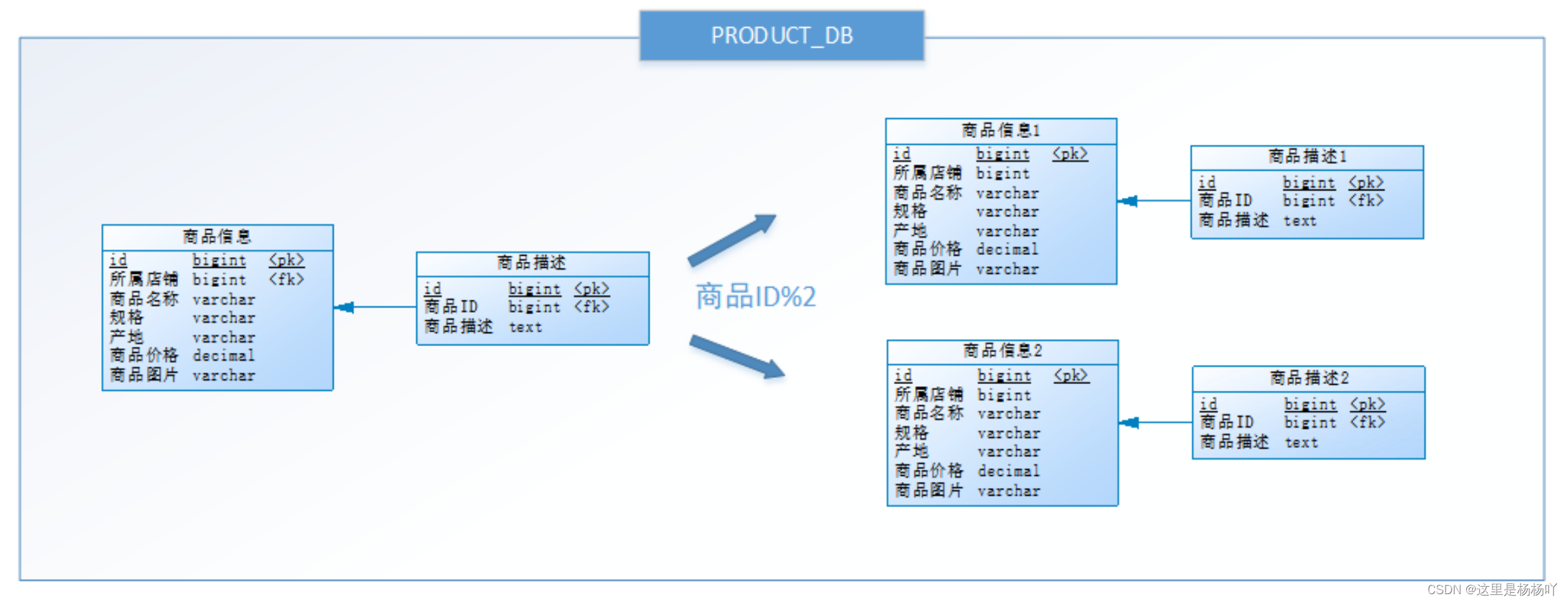
数据预处理
- 假设已经采集到一些数据,在进行训练之前,需要先对数据做以下预处理:
- 数据清洗
- 语音检测(Voice Activity Detection,VAD,也叫Speech Detection,或Silence Suppression,静音抑制)
- 特征提取与标准化(Normalization,注意要和归一化、正则化等说法区分)
- 数据分组
数据清洗
- 目的是提高数据的正确性,关于数据的正确性,可参考说话人识别的数据需求
- 出现数据错误,有以下原因
- 录音设备故障,得到破损的音频文件
- 人工操作失误,导致录制了纯噪声
- 标签反转
- 可以进行人工清洗,或自动化清洗。人工清洗对于标签反转是不可行的,而且效率低
- 对于前两种错误,可以采用以下自动化清洗办法
- 使用信噪比(Signal-to-noise Ratio,SNR)估计算法,例如:WADA-SNR,去除信噪比很低的音频
- 使用VAD算法,去除无法触发VAD的音频
- 使用语音识别(ASR)算法,去除文字结果为空,或者置信度很低的音频
- 对于第三种错误,可采用自监督清洗,步骤如下:
- 先使用,已经去除前两种错误的数据,训练一个初始的说话人识别模型
- 利用初始的说话人识别模型,为数据中的每一个说话人,计算一个说话人的中心点,关于说话人的中心点,可参考说话人识别中的损失函数
- 如果某个说话人的音频,距离该说话人的中心点非常遥远,那么这个音频可能是标签反转噪声,需要去除
- 自监督清洗有利有弊,优点在于效率高,缺点在于可能去除了困难样本
语音检测(VAD)
- 在一段音频中,可能包含语音、静默和噪声,如下图所示:
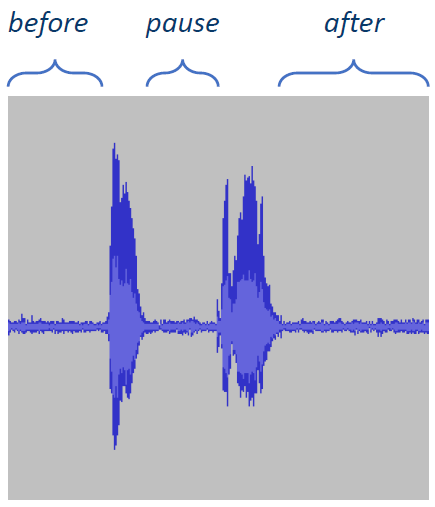
- 使用一个预训练好的VAD模型,去除静默和噪声的部分。VAD模型是对每一帧的二分类,去除那些分类为0的帧即可

特征提取与标准化
- 特征提取是指从音频中提取出MFCC、LFBE或PLP这样的特征
- 问题在于,应该在什么阶段进行特征提取,有两种做法:
- 离线特征提取
- 在训练之前,把数据集中,所有音频的特征提取出来,储存到硬盘上
- 训练时,直接读取这些特征,而不需要读取音频文件
- 优点:
- 提取出的特征可重复使用
- 容易debug
- 缺点:需要大量的额外硬盘空间
- 在线特征提取
- 训练时,直接读取音频文件,再提取特征
- 特征提取变为训练的一部分
- 优点:不需要额外的硬盘空间
- 缺点:
- 每次训练,特征提取都需要重复计算
- 训练过程变慢,消耗变大
- 不容易debug
- 离线特征提取
- 标准化是指对提取出的特征减均值,除标准差,使其均值为0,方差为1。还可以进一步操作,限制数值范围为
[
0
,
1
]
[0,1]
[0,1],或
[
−
1
,
1
]
[-1,1]
[−1,1]
- 限制为
[
0
,
1
]
[0,1]
[0,1]:
- 找出特征的最大值 x m a x x_{max} xmax和最小值 x m i n x_{min} xmin
- 对特征
x
∈
[
x
m
i
n
,
x
m
a
x
]
x \in [x_{min},x_{max}]
x∈[xmin,xmax]进行变换
x = x − x m i n x m a x − x m i n x=\frac{x-x_{min}}{x_{max}-x_{min}} x=xmax−xminx−xmin - 从而 x ∈ [ 0 , 1 ] x \in [0,1] x∈[0,1]
- 限制为
[
−
1
,
1
]
[-1,1]
[−1,1]:
- 找出特征的最大值 x m a x x_{max} xmax,假定 x ≥ 0 x \ge 0 x≥0
- 对特征
x
∈
[
0
,
x
m
a
x
]
x \in [0,x_{max}]
x∈[0,xmax]进行变换
x = x − x m a x / 2 x m a x / 2 x=\frac{x-x_{max}/2}{x_{max}/2} x=xmax/2x−xmax/2 - 从而 x ∈ [ − 1 , 1 ] x \in [-1,1] x∈[−1,1]
- 限制为
[
0
,
1
]
[0,1]
[0,1]:
- 问题在于,为什么要这么做?深度学习开始蓬勃的第一篇文章AlexNet也对数据集里的每一张图片减均值,除标准差,经典的 m e a n = [ 0.485 , 0.456 , 0.406 ] , s t d = [ 0.229 , 0.224 , 0.225 ] mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225] mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]就是从ImageNet中统计出来的
- 原因在于:
- 提取出的特征,其数值范围是不受控制的
- 神经网络的参数初始化,常常会采用高斯分布
- 如果不进行标准化,特征的数值范围与参数的数值范围差距太大,会导致收敛速度极慢
数据分组
- 这是使用广义端到端损失函数,训练说话人识别模型的独有步骤,关于广义端到端损失函数,可参考说话人识别中的损失函数
- 训练神经网络时,需要把数据打包成一个一个batch,而说话人识别的batch,应该包含:
- 多个说话人,数量记为 N N N
- 每个说话人应具有相同的话语个数,记为 M M M
- batch的维度为 N × M N \times M N×M
- 为了提高在训练过程中,从硬盘读取文件,构造batch的速度,需要对数据进行分组
- 高效的分组如下图所示,也就是按照batch中每个说话人应具有的话语个数进行分组,此时
M
=
4
M=4
M=4

- 即使在数据集中,每个说话人具有超过4个话语,也要按照上图的方式进行数据分组。每个说话人具有的多于4个的那部分话语,用于构造另一个batch
数据增强
- 数据的来源一般为数据采集和数据增强,数据增强是自动化、高效、低廉的数据产生方法,而且能提高数据的多样性
- 数据增强技术,一开始在计算机视觉领域得到非常普遍的应用,如下图所示:
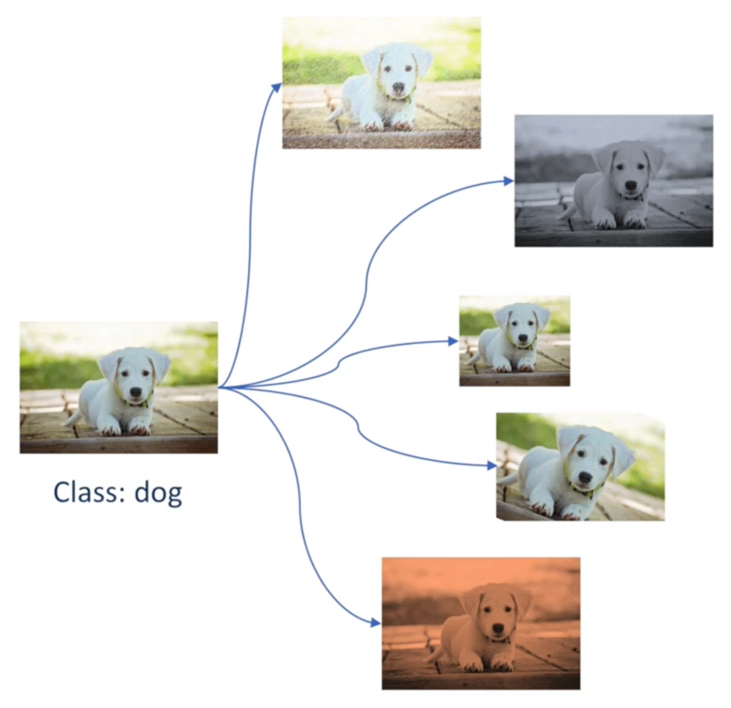
- 数据增强是基于原始数据的,上图中对原始的小狗图像进行了图像旋转、图像裁剪、颜色空间变换、添加噪声等操作,数据增强后,图像的标签不会变化,仍然是小狗,但是数据量变为原来的6倍,并且数据多样性提高了
- 说话人识别领域中,数据增强包括
- 时域增强(WavAugment)
- 检测扰动(Detection Perturbation)
- 时频谱增强(SpecAugment)
- 语音合成增强(Synth2Aug)
时域增强
- 常见的时域增强,包括:
- 音量:直接将整个信号乘以某个常数
- 采样率:对信号进行重采样,比如:将16000Hz信号重采样至8000Hz,以模拟有线电话的语音信号
- 语速:将音频的速度乘以某个在1附近的常数,比如:0.9、1.1
- 音高:随机偏移音频的基频
- 编码格式:将线性脉冲编码的音频,重新编码为MP3、Opus等格式
- 说话人识别中有一个比较重大的挑战——鲁棒说话人识别,也就是说希望说话人识别模型,对不同的声学环境也具备较高的性能
- 不同的声学环境包括:
- 安静的环境
- 有多种背景噪声的环境
- 带有房间混响的环境
- 为了让训练数据覆盖更多的声学环境,需要多风格训练(Multistyle Training,MTR)技术
- 假设我们需要下面的数据:
- 100个说话人
- 每个说话人具有10个话语
- 每个说话人在1000种不同的背景噪声下的话语
- 每个说话人在10种不同的房间混响下的话语
- 只通过数据采集产生上面要求的数据,需要的采集次数是 100 × 10 × 1000 × 100 = 1 , 0000 , 0000 100 \times 10 \times 1000 \times 100=1,0000,0000 100×10×1000×100=1,0000,0000,需要一亿采集,这是不可接受的
- 采用数据增强的方式产生数据:
- 使用一组参数描述一个房间,由于房间大多为立方体,所以可以用长度、宽度和高度来描述
- 确定信号源的位置,和录音设备的位置,可以用它们在房间中的立体坐标来描述
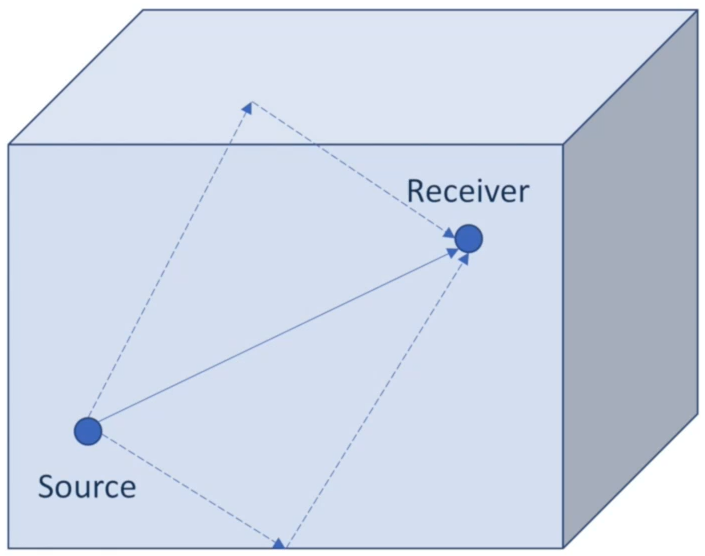
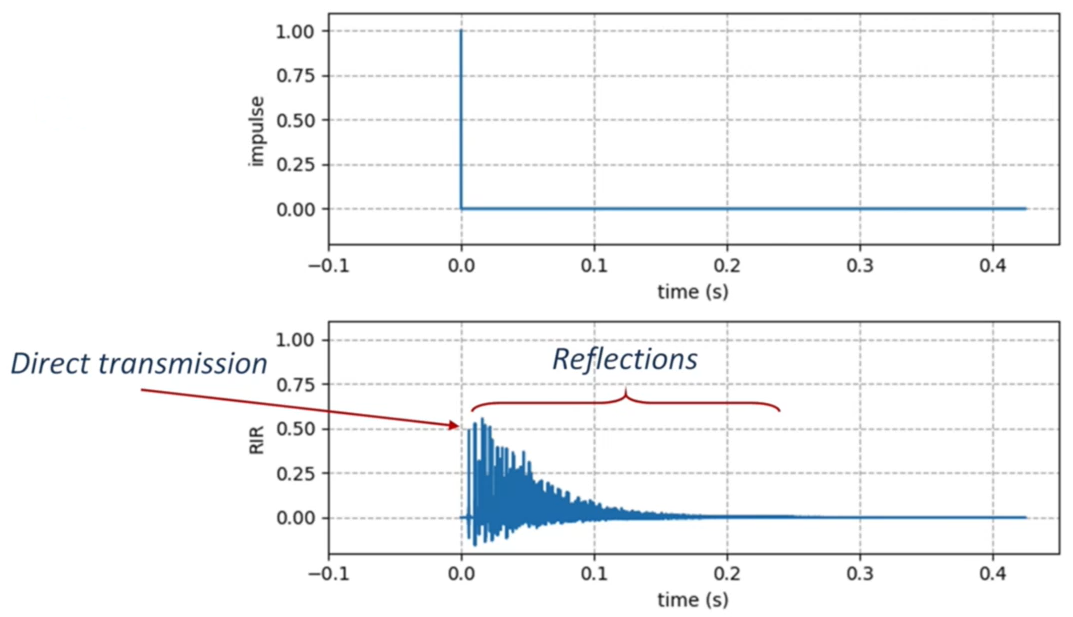
- 使用房间冲击响应(Room Impulse Response,RIR)的公式来描述该房间内,录音设备接受信号源的情况,包括:
- 信号源直线传播,到达录音设备
- 信号源沿其他方向传播,反射到录音设备
- 背景噪声和房间混响的数学形式:
- 信号源记为 x ( t ) x(t) x(t),对应的RIR记为 h s ( t ) h_s(t) hs(t)
- M M M个噪声源记为 n i ( t ) n_i(t) ni(t),对应的RIR记为 h i ( t ) h_i(t) hi(t)
- 假设还有一个加性的(Additive)的噪声源,记为 d ( t ) d(t) d(t)
- 增强后的信号记为
x
r
(
t
)
x_r(t)
xr(t)
x r ( t ) = x ( t ) ∗ h s ( t ) + ∑ i = 1 M n i ( t ) ∗ h i ( t ) + d ( t ) x_r(t)=x(t)*h_s(t)+\sum_{i=1}^{M}n_i(t)*h_i(t)+d(t) xr(t)=x(t)∗hs(t)+i=1∑Mni(t)∗hi(t)+d(t)
其中, ∗ * ∗号表示卷积运算
- 根据公式,我们可以:
- 分别采集语音信号、噪声信号和RIR
- 代入公式中,得到多种组合
- 通过加权,调整信噪比
- 相比起直接采集一亿个信号,我们只需要采集 100 × 10 + 1000 + 100 = 2100 100 \times 10 + 1000 + 100=2100 100×10+1000+100=2100个信号,然后采用多风格训练即可
检测扰动
- 在训练时,我们到底是把数据中的哪一部分喂给模型呢?
- 对于文本相关的说话人识别,数据需要先通过关键词检出(Keyword spotting,KWS)模型,得到关键词片段
- 对于文本无关的说话人识别,数据需要先通过VAD模型,得到语音片段

- 如果在训练时采用的KWS/VAD模型,与运行时采用的KWS/VAD模型不一致,就会导致说话人识别模型的性能下降
- 为了减少说话人识别模型,对特定KWS/VAD模型的依赖,我们可以采用检测扰动的数据增强方法,包括:
- 随机偏移KWS/VAD模型的输出
- 随机扰动KWS/VAD模型的阈值
时频谱增强
- 上面介绍的两种方法都是基于时域的,也就是说,是应用于波形图的,而时频谱增强则是应用于特征提取之后的时频谱图的
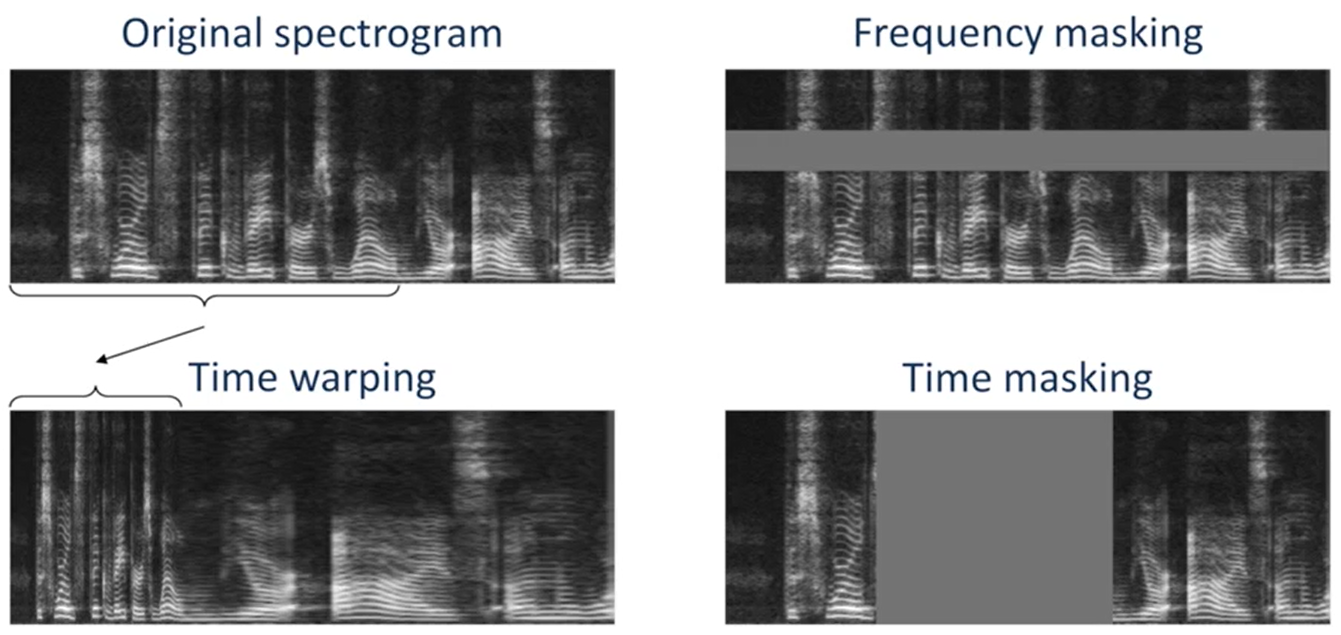
- 时频谱增强的做法有三种,如下图所示,左上角是原始数据
- 时域规整(Time Warping):在原始时频谱图上选定一个时间点,将时间点左边的部分进行挤压,右边的部分进行拉伸。如左下角所示
- 频域遮掩(Frequency Masking):将原始时频谱图,特定频率范围内所有的值,替换成原始时频谱图的均值。如右上角所示
- 时域遮掩(Time Masking):将原始时频谱图,特定时间范围内所有的值,替换成原始时频谱图的均值。如右下角所示
- 优点
- 实现简单,计算代价小
- 实现效率高,可用于在线特征提取,不需要用额外的硬盘空间存储
- 实验表明,时频谱增强对语音类任务,性能提升明显
- 注意,对标准化后的时频谱图,遮掩时只需要全部替换成0即可。实际上,标准化后的时频谱图,其均值为0
语音合成增强
-
根据说话人识别的数据需求,我们要求数据:
- 说话人的多样性
- 文本的多样性
- 录音设备和声学环境的多样性
-
上述的时频域增强和时域增强,提高了录音设备和声学环境的多样性。那么对于说话人和文本的多样性,就需要用到语音合成增强方法
-
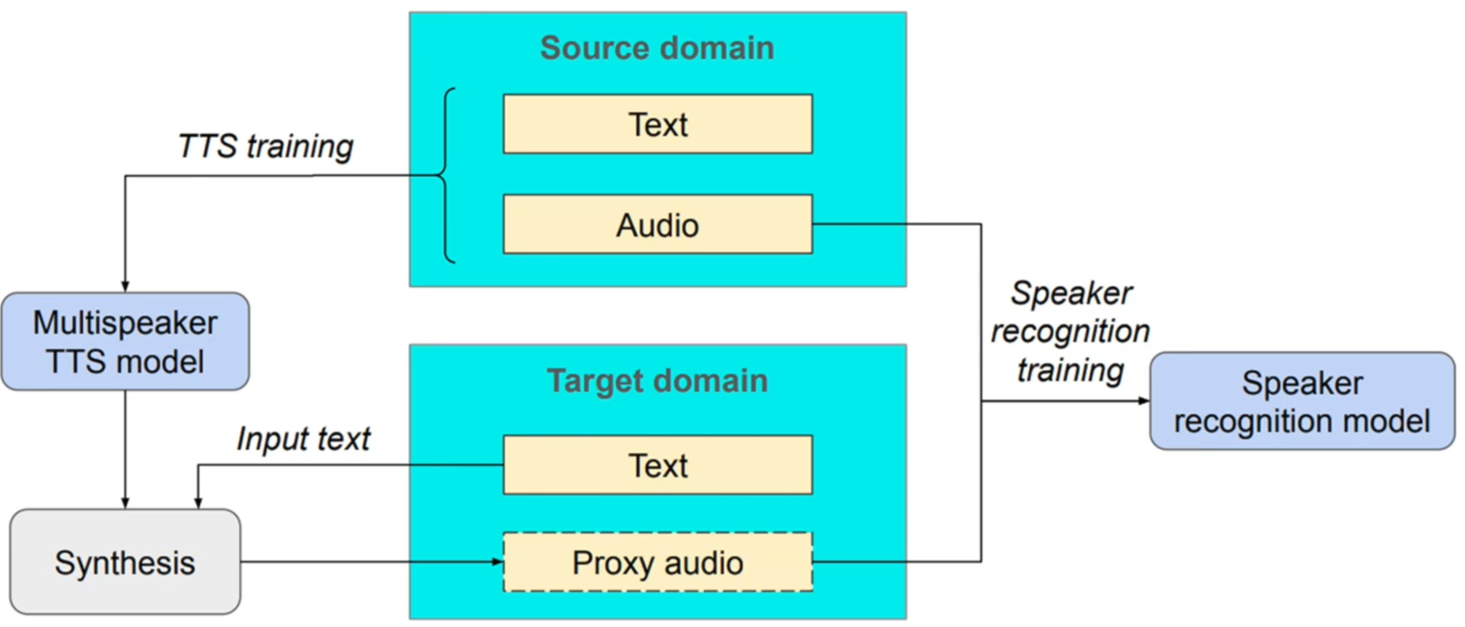
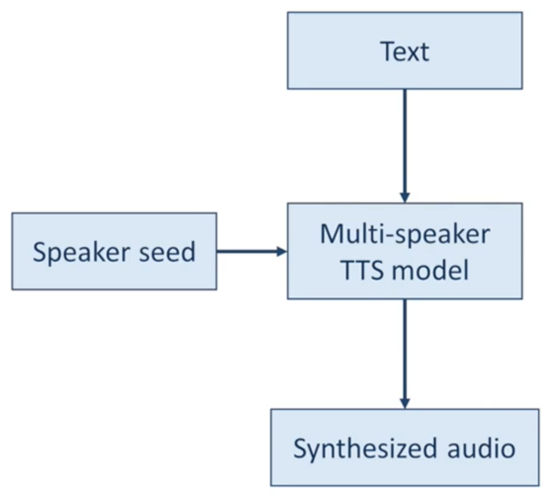
语音合成增强的核心在于,利用多说话人语音合成模型,输入说话人嵌入码和文本内容,就能合成对应的语音
-
关于多说话人语音合成模型,可参考Sample Efficient Adaptive Text-to-Speech
-
语音合成增强本质上是一个领域自适应问题:
- 有足够的源领域语音数据
- 不足的目标领域语音数据
- 有足够的目标领域文本数据
-
解决方案是:利用源领域的语音和文本数据,合成目标领域的语音数据。合成的数据并不是真正的目标领域数据,而是一种近似(Proxy)数据