数据仓库基本概念
数据仓库,简称数仓,用于存储、分析、报告的数据系统。数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持。
- 数据仓库本身并不生产任何数据,其数据来源于不同的外部系统
- 同时数据仓库自身也不需要“消费” 任何数据,其结果开放给各个外部应用使用
- 这也是为什么交“仓库”,不叫工厂的原因
数据仓库为何而来?解决什么问题?
为了分析数据而来,分析结果给企业决策提供支撑
在哪里进行数据分析?
在数据库进行数据分析?可以,但是没有必要。
首先数据库要保证我们正常的业务,数据分析也是读数据,会让数据库压力变大。
而且不同系统不同表之间的字段存在差异,可能格式不同,编码不同,单位不同。字段类型属性不统一
包括历史数据不完善等
为了分析所涉及数据,规模较小的时候,在业务低峰期可以在数据库上直接开展分析。
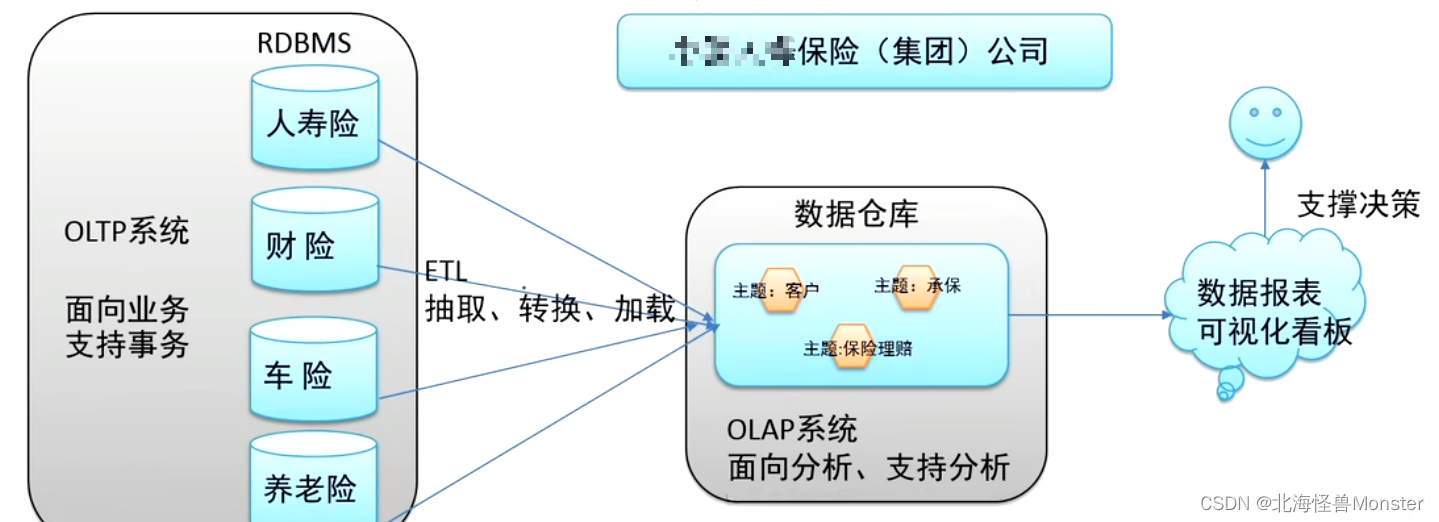
但为了更好的进行各种规模的数据分析,同时也不影响正常系统的运行,此时需要构建一个集成统一的数据分析平台。该平台目的很简单:面向分析,支持分析,并且和正常业务系统解耦合,基于这种需求,数据仓库的雏形开始在企业中出现了。
最终结论:企业中数据仓库为什么而来? 为了更好的分析数据而来。
数据仓库主要特征
1、面向主题
- 主题是一个抽象的概念,是较高层次上数据综合、归类并进行分析利用的抽象。在逻辑意义上,它是对应企业中,某一宏观分析领域所涉及的分析对象。
2、集成性
- 主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。需要集成到数仓主题下。
因此在数据进入数据仓库之气那,必须要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库建设中最关键、最复杂的一步。
3、非易失性
- 也叫非易变性。数据仓库是分析数据的平台,而不是创造数据的平台。我们通过数仓去分析数据中的规律,而不是去创造修改其中的规律,因此数据进行数据仓库后,它便稳定且不会改变。
4、时变性
- 数据仓库的数据需要随着时间更新,以适应决策的需要
数据仓库包含各种粒度的历史数据,数据可能与某个特定日期、星期、月份、季度或者年份有关。当业务变化后会失去时效性,因此数据仓库的数据需要随着时间更新,以适应决策的需要。(这里指的数据更新是指,我这个月分析上个月的数据,我把数据读入数仓,这些数据我是不会去改变的,但是我下个月再分析数据,那么肯定就不能用的还是上个月的数据,用的应该是这个月产生的数据)
从这个角度讲,数据仓库建设是一个项目,更是一个过程。
数据仓库主流开发语言—SQL
在数据分析领域,SQL是分析领域主流开发语言。
很多数仓软件都会去支持SQL语法。
Apache Hive入门
Apache Hive 是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中结构化,半结构化数据文件映射为一张数据表,基于表提供了一种类似SQL的查询模型,成为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群执行
Hive由Facebook实现并开源
为什么使用Hive
使用Hadoop MapReduce直接处理数据所面临的问题:
人员学习成本太高,需要掌握java语言
MapReduce实现复杂查询逻辑开发难度太大
使用Hive处理数据好处
操作接口采用类似SQL语法,提供快速开发的能力,简单容易上手。
避免直接写MapReduce,减少开发人员学习成本。
支持自定义函数,功能扩展很方便
背靠Hadoop,擅长存储分析海量数据集
Hive和Hadoop关系
- 从功能上来说,数据仓库软件,至少需要具备一下两种能力:存储数据能力,分析数据能力
- Apache Hive 作为一款大数据时代的数据仓库软件,当然具备上述两种能力,只不过Hive并不是自己实现了上述两种能力,而是借助了Hadoop
Hive利用HDFS存储数据,利用MapReduce查询分析数据 - 这样突然发现Hive没啥用,不过是套壳Hadoop,其实不然,Hive最大魅力在于,用户可以专注于编写HQL,Hive帮你转换成为MapReduce程序完成对数据的分析
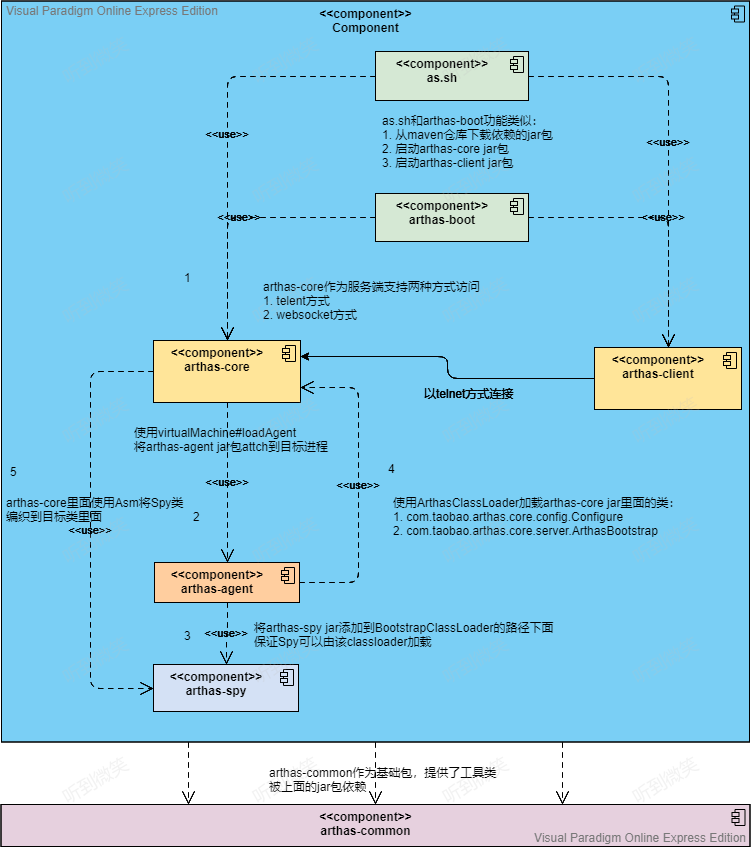
Hive架构图
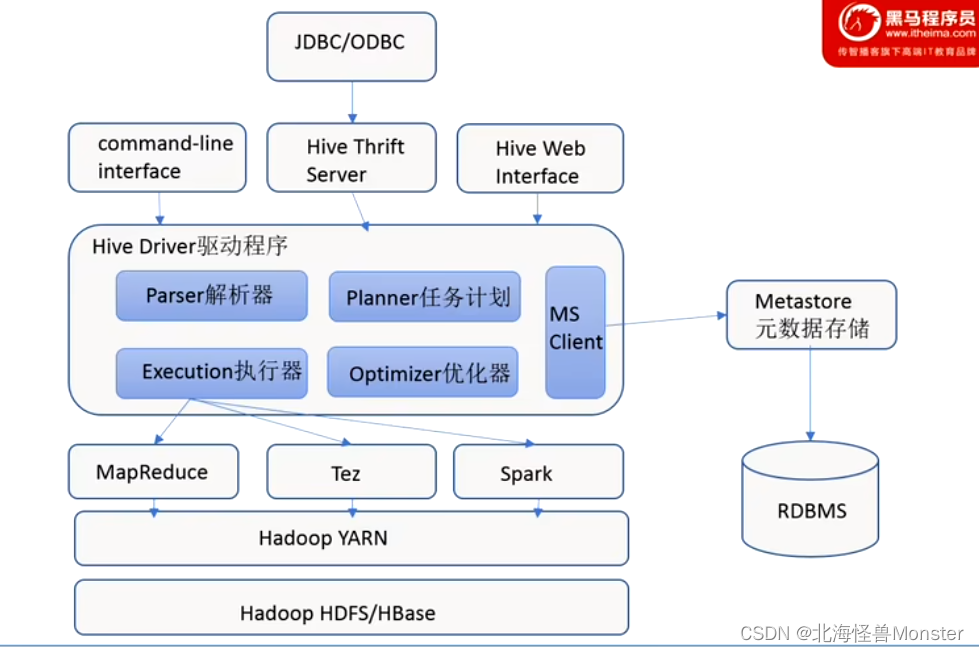
用户接口:
包括CLI、JDBC/ODBC、WebGUI。其中CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议;WebGUI是通过浏览器访问Hive。
元数据存储:
通常是存储在关系数据库中,如mysql / derby(内置数据库)等,Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性是(是否为外部表等),表的数据所在目录等。就是表和文件之间的映射关系。
Hive Driver 驱动程序
包括语法解析器,计划编译器,优化器,执行器。完成HQL查询语句从语法分析、语法解析,编译,优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有执行引擎调用执行。
执行引擎:
Hive本身并不直接处理数据文件,而是通过执行引擎处理,当下Hive支持MapReduce,Tez,Spark 3种执行引擎。
Apache Hive 安装部署
首先我们需要解决元数据存储问题,元数据存储在关系型数据库种,Hive内置了Derby数据库,或者使用第三方数据库,如MySQL
元数据服务,metastore,作用就是管理元数据。因为元数据很重要,所以Hive对其专门开发了一个组件对其管理。
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要指导 数据库 的用户米给和密码,只需要连接metastore服务即可,某种程度上也保证了hive元数据的安全。
metastore服务配置有3种:内嵌模式,本地模式,远程模式
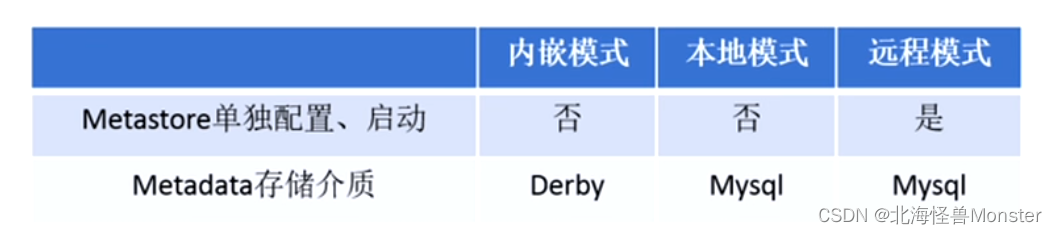
远程模式安装
在搭建Hive之前一定保证Hadoop集群健康可用
启动Hive之前必须先启动Hadoop集群,特别要注意:需等待HDFS安全模式关闭之后再启动运行Hive。
Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
服务器基础环境,集群时间同步,防火墙关闭,主机Host映射,免密登录,JDK安装
只要你安装了Hadoop就没问题。
Hadoop与Hive整合:
因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据;
因此需要在Hadoop种添加相关配置属性,以满足Hive在Hadoop上运行
修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件,重启生效
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
先安装MySql
Mysql安装
-
卸载Centos7自带的mariadb
[root@node3 ~]# rpm -qa|grep mariadb mariadb-libs-5.5.64-1.el7.x86_64 [root@node3 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps [root@node3 ~]# rpm -qa|grep mariadb -
安装mysql
mkdir /export/software/mysql #上传mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar 到上述文件夹下 解压 tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar #执行安装 yum -y install libaio [root@node3 mysql]# rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm warning: mysql-community-common-5.7.29-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-common-5.7.29-1.e################################# [ 25%] 2:mysql-community-libs-5.7.29-1.el7################################# [ 50%] 3:mysql-community-client-5.7.29-1.e################################# [ 75%] 4:mysql-community-server-5.7.29-1.e################ ( 49%) -
mysql初始化设置
#初始化 mysqld --initialize #更改所属组 chown mysql:mysql /var/lib/mysql -R #启动mysql systemctl start mysqld.service #查看生成的临时root密码 cat /var/log/mysqld.log [Note] A temporary password is generated for root@localhost: o+TU+KDOm004 -
修改root密码 授权远程访问 设置开机自启动
[root@node2 ~]# mysql -u root -p Enter password: #这里输入在日志中生成的临时密码 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.29 Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> #更新root密码 设置为hadoop mysql> alter user user() identified by "hadoop"; Query OK, 0 rows affected (0.00 sec) #授权 mysql> use mysql; # 密码和上面设置的保持一致 IDENTIFIED BY 'hadoop' mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION; mysql> FLUSH PRIVILEGES; #mysql的启动和关闭 状态查看 (这几个命令必须记住) systemctl stop mysqld systemctl status mysqld systemctl start mysqld #建议设置为开机自启动服务 [root@node2 ~]# systemctl enable mysqld Created symlink from /etc/systemd/system/multi-user.target.wants/mysqld.service to /usr/lib/systemd/system/mysqld.service. #查看是否已经设置自启动成功 [root@node2 ~]# systemctl list-unit-files | grep mysqld mysqld.service enabled
Hive安装
只需要在一台机器上安装即可。
-
上传安装包 解压
tar zxvf apache-hive-3.1.2-bin.tar.gz -
解决Hive与Hadoop之间guava版本差异
cd /export/server/apache-hive-3.1.2-bin/ rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/ -
修改配置文件
-
hive-env.sh
cd /export/server/apache-hive-3.1.2-bin/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/export/server/hadoop-3.3.0 export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib -
hive-site.xml
vim hive-site.xml<configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hadoop</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> </property> <!-- 远程模式部署metastore metastore地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration>
-
-
上传mysql jdbc驱动到hive安装包lib下
mysql-connector-java-5.1.32.jar -
初始化元数据
cd /export/server/apache-hive-3.1.2-bin/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表
metastore服务启动方式
前台启动,进程会一致占据终端,ctrl + c 结束进程,服务关闭,可以根据需求添加参数开启debug日志,获取详细日志信息,便于排错。
先切换目录到hive的bin目录下
hive --service metastore
后台启动
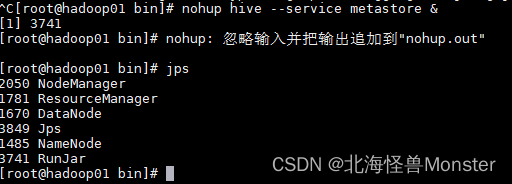
nohup hive --service metastore &
再按一次回车,RunJar就说明启动成功
日志再当前目录下的 nohub.out 文件
杀死进程 kill -9 3741
Hive客户端
Hive自带客户端
再bin目录下 提供新老两个客户端
老版本 hive 新版本beeline
老版本直接访问 Metastore
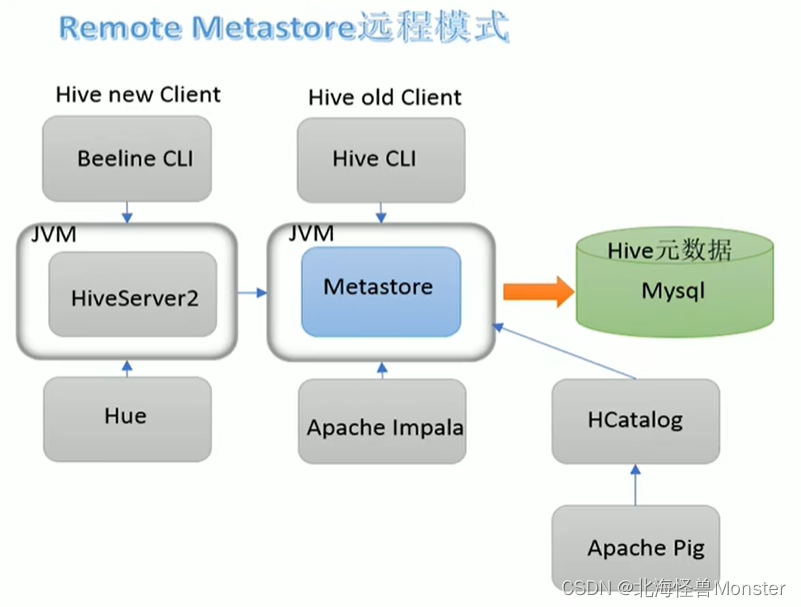
新版本,需要启动两个服务,两个服务还有依赖关系。Beeline客户端首先访问HiveServer2服务,HiveServer2再去访问呢Metastore服务,进而访问元数据。
第一代客户端(deprecated不推荐使用),bin/hive 是一个shell Util,主要功能是:一是可用于以交互或批处理模式运行Hive查询,二是用于Hive相关服务的启动,比如metastore服务
第二代客户端(recommended推荐使用),bin/beeline 是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高。
使用beeline客户端,首先要启动 metastore服务,然后再启动hiveserver2服务
注意,服务启动需要时间,不要metastore启动之后立即启动hiveserver2服务,要等个一两分钟再去启动。
启动hiveserver2服务命令
依然需要再bin目录下执行,不然就需要写hive的全路径
nohup hive --service hiveserver2 &
启动成功之后就会有一个新的 RunJar
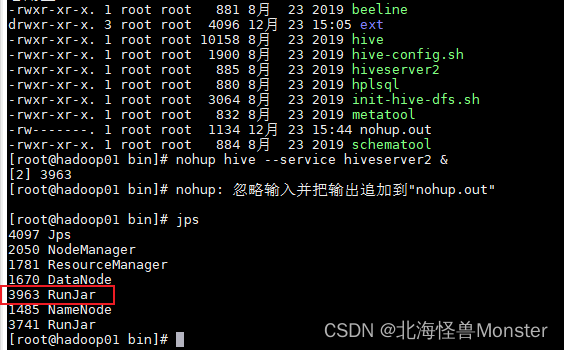
Hive客户端启动
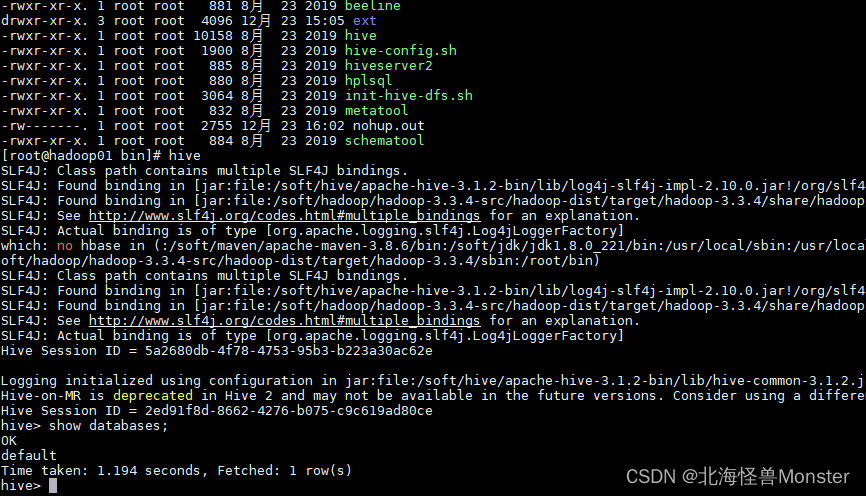
第一代客户端,直接运行 hive即可,hive客户端会根据我们配置文件直接去连接metastore服务
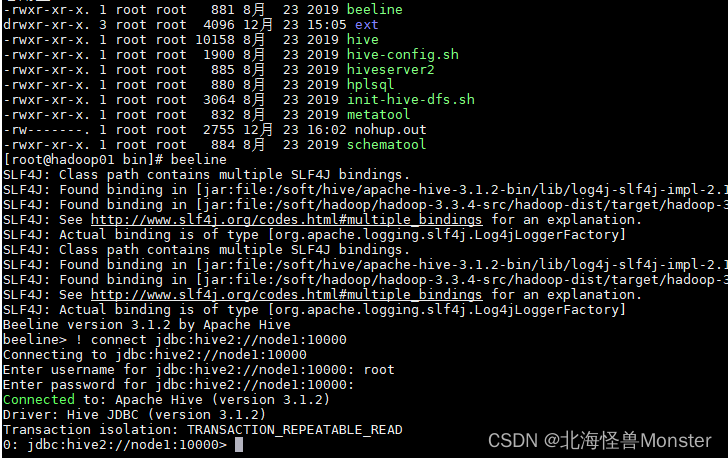
第二代客户端:
运行beeline,之后我们需要手动输入 hiveserver2 服务的地址,首先去连接 hiveserver2,hiveserver2会根据配置文件自动取连接metastore服务,但是 hiveserver2我们没有在配置文件中指定位置,所以需要手动输入:
node1 是因为我们配置了host文件,要是没有配置需要写完整的ip地址
使用root用户连接,root用户不需要输入密码,直接回车即可
! connect jdbc:hive2://node1:10000
Hive第三方可视化客户端
DataGrip
可以在Windows 、 MAC 平台中通过JDBC连接HiveServer2的图形界面工具。
视频教程中,专门用了这款软件,其实在IDEA中有集成的。
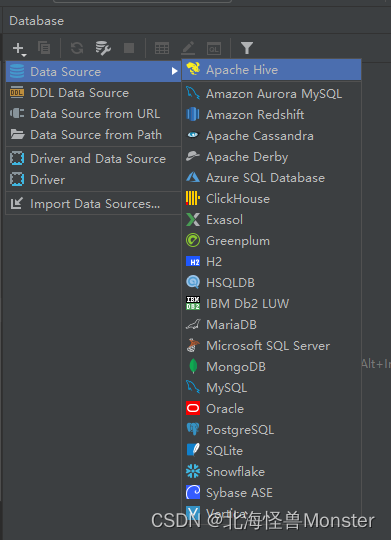
第一次连接显示没有驱动,下载即可
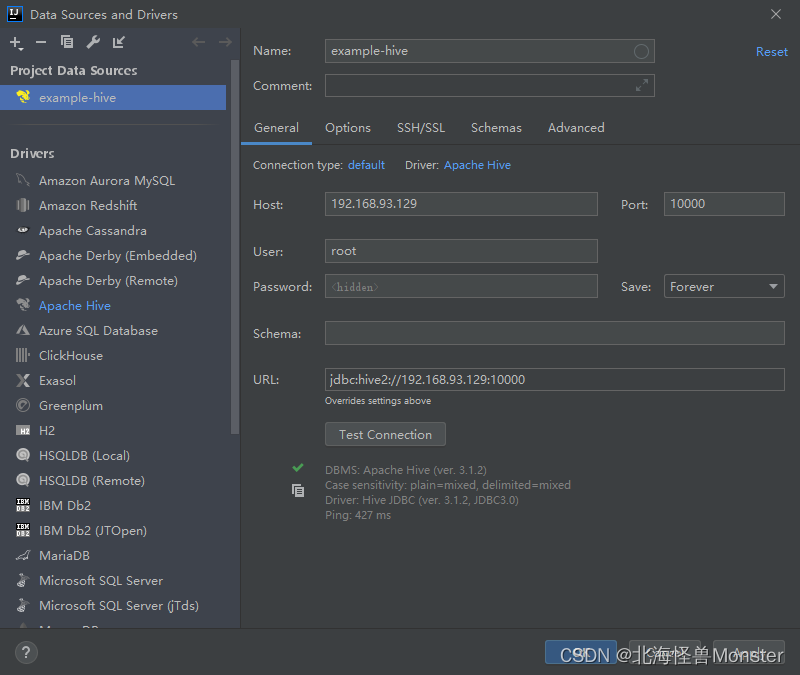
当然你也可以专门下载 DataGrip这款专门连接数据库的工具,会更专业。
将sql文件像项目一样管理。
Hive SQL语言:DDL建库、建表
Hive SQL 与标准SQL语法大同小异,基本相通;
基于Hive设计使用特点, HQL中的create语法是重点,建表是否合适直接影响数据文件是否映射成功,进而影响后续是否可以基于SQL分析数据,直白一点,没有表,表没有数据,Hive分析根本不起作用。所以在Hive中建表非常重要。
在Hive中,默认的数据库叫做default,存储数据位置位于 HDFS 的user/hive/warehouse
用户自己创建的数据库存储位置是 user/hive/warehouse/database_name.db
create database -- 用于创建新的数据库
-- comment :数据库解释说明语句
-- location : 指定数据库在HDFS存储位置,一般不指定
-- with dbproperties:用于指定一些数据库的属性配置
user database -- 切换数据库
drop database -- 删除数据库,必须要求数据库为空,下面没有数据表
drop database cascade -- 等于 rm -rf
建表,很重要,这关系到表和文件的映射关系。
创建表的语法:
create table 表名(
字段名 字段类型 约束,
字段名 字段类型 约束
)
数据类型:分为两大类:原生数据类型,复杂数据类型
最常用的是 字符串String和数字类型int。
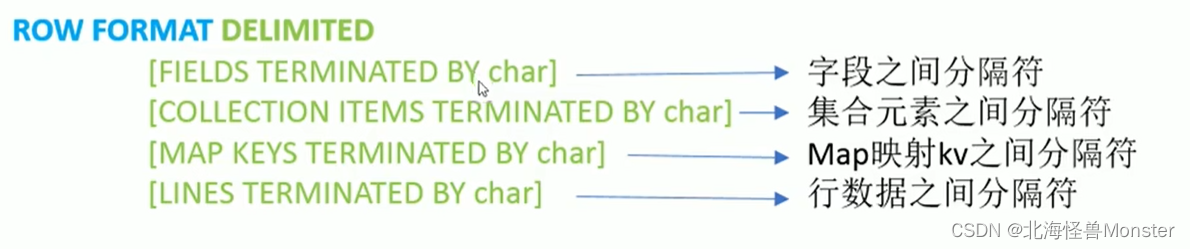
分隔符(hive可以将结构化文件映射成为表)
LazySimpleSerDe是Hive默认的,包含4种子语法,分别用于指定:字段之间,集合元素之间,map映射 kv之间,换行之间的分隔符号
在建表的时候可以根据数据特点灵活搭配使用
练习:针对以下数据建表

-- 建立在default数据库下
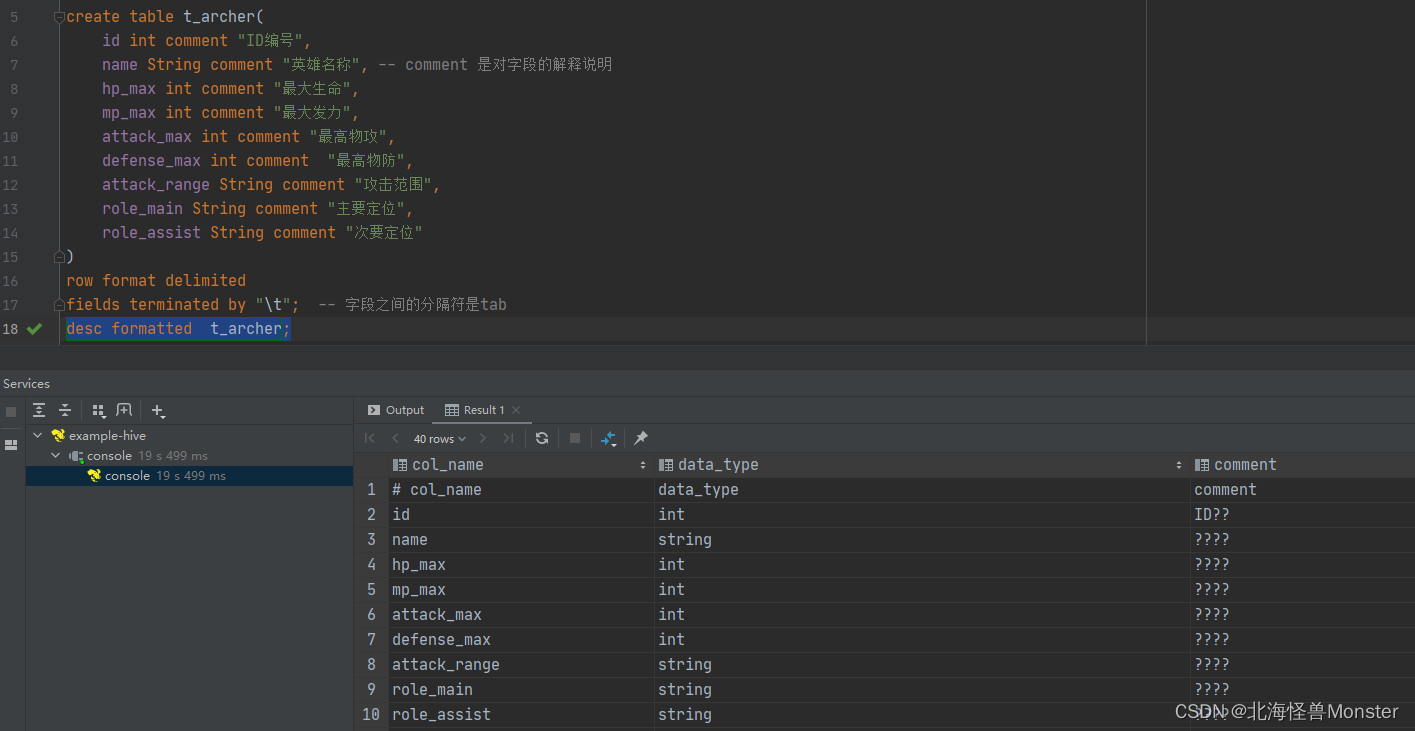
create table t_archer(
id int comment "ID编号",
name String comment "英雄名称", -- comment 是对字段的解释说明
hp_max int comment "最大生命",
mp_max int comment "最大发力",
attack_max int comment "最高物攻",
defense_max int comment "最高物防",
attack_range String comment "攻击范围",
role_main String comment "主要定位",
role_assist String comment "次要定位"
)
row format delimited
fields terminated by "\t"; -- 字段之间的分隔符是tab
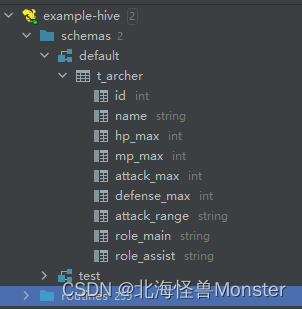
再将对应txt文件上传到对应的hadoop路径中
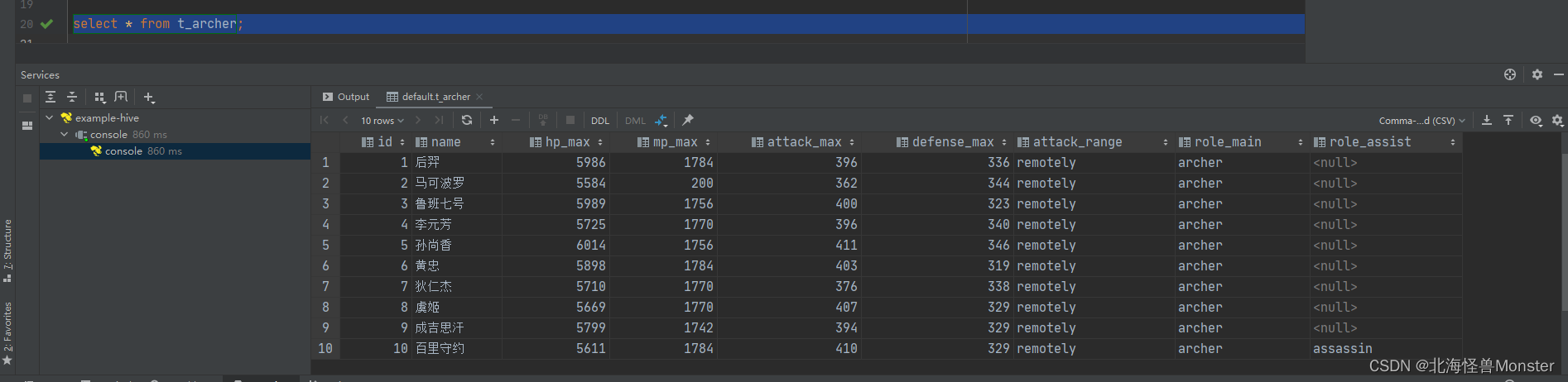
查看数据,我们并没有往表中插入数据,只需要把对应文件放入对应的hadoop路径中,再通过Hive写一个SQL语句,就可以将结构化文件中的数据查询出来。
Hive默认分隔符
Hive建表的时候如果没有指定分隔符,采用默认分隔符
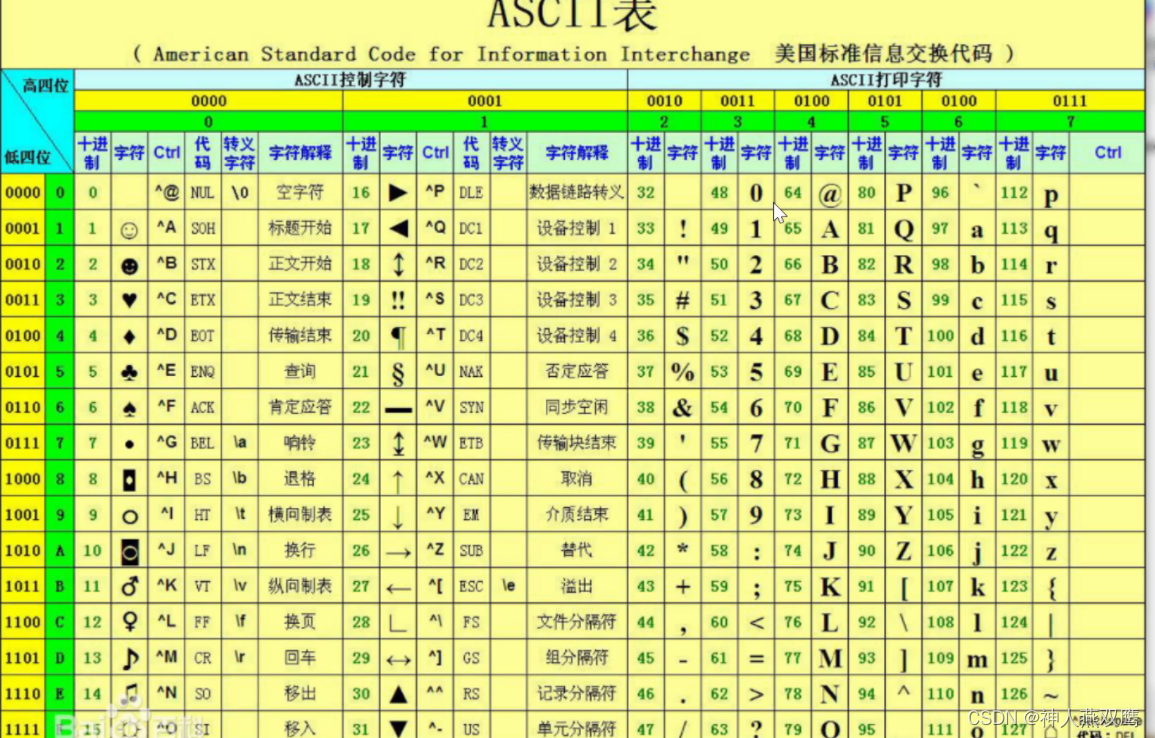
默认分隔符是 ‘\001’ ,是一种特殊的字符,使用的是ASCII编码的指,键盘是打不出来的
再vi 编辑器中特殊字符是: ^A
在文本编辑器中打开是:soh
常见的一些语法
1、显示所有数据库
show datanases;
show schemas;
2、显示当前数据库所有表
show tables
show tables in 数据库名 – 显示其他数据库,就不用use去切换
3、显示一张便的元素据
desc formatted 数据表名
注释comment中文乱码问题解决
解决:
连接上你存储元数据的数据库,我这儿是在mysql中。
就是因为存放元数据的表,是其他编码,对中文支持不友好,你修改之后呢,之前创建的表,还是会乱码,只有删除重建才会生效。
不过这个无所谓了,一般都会文档存放注释信息的。
--注意 下面sql语句是需要在MySQL中执行 修改Hive存储的元数据信息(metadata)
use hive3;
show tables;
alter table hive3.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table hive3.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive3.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table hive3.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table hive3.INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;