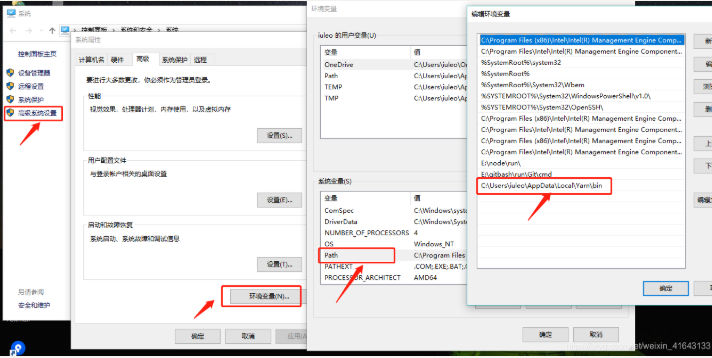
文章目录
- 前言
- 中文
- 数据爬取
- 爬取界面
- 爬取代码
- 数据清洗
- 数据分析
- 实验结果
- 英文
- 数据爬取
- 爬取界面
- 动态爬取
- 数据清洗
- 数据分析
- 实验结果
- 结论
前言
- 本文分别针对中文,英文语料进行爬虫,并在两种语言上计算其对应的熵,验证齐夫定律
github: ShiyuNee/python-spider (github.com)
中文
数据爬取
本实验对四大名著的内容进行爬取,并针对四大名著的内容展开中文文本分析,统计熵,验证齐夫定律
- 爬取网站: https://5000yan.com/
- 以水浒传的爬取为例展示爬取过程
爬取界面

-
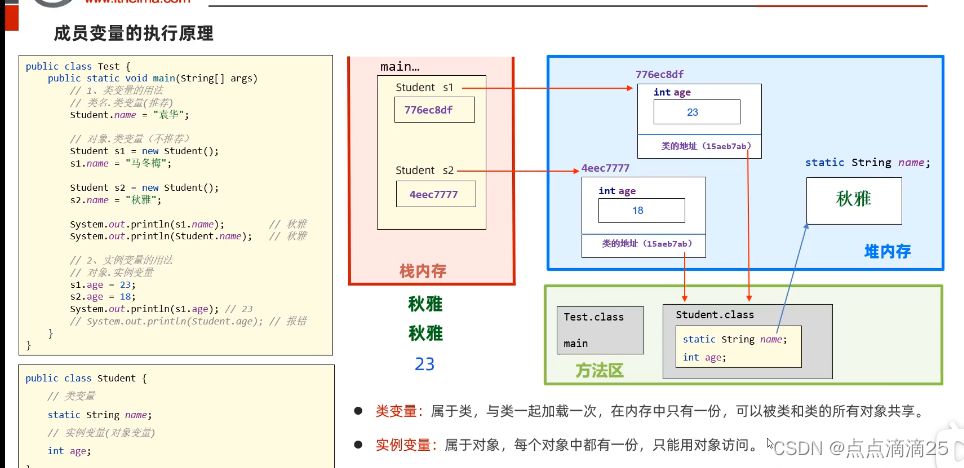
我们需要通过本页面,找到水浒传所有章节对应的
url,从而获取每一个章节的信息 -
可以注意到,这里每个章节都在
class=menu-item的li中,且这些项都包含在class=panbai的ul内,因此,我们对这些项进行提取,就能获得所有章节对应的url -
以第一章为例,页面为

- 可以看到,所有的正文部分都包含在
class=grap的div内,因此,我们只要提取其内部所有div中的文字,拼接在一起即可获得全部正文
- 可以看到,所有的正文部分都包含在
爬取代码
def get_book(url, out_path):
root_url = url
headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36'} # chrome浏览器
page_text=requests.get(root_url, headers=headers).content.decode()
soup1=BeautifulSoup(page_text, 'lxml')
res_list = []
# 获取所有章节的url
tag_list = soup1.find(class_='paiban').find_all(class_='menu-item')
url_list = [item.find('a')['href'] for item in tag_list]
for item in url_list: # 对每一章节的内容进行提取
chapter_page = requests.get(item, headers=headers).content.decode()
chapter_soup = BeautifulSoup(chapter_page, 'lxml')
res = ''
try:
chapter_content = chapter_soup.find(class_='grap')
except:
raise ValueError(f'no grap in the page {item}')
chapter_text = chapter_content.find_all('div')
print(chapter_text)
for div_item in chapter_text:
res += div_item.text.strip()
res_list.append({'text': res})
write_jsonl(res_list, out_path)
- 我们使用
beautifulsoup库,模拟Chrome浏览器的header,对每一本书的正文内容进行提取,并将结果保存到本地
数据清洗
-
因为文本中会有括号,其中的内容是对正文内容的拼音,以及解释。这些解释是不需要的,因此我们首先对去除括号中的内容。注意是中文的括号
def filter_cn(text): a = re.sub(u"\\(.*?)|\\{.*?}|\\[.*?]|\\【.*?】|\\(.*?\\)", "", text) return a -
使用结巴分词,对中文语句进行分词
def tokenize(text): return jieba.cut(text) -
删除分词后的标点符号项
def remove_punc(text): puncs = string.punctuation + "“”,。?、‘’:!;" new_text = ''.join([item for item in text if item not in puncs]) return new_text -
对中文中存在的乱码,以及数字进行去除
def get_cn_and_number(text): return re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039])","",text)
整体流程代码如下所示
def collect_data(data_list: list):
voc = defaultdict(int)
for data in data_list:
for idx in range(len(data)):
filtered_data = filter_cn(data[idx]['text'])
tokenized_data = tokenize(filtered_data)
for item in tokenized_data:
k = remove_punc(item)
k = get_cn_and_number(k)
if k != '':
voc[k] += 1
return voc
数据分析
针对收集好的字典类型数据(key为词,value为词出现的次数),统计中文的熵,并验证齐夫定律
-
熵的计算
def compute_entropy(data: dict): cnt = 0 total_num = sum(list(data.values())) print(total_num) for k, v in data.items(): p = v / total_num cnt += -p * math.log(p) print(cnt) -
齐夫定律验证(由于词项比较多,为了展示相对细节的齐夫定律图,我们仅绘制前200个词)
def zip_law(data: dict): cnt_list = data.values() sorted_cnt = sorted(enumerate(cnt_list), reverse=True, key=lambda x: x[1]) plot_y = [item[1] for item in sorted_cnt[:200]] print(plot_y) x = range(len(plot_y)) plot_x = [item + 1 for item in x] plt.plot(plot_x, plot_y) plt.show()
实验结果
-
西游记
- 熵:8.2221(共364221种token)

-
西游记+水浒传
-
熵:8.5814(共836392种token)

-
-
西游记+水浒传+三国演义
-
熵:8.8769(共1120315种token)

-
-
西游记+水浒传+三国演义+红楼梦
-
熵:8.7349(共1585796种token)

-
英文
数据爬取
本实验对英文读书网站上的图书进行爬取,并针对爬取内容进行统计,统计熵,验证齐夫定律
- 爬取网站: Bilingual Books in English | AnyLang
- 以The Little Prince为例介绍爬取过程
爬取界面

-
我们需要通过本页面,找到所有书对应的
url,然后获得每本书的内容 -
可以注意到,每本书的
url都在class=field-content的span中,且这些项都包含在class=ajax-link的a内,因此,我们对这些项进行提取,就能获得所有书对应的url -
以The Little Prince为例,页面为

- 可以看到,所有的正文部分都包含在
class=page n*的div内,因此,我们只要提取其内部所有div中的<p> </p>内的文字,拼接在一起即可获得全部正文
- 可以看到,所有的正文部分都包含在
动态爬取
需要注意的是,英文书的内容较少,因此我们需要爬取多本书。但此页面只有下拉后才会加载出新的书,因此我们需要进行动态爬取
-
使用
selenium加载Chrome浏览器,并模拟浏览器下滑操作,这里模拟5次def down_ope(url): driver = webdriver.Chrome() # 根据需要选择合适的浏览器驱动 driver.get(url) # 替换为你要爬取的网站URL for _ in range(5): driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(5) return driver -
将
driver中的内容传递给BeautifulSoupsoup1=BeautifulSoup(driver.page_source, 'lxml') books = soup1.find_all(class_ = 'field-content')
整体代码为
def get_en_book(url, out_dir):
root_url = url + '/en/books/en'
headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36'} # chrome浏览器
driver = down_ope(root_url)
soup1=BeautifulSoup(driver.page_source, 'lxml')
books = soup1.find_all(class_ = 'field-content')
book_url = [item.a['href'] for item in books]
for item in book_url:
if item[-4:] != 'read':
continue
out_path = out_dir + item.split('/')[-2] + '.jsonl'
time.sleep(2)
try:
book_text=requests.get(url + item, headers=headers).content.decode()
except:
continue
soup2=BeautifulSoup(book_text, 'lxml')
res_list = []
sec_list = soup2.find_all('div', class_=re.compile('page n.*'))
for sec in sec_list:
res = ""
sec_content = sec.find_all('p')
for p_content in sec_content:
text = p_content.text.strip()
if text != '':
res += text
print(res)
res_list.append({'text': res})
write_jsonl(res_list, out_path)
数据清洗
-
使用
nltk库进行分词def tokenize_en(text): sen_tok = nltk.sent_tokenize(text) word_tokens = [nltk.word_tokenize(item) for item in sen_tok] tokens = [] for temp_tokens in word_tokens: for tok in temp_tokens: tokens.append(tok.lower()) return tokens -
对分词后的token删除标点符号
def remove_punc(text): puncs = string.punctuation + "“”,。?、‘’:!;" new_text = ''.join([item for item in text if item not in puncs]) return new_text -
利用正则匹配只保留英文
def get_en(text): return re.sub(r"[^a-zA-Z ]+", '', text)
整体流程代码如下
def collect_data_en(data_list: list):
voc = defaultdict(int)
for data in data_list:
for idx in range(len(data)):
tokenized_data = tokenize_en(data[idx]['text'])
for item in tokenized_data:
k = remove_punc(item)
k = get_en(k)
if k != '':
voc[k] += 1
return voc
数据分析
数据分析部分与中文部分的分析代码相同,都是利用数据清洗后得到的词典进行熵的计算,并绘制图像验证齐夫定律
实验结果
-
10本书(1365212种token)
- 熵:6.8537

-
30本书(3076942种token)
-
熵:6.9168

-
-
60本书(4737396种token)
-
熵:6.9164

-
结论
从中文与英文的分析中不难看出,中文词的熵大于英文词的熵,且二者随语料库的增大都有逐渐增大的趋势。
- 熵的数值与
tokenizer,数据预处理方式有很大关系 - 不同结论可能源于不同的数据量,
tokenizer,数据处理方式
我们分别对中英文在三种不同数据量熵对齐夫定律进行验证
-
齐夫定律:一个词(字)在语料库中出现的频率,与其按照出现频率的排名成反比
-
若齐夫定律成立
- 若我们直接对排序(
Order)与出现频率(Count)进行绘制,则会得到一个反比例图像 - 若我们对排序的对数(
Log Order)与出现频率的对数(Log Count)进行绘制,则会得到一条直线 - 这里由于长尾分布,为了方便分析,只对出现次数最多的
top 1000个token进行绘制
- 若我们直接对排序(
-
从绘制图像中可以看出,齐夫定律显然成立