工作中我们时常会遇到跨数据库操作的情况,这时候就需要配置多数据源,那么如何配置呢?常用的方式及其背后的原理支撑是什么呢?我们下面来了解一下。
首先看看两种常见的配置方式,分别为通过多个 @Configuration 文件、利用 AbstractRoutingDataSource 配置多数据源。
第一种方式:多个数据源的 @Configuration 的配置方法
这种方式的主要思路是,不同 Package 下面的实体和 Repository 采用不同的 Datasource。所以我们改造一下我们的 example 目录结构,来看看不同 Repositories 的数据源是怎么处理的。
第一步:规划 Entity 和 Repository 的目录结构,为了方便配置多数据源。
将 User 和 UserAddress、UserRepository 和 UserAddressRepository 移动到 db1 里面;将 UserInfo 和 UserInfoRepository 移动到 db2 里面。如下图所示:
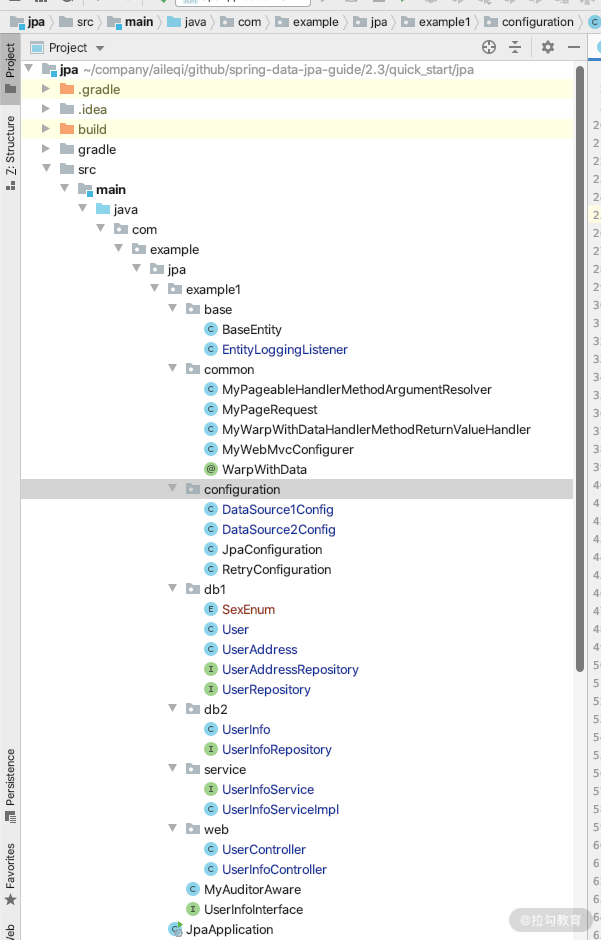
我们把实体和 Repository 分别放到了 db1 和 db2 两个目录里面,这时我们假设数据源 1 是 MySQL,User 表和 UserAddress 在数据源 1 里面,那么我们需要配置一个 DataSource1 的 Configuration 类,并且在里面配置 DataSource、TransactionManager 和 EntityManager。
第二步:配置 DataSource1Config 类。
目录结构调整完之后,接下来我们开始配置数据源,完整代码如下:
复制代码
@Configuration
@EnableTransactionManagement//开启事务
//利用EnableJpaRepositories配置哪些包下面的Repositories,采用哪个EntityManagerFactory和哪个trannsactionManager
@EnableJpaRepositories(
basePackages = {"com.example.jpa.example1.db1"},//数据源1的repository的包路径
entityManagerFactoryRef = "db1EntityManagerFactory",//改变数据源1的EntityManagerFactory的默认值,改为db1EntityManagerFactory
transactionManagerRef = "db1TransactionManager"//改变数据源1的transactionManager的默认值,改为db1TransactionManager
)
public class DataSource1Config {
/**
* 指定数据源1的dataSource配置
* @return
*/
@Primary
@Bean(name = "db1DataSourceProperties")
@ConfigurationProperties("spring.datasource1") //数据源1的db配置前缀采用spring.datasource1
public DataSourceProperties dataSourceProperties() {
return new DataSourceProperties();
}
/**
* 可以选择不同的数据源,这里我用HikariDataSource举例,创建数据源1
* @param db1DataSourceProperties
* @return
*/
@Primary
@Bean(name = "db1DataSource")
@ConfigurationProperties(prefix = "spring.datasource.hikari.db1") //配置数据源1所用的hikari配置key的前缀
public HikariDataSource dataSource(@Qualifier("db1DataSourceProperties") DataSourceProperties db1DataSourceProperties) {
HikariDataSource dataSource = db1DataSourceProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build();
if (StringUtils.hasText(db1DataSourceProperties.getName())) {
dataSource.setPoolName(db1DataSourceProperties.getName());
}
return dataSource;
}
/**
* 配置数据源1的entityManagerFactory命名为db1EntityManagerFactory,用来对实体进行一些操作
* @param builder
* @param db1DataSource entityManager依赖db1DataSource
* @return
*/
@Primary
@Bean(name = "db1EntityManagerFactory")
public LocalContainerEntityManagerFactoryBean entityManagerFactory(EntityManagerFactoryBuilder builder, @Qualifier("db1DataSource") DataSource db1DataSource) {
return builder.dataSource(db2DataSource)
.packages("com.example.jpa.example1.db1") //数据1的实体所在的路径
.persistenceUnit("db1")// persistenceUnit的名字采用db1
.build();
}
/**
* 配置数据源1的事务管理者,命名为db1TransactionManager依赖db1EntityManagerFactory
* @param db1EntityManagerFactory
* @return
*/
@Primary
@Bean(name = "db1TransactionManager")
public PlatformTransactionManager transactionManager(@Qualifier("db1EntityManagerFactory") EntityManagerFactory db1EntityManagerFactory) {
return new JpaTransactionManager(db1EntityManagerFactory);
}
}
到这里,数据源 1 我们就配置完了,下面再配置数据源 2。
第三步:配置 DataSource2Config类,加载数据源 2。
复制代码
@Configuration
@EnableTransactionManagement//开启事务
//利用EnableJpaRepositories,配置哪些包下面的Repositories,采用哪个EntityManagerFactory和哪个trannsactionManager
@EnableJpaRepositories(
basePackages = {"com.example.jpa.example1.db2"},//数据源2的repository的包路径
entityManagerFactoryRef = "db2EntityManagerFactory",//改变数据源2的EntityManagerFactory的默认值,改为db2EntityManagerFactory
transactionManagerRef = "db2TransactionManager"//改变数据源2的transactionManager的默认值,改为db2TransactionManager
)
public class DataSource2Config {
/**
* 指定数据源2的dataSource配置
*
* @return
*/
@Bean(name = "db2DataSourceProperties")
@ConfigurationProperties("spring.datasource2") //数据源2的db配置前缀采用spring.datasource2
public DataSourceProperties dataSourceProperties() {
return new DataSourceProperties();
}
/**
* 可以选择不同的数据源,这里我用HikariDataSource举例,创建数据源2
*
* @param db2DataSourceProperties
* @return
*/
@Bean(name = "db2DataSource")
@ConfigurationProperties(prefix = "spring.datasource.hikari.db2") //配置数据源2的hikari配置key的前缀
public HikariDataSource dataSource(@Qualifier("db2DataSourceProperties") DataSourceProperties db2DataSourceProperties) {
HikariDataSource dataSource = db2DataSourceProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build();
if (StringUtils.hasText(db2DataSourceProperties.getName())) {
dataSource.setPoolName(db2DataSourceProperties.getName());
}
return dataSource;
}
/**
* 配置数据源2的entityManagerFactory命名为db2EntityManagerFactory,用来对实体进行一些操作
*
* @param builder
* @param db2DataSource entityManager依赖db2DataSource
* @return
*/
@Bean(name = "db2EntityManagerFactory")
public LocalContainerEntityManagerFactoryBean entityManagerFactory(EntityManagerFactoryBuilder builder, @Qualifier("db2DataSource") DataSource db2DataSource) {
return builder.dataSource(db2DataSource)
.packages("com.example.jpa.example1.db2") //数据2的实体所在的路径
.persistenceUnit("db2")// persistenceUnit的名字采用db2
.build();
}
/**
* 配置数据源2的事务管理者,命名为db2TransactionManager依赖db2EntityManagerFactory
*
* @param db2EntityManagerFactory
* @return
*/
@Bean(name = "db2TransactionManager")
public PlatformTransactionManager transactionManager(@Qualifier("db2EntityManagerFactory") EntityManagerFactory db2EntityManagerFactory) {
return new JpaTransactionManager(db2EntityManagerFactory);
}
}
这一步你需要注意,DataSource1Config 和 DataSource2Config 不同的是,1 里面每个 @Bean 都 @Primary,而 2 里面不是的。
第四步:通过 application.properties 配置两个数据源的值,代码如下:
复制代码
###########datasource1 采用Mysql数据库
spring.datasource1.url=jdbc:mysql://localhost:3306/test2?logger=Slf4JLogger&profileSQL=true
spring.datasource1.username=root
spring.datasource1.password=root
##数据源1的连接池的名字
spring.datasource.hikari.db1.pool-name=jpa-hikari-pool-db1
##最长生命周期15分钟够了
spring.datasource.hikari.db1.maxLifetime=900000
spring.datasource.hikari.db1.maximumPoolSize=8
###########datasource2 采用h2内存数据库
spring.datasource2.url=jdbc:h2:~/test
spring.datasource2.username=sa
spring.datasource2.password=sa
##数据源2的连接池的名字
spring.datasource.hikari.db2.pool-name=jpa-hikari-pool-db2
##最长生命周期15分钟够了
spring.datasource.hikari.db2.maxLifetime=500000
##最大连接池大小和数据源1区分开,我们配置成6个
spring.datasource.hikari.db2.maximumPoolSize=6
第五步:我们写个 Controller 测试一下。
复制代码
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@Autowired
private UserInfoRepository userInfoRepository;
//操作user的Repository
@PostMapping("/user")
public User saveUser(@RequestBody User user) {
return userRepository.save(user);
}
//操作userInfo的Repository
@PostMapping("/user/info")
public UserInfo saveUserInfo(@RequestBody UserInfo userInfo) {
return userInfoRepository.save(userInfo);
}
}
第六步:直接启动我们的项目,测试一下。
请看这一步的启动日志:
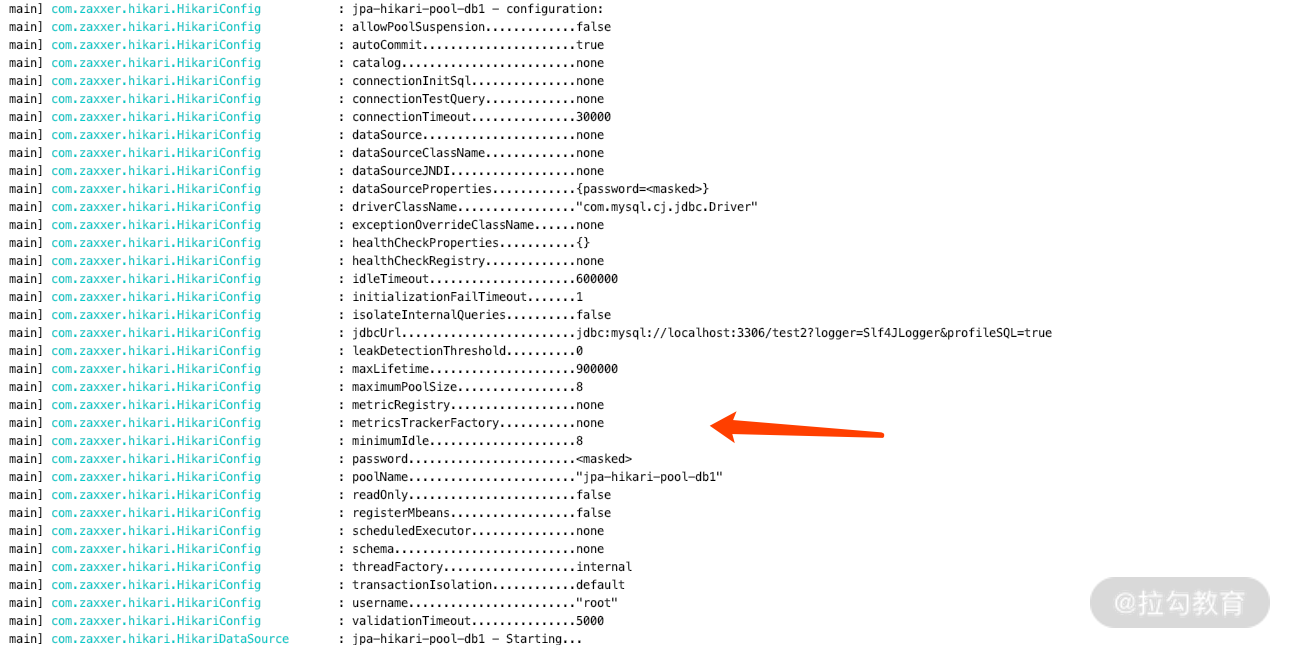
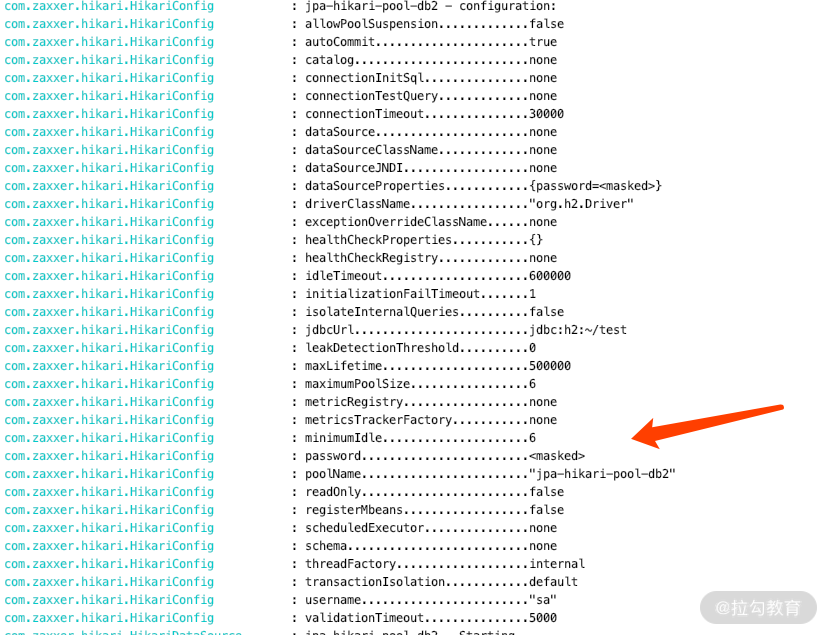
可以看到启动的是两个数据源,其对应的连接池的监控也是不一样的:数据源 1 有 8 个,数据源 2 有 6 个。

如果我们分别请求 Controller 写的两个方法的时候,也会分别插入到不同的数据源里面去。
通过上面的六个步骤你应该知道了如何配置多数据源,那么它的原理基础是什么呢?我们看一下
Datasource 与 TransactionManager、EntityManagerFactory 的关系和职责分别是怎么样的。
Datasource 与 TransactionManager、EntityManagerFactory 的关系分析
我们通过一个类的关系图来分析一下:
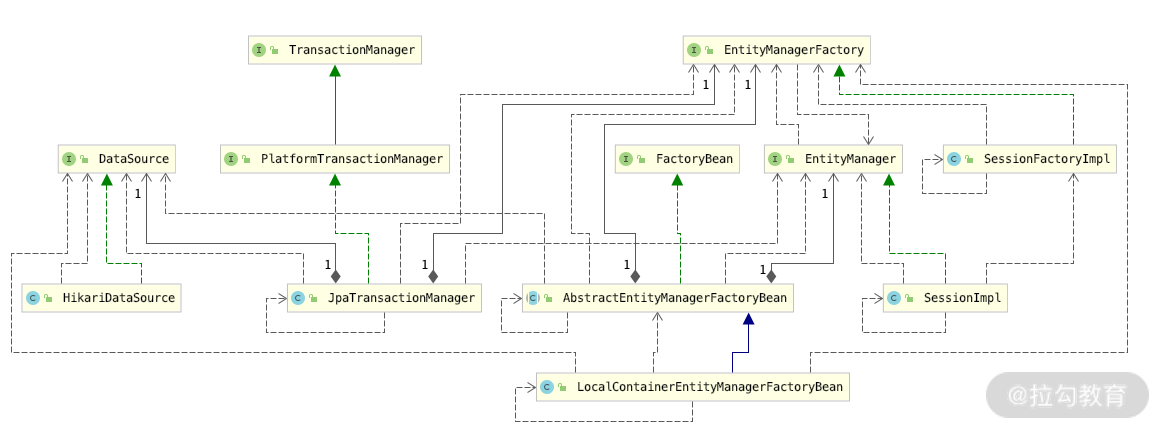
其中,
- HikariDataSource 负责实现 DataSource,交给 EntityManager 和 TransactionManager 使用;
- EntityManager 是利用 Datasouce 来操作数据库,而其实现类是 SessionImpl;
- EntityManagerFactory 是用来管理和生成 EntityManager 的,而 EntityManagerFactory 的实现类是 LocalContainerEntityManagerFactoryBean,通过实现 FactoryBean 接口实现,利用了 FactoryBean 的 Spring 中的 bean 管理机制,所以需要我们在 Datasource1Config 里面配置 LocalContainerEntityManagerFactoryBean 的 bean 的注入方式;
- JpaTransactionManager 是用来管理事务的,实现了 TransactionManager 并且通过 EntityFactory 和 Datasource 进行 db 操作,所以我们要在 DataSourceConfig 里面告诉 JpaTransactionManager 用的 TransactionManager 是 db1EntityManagerFactory。
上一讲我们介绍了 Datasource 的默认加载和配置方式,那么默认情况下 Datasource 的 EntityManagerFactory 和 TransactionManager 是怎么加载和配置的呢?
默认的 JpaBaseConfiguration 的加载方式分析
上一讲我只简单说明了 DataSource 的配置,其实我们还可以通过 HibernateJpaConfiguration,找到父类 JpaBaseConfiguration 类,如图所示:

接着打开 JpaBaseConfiguration 就可以看到多数据源的参考原型,如下图所示:
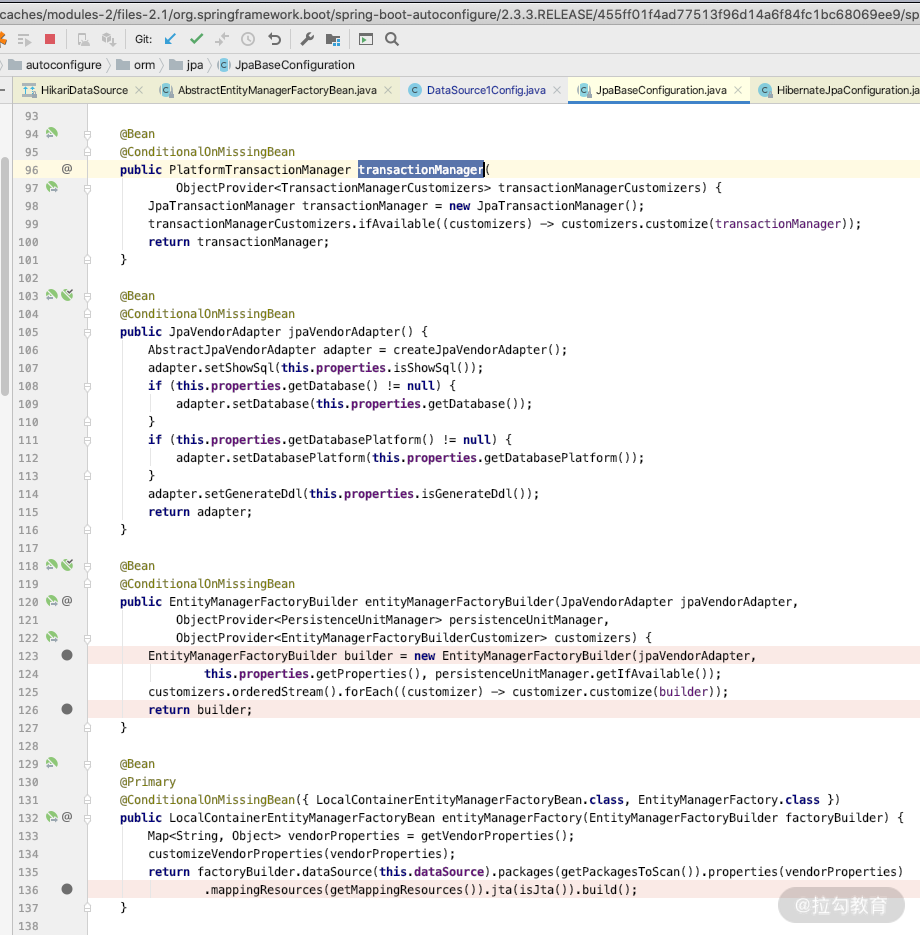
通过上面的代码,可以看到在单个数据源情况下的 EntityManagerFactory 和 TransactionManager 的加载方法,并且我们在多数据源的配置里面还加载了一个类:EntityManagerFactoryBuilder entityManagerFactoryBuilder,也正是从上面的方法加载进去的,看第 120 行代码就知道了。
那么除了上述的配置多数据源的方式,还有没有其他方法了呢?我们接着看一下。
第二种方式:利用 AbstractRoutingDataSource 配置多数据源
我们都知道 DataSource 的本质是获得数据库连接,而 AbstractRoutingDataSource 帮我们实现了动态获得数据源的可能性。下面还是通过一个例子看一下它是怎么使用的。
第一步:定一个数据源的枚举类,用来标示数据源有哪些。
复制代码
/**
* 定义一个数据源的枚举类
*/
public enum RoutingDataSourceEnum {
DB1, //实际工作中枚举的语义可以更加明确一点;
DB2;
public static RoutingDataSourceEnum findbyCode(String dbRouting) {
for (RoutingDataSourceEnum e : values()) {
if (e.name().equals(dbRouting)) {
return e;
}
}
return db1;//没找到的情况下,默认返回数据源1
}
}
第二步:新增 DataSourceRoutingHolder,用来存储当前线程需要采用的数据源。
复制代码
/**
* 利用ThreadLocal来存储,当前的线程使用的数据
*/
public class DataSourceRoutingHolder {
private static ThreadLocal<RoutingDataSourceEnum> threadLocal = new ThreadLocal<>();
public static void setBranchContext(RoutingDataSourceEnum dataSourceEnum) {
threadLocal.set(dataSourceEnum);
}
public static RoutingDataSourceEnum getBranchContext() {
return threadLocal.get();
}
public static void clearBranchContext() {
threadLocal.remove();
}
}
第三步:配置 RoutingDataSourceConfig,用来指定哪些 Entity 和 Repository 采用动态数据源。
复制代码
@Configuration
@EnableTransactionManagement
@EnableJpaRepositories(
//数据源的repository的包路径,这里我们覆盖db1和db2的包路径
basePackages = {"com.example.jpa.example1"},
entityManagerFactoryRef = "routingEntityManagerFactory",
transactionManagerRef = "routingTransactionManager"
)
public class RoutingDataSourceConfig {
@Autowired
@Qualifier("db1DataSource")
private DataSource db1DataSource;
@Autowired
@Qualifier("db2DataSource")
private DataSource db2DataSource;
/**
* 创建RoutingDataSource,引用我们之前配置的db1DataSource和db2DataSource
*
* @return
*/
@Bean(name = "routingDataSource")
public DataSource dataSource() {
Map<Object, Object> dataSourceMap = Maps.newHashMap();
dataSourceMap.put(RoutingDataSourceEnum.DB1, db1DataSource);
dataSourceMap.put(RoutingDataSourceEnum.DB2, db2DataSource);
RoutingDataSource routingDataSource = new RoutingDataSource();
//设置RoutingDataSource的默认数据源
routingDataSource.setDefaultTargetDataSource(db1DataSource);
//设置RoutingDataSource的数据源列表
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
/**
* 类似db1和db2的配置,唯一不同的是,这里采用routingDataSource
* @param builder
* @param routingDataSource entityManager依赖routingDataSource
* @return
*/
@Bean(name = "routingEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean entityManagerFactory(EntityManagerFactoryBuilder builder, @Qualifier("routingDataSource") DataSource routingDataSource) {
return builder.dataSource(routingDataSource).packages("com.example.jpa.example1") //数据routing的实体所在的路径,这里我们覆盖db1和db2的路径
.persistenceUnit("db-routing")// persistenceUnit的名字采用db-routing
.build();
}
/**
* 配置数据的事务管理者,命名为routingTransactionManager依赖routtingEntityManagerFactory
*
* @param routingEntityManagerFactory
* @return
*/
@Bean(name = "routingTransactionManager")
public PlatformTransactionManager transactionManager(@Qualifier("routingEntityManagerFactory") EntityManagerFactory routingEntityManagerFactory) {
return new JpaTransactionManager(routingEntityManagerFactory);
}
}
路由数据源配置与 DataSource1Config 和 DataSource2Config 有相互覆盖关系,这里我们直接覆盖 db1 和 db2 的包路径,以便于我们的动态数据源生效。
第四步:写一个 MVC 拦截器,用来指定请求分别采用什么数据源。
新建一个类 DataSourceInterceptor,用来在请求前后指定数据源,请看代码:
复制代码
/**
* 动态路由的实现逻辑,我们通过请求里面的db-routing,来指定此请求采用什么数据源
*/
@Component
public class DataSourceInterceptor extends HandlerInterceptorAdapter {
/**
* 请求处理之前更改线程里面的数据源
*/
@Override
public boolean preHandle(HttpServletRequest request,
HttpServletResponse response, Object handler) throws Exception {
String dbRouting = request.getHeader("db-routing");
DataSourceRoutingHolder.setBranchContext(RoutingDataSourceEnum.findByCode(dbRouting));
return super.preHandle(request, response, handler);
}
/**
* 请求结束之后清理线程里面的数据源
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
super.afterCompletion(request, response, handler, ex);
DataSourceRoutingHolder.clearBranchContext();
}
}
同时我们需要在实现 WebMvcConfigurer 的配置里面,把我们自定义拦截器 dataSourceInterceptor 加载进去,代码如下:
复制代码
/**
* 实现WebMvcConfigurer
*/
@Configuration
public class MyWebMvcConfigurer implements WebMvcConfigurer {
@Autowired
private DataSourceInterceptor dataSourceInterceptor;
//添加自定义拦截器
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(dataSourceInterceptor).addPathPatterns("/**");
WebMvcConfigurer.super.addInterceptors(registry);
}
...//其他不变的代码省略}
此处我们采用的是 MVC 的拦截器机制动态改变的数据配置,你也可以使用自己的 AOP 任意的拦截器,如事务拦截器、Service 的拦截器等,都可以实现。需要注意的是,要在开启事务之前配置完毕。
第五步:启动测试。
我们在 Http 请求头里面加上 db-routing:DB2,那么本次请求就会采用数据源 2 进行处理,请求代码如下:
复制代码
POST /user/info HTTP/1.1
Host: 127.0.0.1:8089
Content-Type: application/json
db-routing: DB2
Cache-Control: no-cache
Postman-Token: 56d8dc02-7f3e-7b95-7ff1-572a4bb7d102
{"ages":10}
通过上面五个步骤,我们可以利用 AbstractRoutingDataSource 实现动态数据源,实际工作中可能会比我讲述的要复杂,有的需要考虑多线程、线程安全等问题,你要多加注意。
在实际应用场景中,对于多数据源的问题,我还有一些思考,下面分享给你。
微服务下多数据源的思考:还需要这样用吗?
通过上面的两种方式,我们分别可以实现同一个 application 应用的多数据源配置,那么有什么注意事项呢?我简单总结如下几点建议。
多数据源实战注意事项
- 此种方式利用了当前线程事务不变的原理,所以要注意异步线程的处理方式;
- 此种方式利用了 DataSource 的原理,动态地返回不同的 db 连接,一般需要在开启事务之前使用,需要注意事务的生命周期;
- 比较适合读写操作分开的业务场景;
- 多数据的情况下,避免一个事务里面采用不同的数据源,这样会有意想不到的情况发生,比如死锁现象;
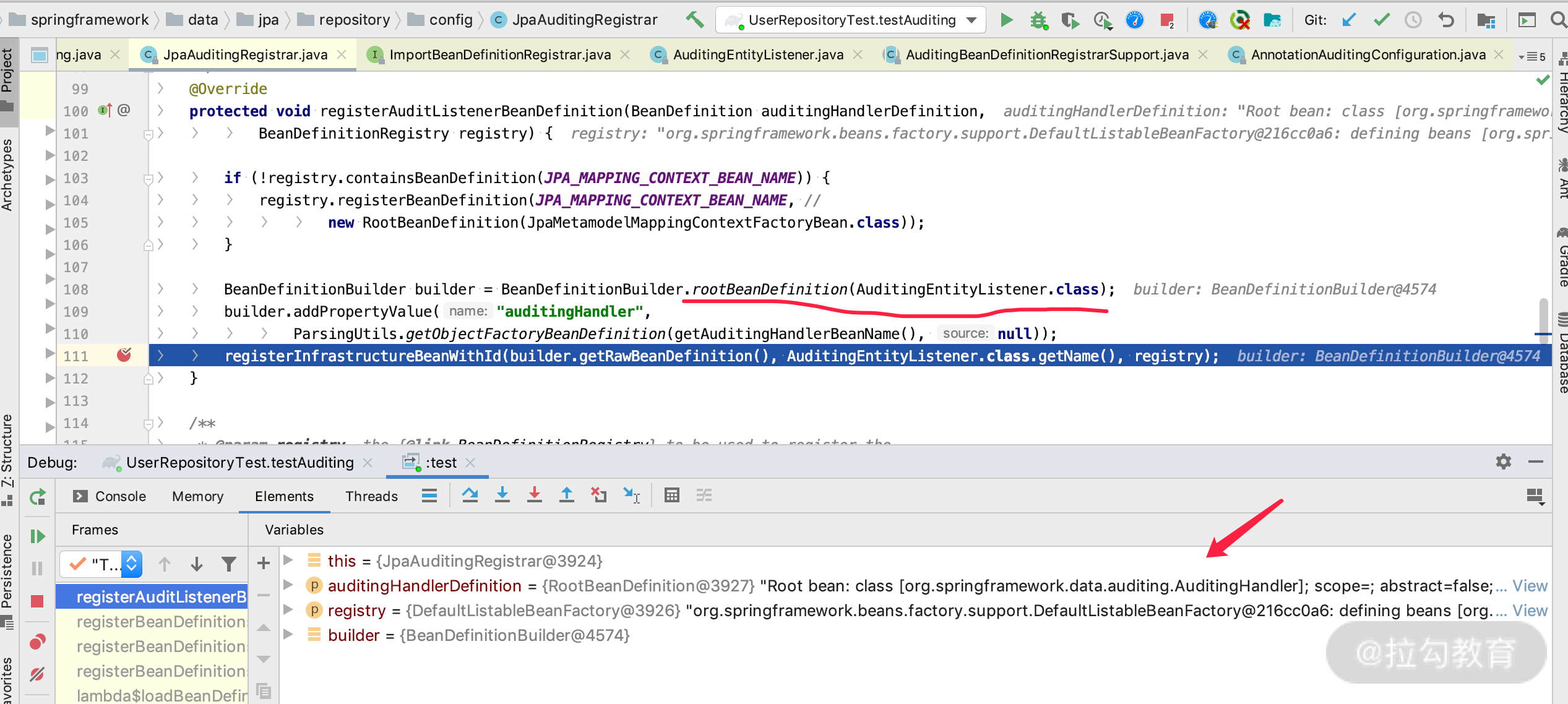
- 学会通过日志检查我们开启请求的方法和开启的数据源是否正确,可以通过 Debug 断点来观察数据源是否选择的正确,如下图所示:
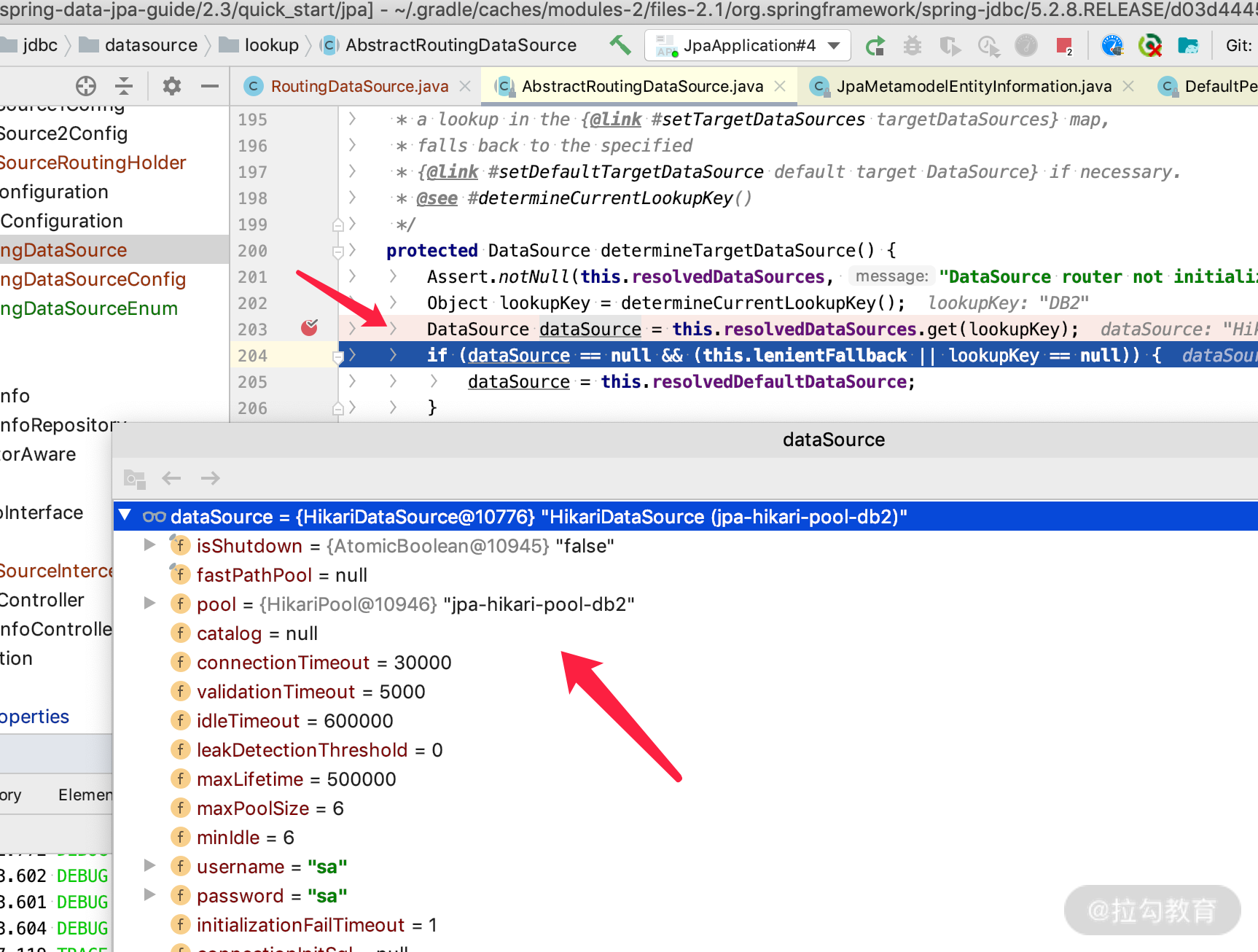
微服务下的实战建议
在实际工作中,为了便捷省事,更多开发者喜欢配置多个数据源,但是我强烈建议不要在对用户直接提供的 API 服务上面配置多数据源,否则将出现令人措手不及的 Bug。
如果你是做后台管理界面,供公司内部员工使用的,那么这种 API 可以为了方便而使用多数据源。
微服务的大环境下,服务越小,内聚越高,低耦合服务越健壮,所以一般跨库之间一定是是通过 REST 的 API 协议,进行内部服务之间的调用,这是最稳妥的方式,原因有如下几点:
- REST 的 API 协议更容易监控,更容易实现事务的原子性;
- db 之间解耦,使业务领域代码职责更清晰,更容易各自处理各种问题;
- 只读和读写的 API 更容易分离和管理。




![[初始java]——规范你的命名规则,变量的使用和注意事项,隐式转化和强制转化](https://img-blog.csdnimg.cn/ca9a3c45410b4a10a1db4034aa185598.png)