目录
顺序存储和链式存储
数组—顺序存储
链表—链式存储
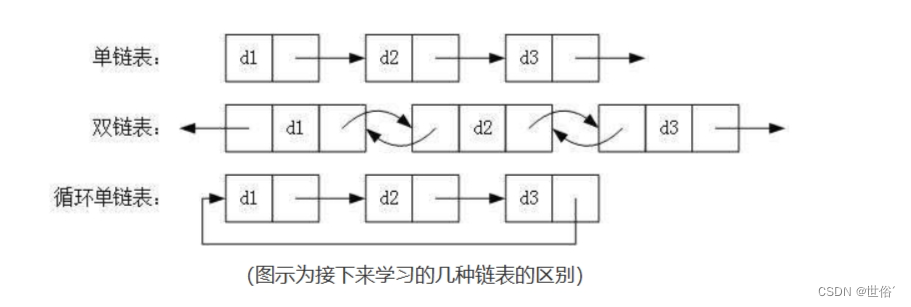
单链表
单链表的基本设计
单链表概念&设计
单链表的基本操作
双向链表
双向链表的基本设计
双向链表的基本操作
循环链表
循环链表的介绍及创建
循环链表的基本操作
顺序存储和链式存储
数组—顺序存储
数组是一种顺序存储结构,它是由相同类型的元素按照一定顺序排列而成的数据集合。在内存中,数组的元素是连续存储的,每个元素占据相同大小的内存空间。
在数组中,每个元素都可以通过下标来访问和操作,数组的下标从0开始,依次递增。通过下标,可以快速地定位到数组中的特定元素。
顺序存储的特点:
- 随机访问:由于数组元素在内存中是连续存储的,所以可以通过下标直接访问和修改任意位置的元素,具有较快的随机访问速度。
- 内存连续性:数组中的元素在内存中是连续存储的,这样可以提高数据的读取效率,减少对内存的访问次数。
- 固定大小:数组的大小在创建时就确定了,并且不能动态改变。如果需要存储更多的元素,就需要重新创建一个更大的数组,并将原数组的元素复制到新数组中。
顺序存储的优点:
- 高效的随机访问:由于数组的元素在内存中是连续存储的,可以通过下标直接访问任意位置的元素,具有很高的访问效率。
- 简单的内存管理:数组的内存分配和释放非常简单,只需要一次性分配一块连续的内存空间即可。
顺序存储的缺点:
- 大小固定:数组在创建时需要指定大小,且大小固定不变。如果需要存储的元素个数超过了数组的大小,就需要重新分配更大的数组,涉及到数据的复制和内存管理的问题。
- 插入和删除效率低:由于数组的大小固定,插入和删除元素时需要移动其他元素,导致效率较低。特别是在数组中间插入或删除元素时,需要移动后续元素的位置。
总结来说,数组是一种顺序存储结构,具有高效的随机访问和简单的内存管理等优点,但大小固定和插入删除效率低是其缺点。在使用数组时,需要根据实际需求权衡其优缺点,并选择合适的数据结构来存储和操作数据。
以C语言数组插入一个元素为例,当我们需要在一个数组{1,2,3,4,5,6,7}的第1个元素后(即第2个元素)的位置插入一个’A’时,我们需要做的有,将第1个元素后的整体元素后移,形成新的数组{1,2,2,3,4,5,6,7},再将第2个元素位置的元素替换为我们所需要的元素’A’,最终形成我们的预期,一个简单的插入操作要进行那么多的步骤,显然不是很核算。
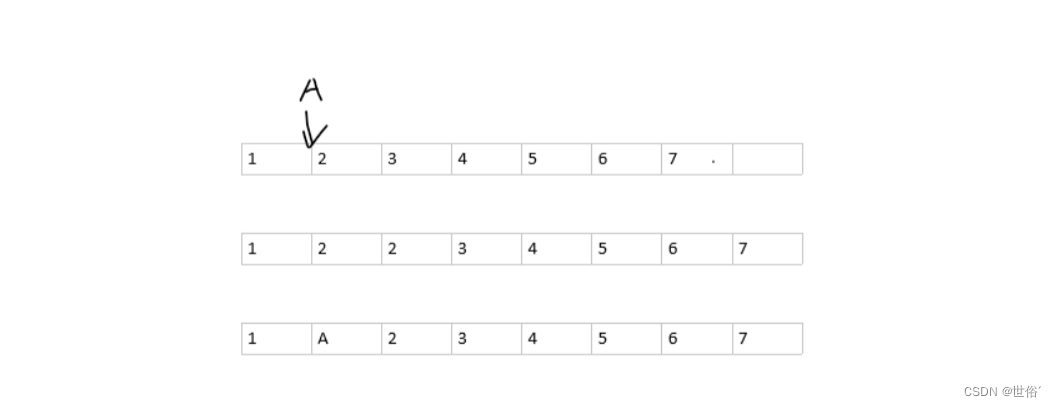
由示意图的操作,我们可以看出这样做的弊端
- 所需要移动的元素很多,浪费算力。
- 必须为数组开足够多的空间,否则有溢出风险。
链表—链式存储
C语言使用中,由于以上出现的这些问题,我们链表的概念就应运而生。
链表是一种常见的数据结构,它使用链式存储方式来组织和管理数据。相比于数组的顺序存储,链表通过使用指针将多个节点连接起来,每个节点包含数据和指向下一个节点的指针。
链表的基本组成部分是节点(Node),每个节点包含两个字段:数据域(Data)和指针域(Next)。数据域用于存储具体的数据,指针域用于指向下一个节点。最后一个节点的指针域通常为空(NULL)。
链表的特点:
- 动态性:链表的大小可以动态地增加或减少,不像数组大小固定。
- 灵活性:链表可以在任意位置插入或删除节点,而不需要像数组一样移动其他元素。
- 内存分配灵活:链表中的节点可以分散存储在内存中的不同位置,不要求连续的内存空间。
链表的优点:
- 插入和删除效率高:由于链表的动态性和灵活性,插入和删除节点时只需要修改指针的指向,不需要移动其他元素,因此效率较高。
- 空间利用率高:链表中的节点可以根据实际需要动态分配内存,避免了固定大小的内存浪费。
链表的缺点:
- 随机访问效率低:由于链表中的节点不是连续存储的,不能通过下标直接访问元素,需要从头节点开始遍历链表才能找到目标节点,因此随机访问效率较低。
- 额外的内存空间开销:链表中每个节点都需要额外的指针域来存储下一个节点的地址,增加了内存空间的开销。
下面是一个简单的链表示例代码,实现了对一组整数进行逆序存储和打印的功能:
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构体
typedef struct Node {
int data; // 数据域
struct Node* next; // 指针域,指向下一个节点
} Node;
// 在链表头部插入新节点
void insertAtHead(Node** head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = *head;
*head = newNode;
}
// 打印链表
void printLinkedList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
int main() {
Node* head = NULL; // 链表头节点初始化为空
insertAtHead(&head, 3);
insertAtHead(&head, 2);
insertAtHead(&head, 1);
printf("Linked List: ");
printLinkedList(head);
return 0;
}
上述代码中,定义了一个链表节点结构体Node,包含数据域data和指针域next。通过insertAtHead函数,在链表头部插入新节点,该函数接受一个指向头节点的指针,并在头节点之前插入新节点。printLinkedList函数用于打印链表中的所有元素。
在main函数中,首先创建一个空链表(头节点为NULL),然后调用insertAtHead函数插入三个节点,最后调用printLinkedList函数打印链表中的元素。
输出结果为:
Linked List: 1 2 3
这个示例展示了链表的基本操作,包括在头部插入节点和打印链表。通过指针的指向,可以将多个节点连接起来形成一个链表,并可以方便地进行插入、删除等操作。
接下来会依次给各位介绍:单链表,双链表,循环单链表,其功能不同但实现方式均大同小异。
单链表
单链表的基本设计
单链表概念&设计
单链表是一种常见的链表结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。单链表中的每个节点只有一个指针域,指向下一个节点,而最后一个节点的指针域为空(NULL)。
单链表的基本设计包括以下几个要素:
1、节点定义:定义一个节点结构体,包含数据域和指针域。例如,在C语言中可以使用如下方式定义节点:
typedef struct Node {
int data; // 数据域
struct Node* next; // 指针域,指向下一个节点
} Node;
2、头节点:单链表通常有一个头节点,它是链表的入口,用于指示链表的起始位置。头节点不存储实际的数据,它的指针域指向第一个真正存储数据的节点。头节点的作用是方便对链表的操作和管理。
3、创建链表:创建一个空链表时,需要初始化头节点,并将头节点的指针域置为空。例如,在C语言中可以使用如下方式创建空链表:
Node* head = (Node*)malloc(sizeof(Node));
head->next = NULL;
4、插入节点:在链表中插入新节点时,需要修改指针的指向,使得新节点插入到正确的位置。常见的插入方式有在链表头部插入和在链表尾部插入。在链表头部插入节点时,只需要将新节点的指针域指向原来的头节点,并将头节点指向新节点。在链表尾部插入节点时,需要找到最后一个节点,然后将最后一个节点的指针域指向新节点。
5、删除节点:删除链表中的节点时,需要修改前一个节点的指针域,使其指向被删除节点的下一个节点。然后释放被删除节点的内存空间。
6、遍历链表:遍历链表是指依次访问链表中的每个节点,可以通过指针的指向逐个遍历节点。常见的遍历方式是使用循环,从头节点开始,依次访问每个节点的数据域,并将指针移动到下一个节点,直到指针为空(到达链表末尾)。
这些是单链表的基本设计要素。通过合理地操作节点和指针的指向,可以实现对链表的插入、删除、查找等操作。在实际应用中,还可以根据需要扩展链表的功能,例如实现按索引访问节点、反转链表等操作。
单链表的基本操作
单链表的基本操作包括插入、删除和查找等操作。下面我将介绍这些基本操作的实现方法:
1、插入操作:
- 在头部插入节点:创建一个新节点,将新节点的指针域指向原头节点,然后将头节点指向新节点。
- 在尾部插入节点:遍历链表,找到最后一个节点,将最后一个节点的指针域指向新节点。
如图,在DATA1和DATA2数据结点之中插入一个NEW_DATA数据结点:
从原来的链表状态

到新的链表状态:

2、删除操作:
- 删除指定节点:遍历链表,找到要删除的节点的前一个节点,将前一个节点的指针域指向要删除节点的下一个节点,然后释放要删除节点的内存空间。
- 删除头节点:将头节点指向头节点的下一个节点,并释放原头节点的内存空间。
- 删除尾节点:遍历链表,找到倒数第二个节点,将其指针域置为空,然后释放最后一个节点的内存空间。
参考如图

3、查找操作:
- 按值查找:从头节点开始遍历链表,比较每个节点的数据域与目标值,直到找到匹配的节点或遍历到链表末尾。
- 按索引查找:从头节点开始遍历链表,依次移动指针,直到达到指定索引位置的节点。
4、遍历操作:
- 使用循环:从头节点开始,依次访问每个节点的数据域,并将指针移动到下一个节点,直到指针为空(到达链表末尾)。
需要注意的是,在进行插入和删除操作时,要确保链表的指针连接正确,避免出现内存泄漏或指针丢失的情况。
以下是一个简单示例代码,展示了单链表的基本操作:
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data; // 数据域
struct Node* next; // 指针域,指向下一个节点
} Node;
// 在头部插入节点
void insertAtHead(Node** head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = *head;
*head = newNode;
}
// 在尾部插入节点
void insertAtTail(Node** head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
if (*head == NULL) {
*head = newNode;
} else {
Node* current = *head;
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
}
}
// 删除指定节点
void deleteNode(Node** head, int data) {
Node* current = *head;
Node* prev = NULL;
if (current != NULL && current->data == data) {
*head = current->next;
free(current);
return;
}
while (current != NULL && current->data != data) {
prev = current;
current = current->next;
}
if (current == NULL) {
return;
}
prev->next = current->next;
free(current);
}
// 查找节点
Node* searchNode(Node* head, int data) {
Node* current = head;
while (current != NULL) {
if (current->data == data) {
return current;
}
current = current->next;
}
return NULL;
}
// 遍历链表
void printLinkedList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
int main() {
Node* head = NULL;
insertAtHead(&head, 3);
insertAtHead(&head, 2);
insertAtHead(&head, 1);
printf("Linked List: ");
printLinkedList(head);
insertAtTail(&head, 4);
insertAtTail(&head, 5);
printf("Linked List after inserting at tail: ");
printLinkedList(head);
deleteNode(&head, 3);
printf("Linked List after deleting node with value 3: ");
printLinkedList(head);
Node* foundNode = searchNode(head, 4);
if (foundNode != NULL) {
printf("Found node with value 4\n");
} else {
printf("Node with value 4 not found\n");
}
return 0;
}
上述代码中,定义了节点结构体Node,并实现了在头部插入节点、在尾部插入节点、删除节点、查找节点和遍历链表等操作。在main函数中,演示了对链表的插入、删除、查找和遍历操作。
输出结果为:
Linked List: 1 2 3
Linked List after inserting at tail: 1 2 3 4 5
Linked List after deleting node with value 3: 1 2 4 5
Found node with value 4
这个示例展示了单链表的基本操作,通过合理地操作指针和节点,可以实现对链表的增删查改等功能。
双向链表
双向链表的基本设计
双向链表的简介&概念
双向链表(Doubly Linked List)是一种常见的链表数据结构,与单向链表相比,每个节点除了包含指向下一个节点的指针外,还包含指向前一个节点的指针。
在双向链表中,每个节点都有两个指针,一个指向前一个节点,一个指向后一个节点。这使得在双向链表中可以方便地进行双向遍历和插入/删除操作。

一个完整的双向链表应该是头结点的pre指针指为空,尾结点的next指针指向空,其余结点前后相链。
双向链表的结点设计
对于每一个结点而言,
+------+ +------+ +------+
| | | | | |
| prev |<--->| data |<--->| next |
| | | | | |
+------+ +------+ +------+
其中,prev表示指向前一个节点的指针,data表示节点存储的数据,next表示指向后一个节点的指针。
双向链表的优点包括:
- 可以双向遍历:由于每个节点都有指向前一个节点和后一个节点的指针,因此可以方便地从头到尾或从尾到头遍历链表。
- 方便插入和删除操作:在双向链表中,插入和删除节点时只需要修改相邻节点的指针,不需要像单向链表那样要找到待操作节点的前一个节点。
- 更灵活:相比于单向链表,双向链表的操作更加灵活,可以更方便地处理一些特定的问题。
然而,双向链表也有一些缺点:
- 占用更多内存:由于每个节点都需要额外存储指向前一个节点的指针,相比于单向链表会占用更多的内存空间。
- 需要更多的指针操作:在插入和删除节点时,需要同时修改前一个节点和后一个节点的指针,相对于单向链表需要更多的指针操作。
总的来说,双向链表在某些场景下可以提供更好的操作灵活性和效率,但也需要权衡其占用的额外内存空间和指针操作的复杂性。
双向链表的基本操作
1、定义节点结构体:
typedef struct Node {
int data; // 数据域
struct Node* prev; // 指向前一个节点的指针
struct Node* next; // 指向后一个节点的指针
} Node;
节点结构体中包含数据域以及指向前一个节点和后一个节点的指针。
2、创建双向链表:
Node* createLinkedList() {
Node* head = (Node*)malloc(sizeof(Node));
head->prev = NULL;
head->next = NULL;
return head;
}
创建一个空的双向链表,返回头节点的指针。
3、在双向链表的末尾插入节点:
void insertAtEnd(Node* head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
Node* current = head;
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
newNode->prev = current;
}
遍历链表找到最后一个节点,然后将新节点插入到最后一个节点之后。
4、在双向链表的指定位置插入节点:
void insertAtPosition(Node* head, int data, int position) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
Node* current = head;
int count = 0;
while (current != NULL && count < position) {
current = current->next;
count++;
}
if (current == NULL) {
printf("Invalid position\n");
return;
}
newNode->next = current;
newNode->prev = current->prev;
current->prev->next = newNode;
current->prev = newNode;
}
在双向链表的指定位置插入新节点。需要遍历链表找到指定位置的节点,然后更新相邻节点的指针,将新节点插入到两个节点之间。
5、删除双向链表中的节点:
void deleteNode(Node* head, int data) {
Node* current = head->next;
while (current != NULL) {
if (current->data == data) {
current->prev->next = current->next;
if (current->next != NULL) {
current->next->prev = current->prev;
}
free(current);
break;
}
current = current->next;
}
}
遍历链表找到要删除的节点,然后更新相邻节点的指针,跳过待删除的节点,并释放其内存空间。
6、遍历双向链表:
void printLinkedList(Node* head) {
Node* current = head->next;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
遍历链表,从头节点的下一个节点开始,依次输出每个节点的数据。
7、释放内存:
void freeLinkedList(Node* head) {
Node* current = head->next;
while (current != NULL) {
Node* temp = current;
current = current->next;
free(temp);
}
free(head);
}
在不再需要双向链表时,需要释放所有节点的内存空间,包括头节点。
以上是双向链表的基本操作,可以通过这些操作实现对双向链表的创建、插入、删除和遍历等功能。需要注意的是,在使用完毕后,要记得释放双向链表的内存空间,以防止内存泄漏。
循环链表
循环链表的介绍及创建
循环链表是一种特殊的链表数据结构,它与普通链表的区别在于,循环链表的尾节点指向头节点,形成一个循环的结构。这意味着在循环链表中,任何一个节点都可以作为起点开始遍历整个链表。
C语言中的循环链表可以通过以下方式进行创建和操作:
首先,我们需要定义循环链表的节点结构:
struct Node {
int data;
struct Node* next;
};
接下来,我们可以实现创建循环链表的函数:
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = NULL;
return newNode;
}
void createCircularLinkedList(struct Node** headRef, int data) {
struct Node* newNode = createNode(data);
if (*headRef == NULL) {
*headRef = newNode;
newNode->next = *headRef; // 将尾节点指向头节点,形成循环
} else {
struct Node* temp = *headRef;
while (temp->next != *headRef) { // 找到尾节点
temp = temp->next;
}
temp->next = newNode;
newNode->next = *headRef; // 将新节点插入到尾节点后面,并将尾节点指向头节点
}
}
以上代码中,createNode函数用于创建一个新的节点,并返回该节点的指针。createCircularLinkedList函数用于创建循环链表,它接受一个指向头节点的指针和要插入的数据作为参数。如果链表为空,则将新节点设置为头节点,并将尾节点指向头节点,形成循环。否则,找到尾节点,将新节点插入到尾节点后面,并更新尾节点的指针。
下面是一个示例,展示如何使用上述函数创建一个包含三个节点的循环链表:
int main() {
struct Node* head = NULL;
createCircularLinkedList(&head, 1);
createCircularLinkedList(&head, 2);
createCircularLinkedList(&head, 3);
// 遍历循环链表并打印节点的值
struct Node* current = head;
do {
printf("%d ", current->data);
current = current->next;
} while (current != head);
return 0;
}
运行上述代码,将输出循环链表中每个节点的值:1 2 3。注意,我们使用了do-while循环来确保至少执行一次循环,即使链表为空。
通过上述方式,我们可以创建和操作循环链表。循环链表的特性使得在某些场景下更加方便,例如循环遍历和实现循环队列等。
循环链表的基本操作
循环链表是一种特殊的链表,它与普通链表不同的地方在于,循环链表的尾节点指向头节点,形成一个环。因此,循环链表可以通过任何一个节点遍历整个链表。
C语言中循环链表的基本操作包括插入、删除和遍历等。下面我们将详细介绍这些操作:
1、插入节点:在循环链表中插入一个新节点,可以在头部插入、尾部插入或者指定位置插入。
在头部插入节点:
void insertAtBeginning(struct Node** headRef, int data) {
struct Node* newNode = createNode(data);
if (*headRef == NULL) {
*headRef = newNode;
newNode->next = *headRef; // 将尾节点指向头节点,形成循环
} else {
struct Node* last = *headRef;
while (last->next != *headRef) {
last = last->next;
}
newNode->next = *headRef;
*headRef = newNode;
last->next = *headRef;
}
}
在尾部插入节点:
void insertAtEnd(struct Node** headRef, int data) {
struct Node* newNode = createNode(data);
if (*headRef == NULL) {
*headRef = newNode;
newNode->next = *headRef; // 将尾节点指向头节点,形成循环
} else {
struct Node* last = *headRef;
while (last->next != *headRef) {
last = last->next;
}
last->next = newNode;
newNode->next = *headRef;
}
}
在指定位置插入节点:
void insertAtPosition(struct Node** headRef, int data, int position) {
if (position < 0) {
printf("Invalid position\n");
return;
}
if (position == 0) {
insertAtBeginning(headRef, data);
return;
}
struct Node* newNode = createNode(data);
struct Node* current = *headRef;
int count = 0;
while (count < position - 1 && current->next != *headRef) {
current = current->next;
count++;
}
if (count < position - 1) {
printf("Invalid position\n");
return;
}
newNode->next = current->next;
current->next = newNode;
}
2、删除节点:从循环链表中删除一个节点,可以根据节点值、位置或者指定条件进行删除。
根据节点值删除节点:
void deleteNode(struct Node** headRef, int key) {
if (*headRef == NULL) {
printf("List is empty\n");
return;
}
struct Node* current = *headRef;
struct Node* prev = NULL;
while (current->data != key && current->next != *headRef) {
prev = current;
current = current->next;
}
if (current->data != key) {
printf("Node not found\n");
return;
}
if (current == *headRef) {
*headRef = current->next;
}
if (prev != NULL) {
prev->next = current->next;
}
free(current);
}
根据位置删除节点:
void deleteAtPosition(struct Node** headRef, int position) {
if (*headRef == NULL) {
printf("List is empty\n");
return;
}
if (position < 0) {
printf("Invalid position\n");
return;
}
if (position == 0) {
struct Node* last = *headRef;
while (last->next != *headRef) {
last = last->next;
}
struct Node* temp = *headRef;
*headRef = (*headRef)->next;
last->next = *headRef;
free(temp);
return;
}
struct Node* current = *headRef;
struct Node* prev = NULL;
int count = 0;
while (count < position && current->next != *headRef) {
prev = current;
current = current->next;
count++;
}
if (count < position) {
printf("Invalid position\n");
return;
}
prev->next = current->next;
free(current);
}
3、遍历循环链表:遍历并输出循环链表中的所有节点。
void traverseCircularLinkedList(struct Node* head) {
if (head == NULL) {
printf("List is empty\n");
return;
}
struct Node* current = head;
do {
printf("%d ", current->data);
current = current->next;
} while (current != head);
}




![buuctf_练[CSCCTF 2019 Qual]FlaskLight](https://img-blog.csdnimg.cn/img_convert/db29190ba10110be7c884fcb85b13bc4.png)

![[SQL开发笔记]UPDATE 语句:更新表中的记录](https://img-blog.csdnimg.cn/ba6f4824fbc5486c91701db622da136c.png)