问题描述
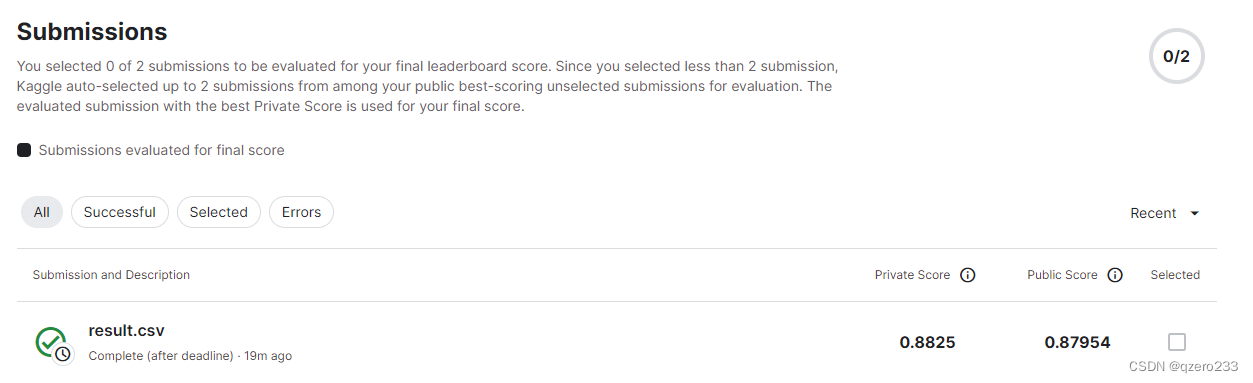
最近笔者在做一个kaggle上的树叶分类的题目(https://www.kaggle.com/competitions/classify-leaves),这个题目要求根据一张树叶的图片给出这片树叶的类别,这个题目也是沐神的《动手深度学习》课程里的一个课程竞赛题目。题目的数据集比较大,训练集有18000张224x224的图片,如果再加上测试集,那么一共有27000张图片
传统思路及其问题
一般而言,我们的处理方法是,自定义一个Dataset,然后根据这个Dataset创建DataLoader,然后进行训练
具体而言,定义Dataset有两种方法
方法1
在Dataset的构造函数中加载所有图片到显存里,然后get_item函数就只需要从构造函数里构造好的tensor中取出一部分来即可
大致的代码实现如下
from torch.utils import data
import torch
class MyDataset(data.Dataset):
def __init__(self):
self.img=read_all_img()
self.labels=read_labels()
pass
def __getitem__(self, item):
return self.img[item],self.labels[item]
train_iter=data.DataLoader(MyDataset(),batch_size)
这种方式有两个问题
- 加载时间非常长
之前测试过一次,如果一张一张地用opencv读取图片,再拼接tensor,加载完18000多张图片总共花了将近20分钟 - 有时候可能显存并不够
这才是最致命的一点,如果用这种方式加载的话,测试下来12GB显存的RTX3080已经跑不动了,24GB显存的RTX3090能勉强跑动,但是如果数据量再大一点点,或者模型参数再多一倍,那3090应该也是跑不动的
所以这种方式的可行性不是特别强
方法二
在初始化Dataset时,不加载具体的图片,而是把图片的路径加载好,在get_item时再去读取具体的图片
也就是下面代码所表示的思路
from torch.utils import data
import torch
class MyDataset(data.Dataset):
def __init__(self,img_paths):
self.img_paths=img_paths
self.labels=read_labels()
pass
def __getitem__(self, item):
img=read_img(self.img_paths[item])
return img,self.labels[item]
train_iter=data.DataLoader(MyDataset(),batch_size)
这种方法的问题就更大了,实测下来的问题就是一个字,慢,而且慢的要死
这其实也是可以预见的,我们一般的训练代码都是长下面这样的
for epoch in range(epochs):
net.train()
for X, y in train_iter:
optimizer.zero_grad()
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
每次循环中,读取到的X,y其实不止包含一张图片,而是包含batch_size张图片,而train_iter,也就是DataLoader,是一次一次地调用Dataset的getitem来获取一张图片的tensor,然后再拼接起来,形成一个batch的tensor
这个过程就涉及到大量的IO操作,是相当花时间的,相当于,每训练一个epoch,就需要经历一次读完所有图片的过程,按照上面测试下来的结果,也就会花将近20分钟的时间在读数据上,这显然是不能接受的
解决方案
Idea
如果从硬件的角度去思考问题,就很容易想到我们在计算机组成原理这门课上学到的一个trick,就是按块传输
就以cache和主存之间的数据交换为例子,同样是把4个字节的数据存入cache,我们有2种方式,一种是把4个字节视为一个块,把整个块的数据存入cache,另一种是先存1个字节,等需要下一个字节时再去主存找,然后存cache。显然,第一种更高效
由此,我们可以大胆的假设,一次性把512张图片读入显存所花费的时间是小于分512次把图片读入显存的时间,至于具体是不是这样,还需要实验来验证
解决思路
具体的解决思路如下:
(注:关于为什么是512张,是因为实验中batch_size取的是512)
首先要对图片进行预处理,把512张图片里的所有数据都存到一个文件里面
然后重写一个迭代器来替代DataLoader,每次就读出一个文件里的所有数据,然后变成图片tensor的形式,并存入显存,再交给训练模块
具体实现
项目完整代码已开源至github,具体见文末链接,为了文章观感,就不贴出完整代码了,以下就只贴出关键部分进行分析
- 图片预处理
首先是使用opencv读取一张图片
注意opencv读出的图片的格式是(高宽,通道),而我们需要的是(通道,高宽),所以这里要进行一些转换
这些转换完全可以放到训练之前来做,我们直接把转换之后的图片数据存入文件,到时候训练时读出便可直接使用,这样又可以节省一些读取数据的时间
def read_img_to_numpy(path):
img = cv2.imread("classify-leaves/"+path)
img = np.concatenate(
(img[:, :, 0].reshape((1, img_size, img_size)), img[:, :, 1].reshape((1, img_size, img_size)),
img[:, :, 2].reshape((1, img_size, img_size))),
axis=0)
return img
接下来就是把图片数据保存到文件里面
由于每张图片都是由3*224*224个无符号整数组成的,每个无符号整数占1个字节,所以很自然的,有一个思路就是把这3*224*224个字节以追加的方式写入文件中
具体代码如下
def append_img_to_file(img_path,file_name):
img = read_img_to_numpy(img_path).reshape((-1))
f = open(file_name, "ab+")
for x in img:
f.write(x.tobytes())
f.close()
- 读取图片
读取的时候需要考虑到整体性,要尽量让所有数据一次性到位,不做其他的处理
这里使用了torch的frombuffer函数,这个函数可以使用一个bytes直接构造tensor,这也正合我们的意,因为我们图片文件里面的数据本来就很规整,直接读取再进行reshape就可以得到我们需要的一个batch的图片数据
需要注意一下的就是,frombuffer里面的dtype是要指定这个bytes的数据类型,我们这里需要指定为8位的无符号整数,也就是uint8,之后才能转为float32
def read_all_img_from_file(file_name,device):
size=os.path.getsize(file_name)
f = open(file_name, "rb")
result = f.read(size)
result=torch.frombuffer(result, dtype=torch.uint8).to(device=device, dtype=torch.float32).reshape((-1, 3, img_size, img_size))
return result
- 自定义迭代器
这部分就很简单了,就只需要调用之前写好的读函数即可
class ImageDataLoader:
def __init__(self,batch_list,batch_size,device="cpu"):
self.batch_list=batch_list
self.batch_size=batch_size
self.current_batch_index=0
self.device=device
# read labels and mapping
labels=pickle.load(open("data/labels.dump","rb"))
self.labels=torch.tensor(labels,dtype=torch.int64,device=device)
self.label_map=pickle.load(open("data/label_map.dump","rb"))
def __iter__(self):
self.current_batch_index=0
return self
def __next__(self):
if self.current_batch_index==len(self.batch_list):
raise StopIteration
# read batch
index = self.batch_list[self.current_batch_index]
labels = self.labels[index * self.batch_size:
min((index + 1) * self.batch_size, len(self.labels))]
start_time=time.time()
# print(f"Try to read batch {index}")
file_name = f"data/batch_{index}.bin"
imgs = read_all_img_from_file(file_name,self.device)
imgs = torch.tensor(imgs, dtype=torch.float32, device=self.device)
# increase index
self.current_batch_index += 1
end_time=time.time()
delta=end_time-start_time
# print(f"Read batch {index} with {len(labels)} samples in {delta} seconds, {len(labels)/delta} samples per second")
return imgs, labels
这里打印计时结果的代码注释掉了
这个迭代器的主要思想就是,传入需要读取的batch的下标,然后依序把这些batch给读出来
这里传入的是list而不是起始下标,这样设计主要是为了方便构造k折交叉验证的数据集,因为训练集所涉及的batch的下标往往是不连续的
实验结果
如果是以一张一张地读的方式,实测下来效率大概是每秒13张图
如果按照上述的批量读取方式,实测效率可达到每秒1100张图,读取一个批量用时不到1秒,可见这种数据读取方式的效率是明显更高的
总结
数据预处理其实也是深度学习中常有的事,其目的是为了缩短训练时间,将小文件转成大文件以节省IO成本,这也是一种很常见的处理方式,比如tensorflow里面的tfrecord
但是这类处理有时候是会有其他的代价,例如本文中的提到的方式,在处理之后文件的大小很明显增加了,光是18000张训练图片就占了大约2628MB的磁盘空间,而原来的27000张图片只占了大约200MB的磁盘空间。推测可能是jpg图片有特殊的压缩技术,不过正好也算是在数据预处理阶段做完了jpg图片“解压缩”的任务
如果需要进一步提高效率,可以考虑使用多线程来读取文件,由于1100张图片每秒的速率已经足够进行训练了,所以笔者也就偷个懒,不再进行深入研究了,感兴趣的读者可以自己动手尝试一下
最后,如果本文的内容有任何错误或疏漏,欢迎大家批评指正,也欢迎大家在评论区里或私信里发表自己的意见,你们的支持是笔者持续创作的最大动力!
附录
项目github地址:https://github.com/QZero233/LeafClassify
(注:这个解法是用了ResNet,目前做出来的最好的准确率是88%,目前正在努力尝试突破到90%,如果大家有想法也欢迎在评论区或私信里探讨)