项目环境配置
根据需求实现项目环境配置
实施
- 注意:所有软件Docker、Hadoop、Hive、Spark、Sqoop都已经装好,不需要额外安装配置,启动即可
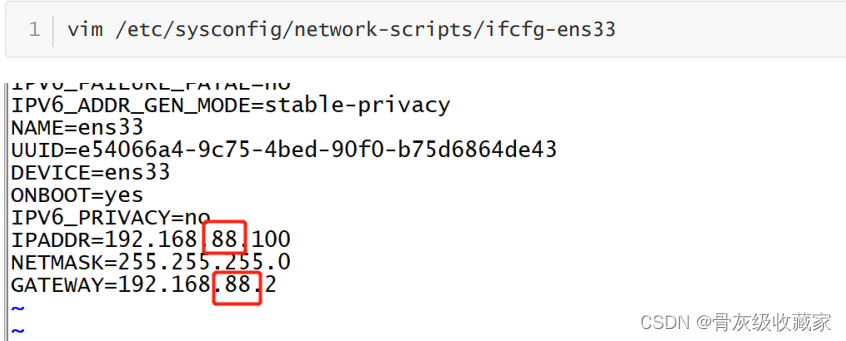
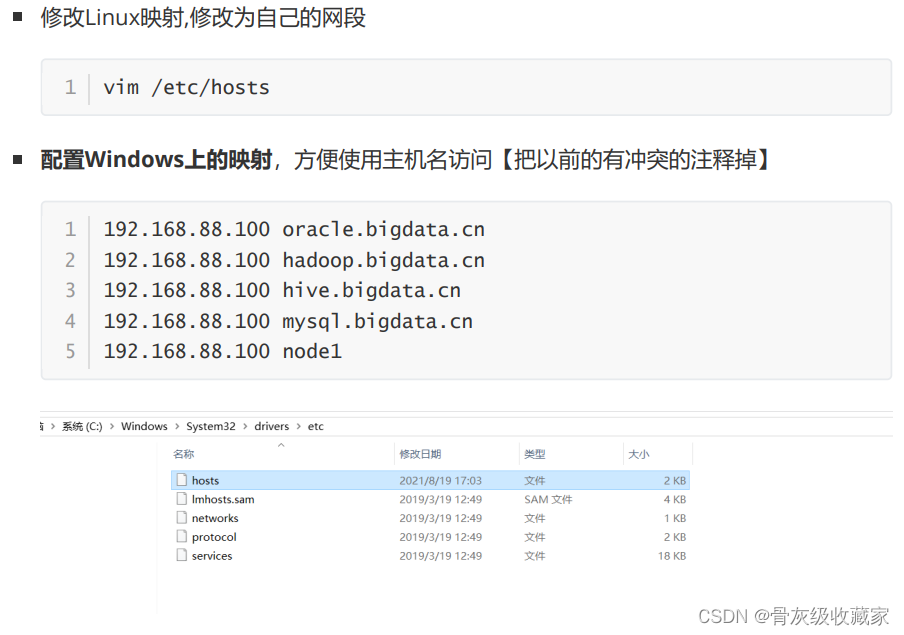
配置网络:如果你的VM Nat网络不是88网段,请按照以下修改
- 修改Linux虚拟机的ens33网卡,网卡和网关,修改为自己的网段

配置映射
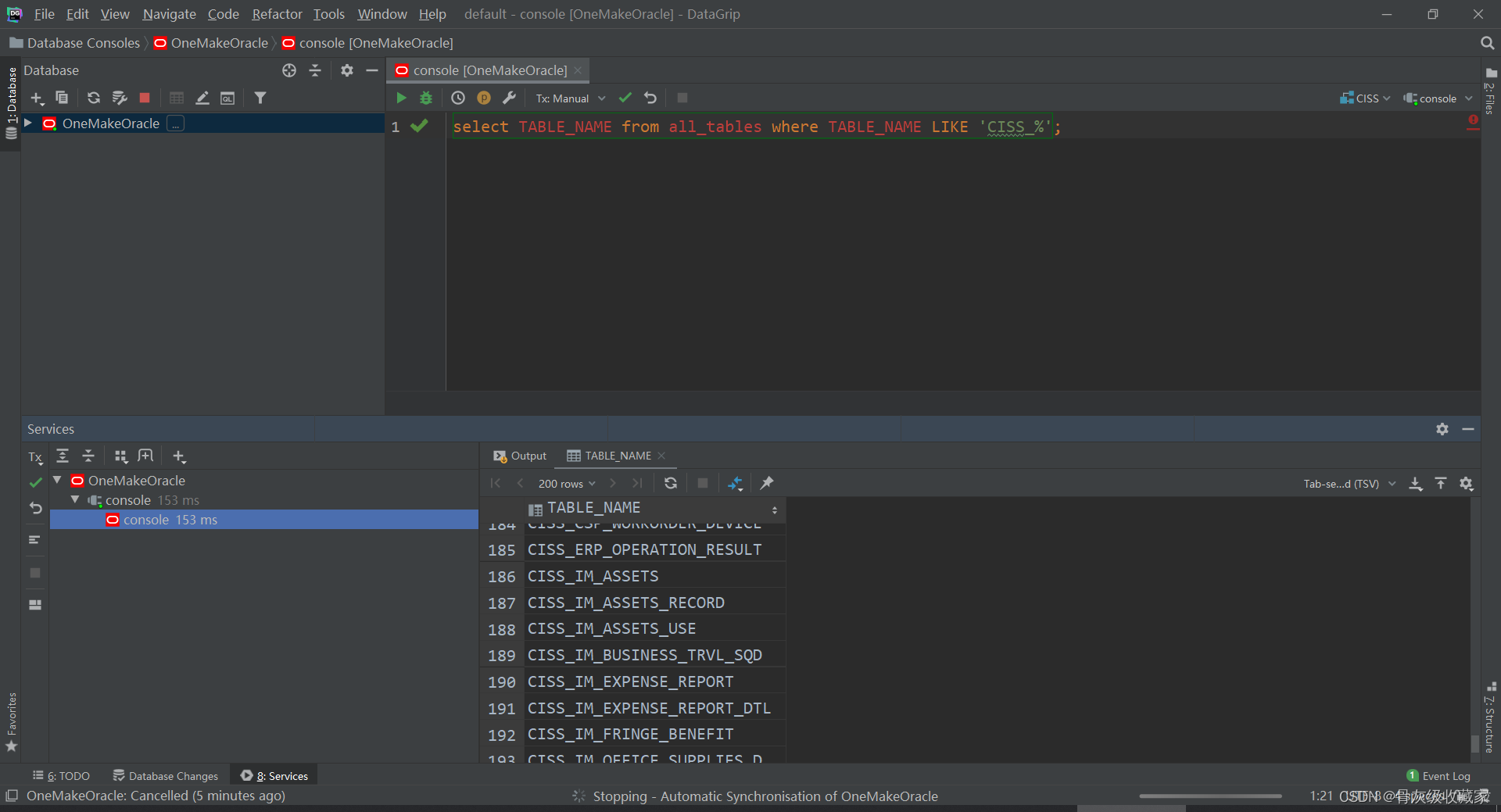
 项目环境测试:Oracle
项目环境测试:Oracle
实现项目Oracle环境的测试
实施
 - 远程连接:DG
- 远程连接:DG
- step1:安装DG
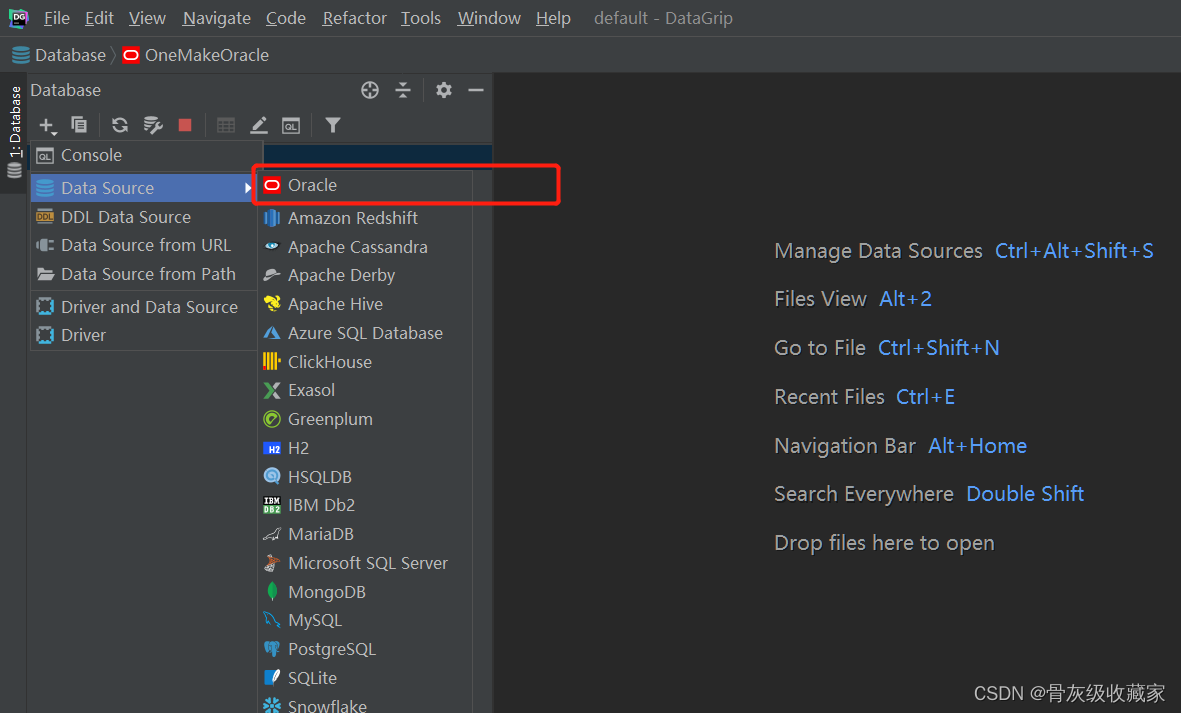
- step2:创建连接
- SID:helowin
- 用户名:ciss
- 密码:123456
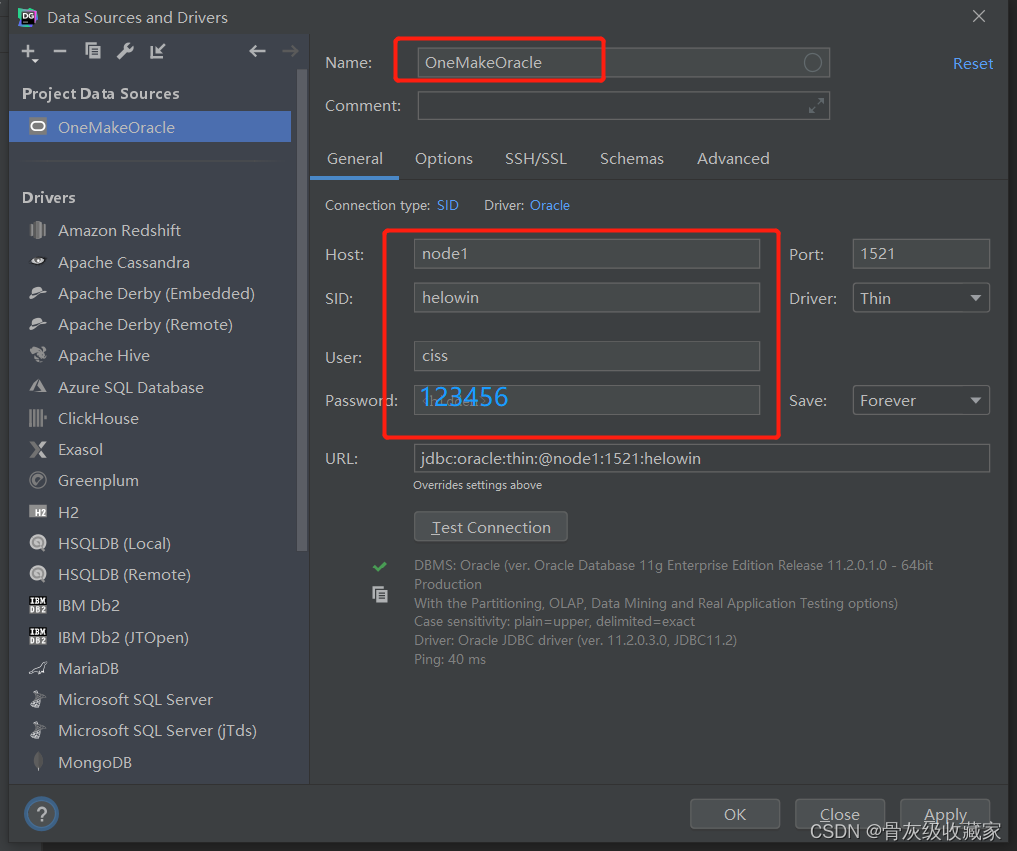
step3:配置驱动包
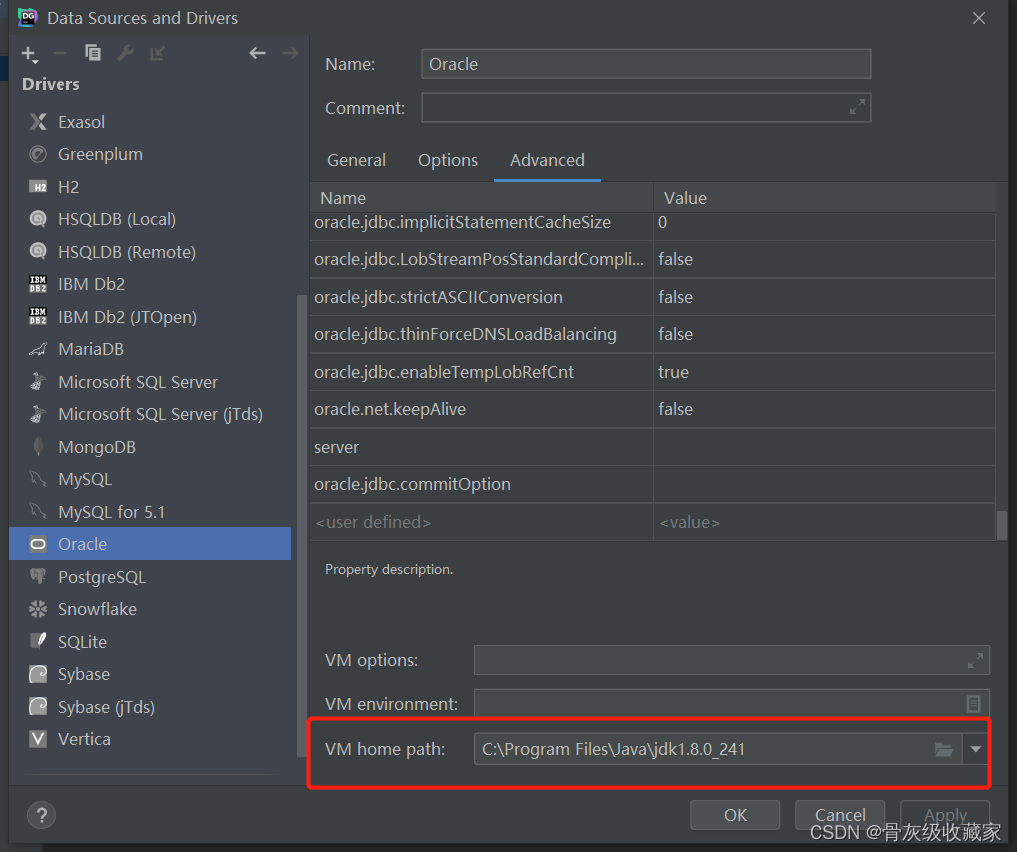
step4:配置JDK
step5:测试
- 关闭

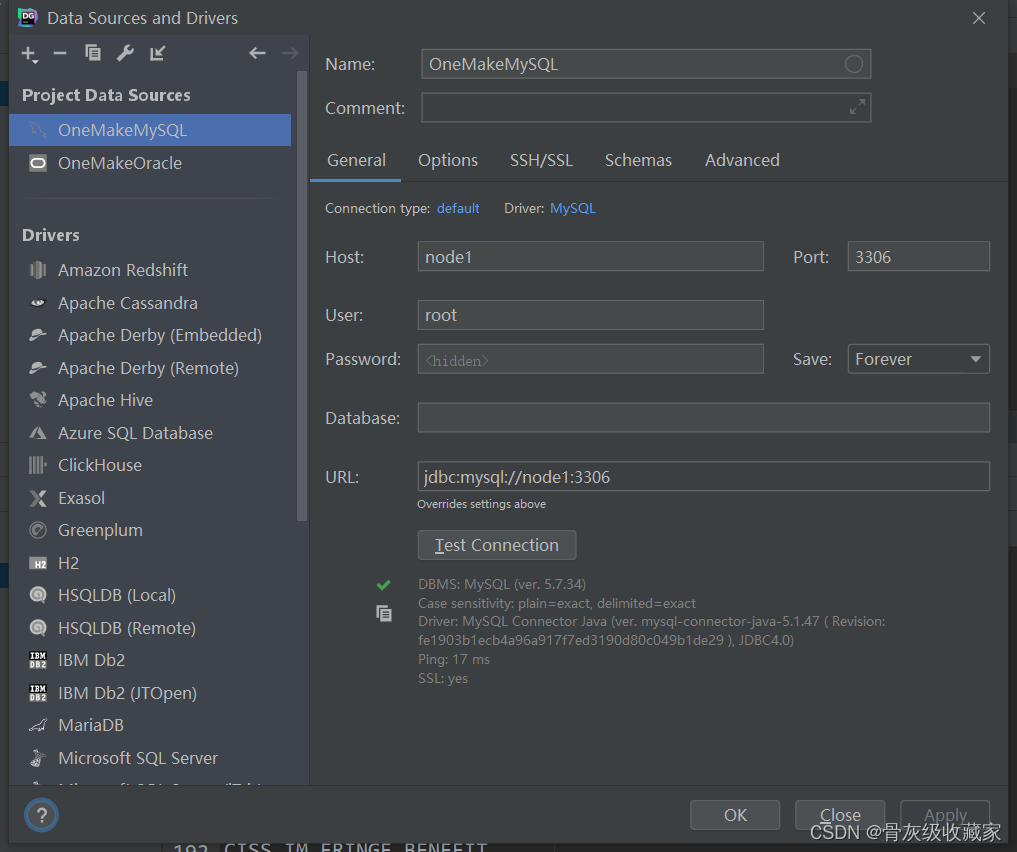
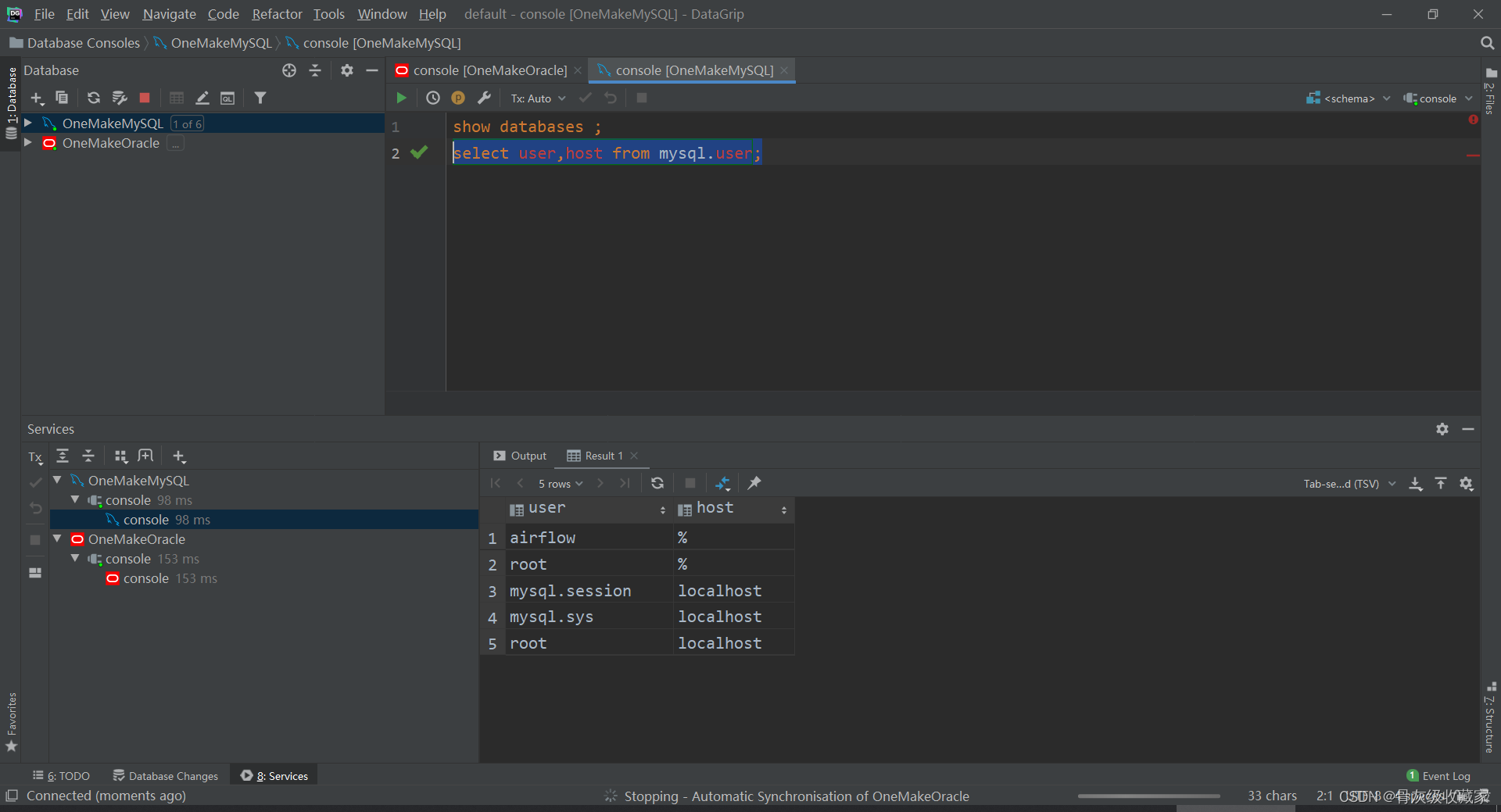
项目环境测试:MySQL
实现项目MySQL环境的测试
实施
- 大数据平台中自己管理的MySQL:两台机器
- 存储软件元数据:Hive、Sqoop、Airflow、Oozie、Hue
- 存储统计分析结果
- 注意:MySQL没有使用Docker容器部署,直接部署在当前node1宿主机器上
- 启动/关闭:默认开启自启动
- 连接:使用命令行客户端、Navicat、DG都可以
- 用户名:root
- 密码:123456

查看
项目环境测试:Hadoop
目标:实现项目Hadoop环境的测试
实施

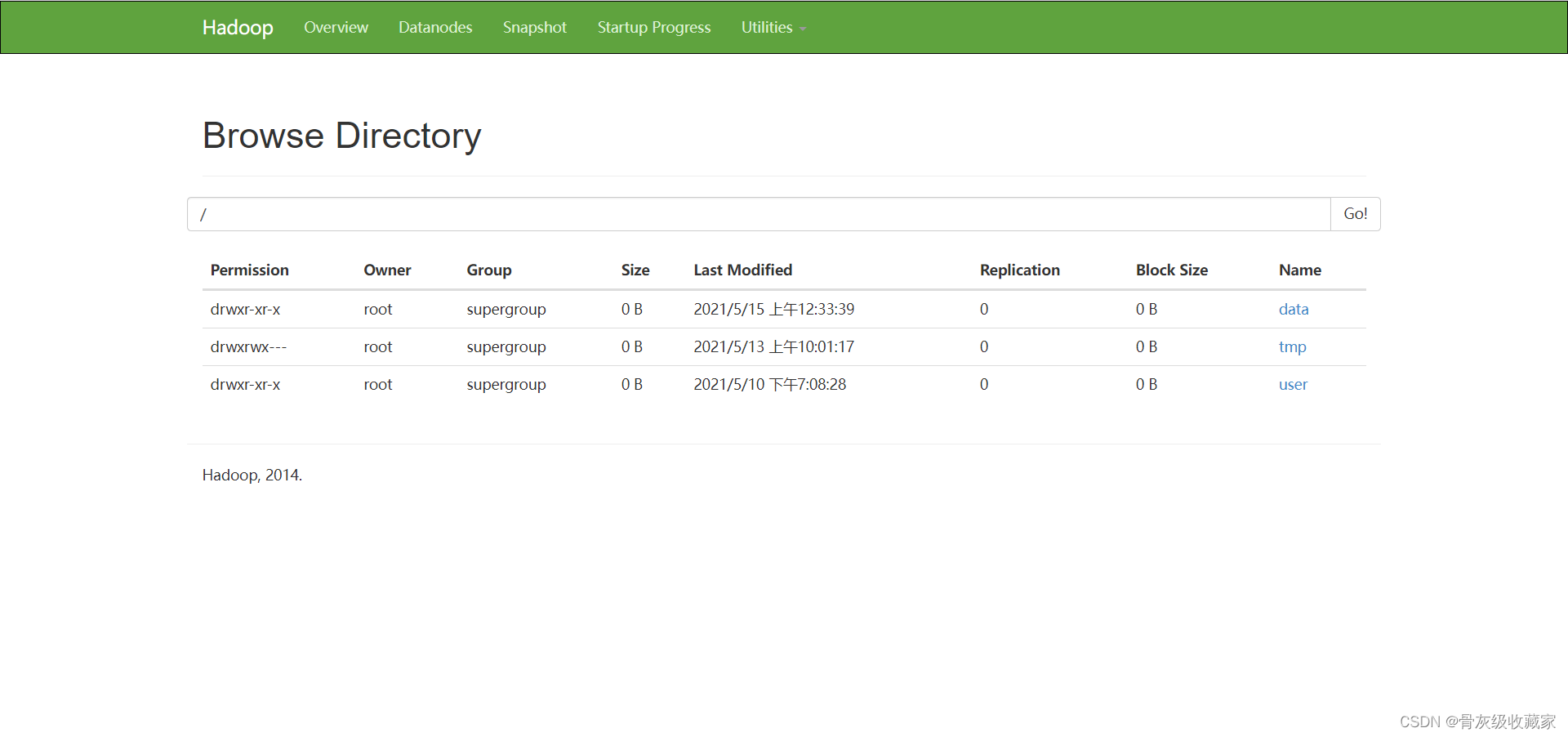
node1:8088

node1:19888

项目环境测试:Hive
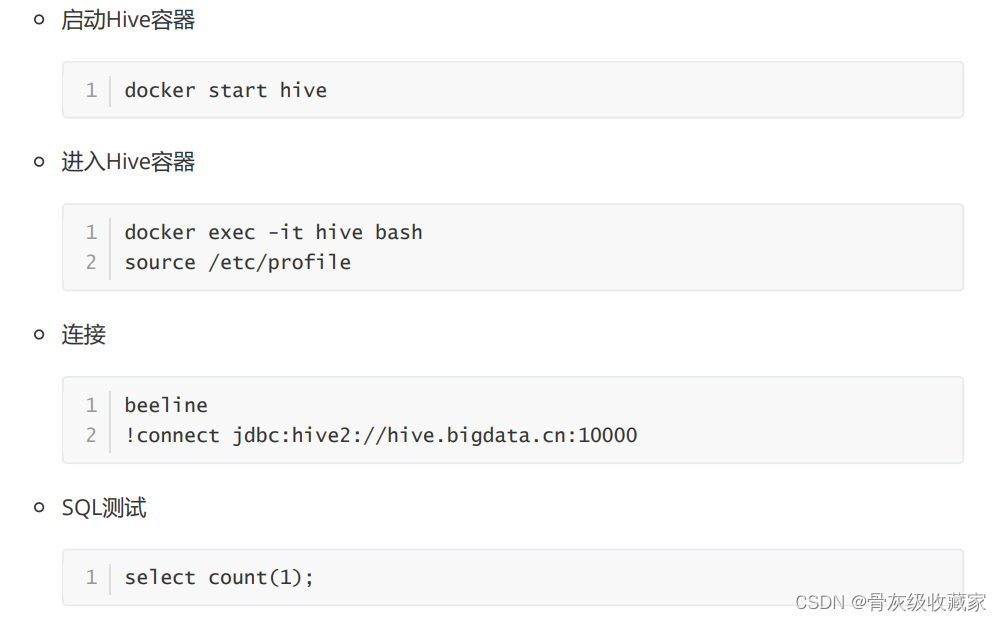
目标:实现项目Hive环境的测试
实施
- Shuffle【分区、排序、分组】三种场景
- 重分区:repartition:分区个数由小变大
- 调用分区器对所有数据进行重新分区
- rdd1
- part0:1 2 3
- part1: 4 5 6
- rdd2:调用分区器【只有shuffle阶段才能调用分区器】
- part0:0 6
- part1:1 4
- part2:2 5
- 全局排序:sortBy
- part0:1 2 5
- part1: 4 3 6
- 方案:将所有数据放入磁盘
- 实现:对数据做了范围分区:将所有数据做了采样:4
- part0:6 5 4
- part1:3 2 1
- 全局分组:groupBy,reduceByKey
- 关闭Hive容器

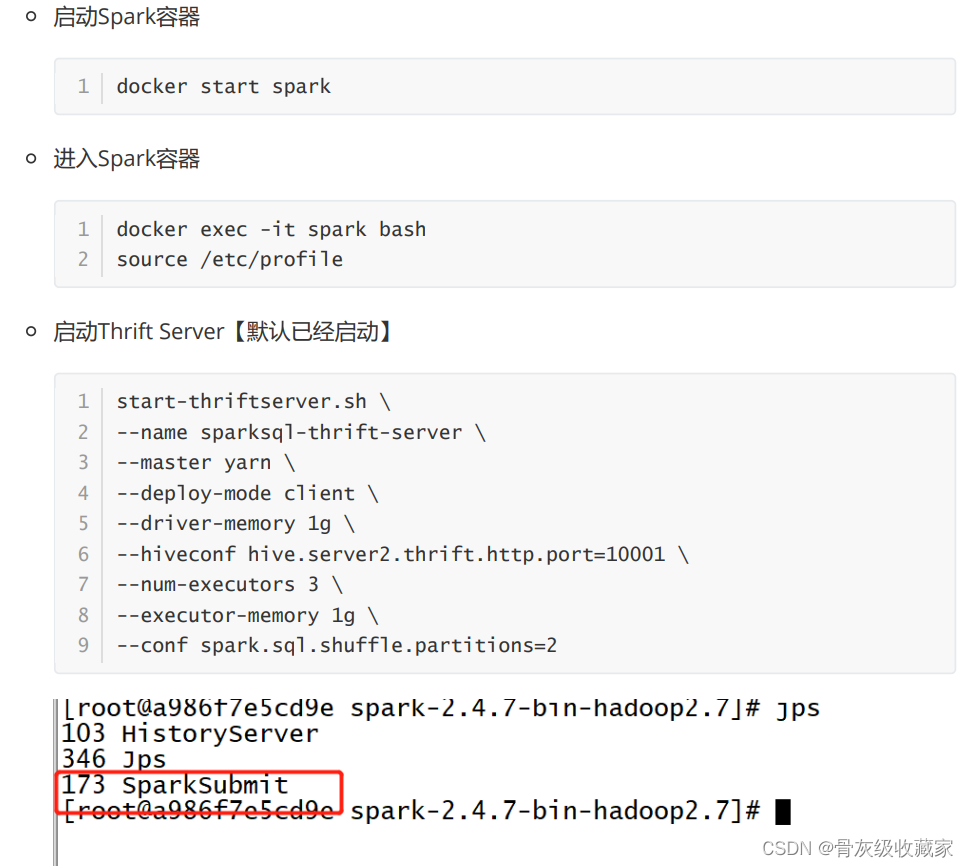
项目环境测试:Spark
目标:实现项目Spark环境的测试
实施
项目环境测试:Sqoop
目标:实现项目Sqoop环境的测试
实施

- 实现项目Sqoop环境的测试
## 要求
1. Python面向对象
- 类和对象
- 方法
2. Hive中建表语法
```
create [external] table tbname(
字段 类型 comment,
)
comment
partitioned by
clustered by col into N buckets
row format
stored as textfile
location
```