系统设计场景题—MySQL使用InnoDB,通过二级索引查第K大的数,时间复杂度是多少?
- 前言
- 明确场景
- 对齐表的结构
- 分析时间复杂度
- 执行一条 select 语句,期间发生了什么?
- 分析性能的瓶颈
- 如何做出优化
- 一、从业务上绕过
- 二、使用覆盖索引避开回表
- 三、预判边界值
- 什么是索引下推
- 灵魂拷问,offset为什么不下推?
- 总结
前言
这个问题是某大厂面试官提出的,比较考验面试者对MySQL理解程度。本文将此问题记录下来,尽量深入浅出的把所有细节讲清楚。
目标:
- 掌握InnoDB底层B+树
- 学习limit offset优化思路
- 优化掉回表,理解下推
明确场景
在MySQL中,使用的存储引擎是InnoDB,一张表有100万条数据。其中score代表各自的分数,在score上建立了二级索引,由大到小。问:查第K大的数,时间复杂度是多少?
要回答这种问题,一般有几个步骤
- 确定问题场景,对齐表的结构
- 解答原始问题,即时间复杂度
- 针对这个场景,分析性能瓶颈
- 针对这个瓶颈,如何做出优化
对齐表的结构
通常而言,面试官抛出一个问题,不见得就是一个非常完善、非常准确的描述,他其实是希望你能提出问题,通过沟通对齐,这也是工作中必备的能力。
首先问面试官,目前表的结构大概是怎样,索引的建设,又是怎样的,假设通过沟通,我们得到如下简化过的表stu_score:
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | bigint(20) unsigned | 主键id |
| name | varchar(128) | 姓名 |
| course | varchar(128) | 课程 |
| score | int(11) unsigned | 分数 |
题目在score字段上建了二级索引,大小是从小到大。这里要找第k个,其实就是偏移k-1:
select * from stu_score order by
score desc offset k - 1 limit 1
分析时间复杂度
这个问题的核心就是查找语句的时间复杂度是多少?
这道题实际是有一定引导性的,故意说索引,就是想让你往树分支上引,我们都知道,走索引,按数值本身查找一个数据,那二级索引的时间复杂度,肯定是O(logN)。
但这题不一样,是找第k个,比如第100个,我们其实是不知道树的分支结构具体是怎样的,因为不知道"第k大的数"的"数值"具体是多少,所以无法充分利用二级索引的优势进行查询。那么想要找出第k大的数,只能通过limit加offset的方式,通过B+Tree叶子节点的双向链表进行暴力查询,即遍历。

所以这里其实是考察B+树的理解,B+树除了分支,底层还有一个双链表,直接走双链表查询,反而是更快的了。
时间复杂是O(N),我们反过来想,其实这道题就是考你B+树数据结构,如果直接问你B+树结构,大多数有准备的面试者,都能回答清楚,但是通过一个实际问题来问你,只有真正理解其作用,才能快速答出。
这就完了吗?当然没有,下一步,面试官肯定会问你这个操作的性能如何,当然你也可以主动谈起。
执行一条 select 语句,期间发生了什么?
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;
将 select * 中的 * 符号扩展为表上的所有列。 - 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
注:上述为简单总结,此处重点讲解 执行器与存储引擎是如何交互的,更详细的内容可去小林coding查阅
现在我们的sql是这样的:
select * from stu_score order by
score desc offset k - 1 limit 1
先简单分析一下sql,order by score,走score二级索引,前面是查询 * ,所有会回表
执行器与存储引擎的执行流程是这样的:
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 B+Tree 的第一条叶子节点;
- 存储引擎根据二级索引的 B+ 树定位到这条记录后,获取主键值,然后进行回表操作,将完整的记录返回给 Server 层;
- Server 层在判断该记录的 偏移 是否等于 k,如果成立则将其发送给客户端;否则跳过该记录;
- 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
- 重复第二步,直到
offset k - 1 limit 1。
上面是针对这条sql来写的流程,看起来可能有点奇怪,下面是回表的通用流程:
- 存储引擎通过二级索引查找,获取主键值;
- 进行回表操作,将完整记录返回给上层;
- 上层判断是否需要该记录,需要则返回给客户端,不需要则跳过该记录;
- 存储引擎接着查找下一条;
- 重复第二步。
分析性能的瓶颈
如果offset大于10000,这个数据查询就会非常的慢。为什么会慢呢,一般都会答因为遍历,时间复杂度是O(N)。但实际如果你测试一下,你会发现这条语句会慢得离谱,这绝不是所谓遍历能导致的。
更深层次的原因在于,对于前10000 - 1个不需要的数据,MySQL每次也要回表去查找,这就导致了10000次随机IO,当然慢成狗。回表会怎么样呢?会操作大量随机IO,是性能的核心瓶颈。
如何做出优化
一、从业务上绕过
将limit、offset,改为next,也就是将第x页,改为下一页,这样就可以通过树分支查找。举个例子,今日头条,抖音,都是只分上一页下一页。
而现在移动互联网时代,用得更多的就是上一页、下一页这样的翻页逻辑,微博、抖音都是这样的逻辑。
--- 记录score为prev_score
select score from t_player order by
score desc limit 20
--- 记录score为prev_score
select score from t_player where
score < prev_score order by score
desc limit 20
使用这种模式,可以利用树索引直接找到目标,也绕过了无效回表问题(本质上,上次查询的时候其实回表过了),在Offset超过一万的情况下,性能通常都能提高两个量级以上。当然,*这种优化方案适合给分页
如果回到我们题目本身来说,那查找第k大的数,就需要循环“下一页”下去,本质上,并没有对回表做出优化,只是业务层的优化。
从两类sql上比较,其本质还是一样的,还是无效回表了k-1个记录,而分页的这种优化,从带宽上来看,反而损耗更大。
select * from stu_score order by
score desc offset k - 1 limit 1
--------------------------------------------
--- 记录score为prev_score
select score from t_player order by
score desc limit 20
--- 记录score为prev_score
select score from t_player where
score < prev_score order by score
desc limit 20
--- 省略
--- 省略
再次提醒:这里是业务层上的优化,没有解决回表的问题,不要搞错了
二、使用覆盖索引避开回表
上面分析了,对无用数据还回表查询,导致大量随机IO,是性能的核心瓶颈,那我们对症下药,能否不回表呢?当然可以,我们可以进行索引覆盖。
索引覆盖是说当二级索引查询的数据都在二级索引本身,比如索引Key或主键ID,那么就不必再去查聚簇索引。
那你可能会问,在我们的场景,还有其它需要查询的信息,比如名字,并不在二级索引上啊。
是的,但我们可以通过sql的拆分,来达到目的,思路如下:
select * from stu_score id in
(select id from stu_score order by
score offset 10000 limit 1)
------------------------------------------------
--- 下面sql是对上面sql的简单理解版本
--- 记录id为 ans_id
select id from stu_score order by
score offset 10000 limit 1
--- 通过聚簇索引去查
select * from stu_score id = ans_id
这句话是说,先从条件查询中,查找数据对应的数据库唯一id值,因为主键在二级索引上就有,所以不用回表到聚簇索引的磁盘上拉取。
如此一来,offset部分均不需要去回表,只有limit出来的x个主键id会去查询聚簇索引,这样只会x次IO。
在业务确实需要用跳转的分页情况下(比方说直接跳转到5000页),使用该方案可以大幅度提高性能,通常能满足性能要求。
好,这里解决了无用的回表,可能还会有人去想,其实现是 while (N--) 循环了N次,这里走B+树的双指针也可能会是瓶颈。
其实这种考虑大可不必,下面是测试总结:
一张500w的表,offset 10000,要是没索引覆盖,处理时间甚至可以达到十秒级,有了的话,能降低到十毫秒级,有质的飞跃。所以性能瓶颈并不在循环这里。
三、预判边界值
这其实也是根据业务场景的做法,能通过业务预判边界,这种方式并不是通用解决方案,但因为《高性能MySQL》中提到了,也一并列出来。
什么是索引下推
索引下推是MySQL 5.6 推出的查询优化策略,索引下推能够减少二级索引在查询时的回表操作,提高查询的效率,因为它将 Server 层部分负责的事情,交给存储引擎层去处理了。
举一个具体的例子,方便大家理解,这里一张用户表如下,我对 age 和 reward 字段建立了联合索引(age,reward):
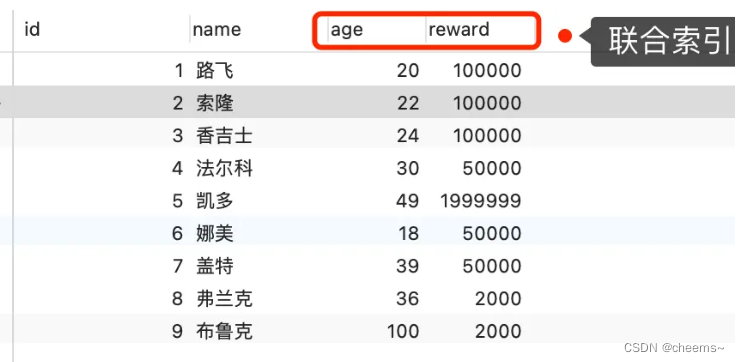
现在有下面这条查询语句:
select * from t_user where age > 20 and reward = 100000;
联合索引当遇到范围查询 (>、<) 就会停止匹配,也就是 age 字段能用到联合索引,但是 reward 字段则无法利用到索引。
那么,不使用索引下推(MySQL 5.6 之前的版本)时,执行器与存储引擎的执行流程是这样的:
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎根据二级索引的 B+ 树快速定位到这条记录后,获取主键值,然后进行回表操作,将完整的记录返回给 Server 层;
- Server 层在判断该记录的 reward 是否等于 100000,如果成立则将其发送给客户端;否则跳过该记录;
- 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,没有索引下推的时候,每查询到一条二级索引记录,都要进行回表操作,然后将记录返回给 Server,接着 Server 再判断该记录的 reward 是否等于 100000。
而使用索引下推后,判断记录的 reward 是否等于 100000 的工作交给了存储引擎层,过程如下 :
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎定位到二级索引后,先不执行回表操作,而是先判断一下该索引中包含的列(reward列)的条件(reward 是否等于 100000)是否成立。如果条件不成立,则直接跳过该二级索引。如果成立,则执行回表操作,将完成记录返回给 Server 层。
- Server 层在判断其他的查询条件(本次查询没有其他条件)是否成立,如果成立则将其发送给客户端;否则跳过该记录,然后向存储引擎索要下一条记录。
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,使用了索引下推后,虽然 reward 列无法使用到联合索引,但是因为它包含在联合索引(age,reward)里,所以直接在存储引擎过滤出满足 reward = 100000 的记录后,才去执行回表操作获取整个记录。相比于没有使用索引下推,节省了很多回表操作。
当你发现执行计划里的 Extr 部分显示了 “Using index condition”,说明使用了索引下推。

灵魂拷问,offset为什么不下推?
上面已经知道了下推是含义:将 Server 层部分负责的事情,交给存储引擎层去处理了,减少回表。
再来看看offset的执行流程:
1.存储引擎通过二级索引查找,获取主键值;
2.进行回表操作,将完整记录返回给上层;
3.上层判断是否需要该记录,需要则返回给客户端,不需要则跳过该记录;
4.存储引擎接着查找下一条;
5.重复第二步。
从流程其实我们能看出,存储引擎层是没有Offset信息的。Offset未曾下推!
为什么MySQL官方不做offset的下推呢?
- 限制场景太多,比如group by,having这种推了也没用的,给多个引擎做有点得不偿失
- 更核心的,分层设计理念,这件事本身是 Server 层的,本就不该存储引擎做。
MySQL官方不做,但是云厂商可以自己做offset下推:
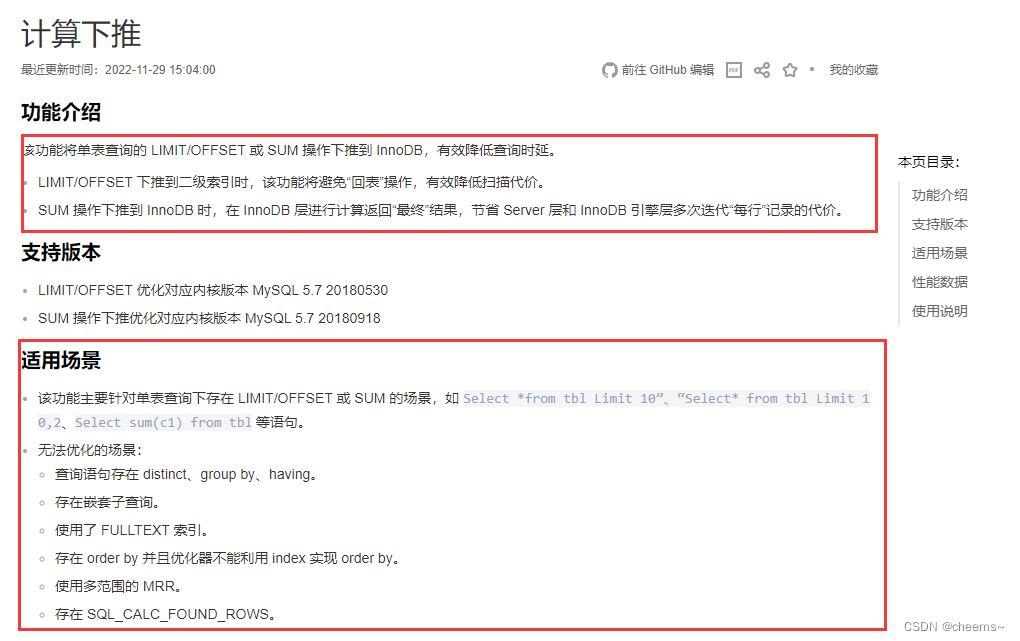
腾讯云 Limit Offset下推
阿里云 Limit Offset下推
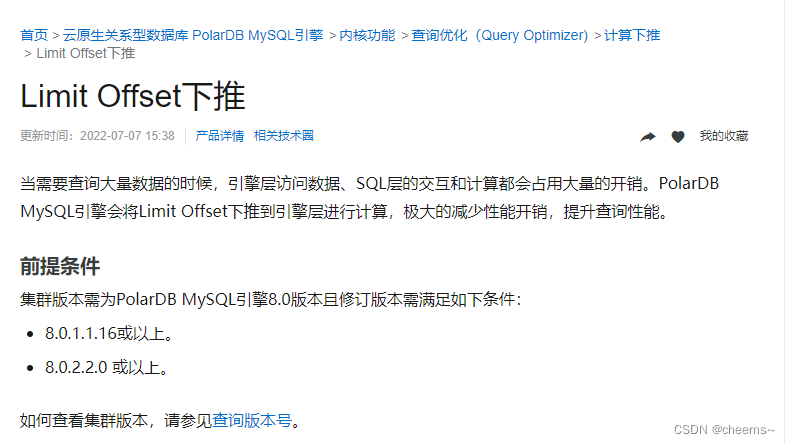
可以发现阿里腾讯两大云厂商MySQL自研版本都做了下推,那MySQL从技术上自然也能。
有大佬针对这个问题还给MySQL提了bug:https://bugs.mysql.com/bug.php?id=109173
还带了修复方案:https://bugs.mysql.com/file.php?id=31884&bug_id=109173
总结
一个看起来很简单的一个问题,其实牵涉到的知识很广。
-
首先时间复杂度是多少:考察B+树结构,到底是O(n)还是O(logN),真的理解吗?
-
Offset为什么慢:考察对底层行为一定程度的掌握,能想到回表与执行流程吗?
-
几种解决方案:考察技术视野和解决问题的能力,针对不同的场景给出不同的解决方案。
-
深层次行为原因:考察MySQL分层架构,及对开源社区的关注。