1.1 AQS 简单介绍
AQS 的全称为(AbstractQueuedSynchronizer),这个类在 java.util.concurrent.locks 包下面。

AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器, 比如我们提到的 ReentrantLock,Semaphore,其他的诸如 ReentrantReadWriteLock,SynchronousQueue,FutureTask(jdk1.7) 等等皆是基于 AQS 的。当然,我们自己也能利用 AQS 非常轻松容易地构造出符合我们自己需求的同步器。
1.2 AQS 原理

1.2.1 AQS 原理概览
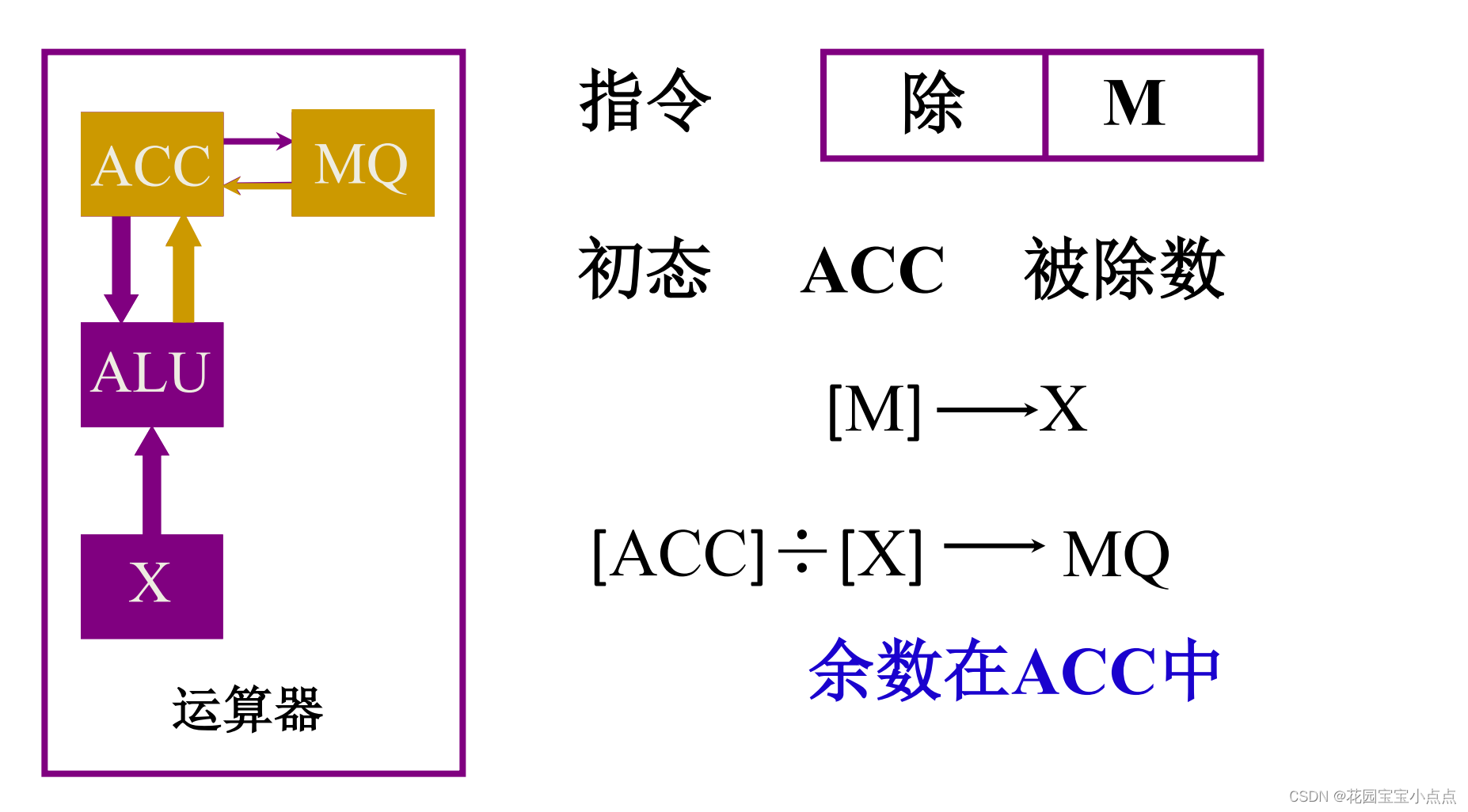
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒 时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。

关于AQS类有一段注释是这样写的:
Wait queue node class.
The wait queue is a variant of a "CLH" (Craig, Landin, and Hagersten) lock queue. CLH locks are normally used for spinlocks. We instead use them for blocking synchronizers, but use the same basic tactic of holding some of the control information about a thread in the predecessor of its node. A "status" field in each node keeps track of whether a thread should block. A node is signalled when its predecessor releases. Each node of the queue otherwise serves as a specific-notification-style monitor holding a single waiting thread. The status field does NOT control whether threads are granted locks etc though. A thread may try to acquire if it is first in the queue. But being first does not guarantee success; it only gives the right to contend. So the currently released contender thread may need to rewait.
To enqueue into a CLH lock, you atomically splice it in as new tail. To dequeue, you just set the head field.大致的意思是这样的:
等待队列节点类。
等待队列是“CLH”(Craig、Landin和Hagersten)锁定队列的变体。CLH锁通常用于自旋锁。相反,我们使用它们来阻止同步器,但使用相同的基本策略,即在其节点的前一个线程中保存一些有关线程的控制信息。每个节点中的“状态”字段跟踪线程是否应该阻塞。节点在其前任释放时发出信号。否则,队列的每个节点都充当一个特定的通知样式监视器,保存一个等待线程。状态字段不控制线程是否被授予锁等。如果线程是队列中的第一个,则线程可能会尝试获取。但第一并不能保证成功;它只赋予了竞争的权利。因此,当前发布的竞争者线程可能需要重新等待。
要排队进入CLH锁,您可以将其作为新的尾部自动拼接。要退出队列,只需设置head字段。
+------+ prev +-----+ +-----+
head | | <---- | | <---- | | tail
+------+ +-----+ +-----+
Insertion into a CLH queue requires only a single atomic operation on "tail", so there is a simple atomic point of demarcation from unqueued to queued. Similarly, dequeuing involves only updating the "head". However, it takes a bit more work for nodes to determine who their successors are, in part to deal with possible cancellation due to timeouts and interrupts.
The "prev" links (not used in original CLH locks), are mainly needed to handle cancellation. If a node is cancelled, its successor is (normally) relinked to a non-cancelled predecessor. For explanation of similar mechanics in the case of spin locks, see the papers by Scott and Scherer at http://www.cs.rochester.edu/u/scott/synchronization/
We also use "next" links to implement blocking mechanics. The thread id for each node is kept in its own node, so a predecessor signals the next node to wake up by traversing next link to determine which thread it is. Determination of successor must avoid races with newly queued nodes to set the "next" fields of their predecessors. This is solved when necessary by checking backwards from the atomically updated "tail" when a node's successor appears to be null. (Or, said differently, the next-links are an optimization so that we don't usually need a backward scan.)翻译:
插入CLH队列只需要对“尾部”执行一个原子操作,所以从未排队到排队有一个简单的原子分界点。同样,退出队列只涉及更新“头部”。然而,节点需要更多的工作来确定他们的继任者是谁,部分原因是要处理由于超时和中断而可能导致的取消。
“prev”链接(未在原始CLH锁中使用)主要用于处理取消。如果某个节点被取消,则其后续节点(通常)将重新链接到未取消的前一个节点。有关自旋锁的类似力学解释,请参阅Scott和Scherer在http://www.cs.rochester.edu/u/scott/synchronization/
我们还使用“下一步”链接来实现阻塞机制。每个节点的线程id都保存在自己的节点中,因此前一个节点通过遍历下一个链接来通知下一个节点唤醒,以确定它是哪个线程。确定后一个节点必须避免与新排队的节点竞争,以设置前一个的“下一个”字段。当一个节点的后继节点看起来为空时,这可以在必要时通过从原子更新的“尾部”向后检查来解决。(或者,换言之,下一个链接是一个优化,因此我们通常不需要反向扫描。)
Cancellation introduces some conservatism to the basic algorithms. Since we must poll for cancellation of other nodes, we can miss noticing whether a cancelled node is ahead or behind us. This is dealt with by always unparking successors upon cancellation, allowing them to stabilize on a new predecessor, unless we can identify an uncancelled predecessor who will carry this responsibility.
CLH queues need a dummy header node to get started. But we don't create them on construction, because it would be wasted effort if there is never contention. Instead, the node is constructed and head and tail pointers are set upon first contention.
Threads waiting on Conditions use the same nodes, but use an additional link. Conditions only need to link nodes in simple (non-concurrent) linked queues because they are only accessed when exclusively held. Upon await, a node is inserted into a condition queue. Upon signal, the node is transferred to the main queue. A special value of status field is used to mark which queue a node is on.
Thanks go to Dave Dice, Mark Moir, Victor Luchangco, Bill Scherer and Michael Scott, along with members of JSR-166 expert group, for helpful ideas, discussions, and critiques on the design of this class.翻译:
抵消给基本算法引入了一些保守性。由于我们必须轮询其他节点的取消,因此我们可能无法注意到被取消的节点是在我们之前还是在我们之后。这是通过在取消时始终取消后续节点的标记来解决的,允许他们稳定在一个新的前任节点上,除非我们能够确定一个未被取消的前任节点将承担此责任。
CLH队列需要一个虚拟头节点才能启动。但我们不会在施工中创建它们,因为如果不存在争议,这将浪费精力。相反,在第一次争用时构造节点并设置头指针和尾指针。
等待条件的线程使用相同的节点,但使用额外的链接。条件只需要链接简单(非并发)链接队列中的节点,因为它们只在独占时被访问。等待时,节点被插入到条件队列中。发出信号后,节点被转移到主队列。状态字段的特殊值用于标记节点所在的队列。
感谢Dave Dice、Mark Moir、Victor Luchangco、Bill Scherer和Michael Scott以及JSR-166专家组成员对本课程设计的有益想法、讨论和评论。
看个 AQS (AbstractQueuedSynchronizer)原理图借用知乎的一张图:
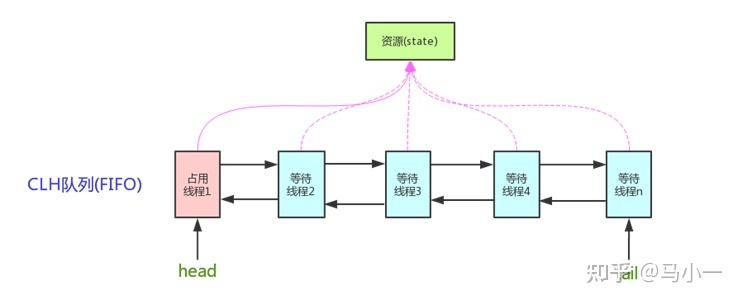
AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。
AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。

状态信息通过 protected 类型的getState , setState , compareAndSetState 进行操作