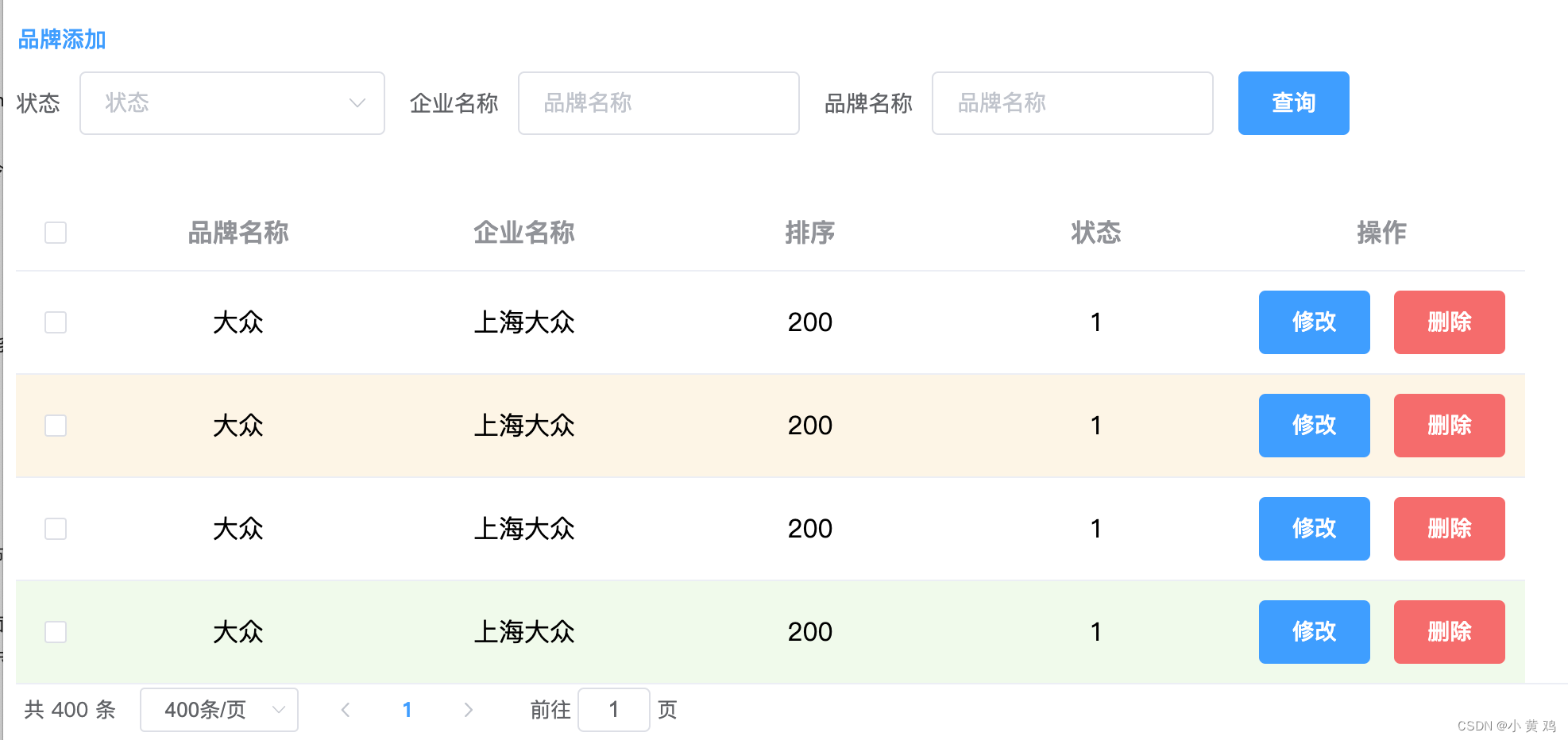
目录
1、什么是索引
2、索引的类型
3、为什么要用索引
4、索引的使用场景
5、索引为什么要用B+树,为什么不能用二叉树、红黑树、B树?
介绍一款可以帮助理解数据结构的网站(很好用):Data Structure Visualization
5.1 二叉查找树
5.2 红黑树(平衡二叉查找树)
5.3 B树
5.4 B+树
5.5 Hash
6、哪些情况索引会失效?
1、什么是索引
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。索引是针对表而建立的,它是由数据页面以外的索引页面组成的,每个索引页面中的行都会含有逻辑指针,以便加速检索物理数据。(百度定义)
索引(index)是帮助MySQL高效获取数据的数据结构。(MySQL官方)
通俗的讲索引就是一个目录,为了方便快速的查找书中内容,是一个文件,要在磁盘中占用物理空间的。
2、索引的类型
| 维度 | 索引名称 | 关键字 | 特点 | 索引介绍 |
| 逻辑维度 | 普通索引 | index | 可以多个 | 基本的索引类型,值可以为空,没有唯一性的限制。 |
| 唯一索引 | unique | 可以多个 | 索引列的所有值都只能出现一次,即必须唯一,值可以为空。 | |
| 主键索引 | primary | 默认自动创建,只能一个 | 主键是一种唯一性索引,但不能为空,但它必须指定为 PRIMARY KEY,每个表只能有一个主键。 | |
| 全文索引 | fulltext | 可以多个 | 全文索引的索引类型为FULLTEXT。 全文索引不支持中文需要借sphinx(coreseek)或迅搜<、code>技术处理中文。 | |
| 数据结构维度 | B+树索引 | 所有数据存储在叶子节点,复杂度为O(logn),适合范围查询。 | ||
| 哈希索引 | 适合等值查询,检索效率高,一次到位。 | |||
| 全文索引 | ||||
| R-Tree索引 | 用来对GIS数据类型创建SPATIAL索引 | |||
| 物理存储维度 | 聚集索引 | 以主键创建的索引,叶子节点上存储该表中的所有数据行记录。 | ||
| 非聚集索引 | 以非主键创建的索引,叶子节点存储的是主键和索引列。 |
聚集索引的优点:
查询通过聚集索引可以直接获取数据,相比非聚集索引需要第二次查询(非覆盖索引情况下)效率高
对范围查询效率很高,因为数据是按照大小排列的
适合排序的场景,非聚集索引不适合
聚集索引的缺点:
维护索引代价很高,特别插入新行或者更新主键导致导致页的分裂
如果主键是随机ID(比如UUID),导致存储稀疏(磁盘碎片),可能比全表扫描还慢,或者主键比较大,导致辅助索引变的很大(节点占用更多的物理空间),这也是建议自增id作为主键的根本原因
3、为什么要用索引
索引的目的是为了提高查询效率。如果没有索引就要a-z进行全表扫描。
4、索引的使用场景
4.1、主键自动建立唯一索引 Primary Key = Unique Key + Not Null
4.2、频繁作为查询条件的字段应该创建索引(银行系统的银行账号、电信系统的手机号)
4.3、查询中与其它表关联的字段,外键关系建立索引
4.4、查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
4.5、查询中统计或者分组字段
4.6、单值/组合索引的选择问题:在高并发下倾向创建组合索引 index(name,age,gender)
5、索引为什么要用B+树,为什么不能用二叉树、红黑树、B树?
介绍一款可以帮助理解数据结构的网站(很好用):Data Structure Visualization
5.1 二叉查找树
- 每个结点最多两个子树,分别称为左子树和右子树;
- 左子节点的值小于当前节点的值,右子节点的值大于当前节点值;
- 顶端的节点称为根节点,没有子节点的节点值称为叶子节点;
时间复杂度:平均 O ( log n ) 最坏情况下:O ( n ),会变成线性的二叉树
缺陷:
1.最坏情况下变成线性二叉树,时间复杂度变成O ( n )
2.在树查找时,每读取一次数据就会发生一次I/O,二叉树的深度越深,I/O的次数越多,而二叉树每个节点最多有两个孩子,若用二叉树作为索引,树的深度会很深,I/O性能消耗太大。
优化思考:把树的节点的数目增加,形成一个多叉树
5.2 红黑树(平衡二叉查找树)
- 每个节点只能是红色或黑色。
- 跟节点必须是黑色。
- 红色的节点,它的叶节点只能是黑色。
- 从任一节点到其叶子节点的所有路径都包含相同数目的黑色节点。
当数据插入时,红黑树通过旋转和变色来达到平衡。这样就弥补了二叉树退化成链表的尴尬
Q:为什么索引的数据结构不用红黑树?
因为当值依次递增插入时树的高度会变得特别高,效率会变得特别低。
时间复杂度为:O(log2N)
5.3 B树
- 一个节点可以有多个元素
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
Q:为什么索引的数据结构不用B树?
虽然B树相对于红黑树,树的高度降低了,但是随着数据量的增多,树的高度还是会变得很高,效率会变得特别低。而且对范围查找也不方便。
5.4 B+树
- 非叶子节点不存储data,只存储索引(冗余),可以放多个索引。
- 叶子节点包含所有的索引字段
- 叶子节点用指针连接,提高区间访问性能(注意是单向指针。)
Q:为什么B+树比B树更适合做索引(MySQL)
- 磁盘读写代价低:非叶子节点仅用来索引(这样能存更多的关键字),数据都保存在叶子节点中,相对与B树能存放更多的关键字,磁盘读写代价低(树的深度低,读的关键字更多)
- B+树的查询效率更加稳定,是稳定的O ( log n )
- B+树更有利于对数据库的扫描,如进行范围查询,在普通查询时性能也更好
Q:为什么innodb表必须有主键?
因为innodb表的索引结构是B+树,而B+树是基于索引来存储数据的。所有的数据全部保存在B+树的叶子节点
Q:如果没有主键会怎么样?
innodb引擎会查找并选择第一个没有null值的列,作为主键索引。如果没有,则会使用隐藏列作为主键。
Q:为什么推荐使用整形自增主键而不用uuid?
优点:
节约空间
插入效率高(由于B+树遵循左小右大,所以自增插入数据总是在最右侧插入。而uuid则不一定,如果页16k已经写满了,那只能把页中的数据向后移,在空位中插入。频繁的移动分页会造成碎片,后续需要使用OPTIMIZE TABLE来进行碎片整理)
Q:为什么非主键索引结构叶子节点存储的是主键值?
非主键索引存储主键值,是为了当数据变动时,不需要修改各非主键索引的值,只需修改主键索引叶子结点的数据即可。减少了重复操作,即提高性能。
5.5 Hash
特点:类似于HashMap
查询效率极高(比B+树还高),但不能作为主流索引
缺点:
- 只能用于对等值的查询,不能实现对范围的查询,即:仅能满足“=",“IN",不能使用范围查询
- 因为Hash是通过hash算法计算出的hash值进行查找,因为计算过后的hash值的大小顺序不能保证和原数据一致(还可能会有hash冲突),所以不能使用范围查找
- 不能用于对数据的排序操作(也是因为hash算法的原因)
- 对与组合索引,不能使用部分索引查询
- 因为计算组合索引hash值时,是对整个组合索引一起做hash运算,计算结果不能拆分(即,abc组合索引,使用ab无法命中索引)
- 不能避免全表扫面
- 不稳定:遇到大量Hash值相等的情况,性能并不一定比B+树高(甚至有可能变成线性结构–链表)
总结:MySQL索引结构采用B+树,有以下4个原因:

1)、从磁盘I/O效率方面来看:B+树的非叶子节点不存储数据,所以树的每一层就能够存储更多的索引数量,也就是说,B+树在层高相同的情况下,比B树的存储数据量更多,间接会减少磁盘I/O的次数。
2)、从范围查询效率方面来看:在MySQL中,范围查询是一个比较常用的操作,而B+树的所有存储在叶子节点的数据使用了双向链表来关联,所以B+树在查询的时候只需查两个节点进行遍历就行,而B树需要获取所有节点,因此,B+树在范围查询上效率更高。
3)、从全表扫描方面来看:因为,B+树的叶子节点存储所有数据,所以B+树的全局扫描能力更强一些,因为它只需要扫描叶子节点。而B树需要遍历整个树。
4)、从自增ID方面来看:基于B+树的这样一种数据结构,如果采用自增的整型数据作为主键,还能更好的避免增加数据的时候,带来叶子节点分裂导致的大量运算的问题。
6、哪些情况索引会失效?
(1):条件是or,如果还想让or条件生效,给or每个字段加个索引
(2):like开头%
(3):如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不会使用索引
(4):where中索引列使用了函数或有运算
(5):对于多列索引,不是使用的第一部分,则不会生效