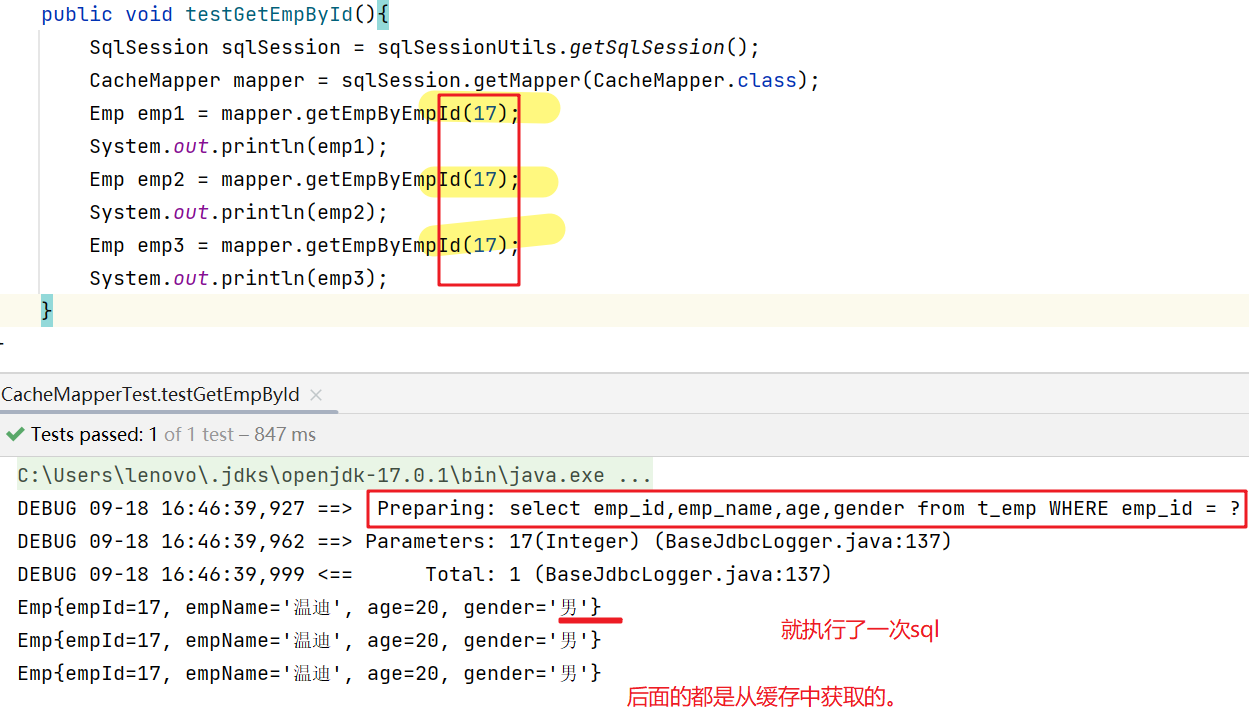
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
8.6.1 定义模型
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
state = torch.zeros((1, batch_size, num_hiddens))
state.shape # (隐藏层数,批量大小,隐藏单元数)
torch.Size([1, 32, 256])
通过一个隐状态和一个输入可以用更新后的隐状态计算输出。
需要强调的是,rnn_layer的“输出”(Y)不涉及输出层的计算:它是指每个时间步的隐状态,这些隐状态可以用作后续输出层的输入。
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape
(torch.Size([35, 32, 256]), torch.Size([1, 32, 256]))
#@save
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
8.6.2 训练与预测
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)
'time travellerffffffffff'
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device) # 比自己写的跑得快
perplexity 1.3, 213489.4 tokens/sec on cuda:0
time traveller held in his han so withtre scon the thin one mige
travellericho for the prof read haly and hes it nople hat d

练习
(1)尝试使用高级API,能使循环神经网络模型过拟合吗?
略。
(2)如果在循环神经网络模型中增加隐藏层的数量会发生什么?能使模型正常工作吗?
num_hiddens1 = 1024
rnn_layer1 = nn.RNN(len(vocab), num_hiddens1)
net1 = RNNModel(rnn_layer1, vocab_size=len(vocab))
net1 = net1.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(net1, train_iter, vocab, lr, num_epochs, device) # 效果更好了,但是曲线没那么平滑了
perplexity 1.0, 97329.8 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby

(3)尝试使用循环神经网络实现 8.1 节的自回归模型。
略




![2023年中国分布式光纤传感产量、需求量及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/6b90839b616e6cecae40b5efe44b69c5.png)