode.net/openmodel/yolov5-seg
详细过程将在文章中给出:
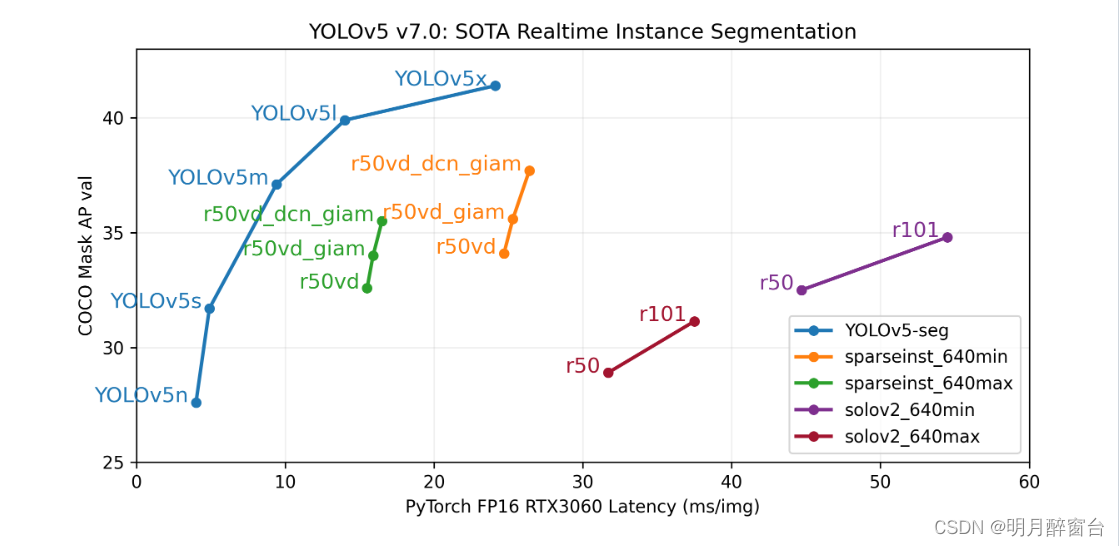
- 2022年11月22号YOLO的官方团队发布了yolov5-v7.0版用于实例分割,号称目前最快和最准确的模型:https://github.com/ultralytics/yolov5/tree/v7.0,其性能如下图:
- 为了对其更好的测试、验证和部署,可以参考官方手稿:https://github.com/ultralytics/yolov5/blob/master/segment/tutorial.ipynb
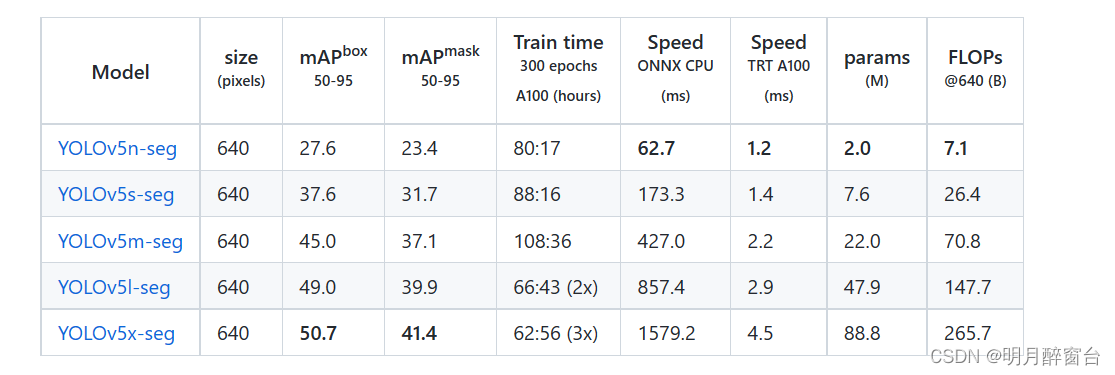
- 我们使用A100 gpu在coco上训练了300个epoch的YoLOv5分割模型,图像大小为640。我们将所有模型导出到ONNX FP32进行CPU速度测试,并导出到TensorRT FP16进行GPU速度测试。为了便于再现,我们在谷歌Colab Pro笔记本电脑上运行了所有速度测试。
YOLOv5n-seg … YOLOv5s-seg … YOLOv5m-seg … YOLOv5l-seg … YOLOv5x-seg
1.模型训练、验证、及预测
- 克隆代码到本地
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
#创建环境
conda create -n yolov5-seg python=3.8
#激活
conda activate yolov5-seg
# 安装 torch 1.8.2+cu11.1
pip install torch==1.8.2 torchvision==0.9.2 torchaudio===0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111
#其他版本:torch+cuda10.2
pip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
# 修改requirements.txt,将其中的torch和torchvision注释掉
pip install -r requirements.txt
- train
YOLOv5 segmentation training supports auto-download COCO128-seg segmentation dataset with--data coco128-seg.yamlargument and manual download of COCO-segments dataset withbash data/scripts/get_coco.sh --train --val --segmentsand thenpython train.py --data coco.yaml.
# Single-GPU
python segment/train.py --model yolov5s-seg.pt --data coco128-seg.yaml --epochs 5 --img 640
# Multi-GPU DDP
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --model yolov5s-seg.pt --data coco128-seg.yaml --epochs 5 --img 640 --device 0,1,2,3
- val 验证
Validate YOLOv5m-seg accuracy on ImageNet-1k dataset:
bash data/scripts/get_coco.sh --val --segments # download COCO val segments split (780MB, 5000 images)
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate
- predict 预测
Use pretrained YOLOv5m-seg.pt to predict bus.jpg:
python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jpg

- 导出onnx或者tensorRT:
python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0
2.训练自己的数据集实现实例分割
-
预训练模型下载
可通过我的开源仓库进行下载,已经各个文件路径、数据集制作等demo准备好,可以直接复用,详见:https://gitcode.net/openmodel/yolov5-seg
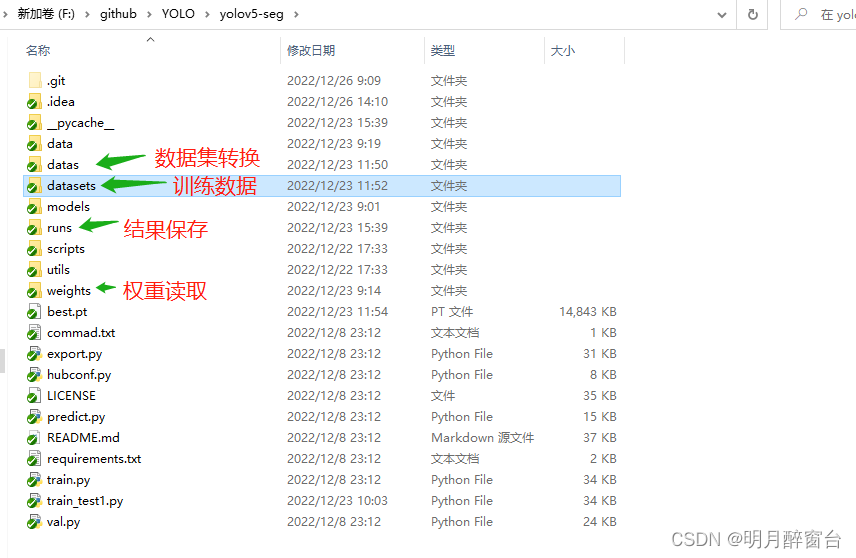
-
实例分割时目标检测与语义分割的结合,所以其标注文件初始为通过labelme标注的json格式,要用yolo模型进行训练,需要将其转换为yolo所需要的txt格式:
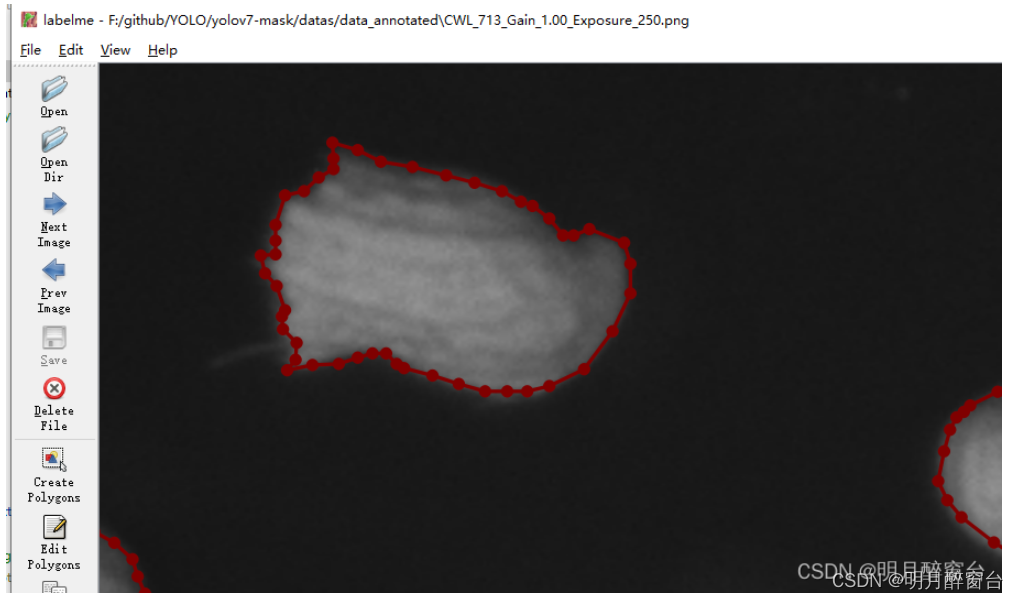
-
对于标准好的数据集,通过
datas中的json2yolo.py将json格式标注文件转换为.txt格式的标准文件


编写demo将标注的多边形区域复制到一个全黑背景(原图大小)图像中并imshow下:
import os, cv2, json
import numpy as np
base_path = './data_'
path_list = [i.split('.')[0]+'.'+i.split('.')[1] for i in os.listdir(base_path) if 'json' in i]
for path in path_list:
image = cv2.imread(f'{base_path}/{path}.png')
h, w, c = image.shape
label = np.zeros((h, w), dtype=np.uint8)
with open(f'{base_path}/{path}.json') as f:
mask = json.load(f)['shapes']
for i in mask:
i = np.array([np.array(j) for j in i['points']])
label = cv2.fillPoly(label, [np.array(i, dtype=np.int32)], color=255)
image = cv2.bitwise_and(image, image, mask=label)
cv2.imshow('Pic', image)
cv2.waitKey(0)
cv2.destroyAllWindows()

- 转换完成后将图像+标签文件(.txt)按照既定格式放到路径
./datasets文件夹下:
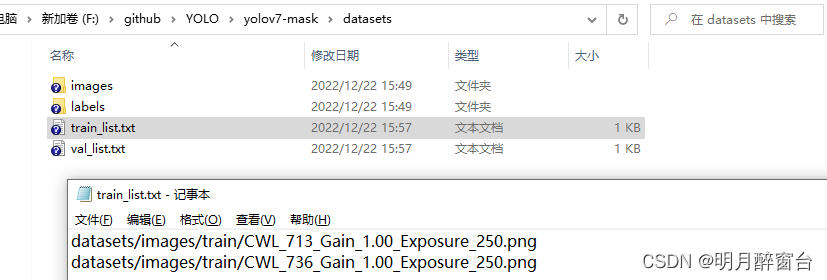
./data下修改模型配置文件:
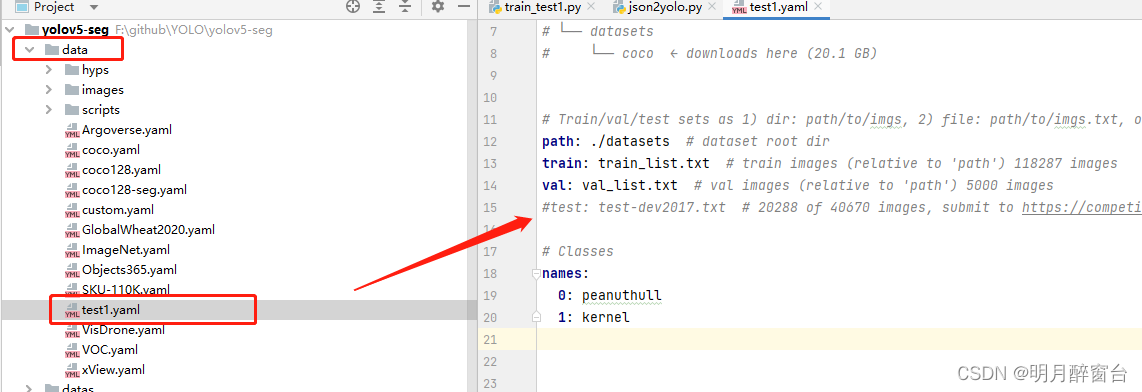
./model下设置模型参数并选择模型(s,m,l):

./weights下下载官方权重作为预训练初始权重:
我已将权重下载好并进行压缩,下载完代码后直接解压即可

- 训练demo修改相应路径,执行训练即可
训练结束后,训练好的best,pt将保存在如下的weights中:
- 修改predict.py中的相应参数,即可进行预测:
3.Load YOLOv5 with PyTorch Hub
详见参考:https://github.com/ultralytics/yolov5/issues/36
This example loads a pretrained YOLOv5s model from PyTorch Hub as model and passes an image for inference. ‘yolov5s’ is the lightest and fastest YOLOv5 model.
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Image
im = 'https://ultralytics.com/images/zidane.jpg'
# Inference
results = model(im)
results.pandas().xyxy[0]
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
This example shows batched inference with PIL and OpenCV image sources. results can be printed to console, saved to runs/hub, showed to screen on supported environments, and returned as tensors or pandas dataframes.
import cv2
import torch
from PIL import Image
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Images
for f in 'zidane.jpg', 'bus.jpg':
torch.hub.download_url_to_file('https://ultralytics.com/images/' + f, f) # download 2 images
im1 = Image.open('zidane.jpg') # PIL image
im2 = cv2.imread('bus.jpg')[..., ::-1] # OpenCV image (BGR to RGB)
# Inference
results = model([im1, im2], size=640) # batch of images
# Results
results.print()
results.save() # or .show()
results.xyxy[0] # im1 predictions (tensor)
results.pandas().xyxy[0] # im1 predictions (pandas)
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie

4.模型导出onnx或tensorRT
详细参考:https://github.com/ultralytics/yolov5/issues/251
YOLOv5 inference is officially supported in 11 formats:
💡 ProTip: Export to ONNX or OpenVINO for up to 3x CPU speedup. See CPU Benchmarks.
💡 ProTip: Export to TensorRT for up to 5x GPU speedup. See GPU Benchmarks.
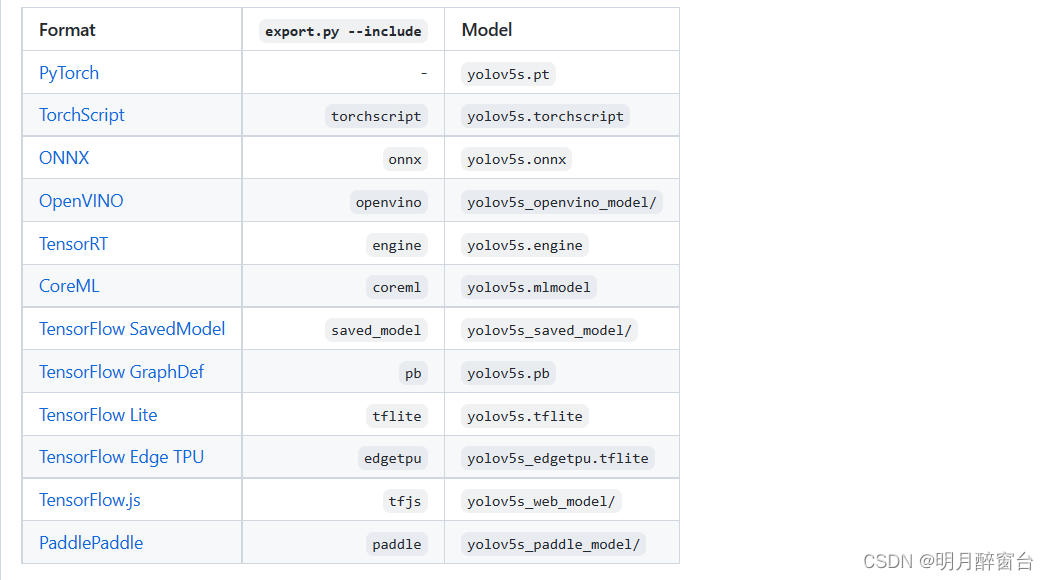
- 将已训练好的yolov5模型导出
This command exports a pretrained YOLOv5s model to TorchScript and ONNX formats.
python export.py --weights yolov5s.pt --include torchscript onnx
💡 ProTip: Add --half to export models at FP16 half precision for smaller file sizes
output:
export: data=data/coco128.yaml, weights=['yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['torchscript', 'onnx']
YOLOv5 🚀 v6.2-104-ge3e5122 Python-3.7.13 torch-1.12.1+cu113 CPU
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt to yolov5s.pt...
100% 14.1M/14.1M [00:00<00:00, 274MB/s]
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
PyTorch: starting from yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)
TorchScript: starting export with torch 1.12.1+cu113...
TorchScript: export success ✅ 1.7s, saved as yolov5s.torchscript (28.1 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.3s, saved as yolov5s.onnx (28.0 MB)
Export complete (5.5s)
Results saved to /content/yolov5
Detect: python detect.py --weights yolov5s.onnx
Validate: python val.py --weights yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')
Visualize: https://netron.app/
The 3 exported models will be saved alongside the original PyTorch model:

Netron Viewer is recommended for visualizing exported models:

- 引用模型:
python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
OpenCV inference with ONNX models:
python export.py --weights yolov5s.pt --include onnx
python detect.py --weights yolov5s.onnx --dnn # detect
python val.py --weights yolov5s.onnx --dnn # validate
Tutorials
- Train Custom Data 🚀 RECOMMENDED
- Tips for Best Training Results ☘️ RECOMMENDED
- Multi-GPU Training
- PyTorch Hub 🌟 NEW
- TFLite, ONNX, CoreML, TensorRT Export 🚀
- NVIDIA Jetson Nano Deployment 🌟 NEW
- Test-Time Augmentation (TTA)
- Model Ensembling
- Model Pruning/Sparsity
- Hyperparameter Evolution
- Transfer Learning with Frozen Layers
- Architecture Summary 🌟 NEW
- Roboflow for Datasets, Labeling, and Active Learning 🌟 NEW
- ClearML Logging 🌟 NEW
- Deci Platform 🌟 NEW
- Comet Logging 🌟 NEW