文章目录
- 概要
- 背景
- 方法
- 1. 概述
- 2. 参数更新
- 3.目标z'_ξ的构建和q_θ的预测
- 结果
- 结论
- 个人看法

概要
本篇博客介绍了Bootstrap Your Own Latent (BYOL)方法,这是DeepMind和Imperial London提出的一种自监督学习方法。
- BYOL 包含两个架构相同但参数不同的网络。
- BYOL 不需要负对,而大多数对比学习方法都需要,例如SimCLR
背景
对比学习 (contrastive learning, CL)目前在自我监督学习中取得了最先进的性能。在对比学习中,从相同图像创建的视图称为正对,而来自不同图像的视图称为负对。
然而,可以有无限数量的负对,CL 需要大量的负对以确保其性能。因此,这项工作提出了一个称为 BYOL 的新框架,以消除对负对的需求。
方法
1. 概述
这个框架中有两个网络。一个名为在线模型,另一个名为目标模型。在线模型由 θ 参数化,目标模型由 ξ 参数化。两个模型具有动态行为:
- 目标模型通过计算θ的指数移动平均值 (EMA)来更新其参数 ξ 。
- 在线模型通过学习目标模型的参数 ξ 来更新其参数 θ。

2. 参数更新
我将在下面详细解释每个更新的方式:
-
ξ 由 θ 更新:这是通过计算指数移动平均线 (EMA) 完成的,其定义如下:
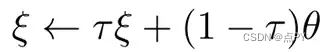
指数移动平均线 (EMA) 的公式。τ 是目标衰减率,τ ∈ [0,1]。假设与在某个时间序列上获得 θ 的简单平均值相比,EMA 为最近的 θ 分配了更大的权重。这可以从以下事实中看出:如果您展开右侧的 ξ,则 τ 变为 τⁿ(n 是时间步长)。随着 τ 越来越小,τⁿ 会变小,这意味着它的重要性正在衰减。 -
θ 由 ξ 更新:这是通过优化目标函数来完成的。目标函数是归一化预测 q_θ_bar 和目标 z’_ξ_bar 之间的均方误差:
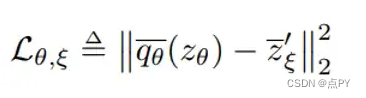
-
q_θ_bar 是 q_θ 的L2 归一化
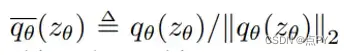
-
z’_ξ_bar 是 z’_ξ 的 L2 归一化:
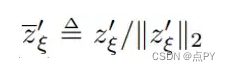
3.目标z’_ξ的构建和q_θ的预测
这是该方法的核心部分。在在线模型中,分为三个阶段:encoder f_θ、projector g_θ和predictor q_θ。
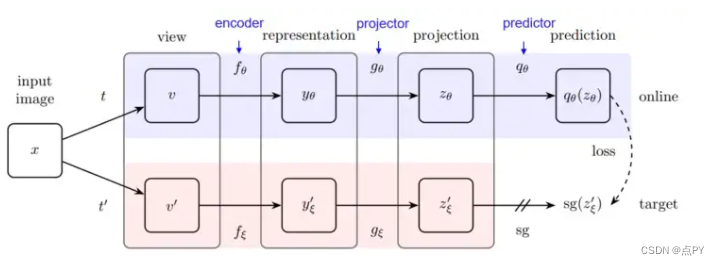
在线模型由编码器、投影仪和预测器组成。在线模型通过上述目标函数预测目标的投影。sg 代表停止梯度,意味着梯度不会在目标模型中反向传播,因为目标模型是使用 EMA 更新的。训练后,除了 f_θ 之外的所有东西都被丢弃。
整个结构很可能建立在SimCLR框架之上,因此我将简要介绍一下。在 SimCLR 中,输入图像通过 t 和 t’ 进行变换以生成两个增强视图,然后通过编码器 f(⋅) 和投影仪 g(⋅) 以获得投影表示。然后对比投影表示 zᵢ 和 zⱼ 以最大化它们的一致性,发现这比直接最大化 hᵢ 和 hⱼ 之间的一致性导致更好的性能。负对是通过使用来自不同输入图像的视图来构建的。
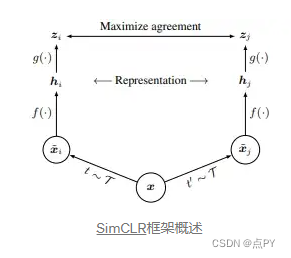
然而,不同之处在于,在 BYOL 中,两个视图是通过不同的编码器 f_θ 和 f_ξ 生成的。这两个是相同的架构,但参数不同。此外,在 BYOL 中,有一个预测器和一个目标网络。如您所见,在 BYOL 中,不需要负数对。
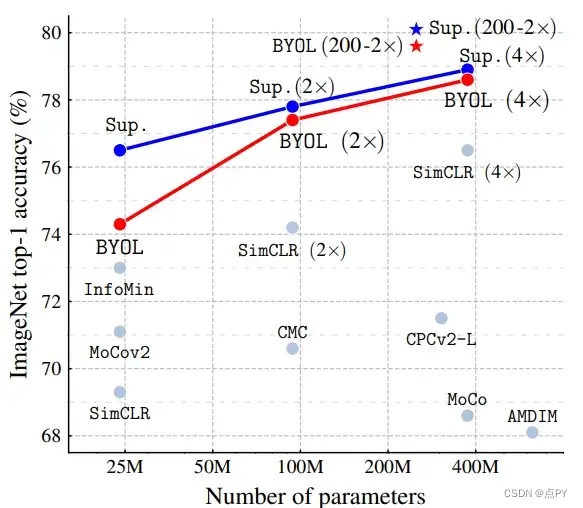
结果
结论
-
BYOL 提供了一种不需要负对的自我监督学习的新方法。
-
BYOL 有两种模型,架构相同但参数不同。在线模型通过优化目标函数来更新其参数。目标模型通过计算指数移动平均值来更新其参数。
个人看法
-
构造足够多的负对是保证对比学习性能的重要一步。否则,可能会发生称为折叠表示的问题。这项工作为不使用负对的自监督学习开辟了一条新途径。
-
EMA 用于考虑以前的 θ,偏向较新的。该技术已用于其他方法,例如Adam优化器。原始论文还对 EMA 的 τ 进行了消融研究。