数据结构与算法——Java实现排序算法(一)_我爱布朗熊的博客-CSDN博客
七、希尔排序(自我感觉有点难理解)
为了解决直接插入排序所带来的弊端,我们接来下看一下希尔排序
希尔排序也是一种插入排序,简单插入排序经过改进之后的另一个更高效的版本,也成为了缩小增量排序
希尔排序是把记录按下标的一定增量分组(分组并没有按照顺序),对每组使用直接插入排序算法排序
随着增量逐渐减少,每组包含的关键词越来越多,当增量减到1时,整个文件恰被分到一组,算法便终止
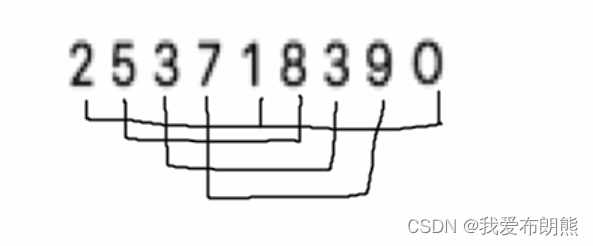
7.1 思路分析
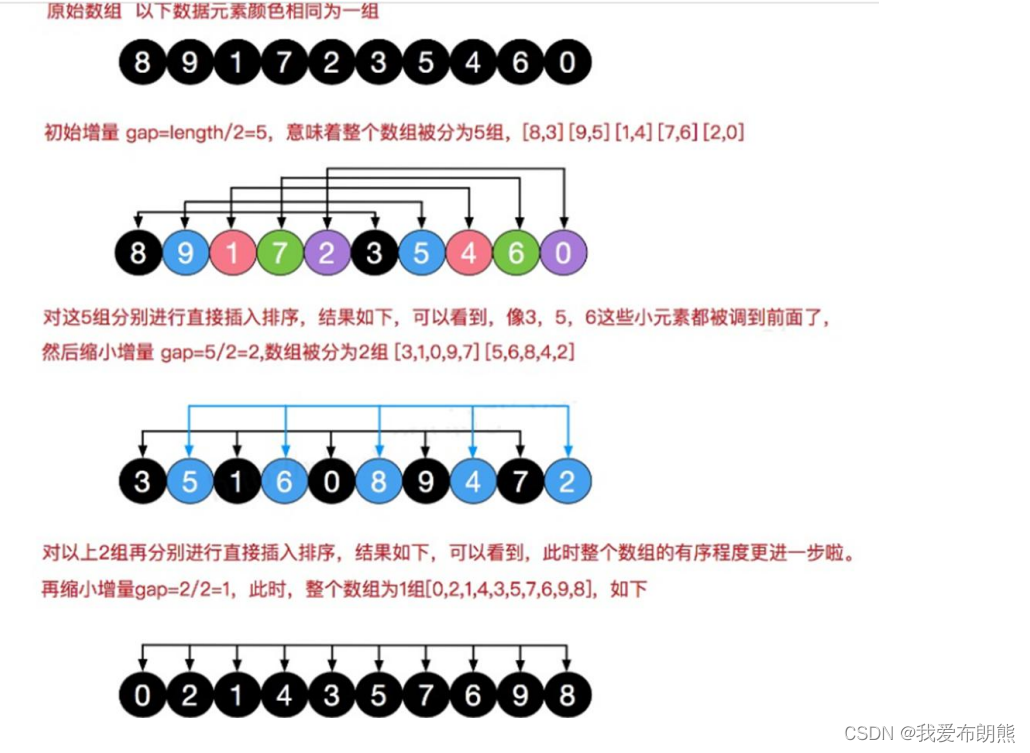

很多人会想,那上面的数量刚好是凑好的,那要是凑不好怎么办呢?
我们看一下下面的数据,第一组中的数据有三个,其他组的数据有两个,不过也不耽误我们的运行
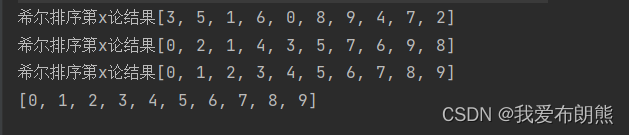
7.2 希尔排序交换式算法实现(交换式,速度慢)
public class ShellSort {
public static void main(String[] args) {
int[] arr = {8,9,1,7,2,3,5,4,6,0};
shellSort(arr);
System.out.println(Arrays.toString(arr));
}
// 编写希尔排序
public static void shellSort(int[] arr){
int temp=0;
// gap是步长,也表示会分成几组,步长为5则表示分成5组
// 最外面这个for循环控制分组
// 控制排序中一共会分成几组,怎么分
for(int gap = arr.length/2 ; gap>0 ; gap/=2){
// 第二个for循环和第三个for循环可以看做一体的
// 此for循环是为了确定分组之后的每个小组内的数据可以比较,这样我们一个for循环就搞定了
// i=5,6,7,8,9 则i-gap对应0,1,2,3,4
for(int i=gap;i<arr.length;i++){
// 遍历各组中的所有元素,比较大小
// i-gap 相当于是第几组内的比较,j-=gap表示隔着一个步长的距离才是同一个小组
for(int j=i-gap;j>=0;j-=gap){
// 我们把小的放到左侧
if(arr[j]>arr[j+gap]){
temp=arr[j];
arr[j]=arr[j+gap];
arr[j+gap]=temp;
}
}
}
System.out.println("希尔排序第x论结果"+ Arrays.toString(arr));
}
}
}
public static void shellSort(int[] arr){
int temp=0;
for(int gap = arr.length/2; gap>0 ; gap =gap/2){
// gap的每次循环遍历都要比之前少一半,故除2
// 我们根据步长分了一个组,所以我们要给每个组排序一下
for(int i=gap ;i<arr.length; i++){
// 遍历本组的所有元素,然后进行比较,如果本组中与三个元素的话,就运行三次
// j可以等于0,因为下标可以为0
for(int j=i-gap;j>=0;j=j-gap){
if(arr[j]>arr[j+gap]){
temp=arr[j];
arr[j]=arr[j+gap];
arr[j+gap]=temp;
}
}
}
}
}
7.3 希尔排序移位式算法实现(插入式,效率高)
就是相当于不断的往后移动,最终会空出来一个位置,插进去
// 希尔排序移位法
public static void shellSort2(int[] arr){
// 增量gap,逐步缩小增量,gap是步长,也表示会分成几组,步长为5则表示分成5组
// 最外面这个for循环控制分组
// 控制排序中一共会分成几组,怎么分
for(int gap = arr.length/2 ; gap>0 ; gap/=2){
for(int i=gap;i<arr.length;i++){
// 进行插入,先假设插入到下表为j处
int j=i;
// 临时指针,先存储一下
int temp =arr[j];
// 找位置
// j-gap>=0防止数组下标不规范,出现小于零的状况
// 因为我们想把打的插到后面,所以小的进入循环 temp< arr[j-gap]
while (j-gap>=0 && temp< arr[j-gap]){
// 移动,说明arr[j-gap]大
arr[j] =arr[j-gap];
j=j-gap;
}
// 退出for循环之后,说明我们找到位置了
// 这个地方实现插入
arr[j]= temp;
}
}
}
八、快速排序
快速排序是对冒泡排序的一种改进。
8.1 思路分析
基本思想:通过一趟排序将要排序的数据分割成独立的两部分,将一部分数据的所有数据都比另一部分的所有数据都要小,然后再按此方法对两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
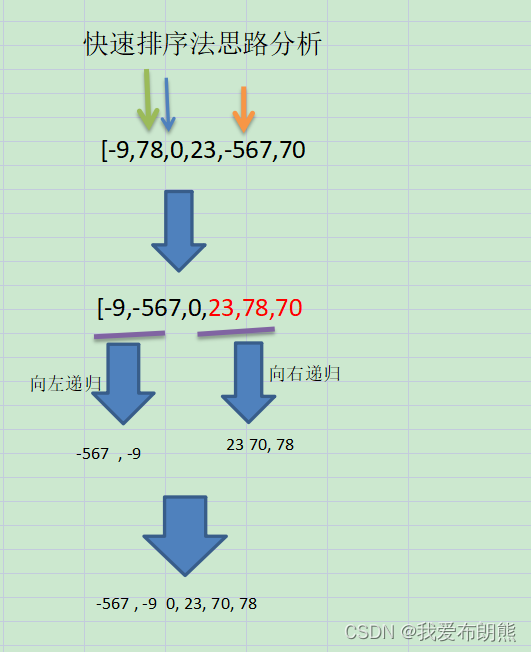
切分原理:
- 找一个基准值,用两个指针分别指向数组的头和尾部;
- 先从尾部向头部开始搜索,找一个比基准值小的元素,搜到便停止,并记录指针的位置;
- 再从头部向尾部开始搜索,找一个比基准值大的元素,搜到便停止,并记录指针的位置;
- 交换当前左边指针位置和右边指针位置的元素;
- 重复2,3,4步骤,直到左边指针的值大于右边指针的值为止
如下图所示
数组下标最大值是5,故5/2=2,所以选择下标为2处的值,刚好是0。 至于到底怎么选,自己指定就行,我们在这里指定选数据中心作为分割。
绿线最开始在最左侧,黄线最开始在最右侧
8.2 代码实现
public class QuickSort {
public static void main(String[] args) {
// int[] arr={ -9,78,0,23,-567,70};
// 全局操作的就是同一个数组
int[] arr={ -9,0,0,23,-567,70};
quickSort(arr,0,arr.length-1);
System.out.println(Arrays.toString(arr));
}
/**
*
* @param arr 要排序的数组
* @param left 左侧的索引
* @param right 右侧的索引
*/
public static void quickSort(int[] arr,int left,int right){
int l =left;
int r = right;
int temp =0; //临时变量,交换时使用
// 中轴数据
int pivot = arr[(l+r)/2];
// while循环的目的:让比pivot小的值放到左边,比pivot大的值放到右边
while(l<r){
// 要从左边找出大于等于pivot的元素
while(arr[l]<pivot){
// 退出循环的话说明arr[l]>=pivot,此时我们要把这个arr[l]放到pivot的右侧
l+=1;
}
while (arr[r] >pivot){
// 退出循环的话说明arr[l]<=pivot,此时我们要把这个arr[l]放到pivot的左侧
r-=1;
}
// 一会去掉这一个语句
// 左侧均小于等于pivot,右边全部是大于
// 如果说明false,说明左右还没有遍历完成
if(l>=r){
break;
}
// 交换
temp =arr[l];
arr[l] =arr[r];
arr[r]=temp;
// 如果交换完后,发现arr[l] == pivot 相等,向前移动一步
// 没有下面这两个if会进入死循环
if(arr[l] == pivot){
// 往头部移动
r-=1;
}
if(arr[r] == pivot){
// 往尾部移动
l+=1;
}
}
// 如果l==r ,必须l++,r--,否则为出现栈溢出
// 换个理解方式:我们l==r的时候一般在pivot点,这个中间点不能带入
if(l==r){
l+=1;
r-=1;
}
// 还有向左递归,向右递归
// 向左递归 left=r的时候说明已经就剩下一个数了,不用再递归了
if(left<r){
quickSort(arr,left,r);
}
// 向右递归 当right=l的时候,说明就剩下一个数了,不用再递归了
if(right>l){
quickSort(arr, l, right);
}
}
}8.3 思路分析(另外一种实现,这个好懂)
说实话,在我分析8.1的时候我分析的很明白,但是继续学习的时候写代码的时候能读懂一部分,剩下的一部分模棱两可,所以我又从新找了一个视频看,就有了下面的这种方式
也可以看下图的例子
下图中的基准都是以数组最后一个数为基准,这个基准在合理范围内自己定义就行
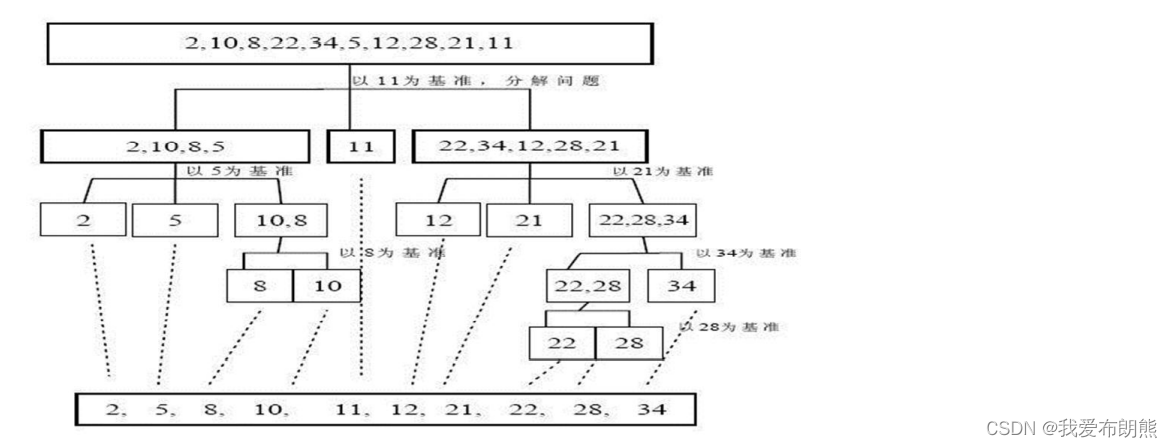
下面是选择在了头部为比较值,这个随便怎么选,能实现就行
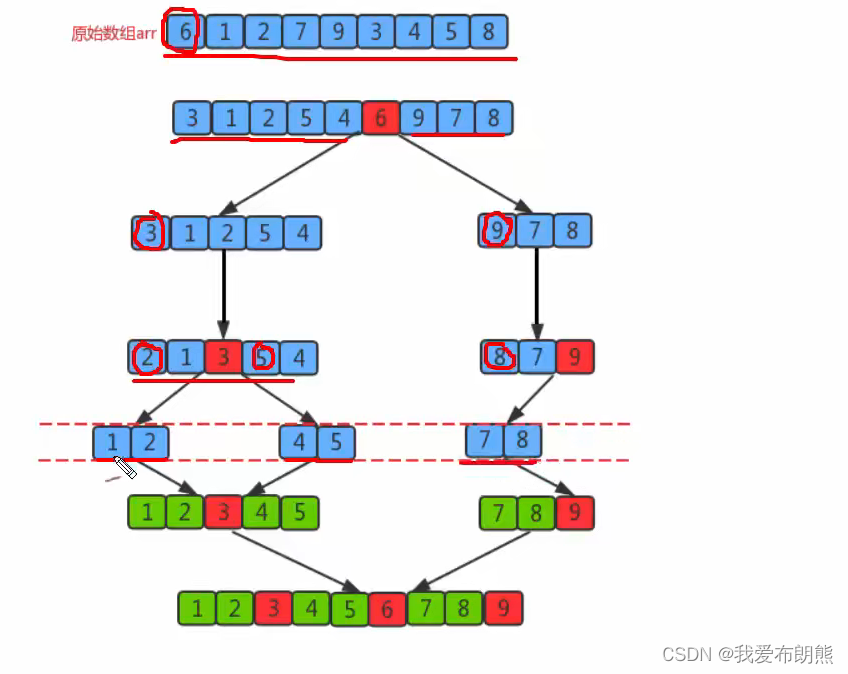
为了更能明白,我们就一步一步的做一遍
我们选取下面一组数据,我们以每组的第一个数作为基准值,下组的基准值就是三,我们写到右边记录一下 。
再次之前,我们先设置一个头部指针和尾部指针,头向尾部移动,尾向头部移动,如下图所示。
约定把比基准值小的放到基准值的左边,大的放到基准值的右边

我们先从右边遍历,先遍历到6,6是比3大的,而且就是在3的右侧,所以不用管。

尾指针向左移动到2,我们发现2比3小,然后将2覆盖3,如下图所示

此时我们不再移动尾指针了,我们移动头指针,头指针移动到5,发现5比3大,然后用5覆盖尾指针2所在的位置

此时我们再移动尾指针,将尾指针移动到1处,发现1比头指针处的5小,故用1覆盖头指针处的5

此时再移动头指针,把头指针往后移动到7处,7比3小,将头指针处的7覆盖尾指针处的1

此时再移动尾指针到5,发现五比三大,又将尾指针移动到9,9也比三大,又将尾指针移动到8,最终移动到7,此时头指针和尾指针重合了

此时此组的排序已经接近尾声,然后把3覆盖头指针和尾指针重合的位置,此时也将数组分成了两部分,左边比三小,右边比三大

同样的方式,我们也可以排序左边和右边,无限递归完成排序
那递归结束的条件是什么?每组中只有一个元素,即开始和结束都是一个地方,此时递归结束
8.4 代码实现(这个清晰好懂)
public class QuickSort {
public static void main(String[] args) {
int[] arr = new int[]{3,4,6,7,2,7,2,8,0};
quickSort(arr,0, arr.length-1);
System.out.println(Arrays.toString(arr));
}
public static void quickSort(int[] arr,int start,int end){
if(start>=end){
// 满足这个条件,就就说明数组的小分组中就还有一个元素,就不用分组了
return;
}
// 基准数
int pivot = arr[start];
// 两个指针坐标,记录下标
int left = start;
int right = end;
// 循环找数字替换,比标准数小的在左,大的的在右
// left=right,两个相等的时候,说明已经遍历了一遍了从头到尾
while(left<right){
// 先从右侧开始遍历,只要小的
while (left<right && pivot <=arr[right]){
// 进入到此时,说明基准数小,我们继续移动尾部指针向前
right--;
}
// 退出while循环说明我们找到了比基准数小的数据
// 使用尾部指针处的数据替换头部指针出的数据
arr[left] = arr[right];
// 下面移动头部指针,只找大的
while(left<right && pivot>=arr[left]){
// 如果左边的数比标准数小的话不用交换数据,把头指针往后移动
left++;
}
// 退出while循环说明头指针找了的比基准数大的
// 使用头指针处的数据替换尾指针处的数据
arr[right]=arr[left];
}
// 大循环结束说明左右指针在同一个位置,将标准数填入到这个位置
// 这个地方没有if语句也行
if(left==right){
arr[left] =pivot;
}
// 上边已经实现一边高一边低了
// 这个地方也可以 quickSort(arr,start,left-1);quickSort(arr,right,end);
// 因为此时right和left是一个位置,我们只要保证下面有一个能遍历到就行了,但是不能是两个都遍历到
// 左侧递归
quickSort(arr,start,left);
// 右侧递归
quickSort(arr,right+1,end);
}
}
九、归并排序
利用归并的思想实现排序的方法,该方法采用经典的分治策略。
分治法将问题的分是分成一些小的问题然后递归求解,而治的阶段则将分的阶段得到的各答案“修补”在一起,即分而治之。
9.1 思路分析
合并的时候会有排序
下面这组数据一共合并了七次,一共有八个数据
如果有10000个数据,会合并9999次,合并的次数是一个线性增长
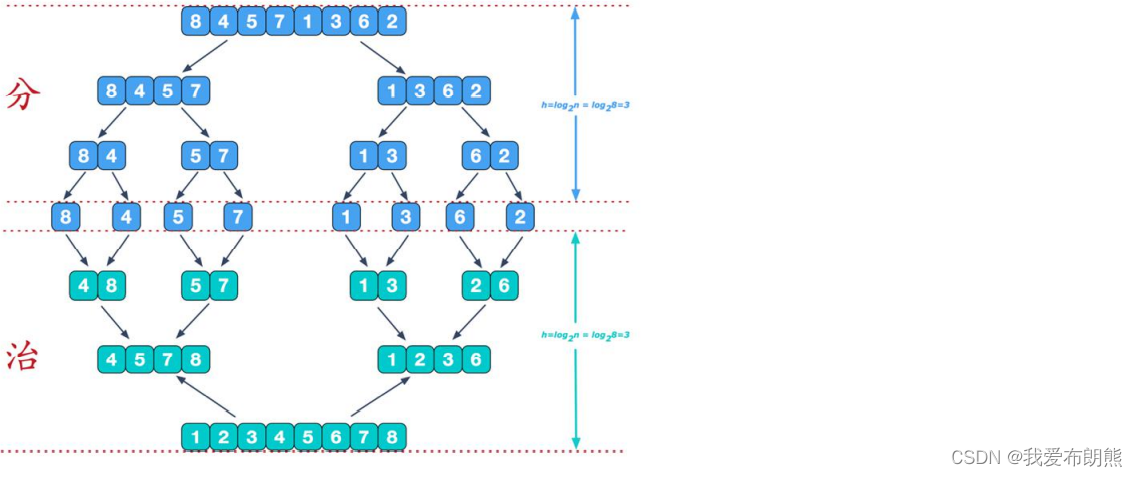
下面蓝色的那个数组就是一个临时数组
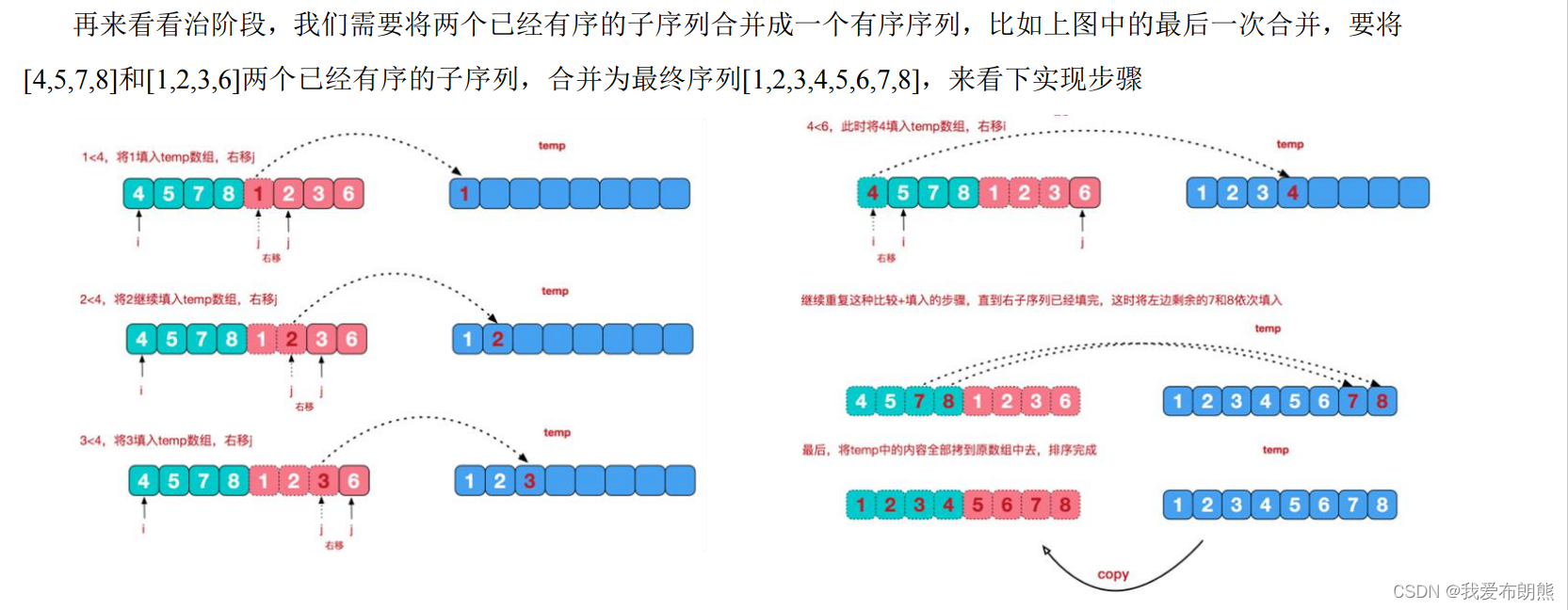
下面的这个图比较具体,因为比较大,所以看起来很不清晰,放大凑活看把自己做的,序号是执行顺序
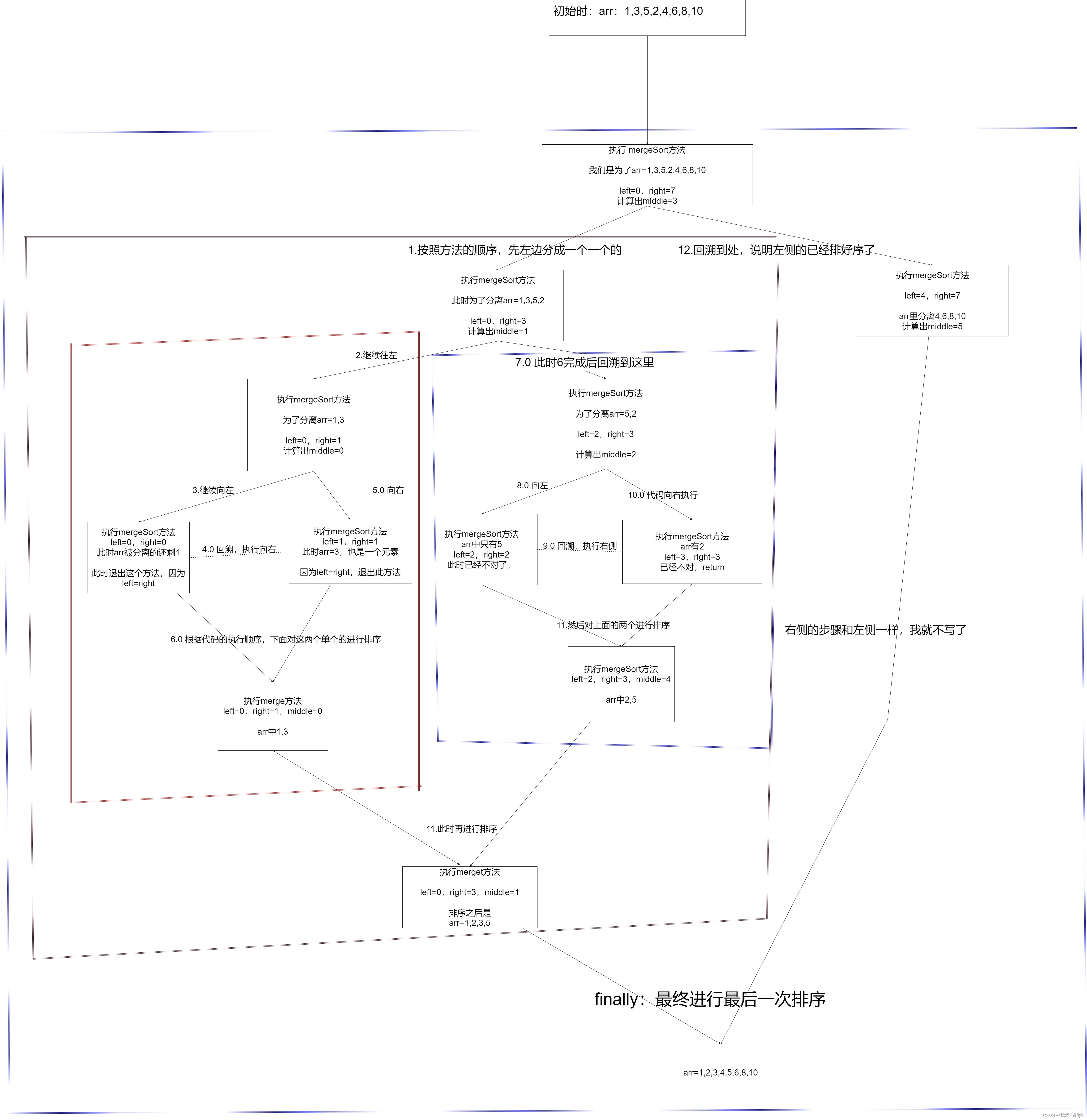
9.2 代码实现
public class MergeSort {
public static void main(String[] args) {
int[] arr = new int[]{1,3,5,2,4,6,8,10};
// 右边的范围
mergeSort(arr,0,arr.length-1);
System.out.println(Arrays.toString(arr));
}
public static void mergeSort(int[] arr,int left,int right){
int middle=(left+right)/2;
// 什么时候递归结束?
if(left>=right){
// 这显然left>=right是不对的,如果满足此条件,我们就可以退出了
// 其实这种情况下就只有一个元素了
return;
}
// 先进行分组,将其分成一个一个的
// 处理左边:处理每次分组的左边 left,middle这是一个范围
mergeSort(arr,left,middle);
// 处理每次分组的右边 middle+1,right这又是一个范围
mergeSort(arr,middle+1,right);
// 经过上面的分组,最终数据就会被分成一个一个的
// 归并
merge(arr,left,middle,right);
}
/**
*
* @param arr 数组
* @param left 左侧数组的最左侧
* @param middle 从哪个地方将数组分成两块,这个middle一般指右边那一块的第一个元素,因为并不能指向中间的切割的那条线
* @param right 右侧数组的最右侧
*/
public static void merge(int[] arr, int left ,int middle,int right){
// 用于存储归并后的临时数组
int[] temp = new int[right-left+1];
// 其实就是在一个数组中,我们为了形象点说明,引出了第一个数组第二个数组的说法
// 记录第一个数组指针的位置
int l =left;
// 记录第二个数组中指针的位置,从middle+1的位置开始,middle下标处的数据在第一个数组
int r =middle+1;
// 用于记录放在temp数组的哪个位置
int index =0;
// 作用:遍历两个数组,取出小的数字放入临时数组中
while(l<=middle && r<=right){
// 一直循环比较然后放入临时数组,直到有一边遍历完成为止
if(arr[l]<=arr[r]){
// 进入到if语句说明左侧数组的下标为l的元素小,先放到临时数组
temp[index]=arr[l];
// 然后左侧的指针向右移动
l++;
index++;
}else{
// 此时是右侧数组r对应的数据更下,放到临时数组
temp[index]=arr[r];
// 也是加加,因为我们是从middle+1开始算的
r++;
index++;
}
}
// 从while循环中出来了,可能都遍历完成了两侧,也有可能其中的一侧没有遍历完
// 如果没有遍历完怎么办?
// 把剩下 的数据放入临时数组就行
while(l<=middle){
// 如果进入到循环说明左侧有些数据没有放入到临时数组中
temp[index]=arr[l];
l++;
index++;
}
while(r<=right){
// 如果进入到循环说明右侧有些数据没有放入到临时数组中
temp[index]=arr[r];
r++;
index++;
}
// 运行到这里说明左右都放入到临时数组了
// 将临时数组中的数据放入到arr
// arr=temp; 不能直接赋值
for(int i=0;i<temp.length;i++){
arr[i+left] = temp[i];
}
}
}
十、基数排序
属于分配式排序,又称“桶子法”,或bin sort,它是通过键值的各个位的值,将要排序的元素分配到某些“桶”中,达到排序的作用(这些桶其实就是一个数组,我们要准备十个桶,从0到9)
技术排序属于稳定性排序,基数排序法是效率高的稳定性排序法
基数排序是桶排序的扩展
将整数按位数切割成不同的数字,然后按每个位数分别比较
10.1 思路分析
并没有递归的过程,具体要进行几轮取决于最大位的位数,如果是三位就三轮,四位就四轮
- 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。
- 然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。

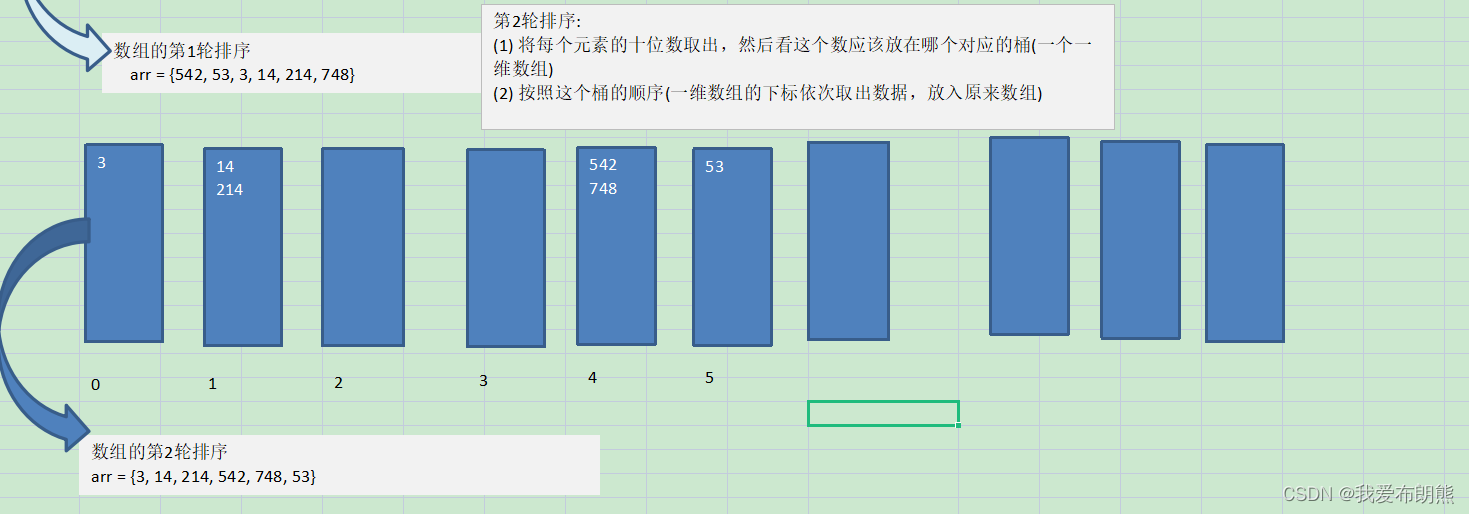
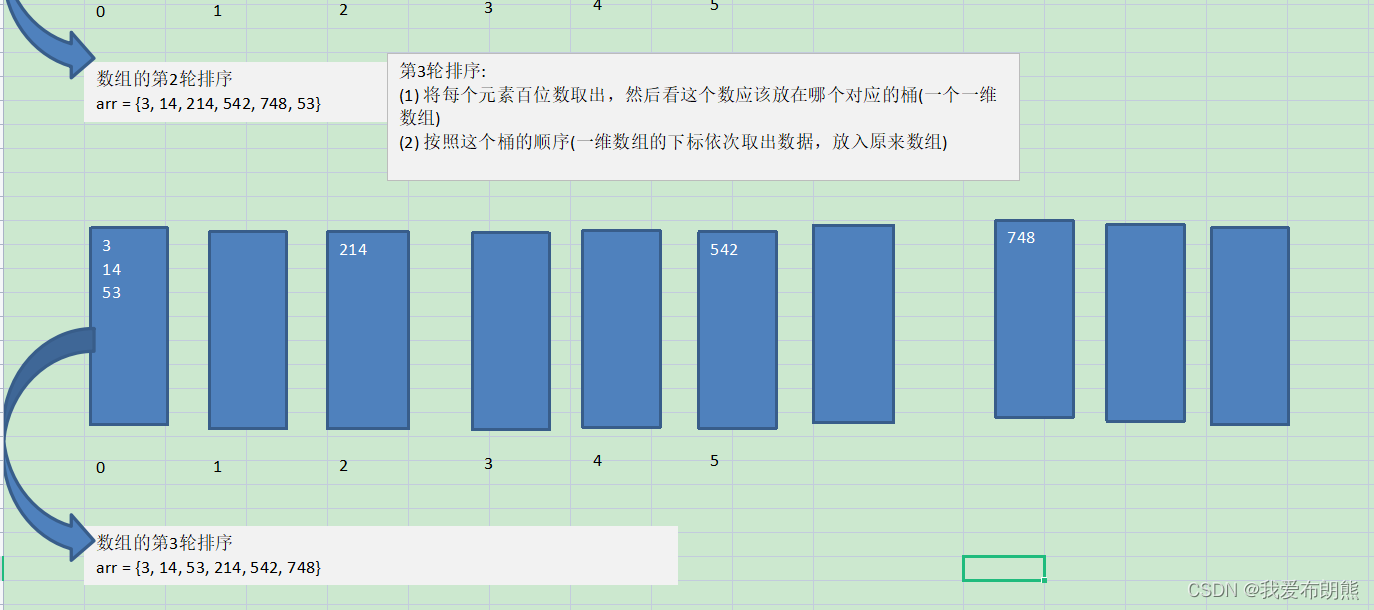
10.2 代码实现
public class RadixSort {
public static void main(String[] args) {
int[] arr= new int[]{23,6,189,45,9,287,56,1,798,34,65,652,5};
radixSort(arr);
System.out.println(Arrays.toString(arr));
}
// 我们这个算法其实是按照最大的那个数字是几位数,我们就排几轮
// 比如最大的是三位数,我们就排三轮,最大的是四位数,我们就排四轮
public static void radixSort(int[] arr){
// 1.找数组中最大的数字
int max = Integer.MIN_VALUE; //Integer.MIN_VALUE=-2147483648
for(int i=0;i<arr.length;i++){
if(arr[i]>max){
max=arr[i];
}
}
// 2.判断最大的那个数字是几位数,由最大位的几位数决定比较的次数
// 方法:将最大数变成普通字符串,然后调用length方法
int maxLength = (max+"").length();
// 3. 定义临时存放数据的数组(二维数组)
// 10:代表着捅,0-9是个捅
// arr.length:代表着每个捅最多存放的数据,就是我们打算排序的数组的长度
int[][] temp = new int[10][arr.length];
// 此数组记录十个桶中每个捅下一个元素应该排放到哪个位置,初始值都是0,代表着应放在下标为0处
int[] count = new int[10];
// 4. 开始取余数,往临时数组中存
// 为什么要定义n变量?
// 因为我们比较个位数很好比较,将一个数除10取余即可,
// 但是十位数的话,我们得除10,再除10取余
// 百位数,我们的先除100,再除10取余
// .......
for(int i=0,n=1;i<maxLength;i++,n*=10){
// 4.1 将数据存入临时数组
// 把每一个数字分别计算余数
for(int j=0;j< arr.length;j++){
// 拿到数组中的每个数的余数
int ys = arr[j]/n%10;
// 把当前余数放到临时数组的指定位置
temp[ys][count[ys]] = arr[j];
// 往后移动一次,代表着这个捅下此存放到下表为count[ys]++处
count[ys]++;
}
// 4.2 将数据从临时数组中取出
int index =0;
// 遍历count数组之后我们才知道对应temp临时数组中每个捅需要取出多少元素
for (int k =0;k< count.length;k++){
if (count[k]!=0){
// 说明有数据 count[j]=1,,说明有一个数据,等于2说明有两个数据,循环取出
for (int l=0;l<count[k];l++){
arr[index]= temp[k][l];
index++;
}
// 把数量置为0,然后我们后面大规律还会用到这个count数组(我们后面还会比较好几轮)
count[k]=0;
}
}
}
}
}
10.3 基数排序优化
我们可以将上面的代码进行优化
具体思想:因为我们上面的数组存和取的时候很像我们之前学的队列(先进先出原则,先放进去的先去,我们怎么放进去的怎么取出来),下面用队列的形式进行优化
用队列的数组代替暂时存放数据的整数二维数组,此时队列数组的长度依然是10,代表从0-9这10个捅,并且不需要记录每个捅放多少数据的count数组
3.9 基数排序之队列实现_哔哩哔哩_bilibili
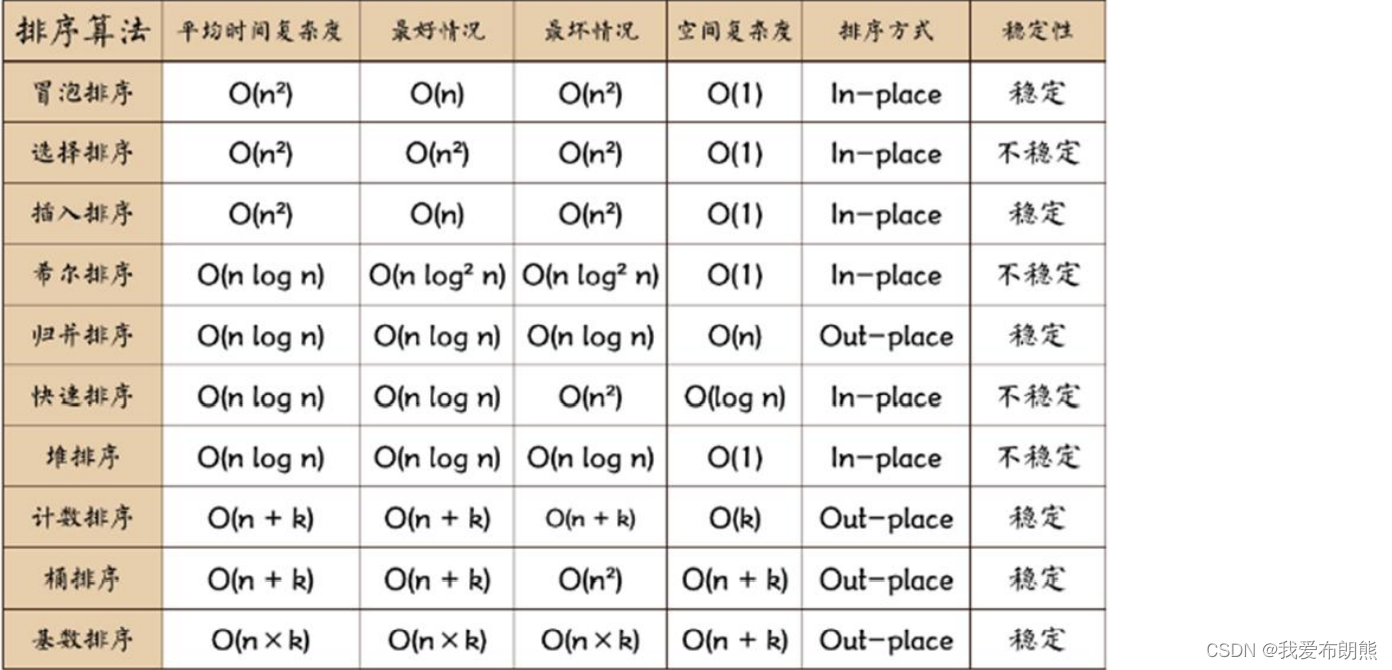
十一、常用排序算法总结