深度学习:ResNet从理论到代码
- 面临的问题
- 模型退化问题
- ResNet
- 核心思想
- 反向传播公式推导
- 残差的由来
- 残差模块为什么效果好
- 代码实现
面临的问题
模型退化问题
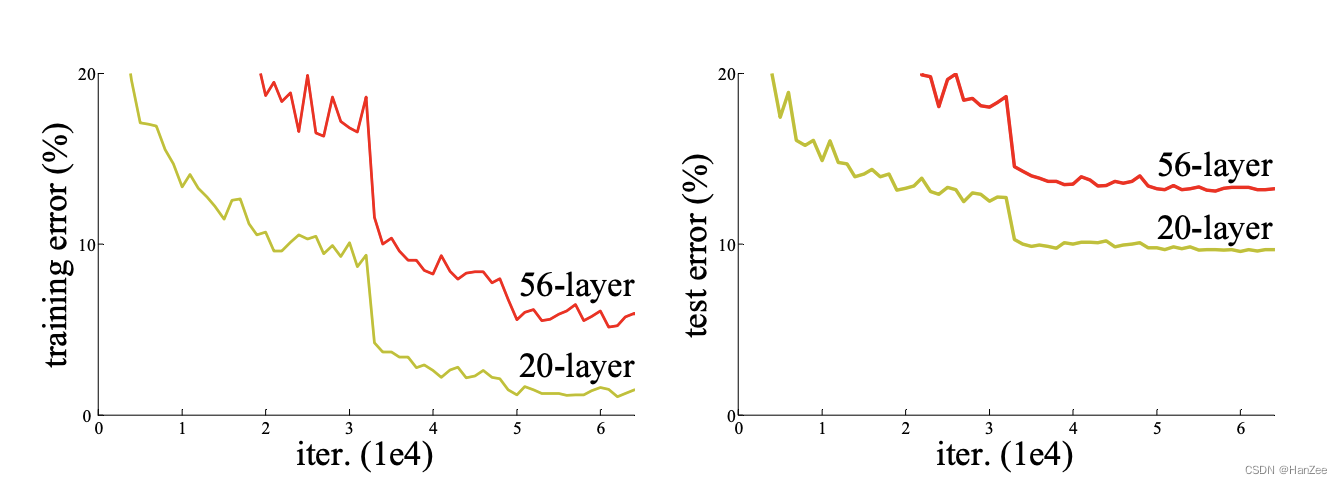
随着网络层数加深,性能逐渐降低,但它并不是过拟合,因为在test error降低的同时,train error 也在降低。
可能的原因:网络训练过程中正反向信息流动不通畅,网络没有被完全训练。
ResNet
作者的思想是如果在一个浅层模型可以找到一个很好的结果,那么他的对应版本的深层网络也会很好,因为只需要在浅层网络后面加恒等映射就可以(就是浅层网络后面的层即使不干好事,但也不会变坏),可是优化器SGD很难做到恒等映射也就是不变的操作,于是就有了下面的ResNet。
核心思想
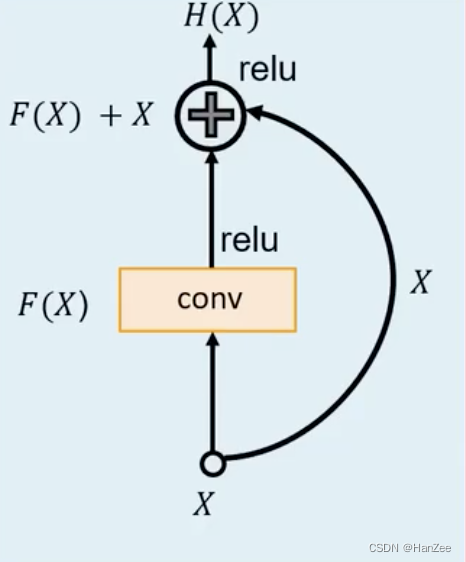
如上图所示,输入X,经过卷积层,ReLU激活得到F(X),然后计算F(x)+x得到H(x)。
H
(
x
)
=
F
(
x
)
+
x
H(x)=F(x)+x
H(x)=F(x)+x
x是残差块的输入,H(x)是输出,这种架构表示了即使Fx什么都不干,输出仍然会有x的信息,让网络不会变差。
句个🌰:
锐化操作实际上是一组特定的卷积核提取了图像某些特定的特征,然后与原图像合并进行视觉效果上的增强。

上图就可以看作原图x通过卷积层提取了相应的特征,然后把卷积层的输出与原图x在进行相加,这样就把卷积层感兴趣的特征与原图都保留了下来,就保证了图像/特征至少不会变坏。
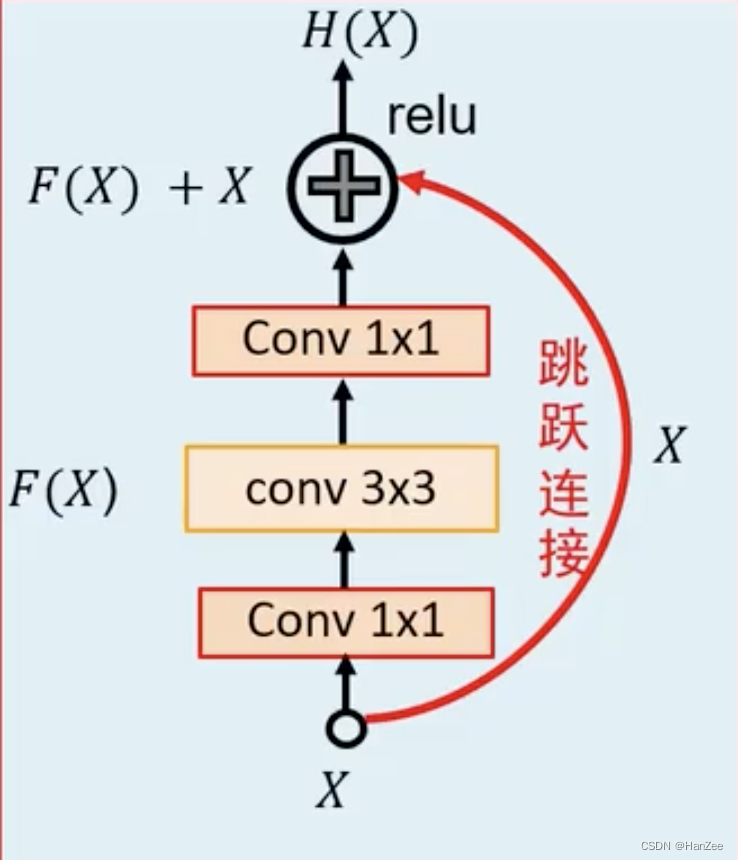
其中由于ReNet可以堆叠100多层,为了让控制计算量,采用1 * 1 卷积投影降低计算量。
反向传播公式推导

残差的由来

听过上面的图我们发现,卷积层就是F(x),而Fx= hx-x 也就是输出-输入,所以我们把这个模块也叫做残差模块。
残差模块为什么效果好
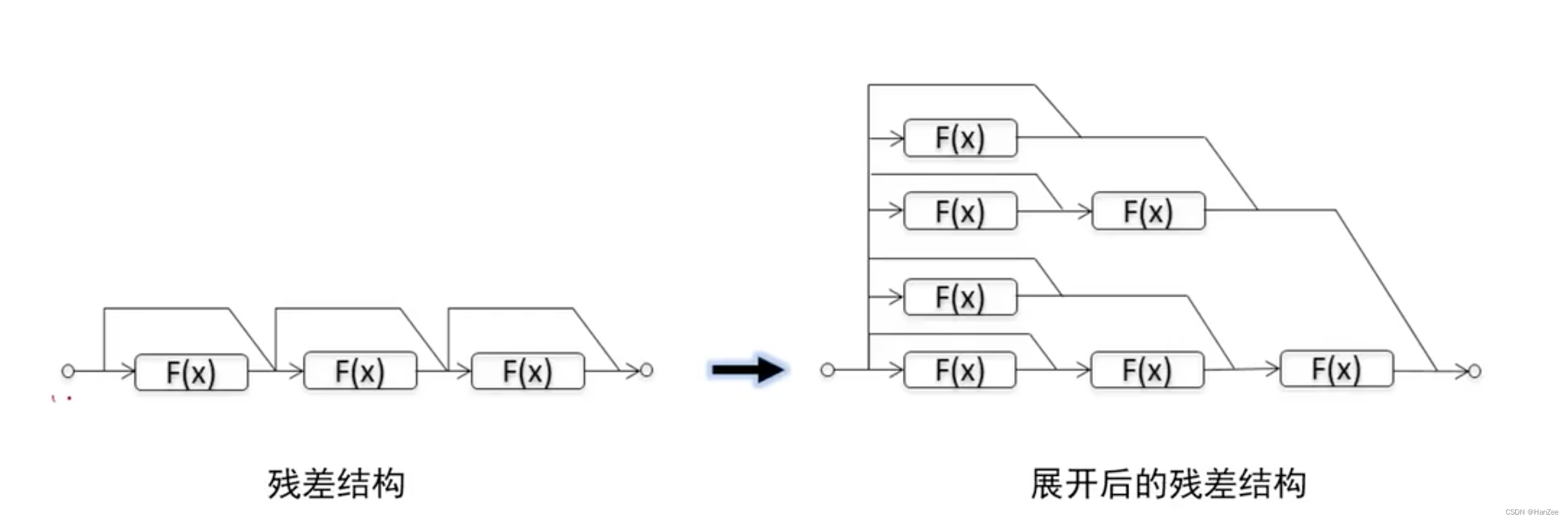
我们可以把残差结构看成一个集成网络,把它展开后,可以看成多个小的网络求和的结果,那么他的健壮性就很好,即使干掉其中一个,他也可以保持很好的效果。
代码实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)