Hadoop综合项目——二手房统计分析(Hive篇)
文章目录
- Hadoop综合项目——二手房统计分析(Hive篇)
- 0、 写在前面
- 1、Hive统计分析
- 1.1 本地数据/HDFS数据导入到Hive
- 1.2 楼龄超过20年的二手房比例
- 1.3 四大一线城市各楼层地段的平均价格
- 1.4 采光较好的二手房比例
- 1.5 二手房面积大小各个区间的比例
- 1.6 各大宣传标签的二手房占比
- 1.7 统计四大一线城市二手房关注人数
- 1.8 四大一线城市二手房规格比例
- 2、数据及源代码
- 3、总结

0、 写在前面
- Windows版本:
Windows10 - Linux版本:
Ubuntu Kylin 16.04 - JDK版本:
Java8 - Hadoop版本:
Hadoop-2.7.1 - Hive版本:
Hive1.2.2 - IDE:
IDEA 2020.2.3 - IDE:
Pycharm 2021.1.3 - IDE:
Eclipse3.8
1、Hive统计分析
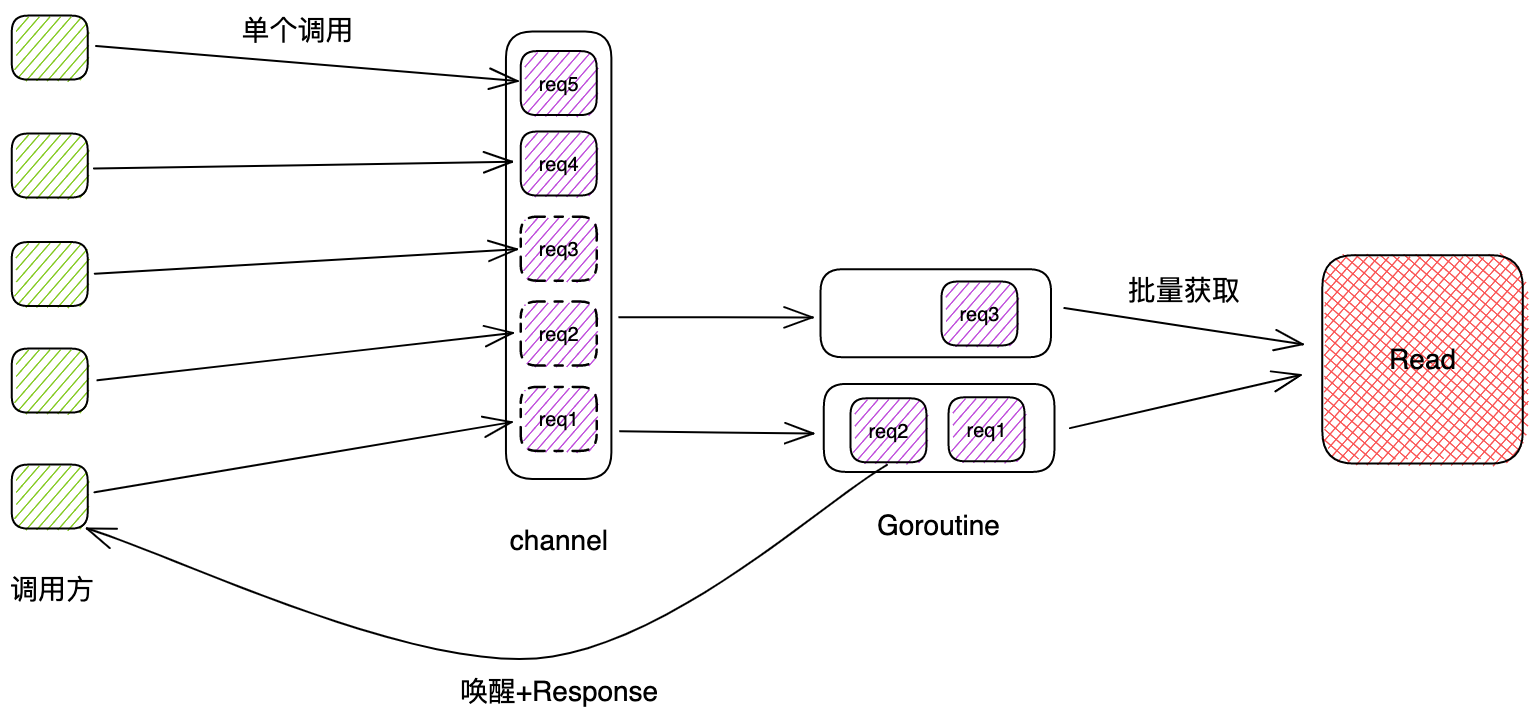
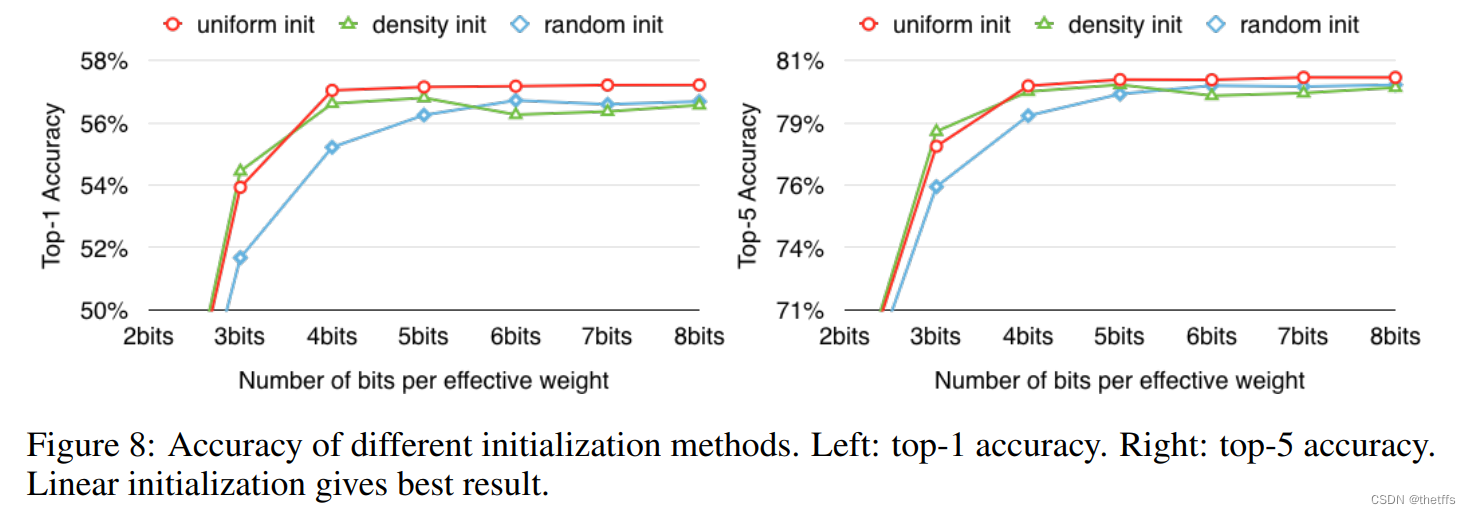
使用Hive做了7个不同的统计分析,更好地展示二手房的情况
1.1 本地数据/HDFS数据导入到Hive
先创建数据库db_ke_house以及表tb_ke_house,再从HDFS导入数据
hive> create database if not exists db_ke_house;
OK
Time taken: 0.163 seconds
hive> use db_ke_house;
OK
hive> create table if not exists tb_ke_house (
> id int,
> city string,
> title string,
> houseInfo array<string>,
> followInfo array<string>,
> positionInfo string,
> total int,
> unitPrice double,
> tag string,
> crawler_time timestamp
> )
> row format delimited fields terminated by '\t'
> collection items terminated by '|';
OK
Time taken: 0.061 seconds
hive> load data inpath '/Ke_House/tb_house.txt' into table tb_ke_house;
Loading data to table db_ke_house.tb_ke_house
Table db_ke_house.tb_ke_house stats: [numFiles=1, totalSize=3385429]
OK
Time taken: 0.223 seconds
查看表数据
hive> select * from tb_ke_house limit 5;

1.2 楼龄超过20年的二手房比例
- 分析目的:
楼龄的长短是顾客是否购买房子的决定因素之一,楼龄越短,房子越新,顾客购买的欲望也越大。
- 代码:
with t1 as (
select city, count(city) totalcnt from tb_ke_house where array_contains(houseinfo, "未透露年份建") = false group by city
), t2 as (
select city, 2022 - cast(substring(houseinfo[2],0,length(houseinfo[2])-2) as int) as ycnt
from tb_ke_house where houseinfo[2] != "未透露年份建"
), t3 as (
select city, count(ycnt) as cnt from t2 where ycnt >= 20 group by city
)
select t1.city, cnt / totalcnt rate from t1 join t3 on t1.city = t3.city group by t1.city, cnt, totalcnt;
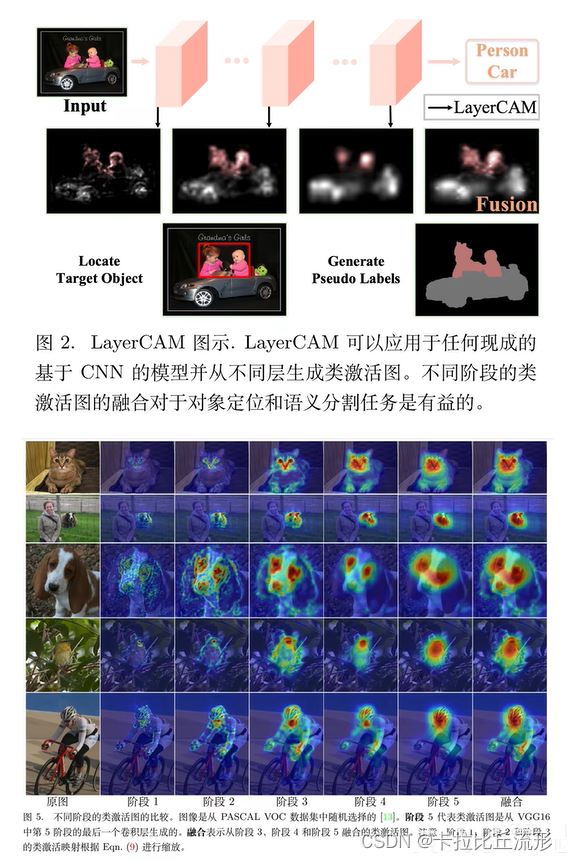
- 运行情况:

- 结果:

1.3 四大一线城市各楼层地段的平均价格
- 分析目的:
价格是顾客心中最重要的一个因素,也是顾客是否购买房子的决定因素之一,性价比好的房子,顾客购买欲望可能更大。
- 代码:
select city,layer, avg(total/size) from (
select city,houseinfo[0] layer,cast(substring(houseinfo[4],0,length(houseinfo[4])-2) as int) as size, total from tb_ke_house
) t
group by city,layer;
-
运行情况:

-
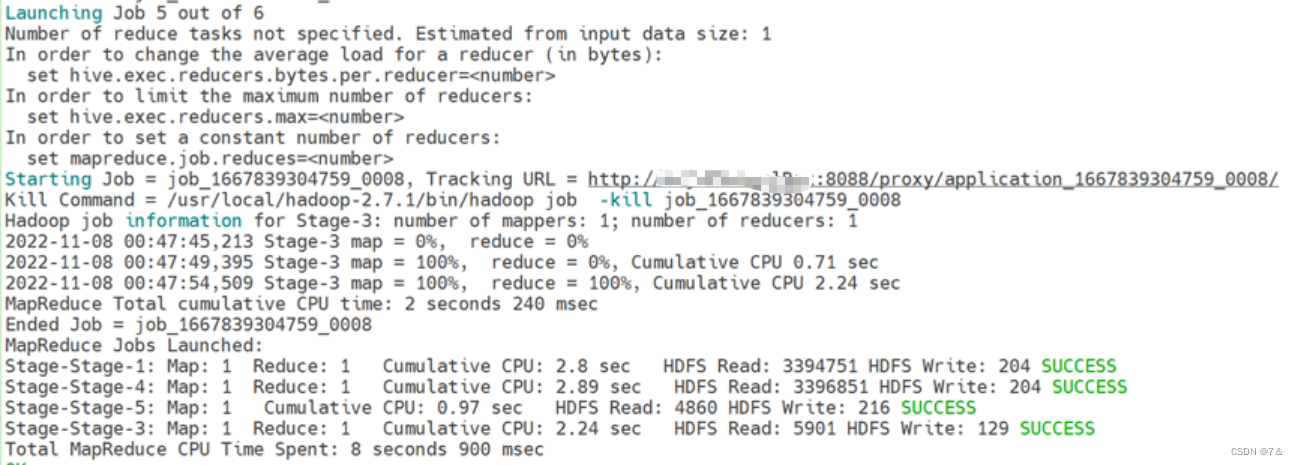
结果:
1.4 采光较好的二手房比例
- 分析目的:
阳光是否充同样是顾客心中最重要的一个因素,采光好的房源,顾客更倾向于购买。
- 代码:
with t1 as
select city, sum(if (title regexp('.*采光.*') = true, 1, 0)) cnt1 from tb_ke_house group by city
), t2 as (
select city, count(city) totalcnt from tb_ke_house group by city
)
select t1.city, cnt1/totalcnt rate1 from t1 join t2 on t1.city = t2.city roup by t1.city, cnt1, totalcnt;
- 运行情况:


- 结果:

1.5 二手房面积大小各个区间的比例
- 分析目的:
顾客对于房子的大小各有不同,为了更好满足顾客要求,面积大小的统计展示是必不可少的。
- 代码:
with t2 as (
select city, size,
case when size < 100 then '<100'
when size < 200 then '100~200'
when size < 300 then '200~300'
when size < 500 then '300~500'
else 'other'
end sizerange
from (
select id, city, substring(houseInfo[4], 0, length(houseinfo[4]) - 2) as size from tb_ke_house
) t1
), t3 as (
select city, count(city) totalcnt from tb_ke_house group by city
)
select t2.city, sizerange, count(sizerange)/totalcnt as rate from t2 join t3 on t2.city = t3.city
group by t2.city, sizerange,totalcnt
-
运行情况:


-
结果:

1.6 各大宣传标签的二手房占比
- 分析目的:
吸引顾客购买的一大来源便是房子的优势,好的宣传标签可以促进房子的销量。
- 代码:
with t1 as (
select city, count(city) totalcnt from tb_ke_house group by city
), t2 as (
select city, count(tag) cnt, if(tag != '', tag, "未知标签") as newTag
from tb_ke_house group by city, tag
)
select t2.city, newTag, cnt / totalcnt as rate from t2 join t1 on t2.city = t1.city
group by t2.city, newTag,cnt, totalcnt
- 运行情况:


- 结果:

1.7 统计四大一线城市二手房关注人数
- 分析目的:
房子的关注数可以体现出顾客此段房源的热爱程度,有利于开发商合理规划房源。
- 代码:
select city, sum(size) from (
select city, cast(substring(followinfo[0], 0, length(followinfo[0]) - 3) as int) as size
from tb_ke_house
)t
group by city
- 运行情况:

- 结果:
tp
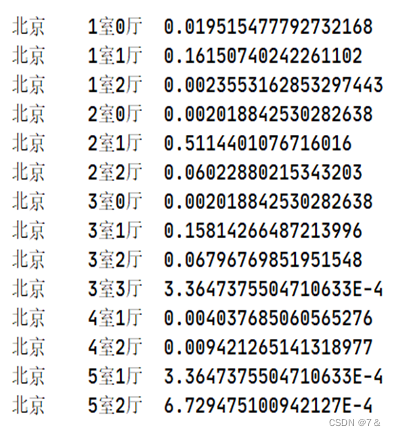
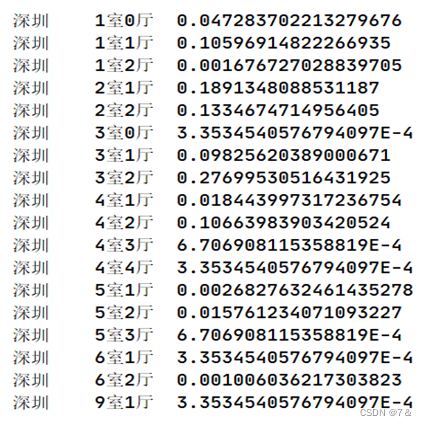
1.8 四大一线城市二手房规格比例
- 分析目的:
房子规格大小直接影响到顾客对于房源的好感度,合理的规格可以促进顾客的购买欲望。
- 代码:
with t1 as (
select city, count(city) totalcnt from tb_ke_house group by city
), t2 as (
select city, houseinfo[3] as scale, count(houseinfo[3]) as size
from tb_ke_house group by city, houseinfo[3]
)
select t2.city, scale, size / totalcnt as rate from t1 join t2 on t1.city = t2.city
group by t2.city, scale, size, totalcnt
-
运行情况:

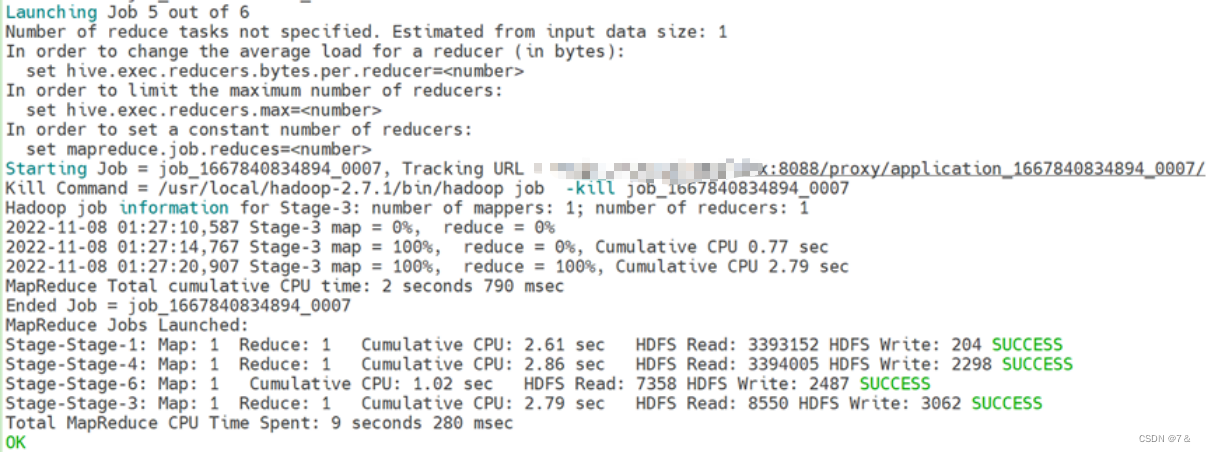
-
结果:


2、数据及源代码
-
Github
-
Gitee
3、总结
Hive统计分析过程最主要是HQL语句的正确编写,HQL语法和SQL语法不太一样,需要注意两者之间的差别,总体来说,难度并不高,一步一步来是可以顺利实现的。
结束!