文章目录
- 📚import requests
- 📚import re
- 📚from lxml import etree
- 📚from bs4 import BeautifulSoup
- 📚小结
契机是课程项目需要爬取一份数据,于是在CSDN搜了搜相关的教程。在博主【朦胧的雨梦】主页学到很多😄。本文基于大佬给出的实例学习记录自用。以下将相关博客列出,推荐学习~
- Python |浅谈爬虫的由来
- Python爬虫 | 利用python爬虫获取想要搜索的数据
- Python爬虫经典战役——正则实战
- Python爬虫| 一文掌握XPath
- Python爬虫之美丽的汤——BeautifulSoup
📚import requests
-
使用模板
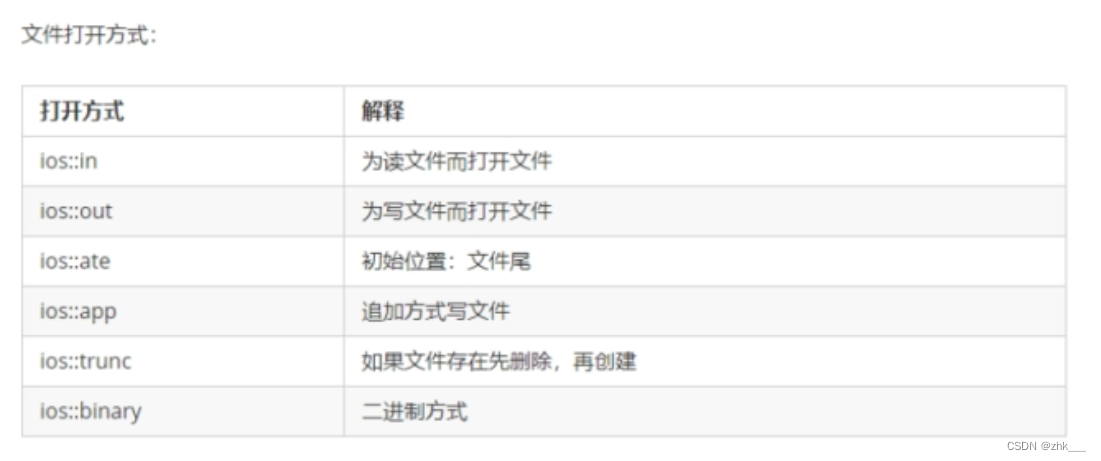
import requests url ='xxxxxxxxxxxx' #发送请求 response = request.get(url, params,headers) (get请求或者post请求) #根据相应的格式解码 response.encoding=response.appareent_encoding
-
在爬虫应用中,伪装请求头里的User-Agent和Cookie具有以下作用和目的:
- User-Agent:User-Agent是HTTP请求头的一部分,用于告诉服务器发送请求的客户端的信息,其中常用的是浏览器标识。在爬虫中,通过设置一个合适的User-Agent,可以模拟不同的浏览器或客户端发起请求,使得请求看起来更像是来自真实的人而不是自动化程序。有些网站可能会根据User-Agent的不同来返回不同的内容,所以在编写爬虫时,设置合适的User-Agent可以提高请求的成功率。
- Cookie:Cookie是存储在客户端(浏览器)中的一小段数据,用于跟踪用户的会话状态。在爬虫中,有些网站会使用Cookie来记录用户的登录状态、浏览历史等信息。为了模拟用户登录状态或以合适的身份进行访问,我们可以在请求头中添加Cookie信息。通过使用合适的Cookie值,可以使请求看起来更像是经过登录验证的用户发起的请求,从而获取到需要登录才能访问的内容。
-
通过伪装请求头中的User-Agent和Cookie,可以增加爬虫对目标网站的访问成功率,避免被服务器拒绝访问或返回错误的内容。另外,在使用伪装请求头时,需要注意遵守网站的使用规则和避免非法操作,以免违反相关法律法规或引起不必要的麻烦。
-
代码精读
import requests data = input('输入你想要查找的数据:').split() # 地址 url ='http://www.baidu.com/s' # 伪装请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36', 'Cookie': 'BIDUPSID=CDE3B4BEE7AE0D336C4D0734E42BCF8B; PSTM=1664331801; BAIDUID=CDE3B4BEE7AE0D33996D27FED1DDB4DB:FG=1; BD_UPN=12314753; BDUSS=JNdXVzTXMyWmFKM0x1VWJ5eG9GUjg4UmVCRFQxY1dtejBPVDFBfjc0VHhYRnRqRVFBQUFBJCQAAAAAAAAAAAEAAACse3WjanNuZGJpZAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAPHPM2PxzzNjTT; BDUSS_BFESS=JNdXVzTXMyWmFKM0x1VWJ5eG9GUjg4UmVCRFQxY1dtejBPVDFBfjc0VHhYRnRqRVFBQUFBJCQAAAAAAAAAAAEAAACse3WjanNuZGJpZAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAPHPM2PxzzNjTT; newlogin=1; ZFY=utLrULRdQjGdhXHuTriamg7jZ2PZMLmnKmUCBUiVrTw:C; BAIDUID_BFESS=CDE3B4BEE7AE0D33996D27FED1DDB4DB:FG=1; BA_HECTOR=ag04ah242k2l2h0la0010ofe1ho8t901f; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; COOKIE_SESSION=765400_1_9_9_5_15_1_0_9_7_0_0_1292084_0_0_0_1668919087_1669684425_1669684425%7C9%234656831_6_1669684425%7C3; B64_BOT=1; BDRCVFR[7FEYkXni5q3]=mk3SLVN4HKm; BD_HOME=1; H_PS_PSSID=26350; BD_CK_SAM=1; PSINO=3; delPer=1; H_PS_645EC=3d48biiwjEvDlNFtMaUHuepsRu67OxRgPoEiOrMKvfRketUwB4GowDbv4KmDa%2BaTHUgCCoc; baikeVisitId=e1f583c7-eb15-4940-a709-054666f30f48; BDSVRTM=443' } data = { # 'wd'是百度搜索的关键字参数 'wd': data } # 获得响应 response = requests.get(url=url, params=data, headers=headers) # 智能解码 response.encoding = response.apparent_encoding # 返回响应内容 print(response.text)
📚import re
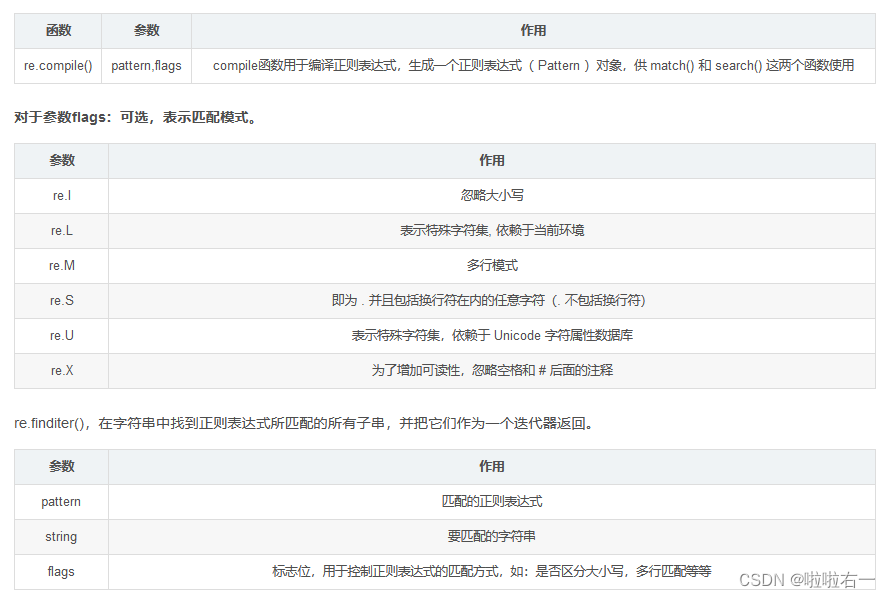
- 贪婪匹配,尽可能多的匹配字符:
.* - 非贪婪匹配,尽可能少的匹配字符:
.*?
-
代码精读
import requests import re # 目标网页的URL url = 'https://movie.douban.com/top250' # 请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36' } # 使用requests库发送GET请求,获取目标网页的内容,并将其编码为对应的字符编码格式。 response = requests.get(url=url, headers=headers) response.encoding = response.apparent_encoding # 响应内容的文本形式,存储在变量h h = response.text # 通过正则表达式模式匹配和提取电影信息 pattern = re.compile(r'<img width="100" alt="(?P<name>.*?)"' r'.*?<p class="">.*? ' r'导演: (?P<director>.*?) .*?' r'主演: (?P<actors>.*?)<br>' r'(?P<year>.*?) .*?' r'/ (?P<country>.*?) .*?' r';(?P<type>.*?)</p>.*?' r'<span class="rating_num" property="v:average">(?P<mark>.*?)</span>.*?' r'<span>(?P<evaluate>.*?)</span>', re.S) # 在字符串h中搜索与pattern匹配的内容,并返回一个迭代器对象 result = pattern.finditer(h) for item in result: with open('豆瓣电影信息.txt', 'a', encoding='utf-8') as fp: fp.write('\n') # 使用group方法获取每个匹配项中各个信息字段的值 fp.write(item.group('name')) # 写入文件 fp.write('\n') fp.write(item.group('director')) fp.write('\n') fp.write(item.group('actors')) fp.write('\n') fp.write(item.group('year').strip()) fp.write('\n') fp.write(item.group('country')) fp.write('\n') fp.write(item.group('type')) fp.write('\n') fp.write(item.group('mark')) fp.write('\n') fp.write(item.group('evaluate')) fp.write('\n') print('爬取完成')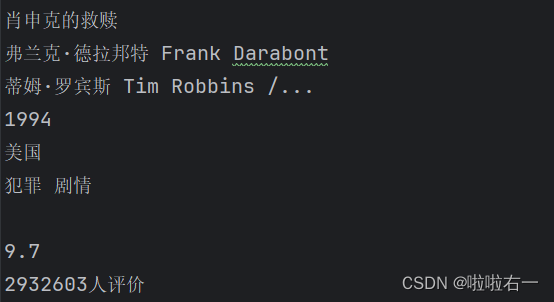


<img width="100" alt="(?P<name>.*?)"- 匹配电影海报的img标签,其中包含了电影名称。
(?P<name>.*?)使用?P<name>为该匹配项命名为’name’,并使用非贪婪模式匹配任意字符。
- 匹配电影海报的img标签,其中包含了电影名称。
.*?<p class="">.*?- 匹配电影信息中的起始标签
<p class="">之后的任意字符。
- 匹配电影信息中的起始标签
导演: (?P<director>.*?) .*?- 匹配导演姓名,导演姓名使用
(?P<director>.*?)命名为’director’,并使用非贪婪模式匹配任意字符。
- 匹配导演姓名,导演姓名使用
主演: (?P<actors>.*?)<br>- 匹配主演姓名,主演姓名使用
(?P<actors>.*?)命名为’actors’,并使用非贪婪模式匹配任意字符。该部分以<br>标签结尾。
- 匹配主演姓名,主演姓名使用
(?P<year>.*?) .*?- 该部分匹配包含电影年份的文本,年份使用
(?P<year>.*?)命名为’year’,并使用非贪婪模式匹配任意字符。该部分以 结尾。
- 该部分匹配包含电影年份的文本,年份使用
/ (?P<country>.*?) .*?- 匹配电影国家/地区,国家/地区使用
(?P<country>.*?)命名为’country’,并使用非贪婪模式匹配任意字符。该部分以 结尾。
- 匹配电影国家/地区,国家/地区使用
;(?P<type>.*?)</p>.*?- 匹配包含电影类型的文本,类型使用
(?P<type>.*?)命名为’type’,并使用非贪婪模式匹配任意字符。该部分以;和</p>标签结尾。
- 匹配包含电影类型的文本,类型使用
<span class="rating_num" property="v:average">(?P<mark>.*?)</span>.*?- 匹配电影评分,评分使用
(?P<mark>.*?)命名为’mark’,并使用非贪婪模式匹配任意字符。该部分以<span class="rating_num" property="v:average">和</span>标签结尾。
- 匹配电影评分,评分使用
<span>(?P<evaluate>.*?)</span>- 匹配电影评价,评价使用
(?P<evaluate>.*?)命名为’evaluate’,并使用非贪婪模式匹配任意字符。该部分以<span>和</span>标签结尾。
- 匹配电影评价,评价使用
📚from lxml import etree
- 代码精读
import requests from lxml import etree # 需要请求的url url = 'https://www.duanmeiwen.com/xinshang/3203373.html' # 伪装请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36', } # 获得响应 response = requests.get(url=url, headers=headers) # 智能解码 response.encoding = response.apparent_encoding # 提取数据 # 使用etree.HTML函数将HTML文本转换为可进行XPath操作的树结构对象tree。 tree = etree.HTML(response.text) # 指定了要提取的目标位置 # 即在HTML文档中,位于/html/body/div[2]/div[2]/div/div[2]/h2这个路径下的<h2>标签。 # div[2]表示选择第二个div元素 # text()表示提取选定元素的文本内容。 # 将结果存储在titles变量 titles = tree.xpath('/html/body/div[2]/div[2]/div/div[2]/h2/text()') # 同上 message = tree.xpath('/html/body/div[2]/div[2]/div/div[2]/p/text()') #遍历保存数据 for i in range(len(message)): with open('优美文艺句子.txt', 'a', encoding='utf-8') as fp: fp.write(message[i]) fp.write('\n') print('文章爬取完成')

📚from bs4 import BeautifulSoup
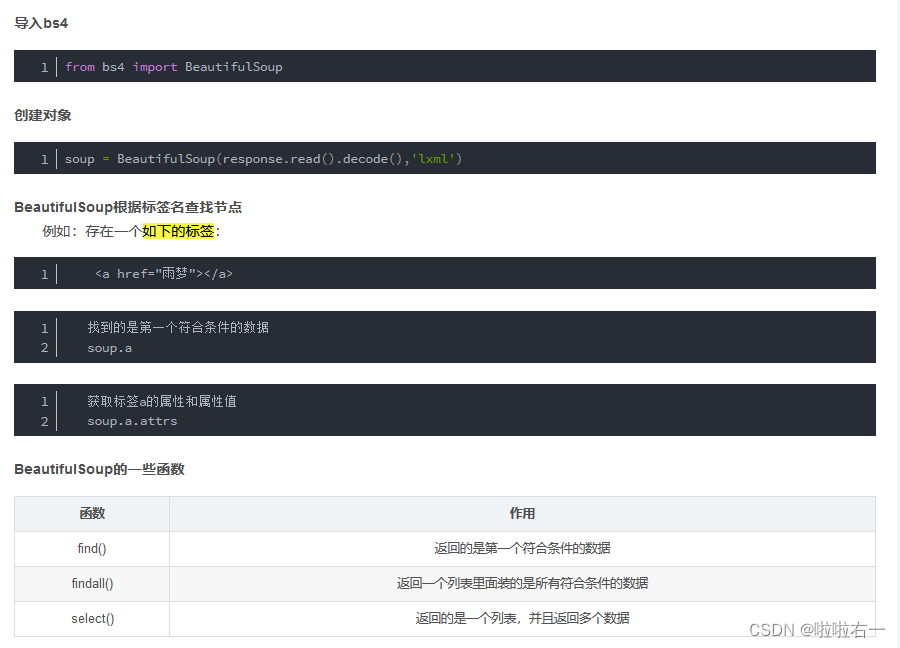
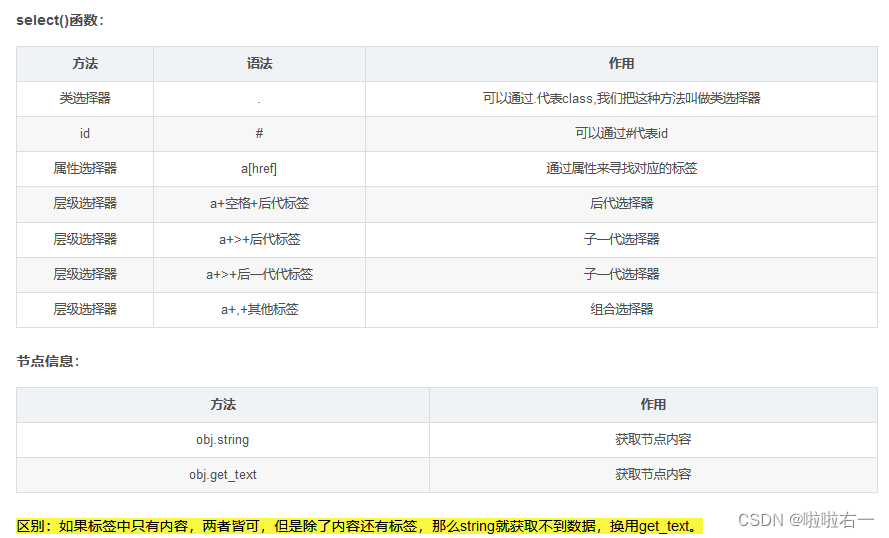
-
代码精读
import requests from bs4 import BeautifulSoup # 需要请求的url url = 'https://www.starbucks.com.cn/menu/' # 伪装请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36', } # 获得响应 response = requests.get(url=url, headers=headers) # 智能解码 response.encoding = response.apparent_encoding # 提取数据 soup = BeautifulSoup(response.text, 'lxml') # 通过选择器找到了class为"grid padded-3 product"的ul元素下的strong标签,并将其结果存储在name_list变量中 name_list = soup.select('ul[class="grid padded-3 product"] strong') print(name_list) # 保存数据 for i in name_list: with open('星巴克.txt', 'a', encoding='utf-8') as fp: # 提取HTML或XML文档中指定元素的文本内容 fp.write(i.get_text()) fp.write('\n') print('文章爬取完成')
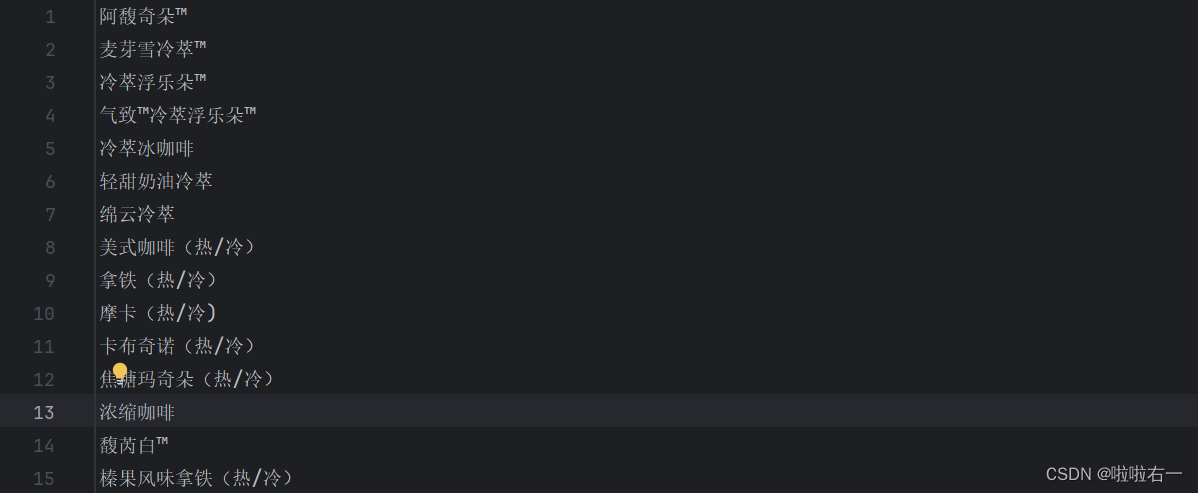
📚小结
在爬虫应用中,常用的第三方库包括requests、re、lxml和beautifulsoup。
-
requests库:requests是一个功能强大且易于使用的HTTP库,用于发送HTTP请求。它可以方便地进行网页的访问和数据的获取,包括发送GET和POST请求,设置请求头、参数、Cookie等,并获取响应结果。它可以用于下载网页内容、API数据等。
-
re库:re是Python内置的正则表达式库,它提供了丰富的方法来处理字符串匹配和替换的操作。在爬虫应用中,re经常被用来从HTML页面或文本中提取所需的信息,比如通过正则表达式来匹配特定的文本内容或URL。
-
lxml库:lxml是一个用于解析XML和HTML的库,并提供了XPath和CSS选择器等灵活的选择器语法,用于定位和提取HTML或XML文档中的元素和文本。lxml库具有高效的解析速度和稳定的性能,在爬虫应用中经常被用来解析HTML页面,提取所需的数据。
-
BeautifulSoup库:BeautifulSoup库是基于lxml或者html.parser库构建的Python库,用于将HTML或XML文档解析为可以操作和搜索的树形结构,更方便地进行数据提取。BeautifulSoup提供了直观而简洁的API,可以使用选择器语法来定位元素、获取文本内容、提取属性等。它还具有处理错误和不完整的HTML文档的能力,方便地处理各种网页结构。在爬虫应用中,BeautifulSoup经常被用来解析和处理网页数据,从中提取所需的信息。
这些库在爬虫应用中通常是相互配合使用的,requests用于发送HTTP请求获取网页内容,re用于对网页内容进行正则匹配提取,lxml用于解析网页内容,而BeautifulSoup则用于定位和提取所需的数据。