=========================================================================
相关代码gitee自取:
C语言学习日记: 加油努力 (gitee.com)
=========================================================================
接上期:
【数据结构初阶】九、排序的讲解和实现(直接插入 \ 希尔 \ 直接选择 \ 堆 \ 冒泡 -- C语言)-CSDN博客
=========================================================================
常见排序算法的实现(续上期)
(详细解释在图片的注释中,代码分文件放下一标题处)
三、交换排序
基本思想:
所谓交换,就是根据序列中两个记录键值的比较结果来交换这两个记录在序列中的位置
交换排序的特点
将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动
交换排序 -- 快速排序
该算法基本思想:
- 快速排序是Hoare(霍尔)于1962年提出的一种二叉树结构的交换排序方法
- 其基本思想为:
任取待排序元素序列中的某元素作为基准值(key值),
按照该基准值(key值)将待排序集合分割成两个子序列(子区间),
左子序列(左子区间)中所有元素均小于基准值(key值),
右子序列(右子区间)中所有元素均大于基准值(key值),
然后当前左右子序列(子区间)再重复上述过程,
直到所有元素都排列在相应位置上为止
- 上述为快速排序递归实现的主框架,可以发现其过程与二叉树前序遍历规则非常像,
在写递归框架时可参考二叉树前序遍历规则,
后续只需分析如何按照基准值(key值)来对区间中数据进行划分的方式即可
- 将区间按照基准值(key值)划分为左右两半部分的常见方式有:
hoare版本(原始版本)快速排序 、 挖坑法快速排序 、前后指针版本快速排序
快速排序的特性总结:
快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
该算法时间复杂度:O(N*logN)
该算法空间复杂度:O(logN)
该算法稳定性:不稳定
---------------------------------------------------------------------------------------------
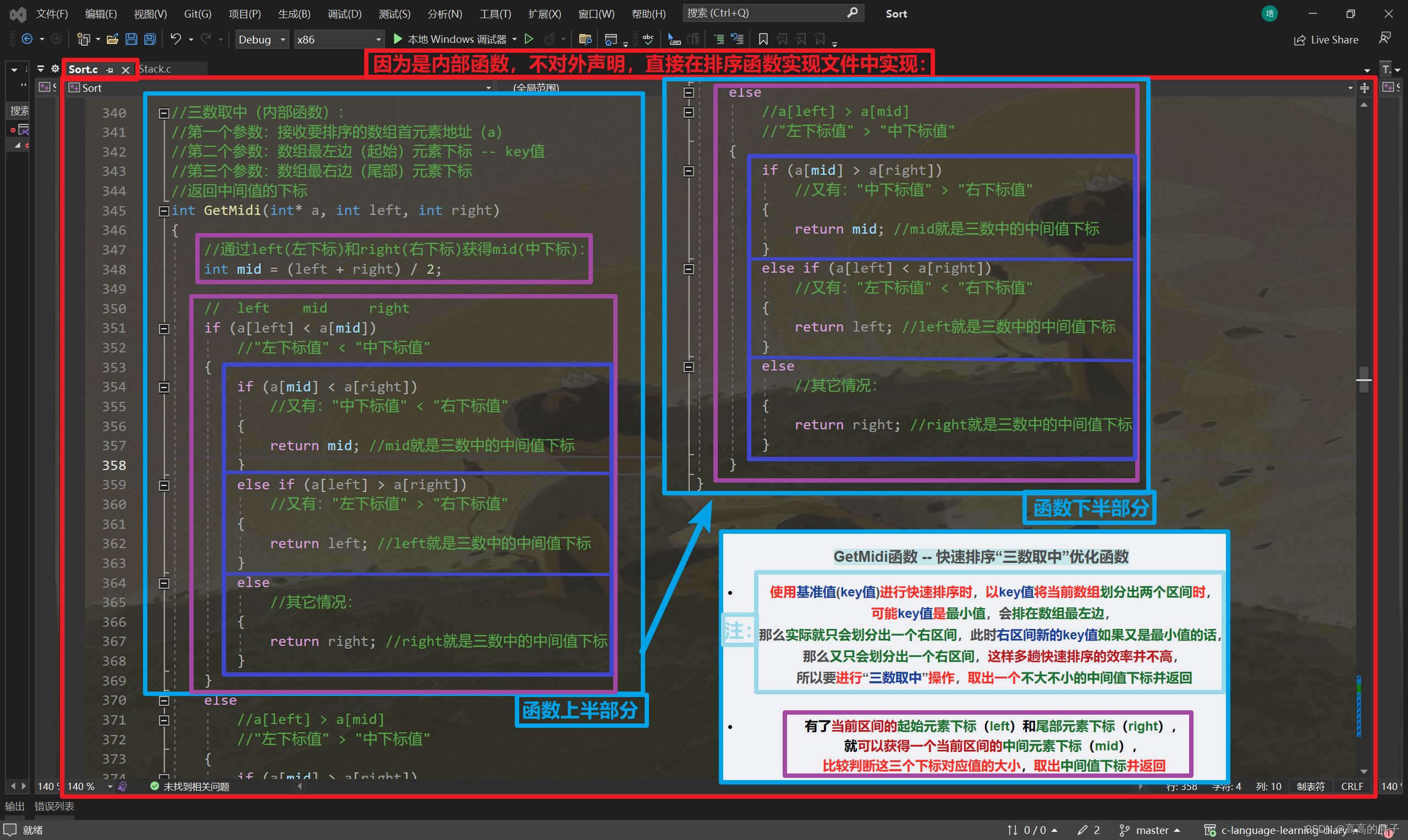
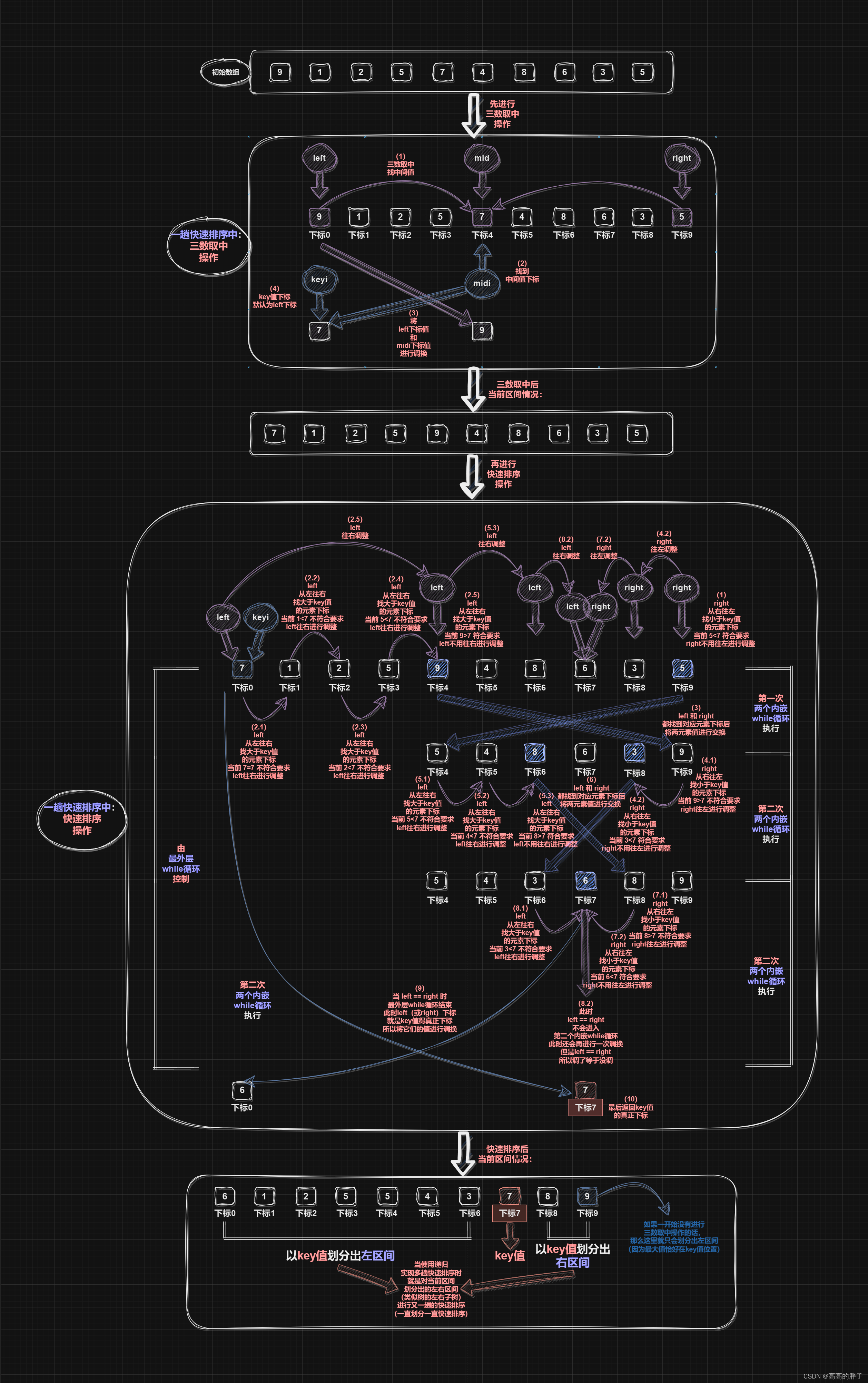
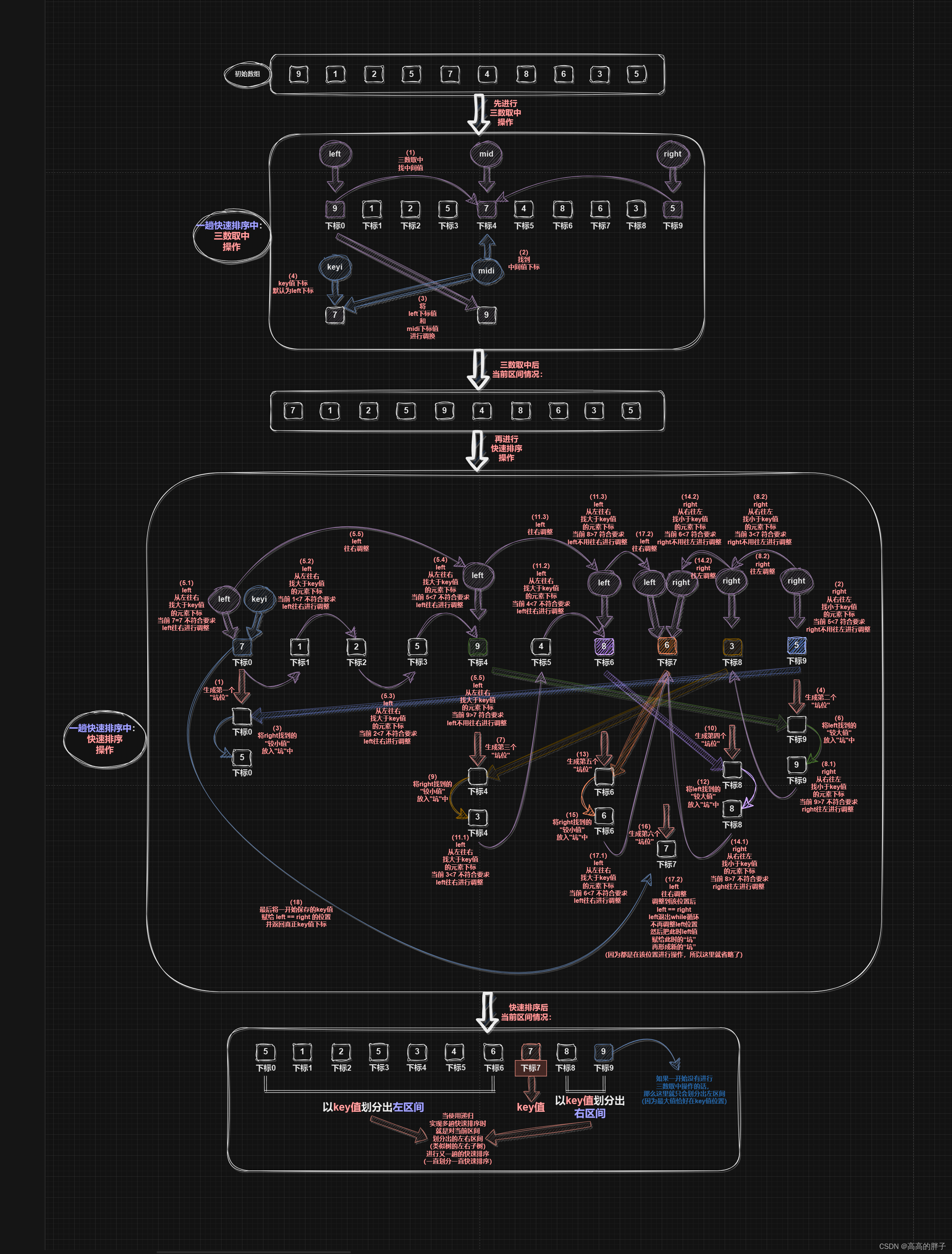
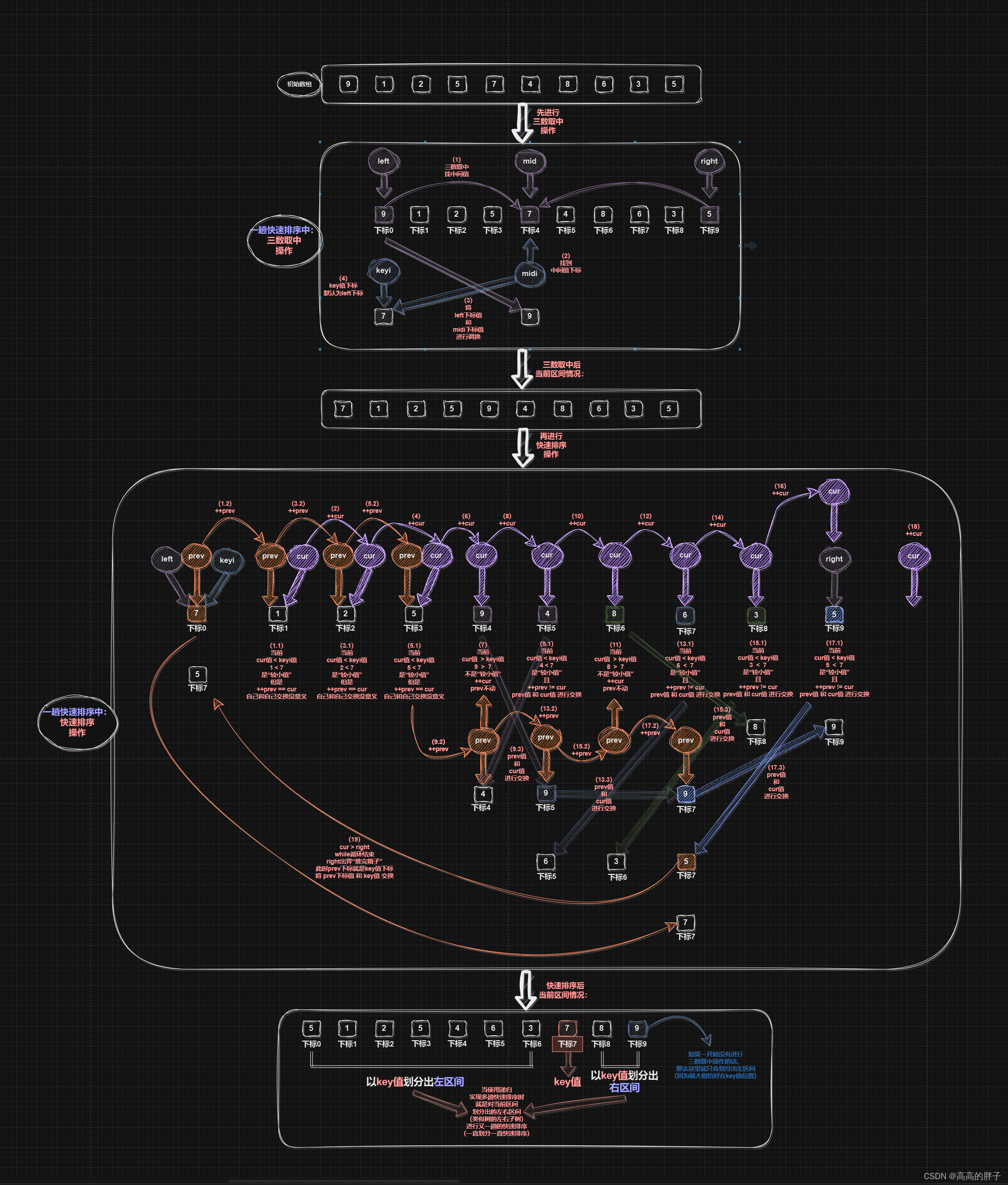
GetMidi内部函数 -- 快速排序“三数取中”优化函数
使用基准值(key值)进行快速排序时,以key值将当前数组划分出两个区间时,
可能key值是最小值,会排在数组最左边,
那么实际就只会划分出一个右区间,此时右区间新的key值如果又是最小值的话,
那么又只会划分出一个右区间,这样多趟快速排序的效率并不高,
所以要进行“三数取中”操作,取出一个不大不小的中间值下标并返回
- 有了当前区间的起始元素下标(left)和尾部元素下标(right),
就可以获得一个当前区间的中间元素下标(mid),
比较判断这三个下标对应值的大小,取出中间值下标并返回图示:
---------------------------------------------------------------------------------------------
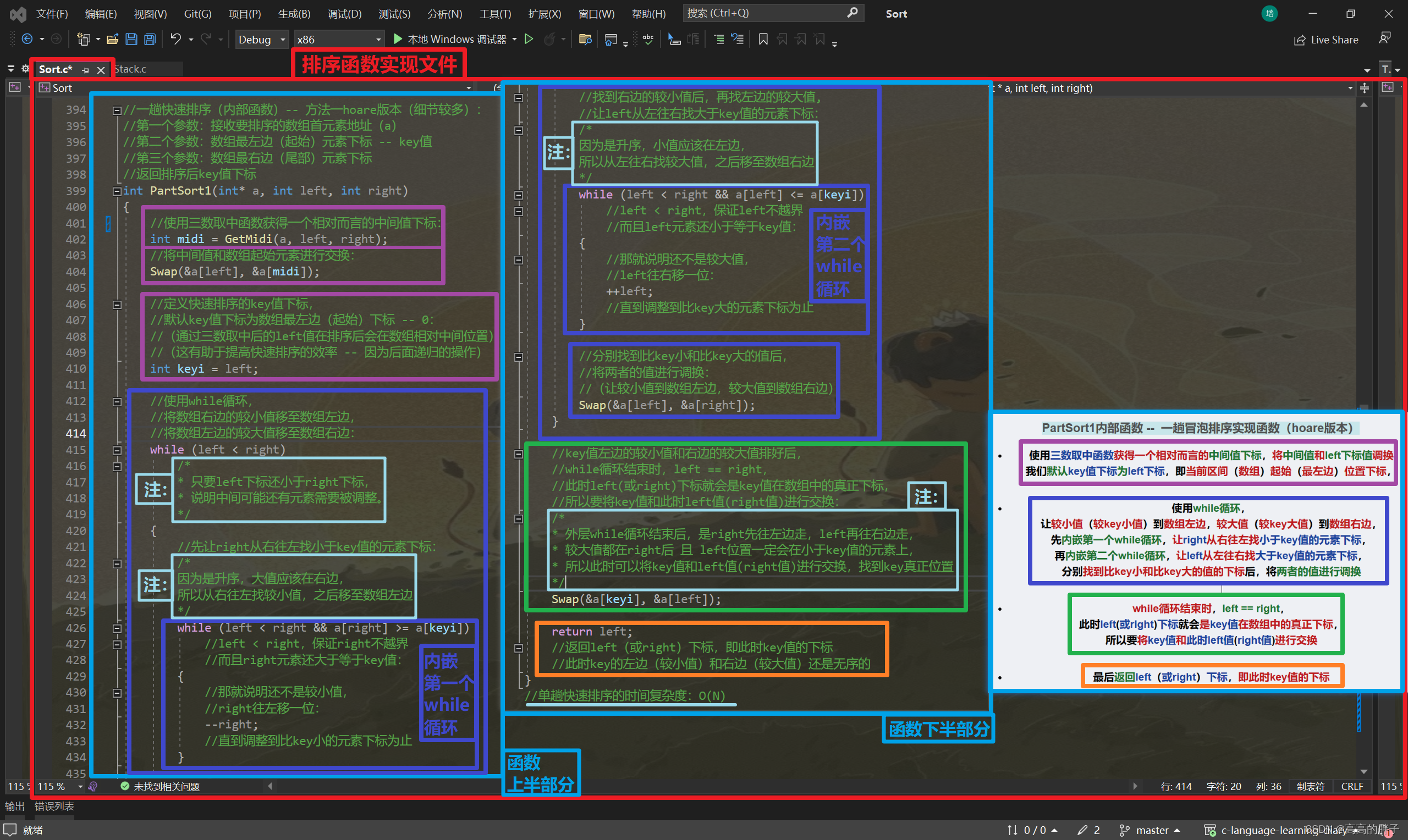
PartSort1内部函数 -- 一趟冒泡排序实现函数(hoare版本)
- 使用三数取中函数获得一个相对而言的中间值下标,将中间值和left下标值调换,
我们默认key值下标为left下标,即当前区间(数组)起始(最左边)位置下标,
- 使用while循环,
让较小值(较key小值)到数组左边,较大值(较key大值)到数组右边,
先内嵌第一个while循环,让right从右往左找小于key值的元素下标,
再内嵌第二个while循环,让left从左往右找大于key值的元素下标,
分别找到比key小和比key大的值的下标后,将两者的值进行调换
- while循环结束时,left == right,
此时left(或right)下标就会是key值在数组中的真正下标,
所以要将key值和此时left值(right值)进行交换
- 最后返回left(或right)下标,即此时key值的下标
图示:
该函数执行逻辑图:
---------------------------------------------------------------------------------------------
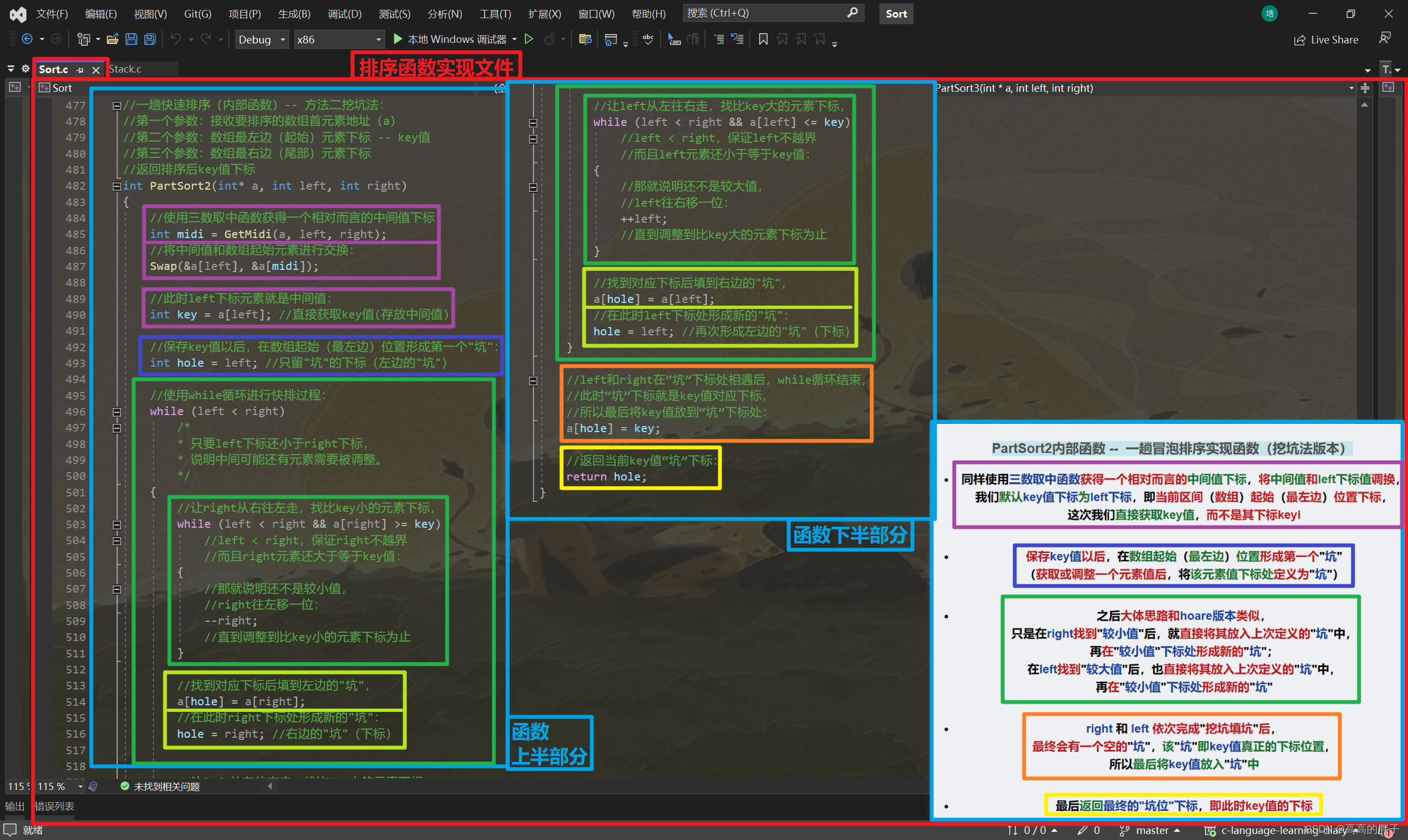
PartSort2内部函数 -- 一趟冒泡排序实现函数(挖坑法版本)
- 同样使用三数取中函数获得一个相对而言的中间值下标,将中间值和left下标值调换,
我们默认key值下标为left下标,即当前区间(数组)起始(最左边)位置下标,
这次我们直接获取key值,而不是其下标keyi
- 保存key值以后,在数组起始(最左边)位置形成第一个"坑"
(获取或调整一个元素值后,将该元素值下标处定义为"坑")
- 之后大体思路和hoare版本类似,
只是在right找到"较小值"后,就直接将其放入上次定义的"坑"中,
再在"较小值"下标处形成新的"坑";
在left找到"较大值"后,也直接将其放入上次定义的"坑"中,
再在"较小值"下标处形成新的"坑"
- right 和 left 依次完成"挖坑填坑"后,
最终会有一个空的"坑",该"坑"即key值真正的下标位置,
所以最后将key值放入"坑"中
- 最后返回最终的"坑位"下标,即此时key值的下标
图示:
该函数执行逻辑图:
---------------------------------------------------------------------------------------------
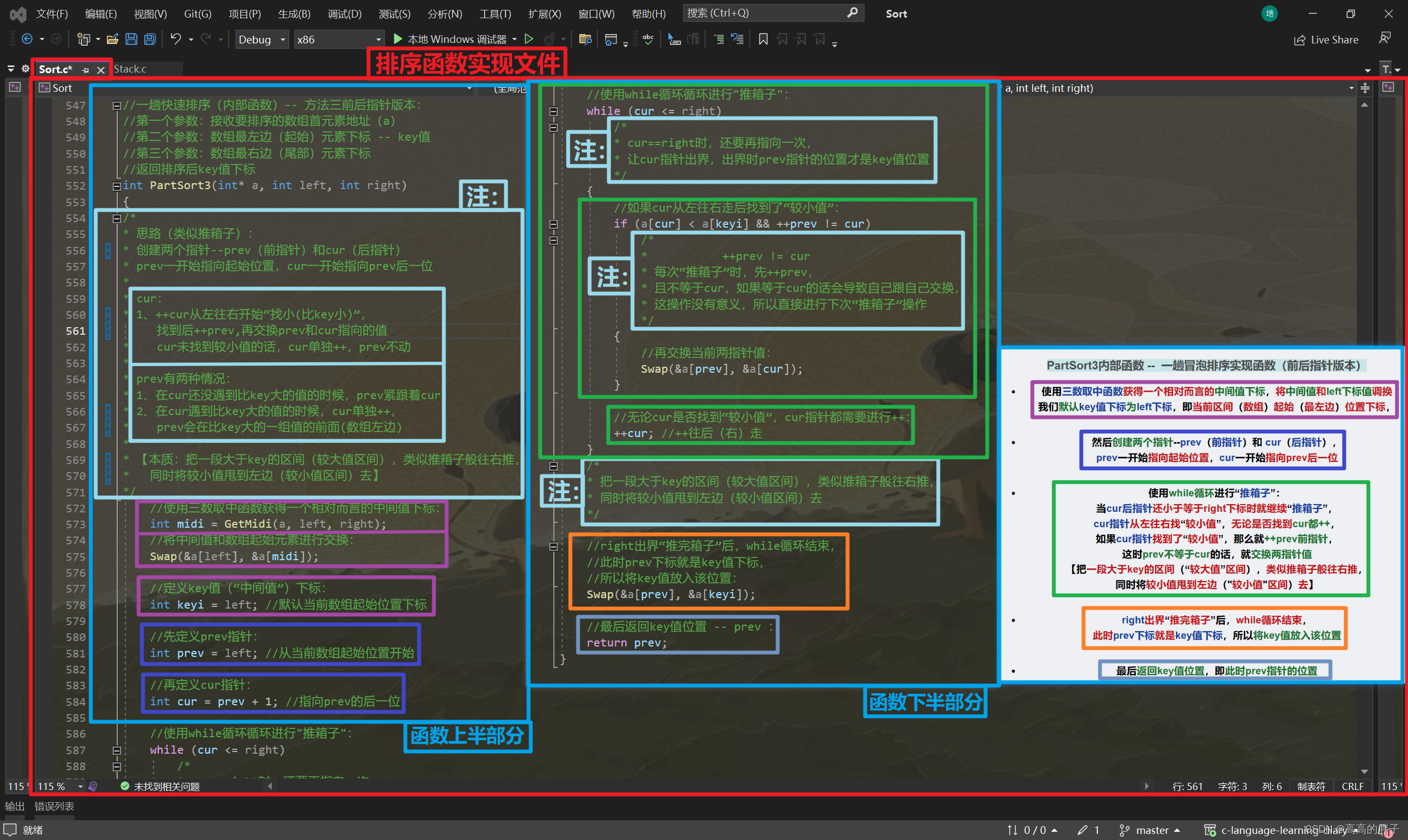
PartSort3内部函数 -- 一趟冒泡排序实现函数(前后指针版本)
- 使用三数取中函数获得一个相对而言的中间值下标,将中间值和left下标值调换
我们默认key值下标为left下标,即当前区间(数组)起始(最左边)位置下标,
- 然后创建两个指针--prev(前指针)和 cur(后指针),
prev一开始指向起始位置,cur一开始指向prev后一位
- 使用while循环进行“推箱子”:
当cur后指针还小于等于right下标时就继续“推箱子”,
cur指针从左往右找“较小值”,无论是否找到cur都++,
如果cur指针找到了“较小值”,那么就++prev前指针,
这时prev不等于cur的话,就交换两指针值
【把一段大于key的区间(“较大值”区间),类似推箱子般往右推,
同时将较小值甩到左边("较小值"区间)去】
- right出界“推完箱子”后,while循环结束,
此时prev下标就是key值下标,所以将key值放入该位置
- 最后返回key值位置,即此时prev指针的位置
图示:
该函数执行逻辑图:
---------------------------------------------------------------------------------------------
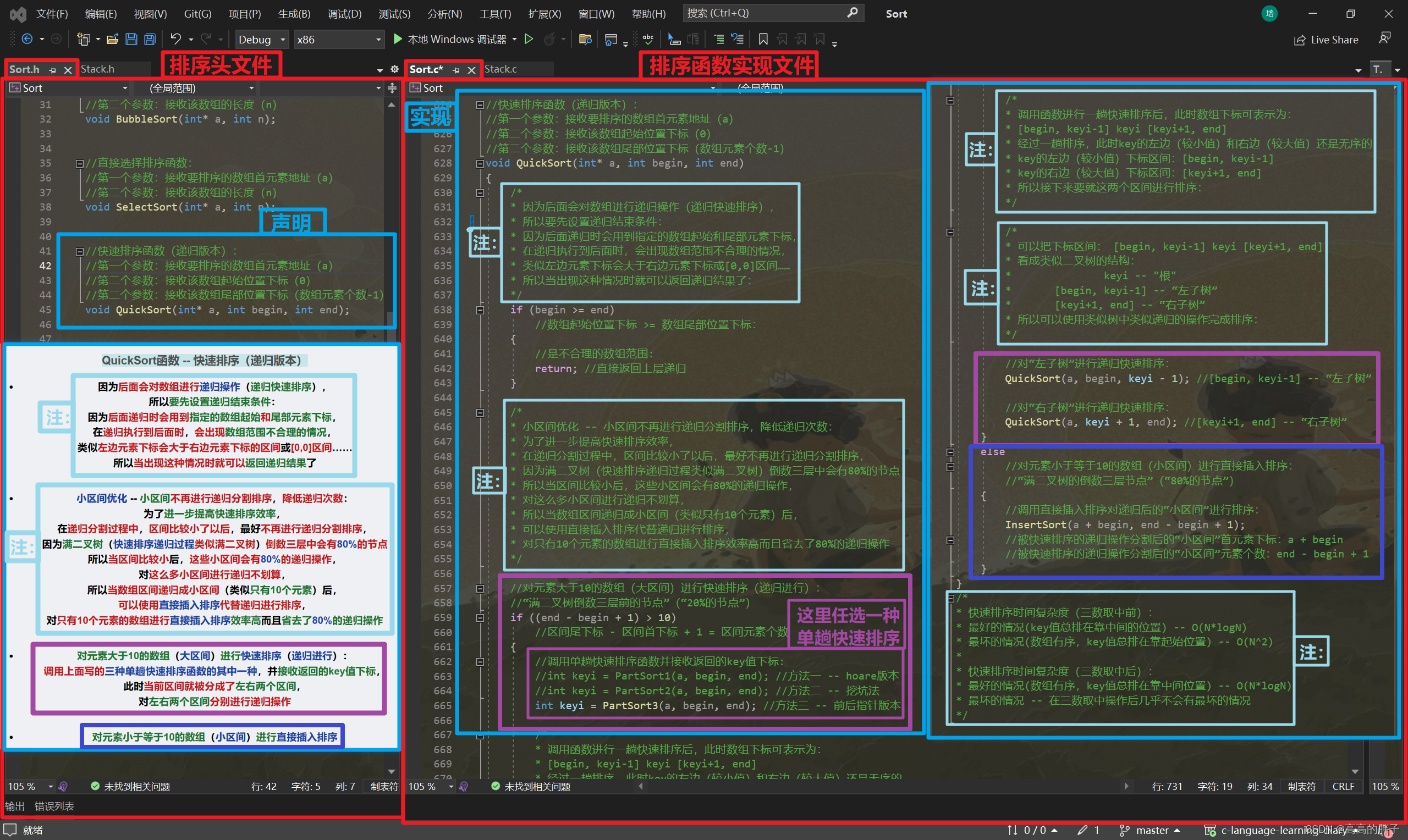
QuickSort函数 -- 快速排序(递归版本)
- 因为后面会对数组进行递归操作(递归快速排序),
所以要先设置递归结束条件:
因为后面递归时会用到指定的数组起始和尾部元素下标,
在递归执行到后面时,会出现数组范围不合理的情况,
类似左边元素下标会大于右边元素下标的区间或[0,0]区间……
所以当出现这种情况时就可以返回递归结果了
- 小区间优化 -- 小区间不再进行递归分割排序,降低递归次数:
为了进一步提高快速排序效率,
在递归分割过程中,区间比较小了以后,最好不再进行递归分割排序,
因为满二叉树(快速排序递归过程类似满二叉树)倒数三层中会有80%的节点
所以当区间比较小后,这些小区间会有80%的递归操作,
对这么多小区间进行递归不划算,
所以当数组区间递归成小区间(类似只有10个元素)后,
可以使用直接插入排序代替递归进行排序,
对只有10个元素的数组进行直接插入排序效率高而且省去了80%的递归操作
- 对元素大于10的数组(大区间)进行快速排序(递归进行):
调用上面写的三种单趟快速排序函数的其中一种,并接收返回的key值下标,
此时当前区间就被分成了左右两个区间,
对左右两个区间分别进行递归操作
- 对元素小于等于10的数组(小区间)进行直接插入排序
图示:
该函数执行逻辑图:
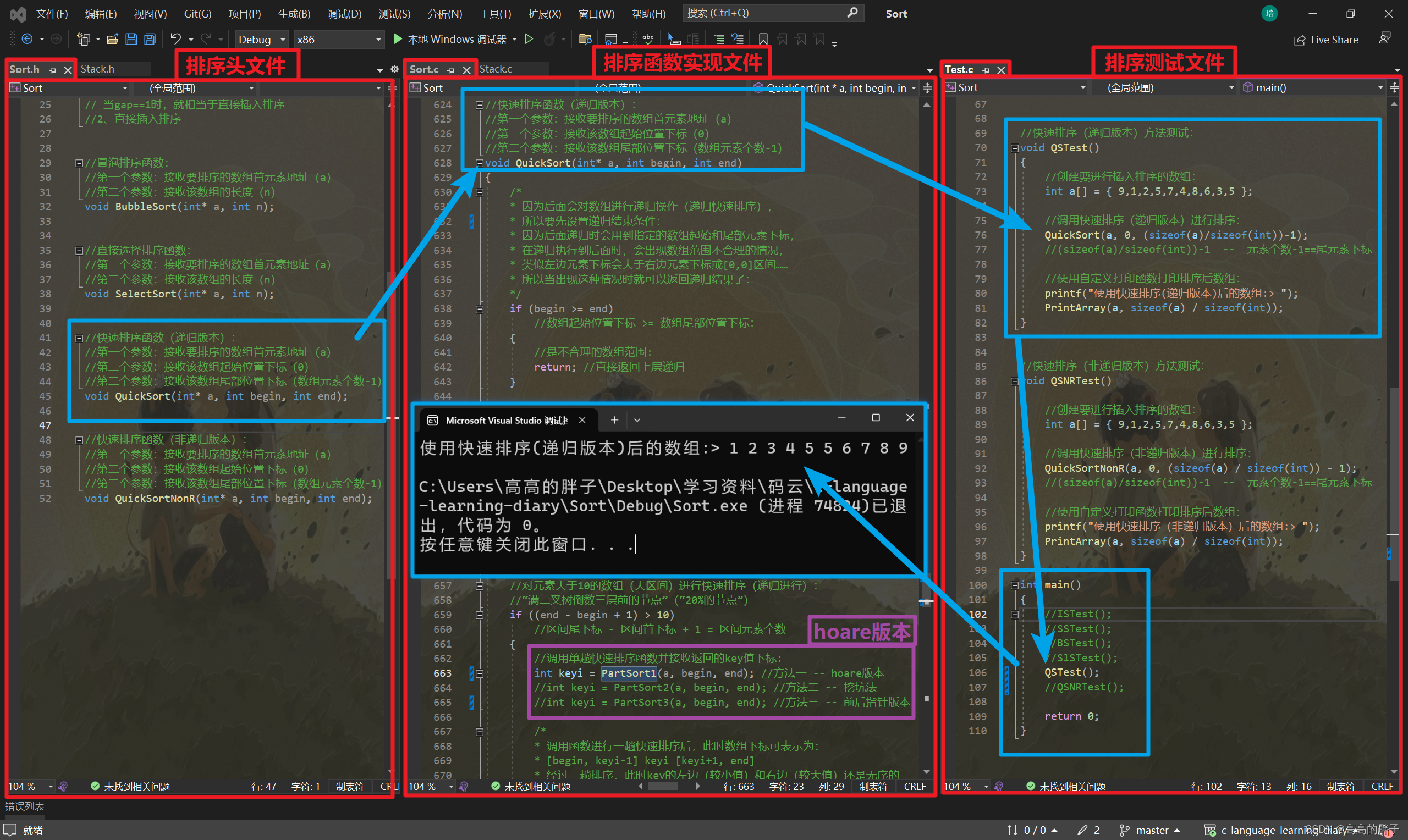
该函数测试(hoare版本):
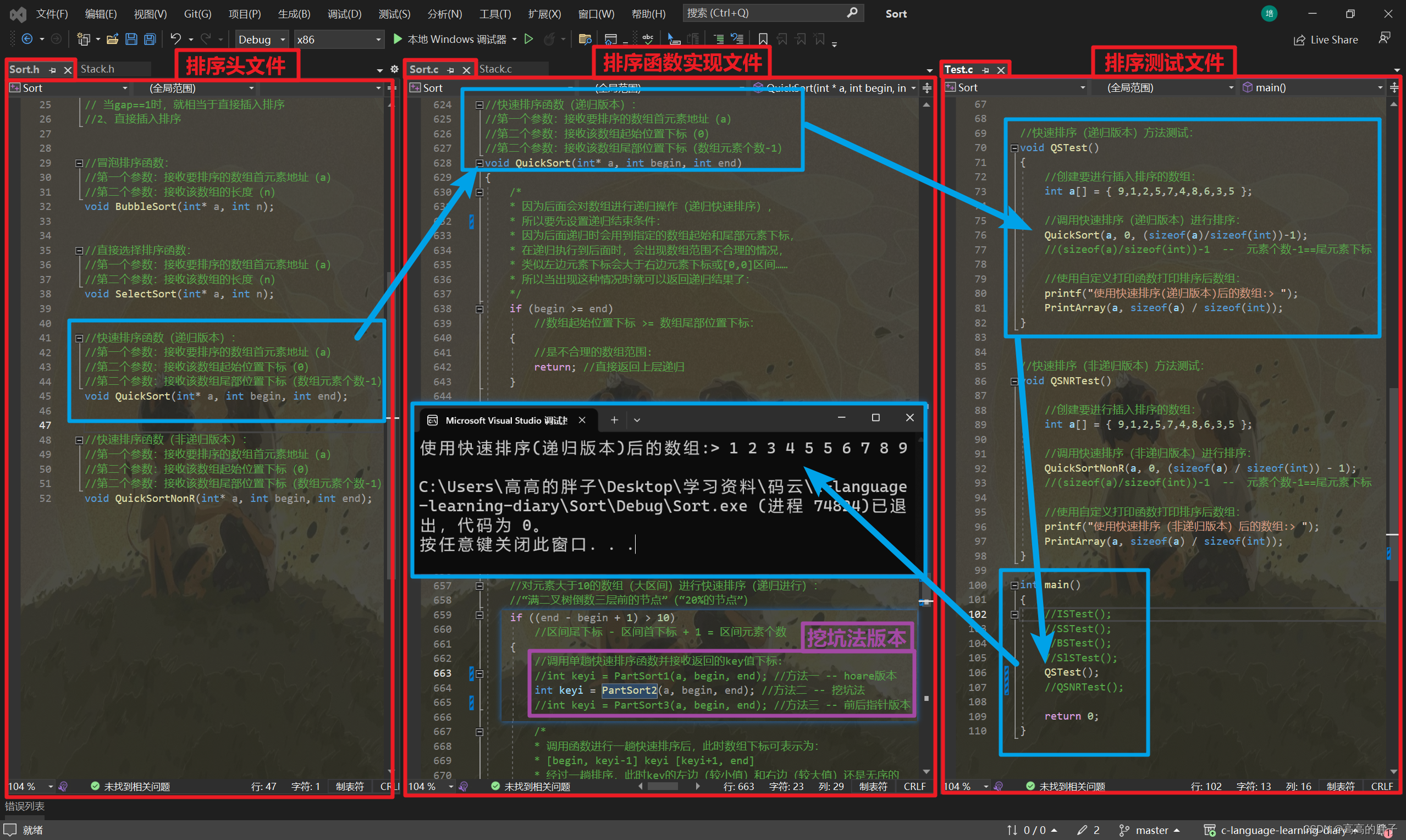
该函数测试(挖坑法版本):
该函数测试(前后指针版本):
---------------------------------------------------------------------------------------------
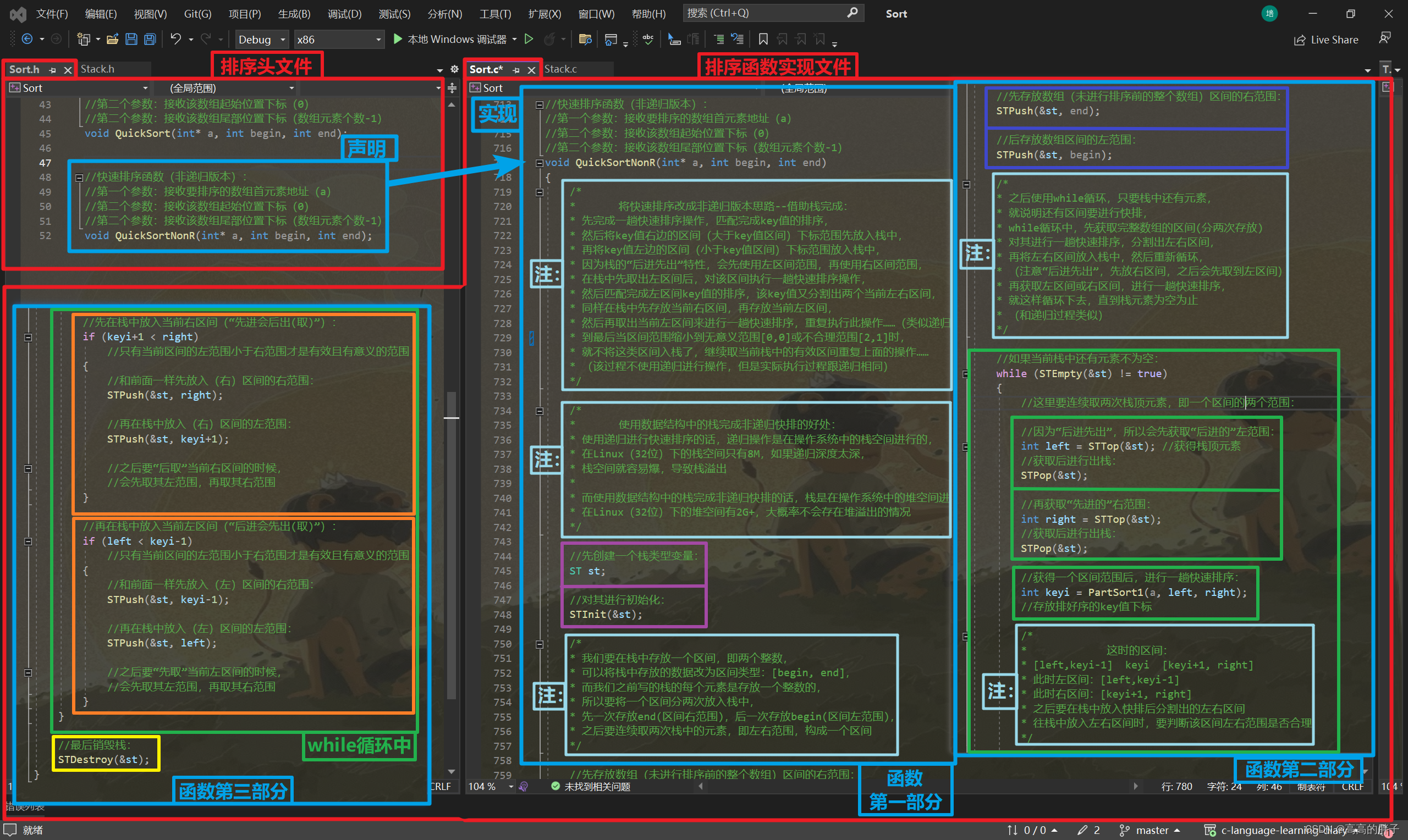
QuickSortNonR函数 -- 快速排序(非递归版本)
- 快速排序非递归版本思路--借助栈(“后进先出”)完成:
先完成一趟快速排序操作,匹配完成key值的排序,
然后将key值右边的区间(大于key值区间)下标范围先放入栈中,
再将key值左边的区间(小于key值区间)下标范围放入栈中,
因为栈的“后进先出”特性,会先使用左区间范围,再使用右区间范围,
在栈中先取出左区间后,对该区间执行一趟快速排序操作,
然后匹配完成左区间key值的排序,该key值又分割出两个当前左右区间,
同样在栈中先存放当前右区间,再存放当前左区间,
然后再取出当前左区间来进行一趟快速排序,重复执行此操作……(类似递归)
到最后当区间范围缩小到无意义范围[0,0]或不合理范围[2,1]时,
就不将这类区间入栈了,继续取当前栈中的有效区间重复上面的操作……
(该过程不使用递归进行操作,但是实际执行过程跟递归相同)
- 使用数据结构中的栈完成非递归快排的好处:
使用递归进行快速排序的话,递归操作是在操作系统中的栈空间进行的,
在Linux(32位)下的栈空间只有8M,如果递归深度太深,
栈空间就容易爆,导致栈溢出
而使用数据结构中的栈完成非递归快排的话,栈是在操作系统中的堆空间进行的,
在Linux(32位)下的堆空间有2G+,大概率不会存在堆溢出的情况先导入之前写的栈实现:
图示:
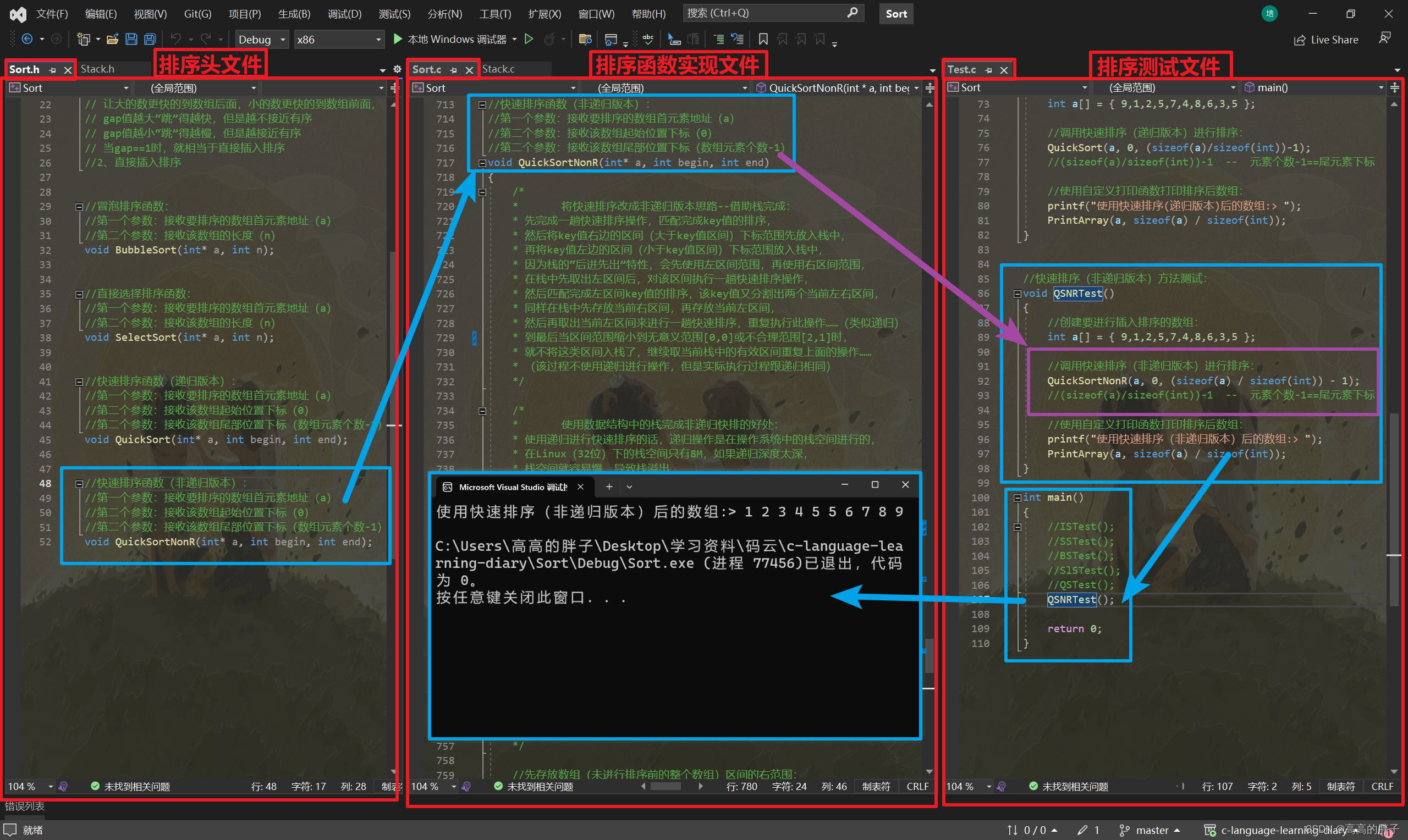
该函数测试:


~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
对应代码(续上期)
Sort.h -- 排序头文件
//快速排序函数(递归版本): //第一个参数:接收要排序的数组首元素地址(a) //第二个参数:接收该数组起始位置下标(0) //第二个参数:接收该数组尾部位置下标(数组元素个数-1) void QuickSort(int* a, int begin, int end); //快速排序函数(非递归版本): //第一个参数:接收要排序的数组首元素地址(a) //第二个参数:接收该数组起始位置下标(0) //第二个参数:接收该数组尾部位置下标(数组元素个数-1) void QuickSortNonR(int* a, int begin, int end);
---------------------------------------------------------------------------------------------
Sort.c -- 排序函数实现文件
//三数取中(内部函数): //第一个参数:接收要排序的数组首元素地址(a) //第二个参数:数组最左边(起始)元素下标 -- key值 //第三个参数:数组最右边(尾部)元素下标 //返回中间值的下标 int GetMidi(int* a, int left, int right) { //通过left(左下标)和right(右下标)获得mid(中下标): int mid = (left + right) / 2; // left mid right if (a[left] < a[mid]) //"左下标值" < "中下标值" { if (a[mid] < a[right]) //又有:"中下标值" < "右下标值" { return mid; //mid就是三数中的中间值下标 } else if (a[left] > a[right]) //又有:"左下标值" > "右下标值" { return left; //left就是三数中的中间值下标 } else //其它情况: { return right; //right就是三数中的中间值下标 } } else //a[left] > a[mid] //"左下标值" > "中下标值" { if (a[mid] > a[right]) //又有:"中下标值" > "右下标值" { return mid; //mid就是三数中的中间值下标 } else if (a[left] < a[right]) //又有:"左下标值" < "右下标值" { return left; //left就是三数中的中间值下标 } else //其它情况: { return right; //right就是三数中的中间值下标 } } } //一趟快速排序(内部函数)-- 方法一hoare版本(细节较多): //第一个参数:接收要排序的数组首元素地址(a) //第二个参数:数组最左边(起始)元素下标 -- key值 //第三个参数:数组最右边(尾部)元素下标 //返回排序后key值下标 int PartSort1(int* a, int left, int right) { //使用三数取中函数获得一个相对而言的中间值下标: int midi = GetMidi(a, left, right); //将中间值和数组起始元素进行交换: Swap(&a[left], &a[midi]); //定义快速排序的key值下标, //默认key值下标为数组最左边(起始)下标 -- 0: //(通过三数取中后的left值在排序后会在数组相对中间位置) //(这有助于提高快速排序的效率 -- 因为后面递归的操作) int keyi = left; //使用while循环, //将数组右边的较小值移至数组左边, //将数组左边的较大值移至数组右边: while (left < right) /* * 只要left下标还小于right下标, * 说明中间可能还有元素需要被调整。 */ { //先让right从右往左找小于key值的元素下标: /* 因为是升序,大值应该在右边, 所以从右往左找较小值,之后移至数组左边 */ while (left < right && a[right] >= a[keyi]) //left < right,保证right不越界 //而且right元素还大于等于key值: { //那就说明还不是较小值, //right往左移一位: --right; //直到调整到比key小的元素下标为止 } //找到右边的较小值后,再找左边的较大值, //让left从左往右找大于key值的元素下标: /* 因为是升序,小值应该在左边, 所以从左往右找较大值,之后移至数组右边 */ while (left < right && a[left] <= a[keyi]) //left < right,保证left不越界 //而且left元素还小于等于key值: { //那就说明还不是较大值, //left往右移一位: ++left; //直到调整到比key大的元素下标为止 } //分别找到比key小和比key大的值后, //将两者的值进行调换: //(让较小值到数组左边,较大值到数组右边) Swap(&a[left], &a[right]); } //key值左边的较小值和右边的较大值排好后, //while循环结束时,left == right, //此时left(或right)下标就会是key值在数组中的真正下标, //所以要将key值和此时left值(right值)进行交换: /* * 外层while循环结束后,是right先往左边走,left再往右边走, * 较大值都在right后 且 left位置一定会在小于key值的元素上, * 所以此时可以将key值和left值(right值)进行交换,找到key真正位置 */ Swap(&a[keyi], &a[left]); return left; //返回left(或right)下标,即此时key值的下标 //此时key的左边(较小值)和右边(较大值)还是无序的 } //单趟快速排序的时间复杂度:O(N) //一趟快速排序(内部函数)-- 方法二挖坑法: //第一个参数:接收要排序的数组首元素地址(a) //第二个参数:数组最左边(起始)元素下标 -- key值 //第三个参数:数组最右边(尾部)元素下标 //返回排序后key值下标 int PartSort2(int* a, int left, int right) { //使用三数取中函数获得一个相对而言的中间值下标: int midi = GetMidi(a, left, right); //将中间值和数组起始元素进行交换: Swap(&a[left], &a[midi]); //此时left下标元素就是中间值: int key = a[left]; //直接获取key值(存放中间值) //保存key值以后,在数组起始(最左边)位置形成第一个"坑": int hole = left; //只留"坑"的下标(左边的"坑") //使用while循环进行快排过程: while (left < right) /* * 只要left下标还小于right下标, * 说明中间可能还有元素需要被调整。 */ { //让right从右往左走,找比key小的元素下标, while (left < right && a[right] >= key) //left < right,保证right不越界 //而且right元素还大于等于key值: { //那就说明还不是较小值, //right往左移一位: --right; //直到调整到比key小的元素下标为止 } //找到对应下标后填到左边的"坑", a[hole] = a[right]; //在此时right下标处形成新的"坑": hole = right; //右边的"坑"(下标) //让left从左往右走,找比key大的元素下标, while (left < right && a[left] <= key) //left < right,保证left不越界 //而且left元素还小于等于key值: { //那就说明还不是较大值, //left往右移一位: ++left; //直到调整到比key大的元素下标为止 } //找到对应下标后填到右边的"坑", a[hole] = a[left]; //在此时left下标处形成新的"坑": hole = left; //再次形成左边的"坑"(下标) } //left和right在“坑”下标处相遇后,while循环结束, //此时“坑”下标就是key值对应下标, //所以最后将key值放到“坑”下标处: a[hole] = key; //返回当前key值“坑”下标: return hole; } //一趟快速排序(内部函数)-- 方法三前后指针版本: //第一个参数:接收要排序的数组首元素地址(a) //第二个参数:数组最左边(起始)元素下标 -- key值 //第三个参数:数组最右边(尾部)元素下标 //返回排序后key值下标 int PartSort3(int* a, int left, int right) { /* * 思路(类似推箱子): * 创建两个指针--prev(前指针)和cur(后指针) * prev一开始指向起始位置,cur一开始指向prev后一位 * * cur: * 1、++cur从左往右开始“找小(比key小)”, 找到后++prev,再交换prev和cur指向的值 * cur未找到较小值的话,cur单独++,prev不动 * * prev有两种情况: * 1、在cur还没遇到比key大的值的时候,prev紧跟着cur * 2、在cur遇到比key大的值的时候,cur单独++, * prev会在比key大的一组值的前面(数组左边) * * 【本质:把一段大于key的区间(较大值区间),类似推箱子般往右推, * 同时将较小值甩到左边(较小值区间)去】 */ //使用三数取中函数获得一个相对而言的中间值下标: int midi = GetMidi(a, left, right); //将中间值和数组起始元素进行交换: Swap(&a[left], &a[midi]); //定义key值(“中间值”)下标: int keyi = left; //默认当前数组起始位置下标 //先定义prev指针: int prev = left; //从当前数组起始位置开始 //再定义cur指针: int cur = prev + 1; //指向prev的后一位 //使用while循环循环进行"推箱子": while (cur <= right) /* * cur==right时,还要再指向一次, * 让cur指针出界,出界时prev指针的位置才是key值位置 */ { //如果cur从左往右走后找到了“较小值”: if (a[cur] < a[keyi] && ++prev != cur) /* * ++prev != cur * 每次“推箱子”时,先++prev, * 且不等于cur,如果等于cur的话会导致自己跟自己交换, * 这操作没有意义,所以直接进行下次“推箱子”操作 */ { //再交换当前两指针值: Swap(&a[prev], &a[cur]); } //无论cur是否找到“较小值”,cur指针都需要进行++: ++cur; //++往后(右)走 } /* * 把一段大于key的区间(较大值区间),类似推箱子般往右推, * 同时将较小值甩到左边(较小值区间)去 */ //right出界“推完箱子”后,while循环结束, //此时prev下标就是key值下标, //所以将key值放入该位置: Swap(&a[prev], &a[keyi]); //最后返回key值位置 -- prev : return prev; } //快速排序函数(递归版本): //第一个参数:接收要排序的数组首元素地址(a) //第二个参数:接收该数组起始位置下标(0) //第二个参数:接收该数组尾部位置下标(数组元素个数-1) void QuickSort(int* a, int begin, int end) { /* * 因为后面会对数组进行递归操作(递归快速排序), * 所以要先设置递归结束条件: * 因为后面递归时会用到指定的数组起始和尾部元素下标, * 在递归执行到后面时,会出现数组范围不合理的情况, * 类似左边元素下标会大于右边元素下标或[0,0]区间…… * 所以当出现这种情况时就可以返回递归结果了: */ if (begin >= end) //数组起始位置下标 >= 数组尾部位置下标: { //是不合理的数组范围: return; //直接返回上层递归 } /* * 小区间优化 -- 小区间不再进行递归分割排序,降低递归次数: * 为了进一步提高快速排序效率, * 在递归分割过程中,区间比较小了以后,最好不再进行递归分割排序, * 因为满二叉树(快速排序递归过程类似满二叉树)倒数三层中会有80%的节点 * 所以当区间比较小后,这些小区间会有80%的递归操作, * 对这么多小区间进行递归不划算, * 所以当数组区间递归成小区间(类似只有10个元素)后, * 可以使用直接插入排序代替递归进行排序, * 对只有10个元素的数组进行直接插入排序效率高而且省去了80%的递归操作 */ //对元素大于10的数组(大区间)进行快速排序(递归进行): //“满二叉树倒数三层前的节点”(“20%的节点”) if ((end - begin + 1) > 10) //区间尾下标 - 区间首下标 + 1 = 区间元素个数 { //调用单趟快速排序函数并接收返回的key值下标: //int keyi = PartSort1(a, begin, end); //方法一 -- hoare版本 //int keyi = PartSort2(a, begin, end); //方法二 -- 挖坑法 int keyi = PartSort3(a, begin, end); //方法三 -- 前后指针版本 /* * 调用函数进行一趟快速排序后,此时数组下标可表示为: * [begin, keyi-1] keyi [keyi+1, end] * 经过一趟排序,此时key的左边(较小值)和右边(较大值)还是无序的 * key的左边(较小值)下标区间:[begin, keyi-1] * key的右边(较大值)下标区间:[keyi+1, end] * 所以接下来要就这两个区间进行排序: */ /* * 可以把下标区间: [begin, keyi-1] keyi [keyi+1, end] * 看成类似二叉树的结构: * keyi -- "根" * [begin, keyi-1] -- “左子树” * [keyi+1, end] -- “右子树” * 所以可以使用类似树中类似递归的操作完成排序: */ //对“左子树”进行递归快速排序: QuickSort(a, begin, keyi - 1); //[begin, keyi-1] -- “左子树” //对“右子树”进行递归快速排序: QuickSort(a, keyi + 1, end); //[keyi+1, end] -- “右子树” } else //对元素小于等于10的数组(小区间)进行直接插入排序: //“满二叉树的倒数三层节点”(“80%的节点”) { //调用直接插入排序对递归后的“小区间”进行排序: InsertSort(a + begin, end - begin + 1); //被快速排序的递归操作分割后的“小区间”首元素下标:a + begin //被快速排序的递归操作分割后的“小区间”元素个数:end - begin + 1 } } /* * 快速排序时间复杂度(三数取中前): * 最好的情况(key值总排在靠中间的位置) -- O(N*logN) * 最坏的情况(数组有序,key值总排在靠起始位置) -- O(N^2) * * 快速排序时间复杂度(三数取中后): * 最好的情况(数组有序,key值总排在靠中间位置) -- O(N*logN) * 最坏的情况 -- 在三数取中操作后几乎不会有最坏的情况 */ //快速排序函数(非递归版本): //第一个参数:接收要排序的数组首元素地址(a) //第二个参数:接收该数组起始位置下标(0) //第二个参数:接收该数组尾部位置下标(数组元素个数-1) void QuickSortNonR(int* a, int begin, int end) { /* * 将快速排序改成非递归版本思路--借助栈完成: * 先完成一趟快速排序操作,匹配完成key值的排序, * 然后将key值右边的区间(大于key值区间)下标范围先放入栈中, * 再将key值左边的区间(小于key值区间)下标范围放入栈中, * 因为栈的“后进先出”特性,会先使用左区间范围,再使用右区间范围, * 在栈中先取出左区间后,对该区间执行一趟快速排序操作, * 然后匹配完成左区间key值的排序,该key值又分割出两个当前左右区间, * 同样在栈中先存放当前右区间,再存放当前左区间, * 然后再取出当前左区间来进行一趟快速排序,重复执行此操作……(类似递归) * 到最后当区间范围缩小到无意义范围[0,0]或不合理范围[2,1]时, * 就不将这类区间入栈了,继续取当前栈中的有效区间重复上面的操作…… * (该过程不使用递归进行操作,但是实际执行过程跟递归相同) */ /* * 使用数据结构中的栈完成非递归快排的好处: * 使用递归进行快速排序的话,递归操作是在操作系统中的栈空间进行的, * 在Linux(32位)下的栈空间只有8M,如果递归深度太深, * 栈空间就容易爆,导致栈溢出 * * 而使用数据结构中的栈完成非递归快排的话,栈是在操作系统中的堆空间进行的, * 在Linux(32位)下的堆空间有2G+,大概率不会存在堆溢出的情况 */ //先创建一个栈类型变量: ST st; //对其进行初始化: STInit(&st); /* * 我们要在栈中存放一个区间,即两个整数, * 可以将栈中存放的数据改为区间类型:[begin, end], * 而我们之前写的栈的每个元素是存放一个整数的, * 所以要将一个区间分两次放入栈中, * 先一次存放end(区间右范围),后一次存放begin(区间左范围), * 之后要连续取两次栈中的元素,即左右范围,构成一个区间 */ //先存放数组(未进行排序前的整个数组)区间的右范围: STPush(&st, end); //后存放数组区间的左范围: STPush(&st, begin); /* * 之后使用while循环,只要栈中还有元素, * 就说明还有区间要进行快排, * while循环中,先获取完整数组的区间(分两次存放) * 对其进行一趟快速排序,分割出左右区间, * 再将左右区间放入栈中,然后重新循环, * (注意“后进先出”,先放右区间,之后会先取到左区间) * 再获取左区间或右区间,进行一趟快速排序, * 就这样循环下去,直到栈元素为空为止 * (和递归过程类似) */ //如果当前栈中还有元素不为空: while (STEmpty(&st) != true) { //这里要连续取两次栈顶元素,即一个区间的两个范围: //因为“后进先出”,所以会先获取“后进的”左范围: int left = STTop(&st); //获得栈顶元素 //获取后进行出栈: STPop(&st); //再获取“先进的”右范围: int right = STTop(&st); //获取后进行出栈: STPop(&st); //获得一个区间范围后,进行一趟快速排序: int keyi = PartSort1(a, left, right); //存放排好序的key值下标 /* * 这时的区间: * [left,keyi-1] keyi [keyi+1, right] * 此时左区间:[left,keyi-1] * 此时右区间:[keyi+1, right] * 之后要在栈中放入快排后分割出的左右区间 * 往栈中放入左右区间时,要判断该区间左右范围是否合理 */ //先在栈中放入当前右区间(“先进会后出(取)”): if (keyi+1 < right) //只有当前区间的左范围小于右范围才是有效且有意义的范围 { //和前面一样先放入(右)区间的右范围: STPush(&st, right); //再在栈中放入(右)区间的左范围: STPush(&st, keyi+1); //之后要“后取”当前右区间的时候, //会先取其左范围,再取其右范围 } //再在栈中放入当前左区间(“后进会先出(取)”): if (left < keyi-1) //只有当前区间的左范围小于右范围才是有效且有意义的范围 { //和前面一样先放入(左)区间的右范围: STPush(&st, keyi-1); //再在栈中放入(左)区间的左范围: STPush(&st, left); //之后要“先取”当前左区间的时候, //会先取其左范围,再取其右范围 } } //最后销毁栈: STDestroy(&st); }
---------------------------------------------------------------------------------------------
Test.c -- 排序测试文件
//快速排序(递归版本)方法测试: void QSTest() { //创建要进行插入排序的数组: int a[] = { 9,1,2,5,7,4,8,6,3,5 }; //调用快速排序(递归版本)进行排序: QuickSort(a, 0, (sizeof(a)/sizeof(int))-1); //(sizeof(a)/sizeof(int))-1 -- 元素个数-1==尾元素下标 //使用自定义打印函数打印排序后数组: printf("使用快速排序(递归版本)后的数组:> "); PrintArray(a, sizeof(a) / sizeof(int)); } //快速排序(非递归版本)方法测试: void QSNRTest() { //创建要进行插入排序的数组: int a[] = { 9,1,2,5,7,4,8,6,3,5 }; //调用快速排序(非递归版本)进行排序: QuickSortNonR(a, 0, (sizeof(a) / sizeof(int)) - 1); //(sizeof(a)/sizeof(int))-1 -- 元素个数-1==尾元素下标 //使用自定义打印函数打印排序后数组: printf("使用快速排序(非递归版本)后的数组:> "); PrintArray(a, sizeof(a) / sizeof(int)); } int main() { //ISTest(); //SSTest(); //BSTest(); //SlSTest(); //QSTest(); QSNRTest(); return 0; }