1.摘要
在上一章节中,我利用Docker快速搭建了一个Kafka服务,并测试成功Kafka生产者和消费者功能,本章内容尝试在Go项目中对Kafka服务进行封装调用, 实现从Kafka自动接收消息并消费。
在本文中使用了Kafka的一个高性能开源库Sarama, Sarama是一个遵循MIT许可协议的Apache Kafka Go客户端库, 该开源库地址为:GitHub - IBM/sarama: Sarama is a Go library for Apache Kafka.。
2.功能结构组织
为了能在项目中快速使用, 我在项目目录中专门新建了一个名为kafka的文件夹,在该文件夹下新建了四个文件,分别为:
kafka (目录)
|
----- consumer.go (消费者方法实现)
|
----- producer.go (生产者方法实现)
|
----- kafka.go (定义接口)
|
----- kafka_test.go (单元功能测试)为方便项目使用,在此基础上做了二次封装。
3.消费者实现
第一步首先定义了一个结构体, 里面包含了Kafka的主机、topic、接收通道和消费者对象信息:
type KafkaConsumer struct {
Hosts string // Kafka主机IP:端口,例如:192.168.201.206:9092
Ctopic string // topic名称
Kchan chan string // 接收信息通道
Consumer sarama.Consumer // 消费者对象
}接下来是消费者初始化函数:
func (k *KafkaConsumer) kafkaInit() {
// 定义配置选项
config := sarama.NewConfig()
config.Consumer.Return.Errors = true
config.Version = sarama.V0_10_2_0
// 初始化一个消费对象
consumer, err := sarama.NewConsumer(k.Hosts, config)
if err != nil {
err = errors.New("NewConsumer错误,原因:" + err.Error())
fmt.Println(err.Error())
return
}
// 获取所有Topic
topics, err := consumer.Topics()
if err != nil {
fmt.Println(err.Error())
return
}
// 判断是否有自定义的Topic
var topicsName = ""
for _, e := range topics {
if e == k.Ctopic {
topicsName = e
break
}
}
// 没有自定义的Topic则报错
if topicsName == "" {
err = errors.New("找不到topics内容")
fmt.Println(err.Error())
return
}
// 将消费对象保存到结构体以备后面使用
k.Consumer = consumer
}在上面的初始化函数中, 首先初始化一个消费对象, 然后获取所有的Topic名称,并判断了在这些Topic名称中是否有我自定义的名称,获取成功后则将消费对象保存到我们绑定的结构体中。
接下来是消费监控函数实现,代码如下:
func (k *KafkaConsumer) kafkaProcess() {
var wg sync.WaitGroup
// 遍历指定Topic分区持续监控消息
Partitions, _ := k.Consumer.Partitions(k.Ctopic)
for _, subPartitions := range Partitions {
pc, err := k.Consumer.ConsumePartition(k.Ctopic, subPartitions, sarama.OffsetNewest)
if err != nil {
continue
}
wg.Add(1)
go func() {
defer wg.Done()
// 这里进入另一个函数可以过滤消息内容
k.processPartition(pc)
}()
}
wg.Wait()
}函数processPartition()的实现代码如下:
func (k *KafkaConsumer) processPartition(pc sarama.PartitionConsumer) {
defer pc.AsyncClose()
for msg := range pc.Messages() {
// 这里可以过滤不需要的Topic的信息
if strings.Contains(string(msg.Value), "group_state2") {
continue
}
// 这里将获取到的Topic信息发送到通道
k.Kchan <- string(msg.Value)
}
}4.生产者实现
为了跟消费者代码配套,这里也同步实现了生产者代码,主要功能是完成工作后,给指定Topic的生产方返回一个指定消息。
定义生产者的结构体如下:
type KafkaProducer struct {
hosts string // Kafka主机
sendmsg string // 消费方返回给生产方的消息
ptopic string // Topic
AsyncProducer sarama.AsyncProducer // Kafka生产者接口对象
}对应的生产者初始化函数实现如下:
func (k *KafkaProducer) kafkaInit() {
// 定义配置参数
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Retry.Max = 5
config.Producer.Return.Successes = true
config.Version = sarama.V0_10_2_0
// 初始化一个生产者对象
producer, err := sarama.NewAsyncProducer(k.hosts, config)
if err != nil {
err = errors.New("NewAsyncProducer错误,原因:" + err.Error())
fmt.Println(err.Error())
return
}
// 保存对象到结构体
k.AsyncProducer = producer
}给生产者回复信息的函数实现如下:
func (k *KafkaProducer) kafkaProcess() {
msg := &sarama.ProducerMessage{
Topic: k.ptopic,
}
// 信息编码
msg.Value = sarama.ByteEncoder(k.sendmsg)
// 将信息发送给通道
k.AsyncProducer.Input() <- msg
}5.接口定义实现
首先对于生产者和消费者,都有对应的初始化和执行操作,因此定义接口函数如下:
// Kafka方法接口
type IKafkaMethod interface {
kafkaInit() // 初始化方法
kafkaProcess() // 执行方法
}为了方便管理接口的赋值操作, 这里定义了一个接口管理方法, 并用Set()函数进行接口类型赋值, Run()函数负责运行对应的成员函数:
// 接口管理结构体
type KafkaManager struct {
kafkaMethod IKafkaMethod // 接口对象
}
// 定义实现Set方法
func (km *KafkaManager) Set(m IKafkaMethod) {
km.kafkaMethod = m // 将指定的方法赋给接口
}
// 定义实现Run方法
func (km *KafkaManager) Run() {
km.kafkaMethod.kafkaInit()
go km.kafkaMethod.kafkaProcess()
}最后一部分是供外部调用的函数,首先定义一个结构体,该结构体中保存了Kafka的基础信息和三个对象指针:
type KafkaMessager struct {
KafkaManager *KafkaManager // 接口管理对象指针
KafkaProducer *KafkaProducer // 生产者对象指针
KafkaConsumer *KafkaConsumer // 消费者对象指针
Hosts string // Kafka主机
topic string // topic
}
// 供外部调用初始化的函数,传入Kafka主机IP和Topic,返回操作对象指针,并初始化结构体成员变量
func NewKafkaMessager(hosts, topic string) *KafkaMessager {
km := &KafkaMessager{
KafkaManager: new(KafkaManager),
KafkaProducer: new(KafkaProducer),
KafkaConsumer: new(KafkaConsumer),
Hosts: hosts,
topic: topic,
}
return km
}6.功能调用和验证
在Kafka_test.go文件中,定义一个用于单元测试的函数,格式如下:
func TestKafka(t *testing.T) {
....
}使用单元测试函数的好处是可以单独调试, 专注核心功能本身。
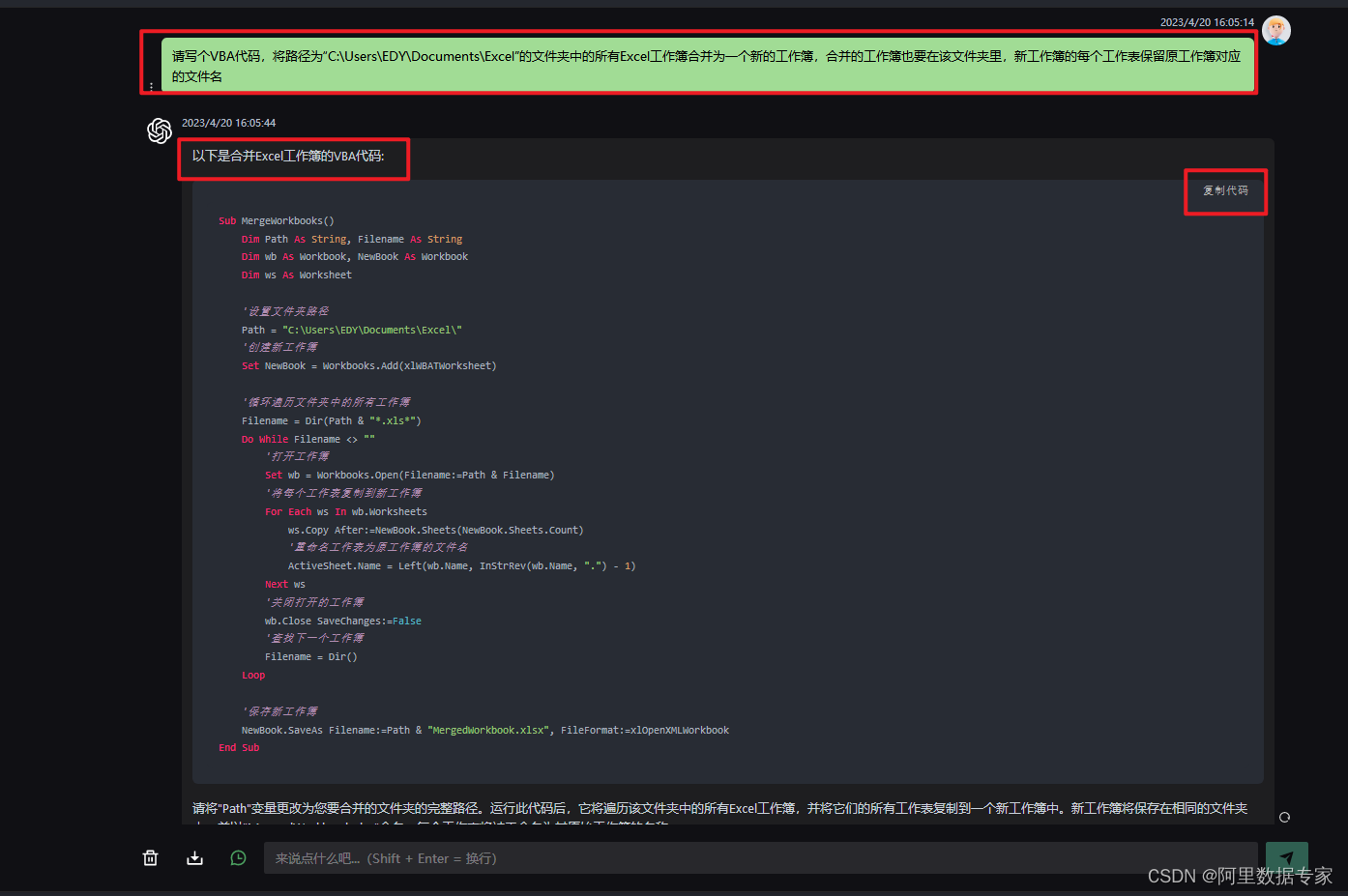
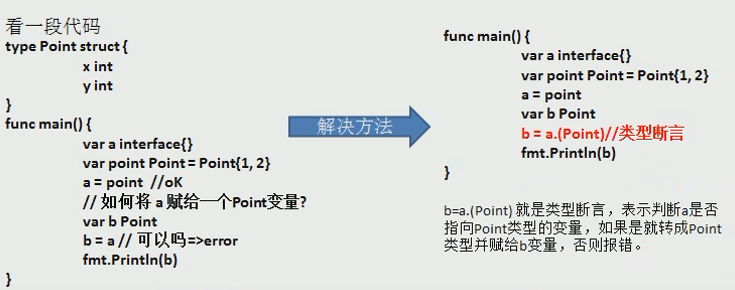
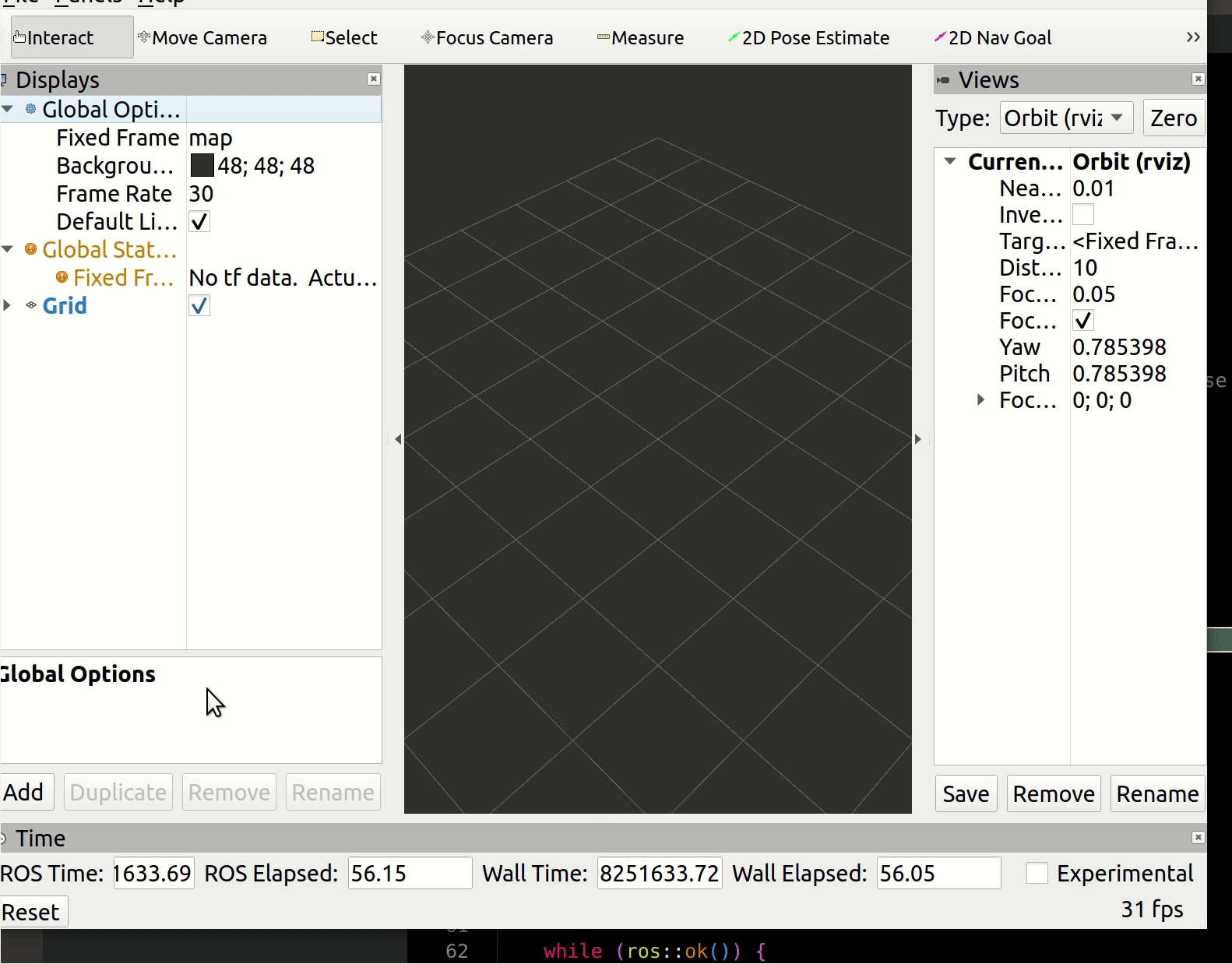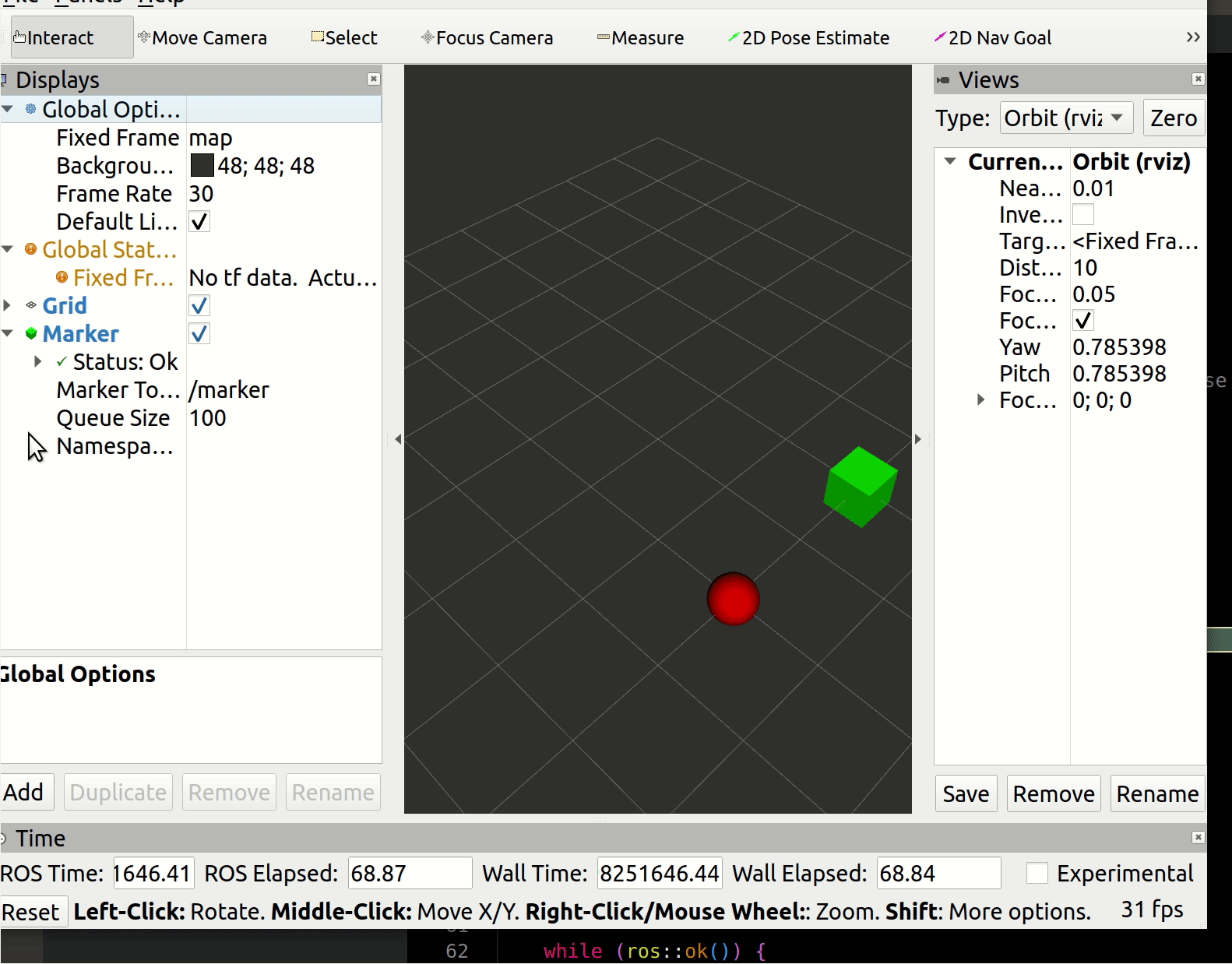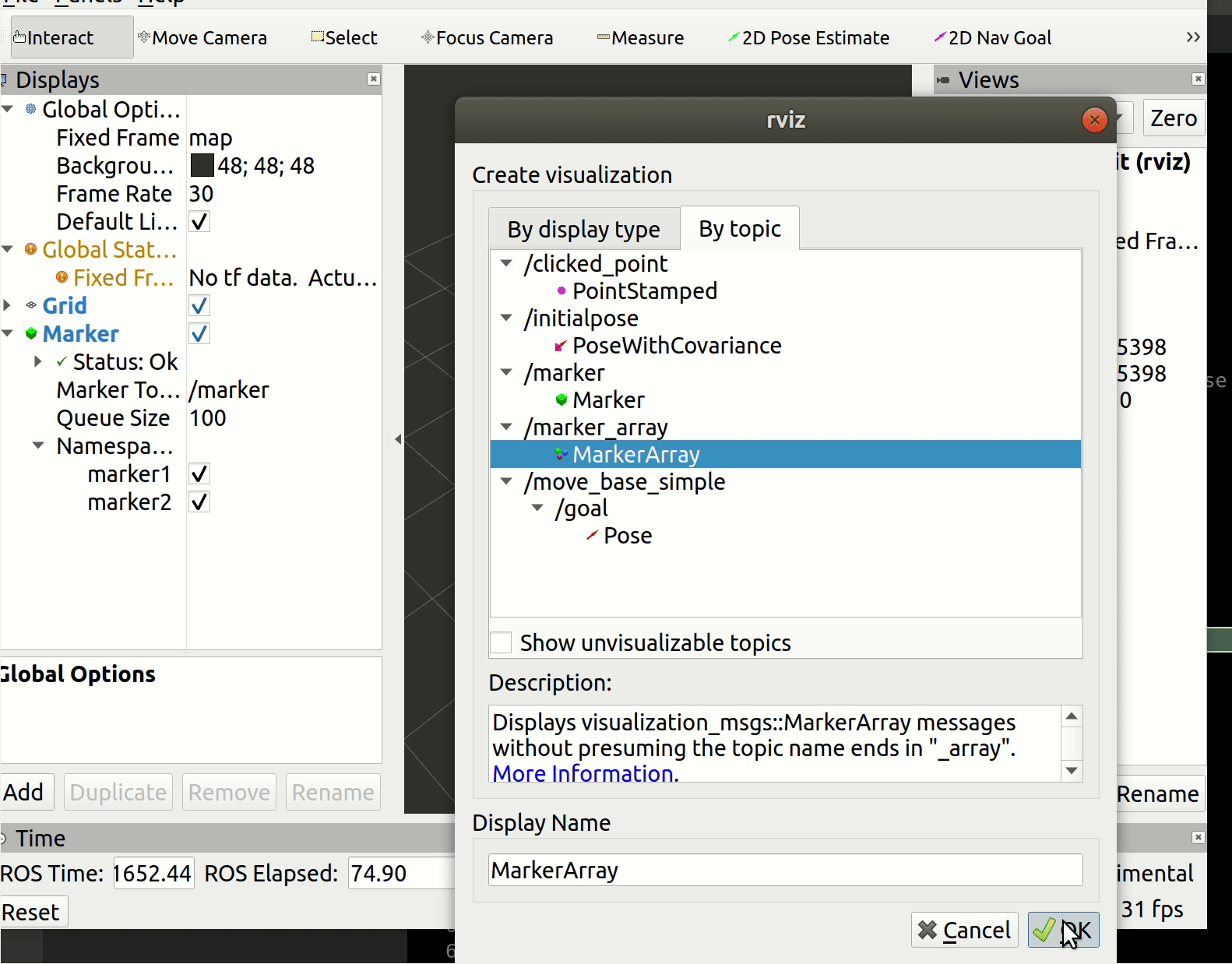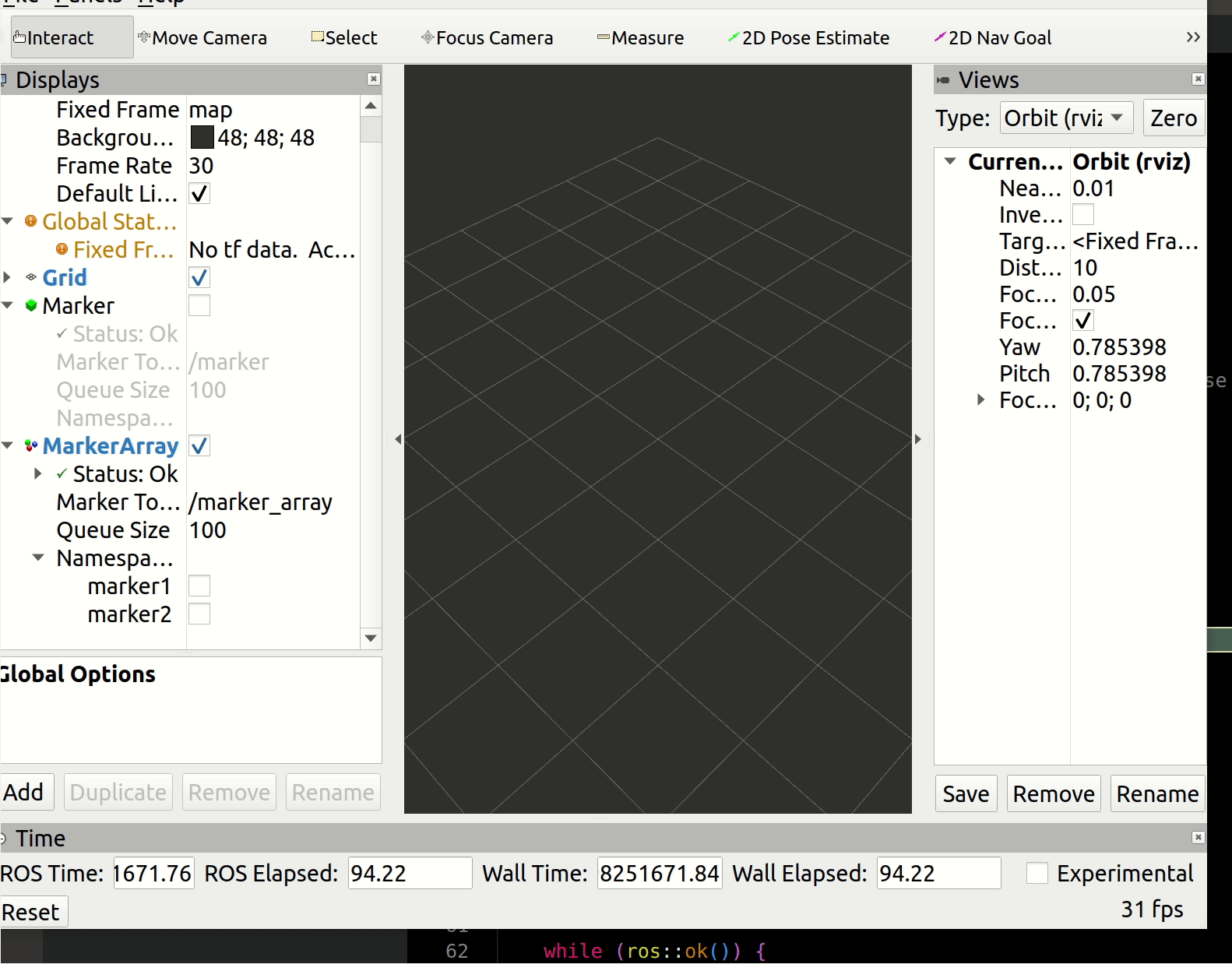
我使用的编辑器是Goland, 在TestKafka函数前面有个三角形小图标,点击可以选择各种调试选项,如图:
下面是我模拟用户调用的客户端代码片段:
// 这里选择我自己搭建的Kafka所在服务器,Topic为test123
// 注意:这里的hosts格式是IP:端口的格式,例如:192.168.201.206:9092
hosts := "192.168.201.206:9092"
topic := "test123"
// 调用初始化函数,并将上面的内容作为参数传进去
nkm := NewKafkaMessager(hosts, topic)
// 初始化消费者,当生产者发出消息,消费者自动消费
nkm.KafkaConsumer.Hosts = hosts // 消费者host赋值
nkm.KafkaConsumer.Ctopic = topic // 消费者topic赋值
nkm.KafkaConsumer.Kchan = make(chan string) // 初始化消息通道
nkm.KafkaManager.Set(nkm.KafkaConsumer) // 接口赋值,设置成操作消费者方法
nkm.KafkaManager.Run() // 执行消费者初始化方法
// 监听通道,接收生产客户端发过来的消息
recv := <- nkm.KafkaConsumer.Kchan
fmt.Println(recv) // 打印接收到的消息现在我们可以选择直接运行程序了,然后在Kafka的生产者控制台中输入字符:Hello,Goland发送:

可以看到,我们的程序成功接收到Kafka生产者发送过来的信息。
--- END --