卷友们好,我是尚霖。
情绪识别在各种对话场景中具有广泛的应用价值。例如,在社交媒体中,可以通过对评论进行情感分析来了解用户的情绪态度;在人工客服中,可以对客户的情绪进行分析,以更好地满足其需求。
此外,情绪识别还可以应用于聊天机器人,通过实时分析用户的情绪状态,生成基于用户情感的回复,从而提供更加个性化的交互体验。对话情感识别(Emotion Recognition in Conversation)是一个分类任务,旨在识别出一段对话序列里面每句话的情感标签。
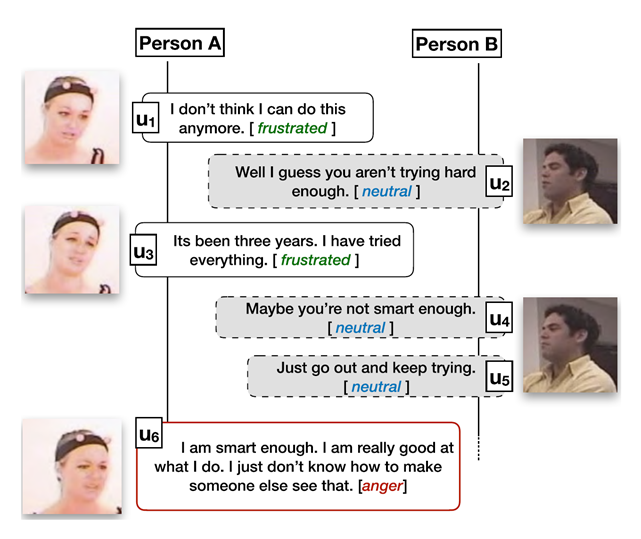
图1给出了一个简单的示例.对话中的话语情绪识别并不简单等同于单个句子的情绪识别,需要综合考虑对话中的背景、上下文、说话人等信息。
长期以来,由于ERC任务强依赖于上下文的理解,基于Roberta的方法即便是在2023年也有接近SOTA的性能,基于Prompt的模型微调方法虽然有但不是主流,在测试集上表现总不如传统方法粗暴有用.所以对话情感识别任务领域一直呈现单句话语特征微调和人物交互细致建模两方面的割裂发展。单句话语特征微调致力于在Glove和RoBERTa的模型上微调并抽取出单句的话语特征,而人物交互细致建模则更加注重于如何去设计话语间,人物间的相互影响来实现精准的情绪识别。
ChatGPT问世以后,几乎所有的NLP任务都在往LLM范式迁移,但ERC任务始终没有进展,一方面研究者们并没有找到好的Instruction框架来激发模型的能力,另外一方面一些用LLM做ERC的浅尝辄止尝试而得到的较差的结果让人们普遍觉得用十亿级别的语言模型来得到一个比小模型差的多的结果实在是大炮打蚊子——小题大作。
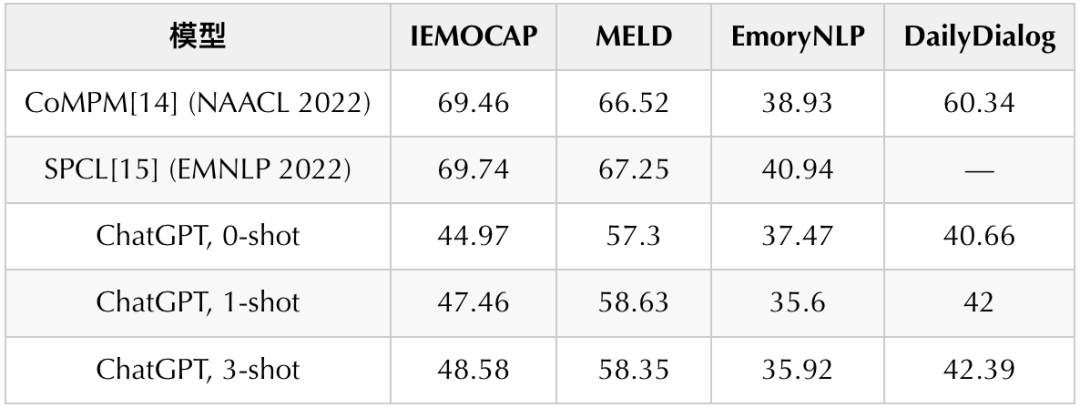
而我们近期的研究则较好地解决了上述两个问题,并且在三个经典榜单上都取得了较大的提升,今天有幸与大家分享我们的方案以及思考。

Paper: https://arxiv.org/abs/2309.11911
Code: https://github.com/LIN-SHANG/InstructERCInstructERC:以生成式视角重构ERC任务
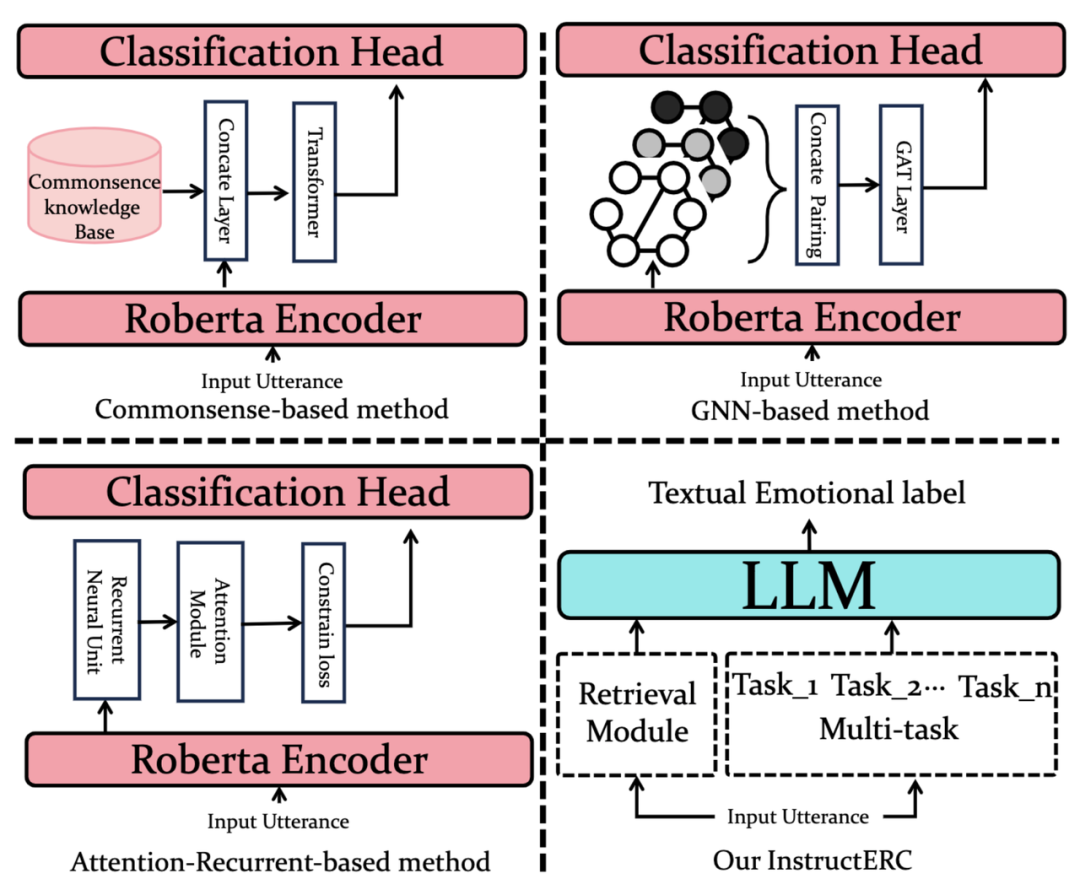
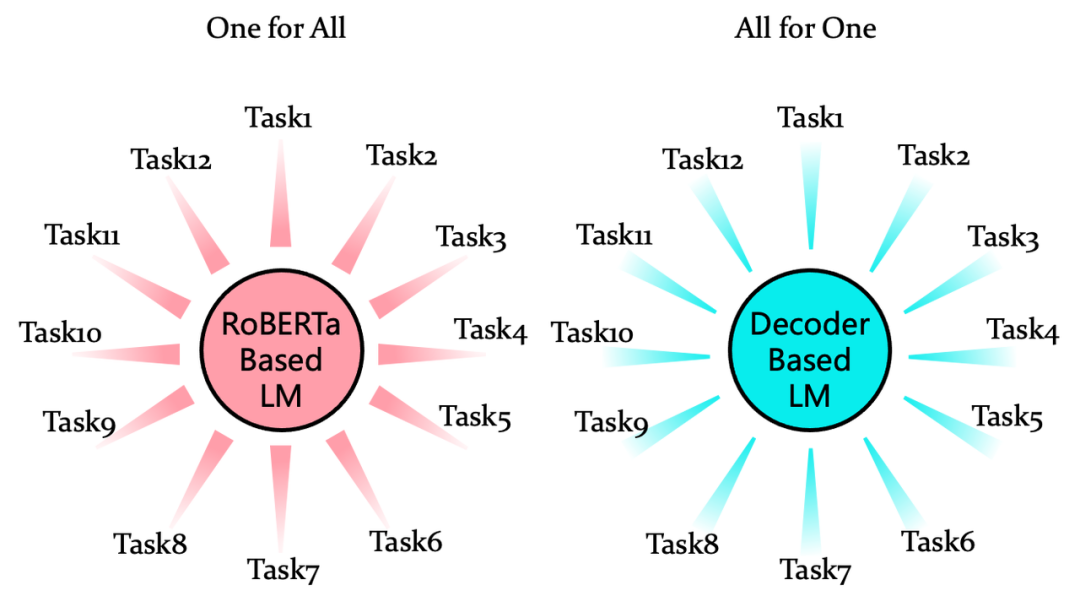
由于预训练方式从Encoder到Decoder的变迁,以Prompt-tuning为代表的技术核心思想为改造下游任务形式,使之符合语言模型的训练范式以便更好的激发语言模型在下游任务上的表现能力,很多NLP任务都被统一为了Seq2Seq的结构,以生成式的方式来解决。
不破不立,对于ERC这种传统判别式任务,InstructERC率先用纯生成式的框架来重构ERC任务,具体结构如下:
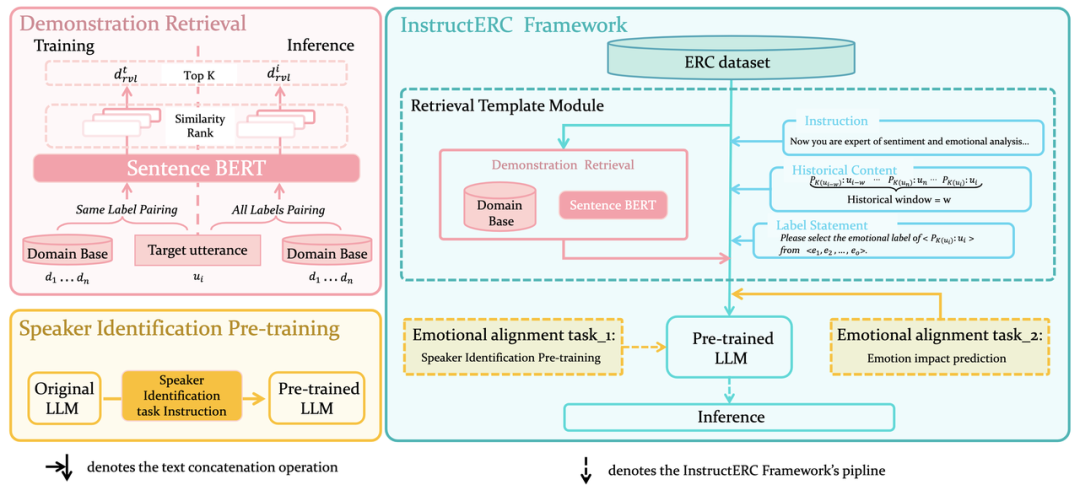
观察InstructERC总体概览图,主体部分为Retrieval Template Module和两个情感对齐任务,Retrieval Template Module,将传统的判别式框架的 ERC 模型转变为了与 LLM 结合的生成式的模型框架。ERC 任务强依赖于历史话语的情感分析 ,同时说话人在表达自己的情感倾向也着强烈的特点,可能是直抒胸臆,也可能反问,最后如果对话中存在多个人物(MELD,EmoryNLP),那么如何去考量对话之间的关系,当前的话语的情绪表达是针对哪句历史话语的回复等都需要被建模。具体来看:
Retrieval Template Module通过一个由historical window超参数控制的窗口来控制输入的历史话语(没有未来信息)以满足输出不超过LLM的input context limitation. 同时以Label Statement这种方式在稳定模型输出上有奇效.
Retrieval Template Module中的Demonstration Retrieval为当前要识别的话语在训练集构建的样本库检索出一个最相近的样本作为demostration以完成多种视角的incontext learning.在训练阶段,由于我们知道样本标签,我们选用和其标签一致的样本进行相似度计算匹配,在推理阶段,由于样本标签未知则将整个样本集进行计算匹配。
由于对LLM进行模型架构修改代价较大且不确定性因素较强,我们同样采用prompt的方式来建模人物特征和对话关系,其由两个情感对齐任务实现。
在情感对齐任务 1中,我们设计了说话人识别的任务,对原始的模型进行了初始的 SFT,SFT 后的模型作为后续ERC任务的SFT 基础。通过这个任务,可以很好的捕获每个说话人的特征。
在情感对齐任务 2中,我们设计了情感影响预测任务,其添加在 Retrieval Template Module 后面,每一次输出,模型需要执行两个情感识别任务,一个当前话语的情感识别,另一个是针对之前的历史话语,来判断它们对当前这句话的情感影响,通过这个任务,我们隐式地让模型捕获对话关系特征。
刷三榜SOTA
找到了正确的架构,LLM在ERC上面的表现可以说是乱杀如表2,需要解释一下,ERC任务每次新 SOTA的Weighted-F1提升大概在 0.2-0.3个点,但是InstructERC仅仅以单模态的数据就在三个数据集上都拿到了 1-2 个点的显著提升,比所有能够验证的单模态,多模态模型的表现都要好。
榜单排名见:IEMOCAP[1], MELD[2], EmoryNLP[3]
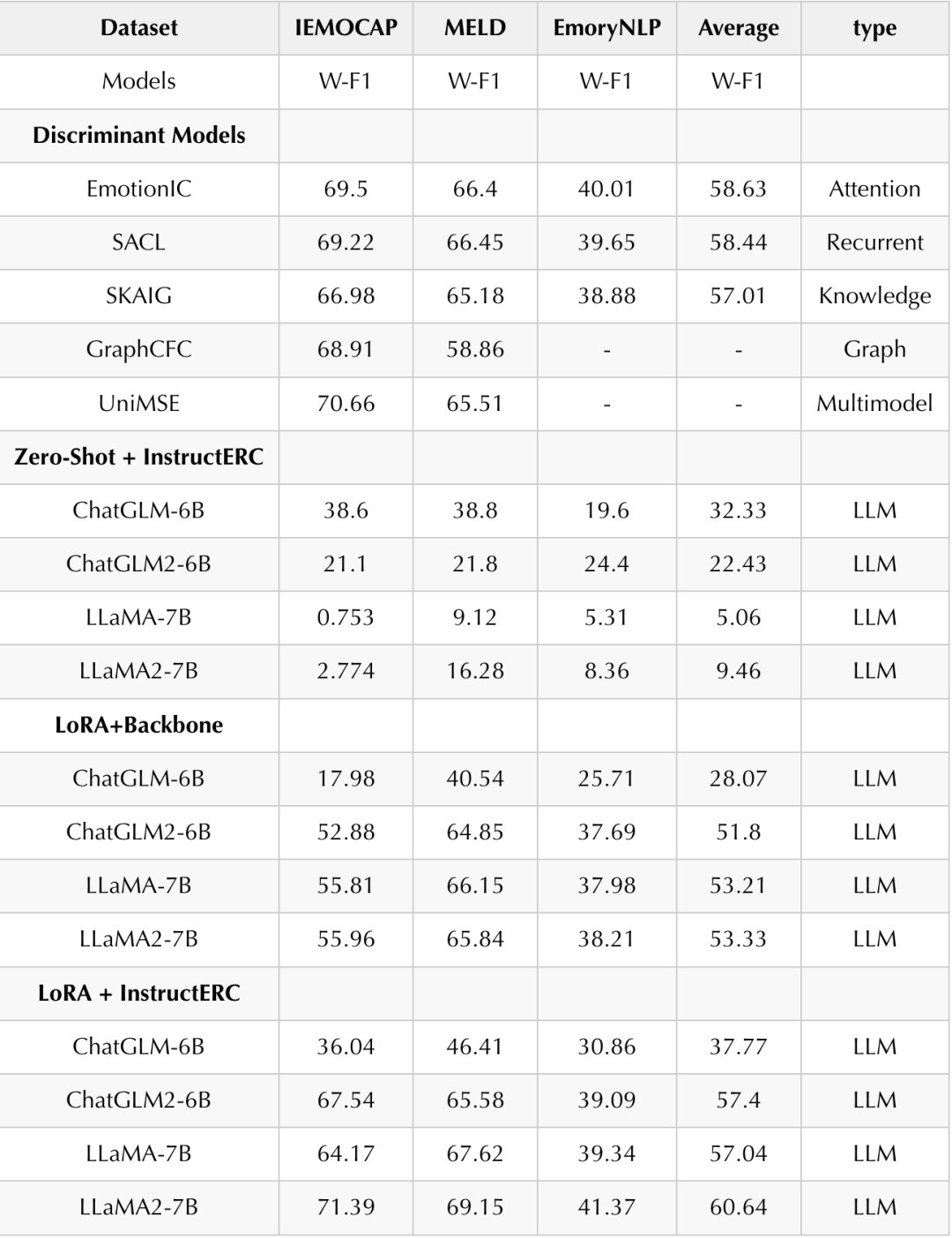
表格分为四部分组成,第一部分是Discriminant Models,由于InstructERC之前的模型都是判别式的,所以我选取了在三个数据集上使用不同判别式方法且表现最优的模型来进行比较。第二部分是Zero-shot + InstructERC,目标是探索在这些基座模型在InstructERC下的指令跟随能力。第三部分是 LoRA+Backbone,目标是为了消融 InstructERC的影响,单独观察 LoRA 的收益。第四部分是 LoRA+InstructERC,目标是探索不同基座在InstructERC下的最佳性能表现。
Discriminant Models:我们分别从 Attention,Recurrent,Knowledge,Graph 和 Multimodel中选择表现最优异的模型,可以发现他们的SOTA只集中在某一个数据集,而 InstructERC在三个数据集上均取得了SOTA。
Zero-Shot + InstructERC:从基座的指令遵循能力方面来看,由于我们采用的 LLaMA 都是原始版本,并非 chat,所以相较于经过指令遵循精调后的ChatGLM 类模型,其按要求输出的能力比较差,很多时候不输出或者输出重复的无关内容,而 ChatGLM 类模型虽然具备一定的遵循能力,但是很多时候会输出一些和标签相近但不正确的答案,比如输出pity----标签 sad, 输出touched----标签 happy 等,这一部分的 Zero-Shot 的bias 可能后续需要一些成熟的解决大模型幻觉的方法来解。
LoRA+Backbone:使用最简单的prompt,但是用LoRA 进行精调,可以观察到 LLM在 ERC 上的性能出现了大的提升,尤其是 MELD 数据集达到了接近 SOTA 的水平。
LoRA+InstructERC:使用 instructERC 框架和 LoRA 方式进行微调,可以观察到 在 Backbone 的基础上出现了更大的提升,同时可以观察到在较于 Backbone,在InstructERC下,LLaMA2 较于 LLaMA 的基座增益明显。
全参数和LoRA的对比在这里[4],就不多叙述了.我们想重点说说下面有意思的实验和发现.
One More Thing (Unified Dataset Experiments)
我们能否做一个更加苛刻的模型泛化性实验呢?
刚刚用到的三个benchmark是各有千秋的,IEMOCAP对话轮次长,MELD对话简短,角色丰富,EmoryNLP类别不均衡严重。他们分别展现了我们日常生活中不同的一些对话场景。在这三个对话场景下能够同时取得SOTA已经能够说明InstructERC的泛化性了。我们更进一步,以1982的论文中提出的The feeling Whale,对三个数据集做了以下对齐:
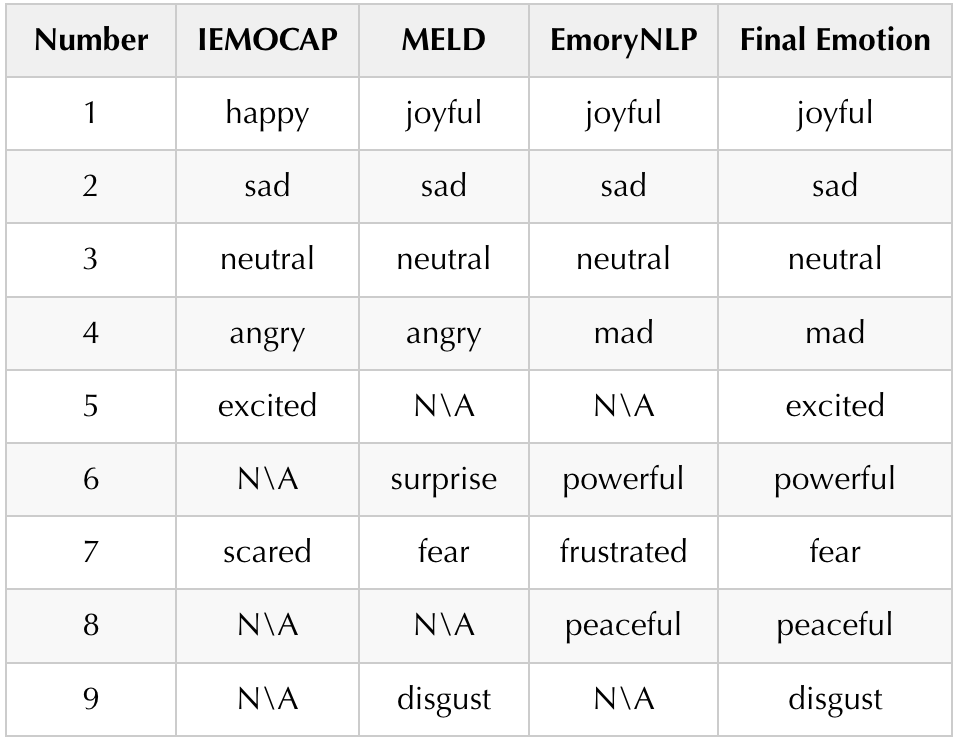
我们依旧使用PEFT中的lora方法对InstructERC在统一数据集上进行训练,训练的结果在三个数据集上分别评测。同时,为了探究不同数据混合策略和数据数量对模型的影响,我们设计了等比例采样和混合数据采样评测实验,在此基础之上,我们更进一步探索了数据采样比例对模型的性能影响,结果如下表4所示,一个更加直观的结果如图6所示。
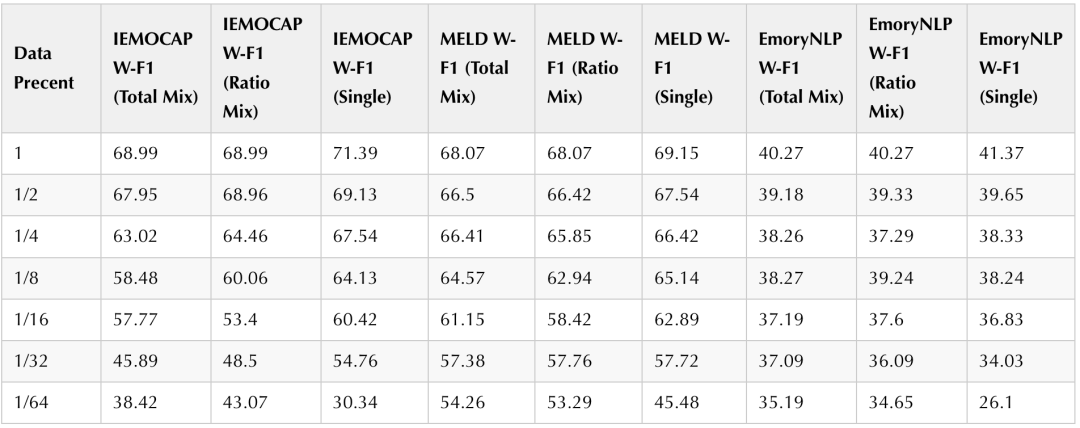
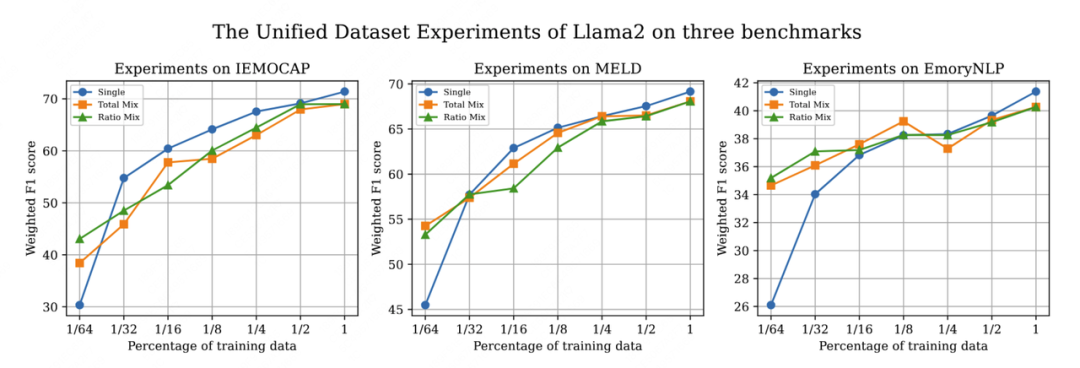
如表4第一行所示,在使用了统一数据集对InstructERC进行finetune的情况下,虽然相较于single数据集训练下的SOTA,三个benchmark的性能出现了轻微下降,但是依旧能够三这三个benchmark上同时保持较高的W-F1,尤其是MELD的性能依旧是领先所有小模型的SOTA水平。因此可以看到,我们对于数据集的处理简单但是高效,另外,基于Llama2大模型基座的InstructERC展现了非凡的鲁棒性,能够同时习得来自多种不同分布的情绪范式,这是以往小模型无法做到的。
大模型具有强大的学习能力,因此在我们的框架下验证the data scaling law是非常重要的一部分。我们对Unified dataset做了从1到1/64的 data scaling 实验,可以看到随着训练数据规模从1到1/32范围内指数级减少,模型在三个benchmark上的性能呈现轻微波动的的线性下降。这和现有的一些大模型探索结论一致。
我们同时惊讶的发现,在训练数据在最后的1/32到1/64阶段,Total Mix和Ratio Mix策略依旧呈现线性的性能下降,但是single方式训练下的模型性能出现了非常猛烈的下降如图6所示。我们认为不同场景的数据给予了模型从不同角度理解情绪的能力,这使得模型在不同的数据下能够获得鲁棒性较强的增益,这种增益在低资源情境(1/64)下尤为明显.
我们进一步探索了不同混合策略对data scaling的影响,在total mix设定下,所有的数据集都混在一起进行统一抽样。而在Ratio mix设定下,数据集被分别抽样然后混合在一起,这两种在训练数据的数量上保持一致,但是由于MELD和EmoryNLP的训练数据绝对数量较多,导致,在Total mix设定下的来源于这两个数据集的训练样本更多,所以比较total mix和ratio mix,可以发现iemocap,meld和EmoryNLP因为训练数据的多与少,有一定的表现偏差。
总结与展望
LLM时代,模型即产品,模型即应用,LLM本身强大的能力如需赋能传统子任务,除了使用更加优良的模型基座以外,本质上是在Prompt和demonstration上面找创新。可以认为,GNN-based、Recurrent-Attenton-based方法是在为所需评测的数据集进行单独的优化的和设计。
如果假定一定存在一个完美的ERC分类器,那么传统的基于RoBERTa的方法与使用LLM进行fintune的方法进行比较。前者可以看作是人为搜索到了一个不错的局部最优架构,在这个架构内部的参数空间进行finetune。
而后者可以看作是在浩如烟海的参数空间中,固定绝大部分参数,让见过近2Ttoken的LLM在Lora的低秩层习得一个适配于数据集的局部最优,虽然可微调的参数量都大差不差,但是LLM背后的知识是传统模型无法企及的,我想这些应该是是数据集单独训练保持SOTA且统一数据集实验性能依旧坚挺的原因。
LLM的路依旧很长,InstructERC可以看做是一个小trick,希望大家能够一起探索LLM赋能更多子任务的精彩表现!
参考资料
[1]
IEMOCAP: https://paperswithcode.com/sota/emotion-recognition-in-conversation-on?p=instructerc-reforming-emotion-recognition-in
[2]MELD: https://paperswithcode.com/sota/emotion-recognition-in-conversation-on-meld?p=instructerc-reforming-emotion-recognition-in
[3]EmoryNLP: https://paperswithcode.com/sota/emotion-recognition-in-conversation-on-4?p=instructerc-reforming-emotion-recognition-in
[4]All Parameters vs Parameter Efficiency: https://github.com/LIN-SHANG/InstructERC#all-parameters-vs-parameter-efficiency

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼



![[初始java]——规范你的命名规则,变量的使用和注意事项,隐式转化和强制转化](https://img-blog.csdnimg.cn/ca9a3c45410b4a10a1db4034aa185598.png)