一、介绍
正如您从标题中看到的,这是一个演示项目,显示了一个非常基本的语音助手脚本,可以根据 Google 搜索结果在终端中回答您的问题。
您可以在 GitHub 存储库中找到完整代码:dimitryzub/serpapi-demo-projects/speech-recognition/cli-based/
后续博客文章将涉及:
- 使用Flask、一些 HTML、CSS 和 Javascript 的基于 Web 的解决方案。
- 使用Flutter和Dart的基于 Android 和 Windows 的解决方案。
二、我们将在这篇博文中构建什么
2.1 环境准备
首先,让我们确保我们处于不同的环境中,并正确安装项目所需的库。最难(可能)是 安装 .pyaudio,关于此种困难可以参看下文克服:
[解决]修复 win 32/64 位操作系统上的 PyAudio pip 安装错误
2.2 虚拟环境和库安装
在开始安装库之前,我们需要为此项目创建并激活一个新环境:
# if you're on Linux based systems
$ python -m venv env && source env/bin/activate
$ (env) <path>
# if you're on Windows and using Bash terminal
$ python -m venv env && source env/Scripts/activate
$ (env) <path>
# if you're on Windows and using CMD
python -m venv env && .\env\Scripts\activate
$ (env) <path> 解释python -m venv env告诉 Python 运行 module( -m)venv并创建一个名为 的文件夹env。&&代表“与”。source <venv_name>/bin/activate将激活您的环境,并且您将只能在该环境中安装库。
现在安装所有需要的库:
pip install rich pyttsx3 SpeechRecognition google-search-results 现在到pyaudio. 请记住,pyaudio安装时可能会引发错误。您可能需要进行额外的研究。
如果您使用的是 Linux,我们需要安装一些开发依赖项才能使用pyaudio:
$ sudo apt-get install -y libasound-dev portaudio19-dev
$ pip install pyaudio如果您使用的是 Windows,则更简单(使用 CMD 和 Git Bash 进行测试):
pip install pyaudio三、完整代码
import os
import speech_recognition
import pyttsx3
from serpapi import GoogleSearch
from rich.console import Console
from dotenv import load_dotenv
load_dotenv('.env')
console = Console()
def main():
console.rule('[bold yellow]SerpApi Voice Assistant Demo Project')
recognizer = speech_recognition.Recognizer()
while True:
with console.status(status='Listening you...', spinner='point') as progress_bar:
try:
with speech_recognition.Microphone() as mic:
recognizer.adjust_for_ambient_noise(mic, duration=0.1)
audio = recognizer.listen(mic)
text = recognizer.recognize_google(audio_data=audio).lower()
console.print(f'[bold]Recognized text[/bold]: {text}')
progress_bar.update(status='Looking for answers...', spinner='line')
params = {
'api_key': os.getenv('API_KEY'),
'device': 'desktop',
'engine': 'google',
'q': text,
'google_domain': 'google.com',
'gl': 'us',
'hl': 'en'
}
search = GoogleSearch(params)
results = search.get_dict()
try:
if 'answer_box' in results:
try:
primary_answer = results['answer_box']['answer']
except:
primary_answer = results['answer_box']['result']
console.print(f'[bold]The answer is[/bold]: {primary_answer}')
elif 'knowledge_graph' in results:
secondary_answer = results['knowledge_graph']['description']
console.print(f'[bold]The answer is[/bold]: {secondary_answer}')
else:
tertiary_answer = results['answer_box']['list']
console.print(f'[bold]The answer is[/bold]: {tertiary_answer}')
progress_bar.stop() # if answered is success -> stop progress bar.
user_promnt_to_contiune_if_answer_is_success = input('Would you like to to search for something again? (y/n) ')
if user_promnt_to_contiune_if_answer_is_success == 'y':
recognizer = speech_recognition.Recognizer()
continue # run speech recognizion again until `user_promt` == 'n'
else:
console.rule('[bold yellow]Thank you for cheking SerpApi Voice Assistant Demo Project')
break
except KeyError:
progress_bar.stop()
error_user_promt = input("Sorry, didn't found the answer. Would you like to rephrase it? (y/n) ")
if error_user_promt == 'y':
recognizer = speech_recognition.Recognizer()
continue # run speech recognizion again until `user_promt` == 'n'
else:
console.rule('[bold yellow]Thank you for cheking SerpApi Voice Assistant Demo Project')
break
except speech_recognition.UnknownValueError:
progress_bar.stop()
user_promt_to_continue = input('Sorry, not quite understood you. Could say it again? (y/n) ')
if user_promt_to_continue == 'y':
recognizer = speech_recognition.Recognizer()
continue # run speech recognizion again until `user_promt` == 'n'
else:
progress_bar.stop()
console.rule('[bold yellow]Thank you for cheking SerpApi Voice Assistant Demo Project')
break
if __name__ == '__main__':
main()四、代码说明
导入库:
import os
import speech_recognition
import pyttsx3
from serpapi import GoogleSearch
from rich.console import Console
from dotenv import load_dotenvrich用于在终端中进行漂亮格式化的 Python 库。pyttsx3Python 的文本到语音转换器可离线工作。SpeechRecognition用于将语音转换为文本的 Python 库。google-search-resultsSerpApi 的 Python API 包装器,可解析来自 15 个以上搜索引擎的数据。os读取秘密环境变量。在本例中,它是 SerpApi API 密钥。dotenv从文件加载环境变量(SerpApi API 密钥).env。.env文件可以重命名为任何文件:(.napoleon.点)代表环境变量文件。
定义rich Console(). 它将用于美化终端输出(动画等):
console = Console()定义main所有发生的函数:
def main():
console.rule('[bold yellow]SerpApi Voice Assistant Demo Project')
recognizer = speech_recognition.Recognizer()在函数的开头,我们定义speech_recognition.Recognizer()并将console.rule创建以下输出:
───────────────────────────────────── SerpApi Voice Assistant Demo Project ─────────────────────────────────────下一步是创建一个 while 循环,该循环将不断监听麦克风输入以识别语音:
while True:
with console.status(status='Listening you...', spinner='point') as progress_bar:
try:
with speech_recognition.Microphone() as mic:
recognizer.adjust_for_ambient_noise(mic, duration=0.1)
audio = recognizer.listen(mic)
text = recognizer.recognize_google(audio_data=audio).lower()
console.print(f'[bold]Recognized text[/bold]: {text}')console.status-rich进度条,仅用于装饰目的。speech_recognition.Microphone()开始从麦克风拾取输入。recognizer.adjust_for_ambient_noise旨在根据环境能量水平校准能量阈值。recognizer.listen监听实际的用户文本。recognizer.recognize_google使用 Google Speech Recongition API 执行语音识别。lower()是降低识别文本。console.print允许使用文本修改的语句richprint,例如添加粗体、斜体等。
spinner='point'将产生以下输出(使用python -m rich.spinner查看列表spinners):
![]()
之后,我们需要初始化 SerpApi 搜索参数以进行搜索:
progress_bar.update(status='Looking for answers...', spinner='line')
params = {
'api_key': os.getenv('API_KEY'), # serpapi api key
'device': 'desktop', # device used for
'engine': 'google', # serpapi parsing engine: https://serpapi.com/status
'q': text, # search query
'google_domain': 'google.com', # google domain: https://serpapi.com/google-domains
'gl': 'us', # country of the search: https://serpapi.com/google-countries
'hl': 'en' # language of the search: https://serpapi.com/google-languages
# other parameters such as locations: https://serpapi.com/locations-api
}
search = GoogleSearch(params) # where data extraction happens on the SerpApi backend
results = search.get_dict() # JSON -> Python dictprogress_bar.update将会progress_bar用新的status(控制台中打印的文本)进行更新,spinner='line'并将产生以下动画:
![]()
之后,使用 SerpApi 的Google 搜索引擎 API从 Google 搜索中提取数据。
代码的以下部分将执行以下操作:
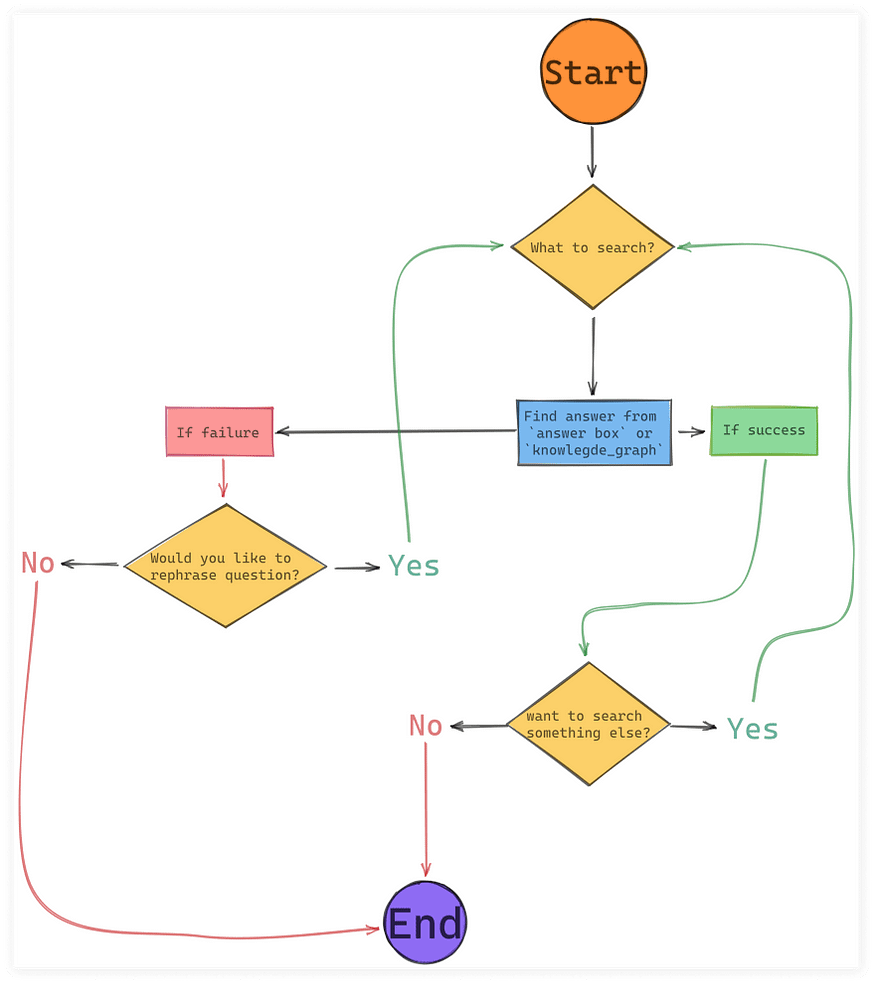
try:
if 'answer_box' in results:
try:
primary_answer = results['answer_box']['answer']
except:
primary_answer = results['answer_box']['result']
console.print(f'[bold]The answer is[/bold]: {primary_answer}')
elif 'knowledge_graph' in results:
secondary_answer = results['knowledge_graph']['description']
console.print(f'[bold]The answer is[/bold]: {secondary_answer}')
else:
tertiary_answer = results['answer_box']['list']
console.print(f'[bold]The answer is[/bold]: {tertiary_answer}')
progress_bar.stop() # if answered is success -> stop progress bar
user_promnt_to_contiune_if_answer_is_success = input('Would you like to to search for something again? (y/n) ')
if user_promnt_to_contiune_if_answer_is_success == 'y':
recognizer = speech_recognition.Recognizer()
continue # run speech recognizion again until `user_promt` == 'n'
else:
console.rule('[bold yellow]Thank you for cheking SerpApi Voice Assistant Demo Project')
break
except KeyError:
progress_bar.stop() # if didn't found the answer -> stop progress bar
error_user_promt = input("Sorry, didn't found the answer. Would you like to rephrase it? (y/n) ")
if error_user_promt == 'y':
recognizer = speech_recognition.Recognizer()
continue # run speech recognizion again until `user_promt` == 'n'
else:
console.rule('[bold yellow]Thank you for cheking SerpApi Voice Assistant Demo Project')
break最后一步是处理麦克风没有拾取声音时的错误:
# while True:
# with console.status(status='Listening you...', spinner='point') as progress_bar:
# try:
# speech recognition code
# data extraction code
except speech_recognition.UnknownValueError:
progress_bar.stop() # if didn't heard the speech -> stop progress bar
user_promt_to_continue = input('Sorry, not quite understood you. Could say it again? (y/n) ')
if user_promt_to_continue == 'y':
recognizer = speech_recognition.Recognizer()
continue # run speech recognizion again until `user_promt` == 'n'
else:
progress_bar.stop() # if want to quit -> stop progress bar
console.rule('[bold yellow]Thank you for cheking SerpApi Voice Assistant Demo Project')
breakconsole.rule()将提供以下输出:
───────────────────── Thank you for cheking SerpApi Voice Assistant Demo Project ──────────────────────添加if __name__ == '__main__'惯用语,以防止用户在无意时意外调用某些脚本,并调用main将运行整个脚本的函数:
if __name__ == '__main__':
main()五、链接
richpyttsx3SpeechRecognitiongoogle-search-resultsosdotenv